Events, Co-Routines, Continuations and Threads
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Events, Co-Routines, Continuations and Threads OS (And Application)Execution Models System Building
Events, Co-routines, Continuations and Threads OS (and application)Execution Models System Building General purpose systems need to deal with • Many activities – potentially overlapping – may be interdependent • Activities that depend on external phenomena – may requiring waiting for completion (e.g. disk read) – reacting to external triggers (e.g. interrupts) Need a systematic approach to system structuring © Kevin Elphinstone 2 Construction Approaches Events Coroutines Threads Continuations © Kevin Elphinstone 3 Events External entities generate (post) events. • keyboard presses, mouse clicks, system calls Event loop waits for events and calls an appropriate event handler. • common paradigm for GUIs Event handler is a function that runs until completion and returns to the event loop. © Kevin Elphinstone 4 Event Model The event model only requires a single stack Memory • All event handlers must return to the event loop CPU Event – No blocking Loop – No yielding PC Event SP Handler 1 REGS Event No preemption of handlers Handler 2 • Handlers generally short lived Event Handler 3 Data Stack © Kevin Elphinstone 5 What is ‘a’? int a; /* global */ int func() { a = 1; if (a == 1) { a = 2; } No concurrency issues within a return a; handler } © Kevin Elphinstone 6 Event-based kernel on CPU with protection Kernel-only Memory User Memory CPU Event Loop Scheduling? User PC Event Code SP Handler 1 REGS Event Handler 2 User Event Data Handler 3 Huh? How to support Data Stack multiple Stack processes? © Kevin Elphinstone 7 Event-based kernel on CPU with protection Kernel-only Memory User Memory CPU PC Trap SP Dispatcher User REGS Event Code Handler 1 User-level state in PCB Event PCB Handler 2 A User Kernel starts on fresh Timer Event Data stack on each trap (Scheduler) PCB B No interrupts, no blocking Data Current in kernel mode Thead PCB C Stack Stack © Kevin Elphinstone 8 Co-routines Originally described in: • Melvin E. -

A Practical UNIX Capability System
A Practical UNIX Capability System Adam Langley <[email protected]> 22nd June 2005 ii Abstract This report seeks to document the development of a capability security system based on a Linux kernel and to follow through the implications of such a system. After defining terms, several other capability systems are discussed and found to be excellent, but to have too high a barrier to entry. This motivates the development of the above system. The capability system decomposes traditionally monolithic applications into a number of communicating actors, each of which is a separate process. Actors may only communicate using the capabilities given to them and so the impact of a vulnerability in a given actor can be reasoned about. This design pattern is demonstrated to be advantageous in terms of security, comprehensibility and mod- ularity and with an acceptable performance penality. From this, following through a few of the further avenues which present themselves is the two hours traffic of our stage. Acknowledgments I would like to thank my supervisor, Dr Kelly, for all the time he has put into cajoling and persuading me that the rest of the world might have a trick or two worth learning. Also, I’d like to thank Bryce Wilcox-O’Hearn for introducing me to capabilities many years ago. Contents 1 Introduction 1 2 Terms 3 2.1 POSIX ‘Capabilities’ . 3 2.2 Password Capabilities . 4 3 Motivations 7 3.1 Ambient Authority . 7 3.2 Confused Deputy . 8 3.3 Pervasive Testing . 8 3.4 Clear Auditing of Vulnerabilities . 9 3.5 Easy Configurability . -

Designing an Ultra Low-Overhead Multithreading Runtime for Nim
Designing an ultra low-overhead multithreading runtime for Nim Mamy Ratsimbazafy Weave [email protected] https://github.com/mratsim/weave Hello! I am Mamy Ratsimbazafy During the day blockchain/Ethereum 2 developer (in Nim) During the night, deep learning and numerical computing developer (in Nim) and data scientist (in Python) You can contact me at [email protected] Github: mratsim Twitter: m_ratsim 2 Where did this talk came from? ◇ 3 years ago: started writing a tensor library in Nim. ◇ 2 threading APIs at the time: OpenMP and simple threadpool ◇ 1 year ago: complete refactoring of the internals 3 Agenda ◇ Understanding the design space ◇ Hardware and software multithreading: definitions and use-cases ◇ Parallel APIs ◇ Sources of overhead and runtime design ◇ Minimum viable runtime plan in a weekend 4 Understanding the 1 design space Concurrency vs parallelism, latency vs throughput Cooperative vs preemptive, IO vs CPU 5 Parallelism is not 6 concurrency Kernel threading 7 models 1:1 Threading 1 application thread -> 1 hardware thread N:1 Threading N application threads -> 1 hardware thread M:N Threading M application threads -> N hardware threads The same distinctions can be done at a multithreaded language or multithreading runtime level. 8 The problem How to schedule M tasks on N hardware threads? Latency vs 9 Throughput - Do we want to do all the work in a minimal amount of time? - Numerical computing - Machine learning - ... - Do we want to be fair? - Clients-server - Video decoding - ... Cooperative vs 10 Preemptive Cooperative multithreading: -

Ultimate++ Forum Probably with These Two Variables You Could Try to Integrate D-BUS
Subject: DBus integration -- need help Posted by jlfranks on Thu, 20 Jul 2017 15:30:07 GMT View Forum Message <> Reply to Message We are trying to add a DBus server to existing large U++ application that runs only on Linux. I've converted from X11 to GTK for Upp project config to be compatible with GIO dbus library. I've created a separate thread for the DBus server and ran into problems with event loop. I've gutted my DBus server code of everything except what is causing an issue. DBus GIO examples use GMainLoop in order for DBus to service asynchronous events. Everything compiles and runs except the main UI is not longer visible. There must be a GTK main loop already running and I've stepped on it with this code. Is there a way for me to obtain a pointer to the UI main loop and use it with my DBus server? How/where can I do that? Code snipped example as follows: ---- code snippet ---- myDBusServerMainThread() { //========================================================== ===== // // Enter main service loop for this thread // while (not needsExit ()) { // colaborate with join() GMainLoop *loop; loop = g_main_loop_new(NULL, FALSE); g_main_loop_run(loop); } } Subject: Re: DBus integration -- need help Posted by Klugier on Thu, 20 Jul 2017 22:30:17 GMT View Forum Message <> Reply to Message Hello, You could try use following methods of Ctrl to obtain gtk & gdk handlers: GdkWindow *gdk() const { return top ? top->window->window : NULL; } GtkWindow *gtk() const { return top ? (GtkWindow *)top->window : NULL; } Page 1 of 3 ---- Generated from Ultimate++ forum Probably with these two variables you could try to integrate D-BUS. -

Fundamentals of Xlib Programming by Examples
Fundamentals of Xlib Programming by Examples by Ross Maloney Contents 1 Introduction 1 1.1 Critic of the available literature . 1 1.2 The Place of the X Protocol . 1 1.3 X Window Programming gotchas . 2 2 Getting started 4 2.1 Basic Xlib programming steps . 5 2.2 Creating a single window . 5 2.2.1 Open connection to the server . 6 2.2.2 Top-level window . 7 2.2.3 Exercises . 10 2.3 Smallest Xlib program to produce a window . 10 2.3.1 Exercises . 10 2.4 A simple but useful X Window program . 11 2.4.1 Exercises . 12 2.5 A moving window . 12 2.5.1 Exercises . 15 2.6 Parts of windows can disappear from view . 16 2.6.1 Testing overlay services available from an X server . 17 2.6.2 Consequences of no server overlay services . 17 2.6.3 Exercises . 23 2.7 Changing a window’s properties . 23 2.8 Content summary . 25 3 Windows and events produce menus 26 3.1 Colour . 26 3.1.1 Exercises . 27 i CONTENTS 3.2 A button to click . 29 3.3 Events . 33 3.3.1 Exercises . 37 3.4 Menus . 37 3.4.1 Text labelled menu buttons . 38 3.4.2 Exercises . 43 3.5 Some events of the mouse . 44 3.6 A mouse behaviour application . 55 3.6.1 Exercises . 58 3.7 Implementing hierarchical menus . 58 3.7.1 Exercises . 67 3.8 Content summary . 67 4 Pixmaps 68 4.1 The pixmap resource . -

An Ideal Match?
24 November 2020 An ideal match? Investigating how well-suited Concurrent ML is to implementing Belief Propagation for Stereo Matching James Cooper [email protected] OutlineI 1 Stereo Matching Generic Stereo Matching Belief Propagation 2 Concurrent ML Overview Investigation of Alternatives Comparative Benchmarks 3 Concurrent ML and Belief Propagation 4 Conclusion Recapitulation Prognostication 5 References Outline 1 Stereo Matching Generic Stereo Matching Belief Propagation 2 Concurrent ML Overview Investigation of Alternatives Comparative Benchmarks 3 Concurrent ML and Belief Propagation 4 Conclusion Recapitulation Prognostication 5 References Outline 1 Stereo Matching Generic Stereo Matching Belief Propagation 2 Concurrent ML Overview Investigation of Alternatives Comparative Benchmarks 3 Concurrent ML and Belief Propagation 4 Conclusion Recapitulation Prognostication 5 References Stereo Matching Generally SM is finding correspondences between stereo images Images are of the same scene Captured simultaneously Correspondences (`disparity') are used to estimate depth SM is an ill-posed problem { can only make best guess Impossible to perform `perfectly' in general case Stereo Matching ExampleI (a) Left camera's image (b) Right camera's image Figure 1: The popular 'Tsukuba' example stereo matching images, so called because they were created by researchers at the University of Tsukuba, Japan. They are probably the most widely-used benchmark images in stereo matching. Stereo Matching ExampleII (a) Ground truth disparity map (b) Disparity map generated using a simple Belief Propagation Stereo Matching implementation Figure 2: The ground truth disparity map for the Tsukuba images, and an example of a possible real disparity map produced by using Belief Propagation Stereo Matching. The ground truth represents what would be expected if stereo matching could be carried out `perfectly'. -

Tcl and Java Performance
Tcl and Java Performance http://ptolemy.eecs.berkeley.edu/~cxh/java/tclblend/scriptperf/scriptperf.html Tcl and Java Performance by H. John Reekie, University of California at Berkeley Christopher Hylands, University of California at Berkeley Edward A. Lee, University of California at Berkeley Abstract Combining scripting languages such as Tcl with lower−level programming languages such as Java offers new opportunities for flexible and rapid software development. In this paper, we benchmark various combinations of Tcl and Java against the two languages alone. We also provide some comparisons with JavaScript. Performance can vary by well over two orders of magnitude. We also uncovered some interesting threading issues that affect performance on the Solaris platform. "There are lies, damn lies and statistics" This paper is a work in progress, we used the information here to give our group some generalizations on the performance tradeoffs between various scripting languages. Updating the timing results to include JDK1.2 with a Just In Time (JIT) compiler would be useful. Introduction There is a growing trend towards integration of multiple languages through scripting. In a famously controversial white paper (Ousterhout 97), John Ousterhout, now of Scriptics Corporation, argues that scripting −− the use of a high−level, untyped, interpreted language to "glue" together components written in a lower−level language −− provides greater reuse benefits that other reuse technologies. Although traditionally a language such as C or C++ has been the lower−level language, more recent efforts have focused on using Java. Recently, Sun Microsystems laboratories announced two products aimed at fulfilling this goal with the Tcl and Java programming languages. -
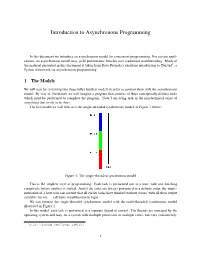
Introduction to Asynchronous Programming
Introduction to Asynchronous Programming In this document we introduce an asynchronous model for concurrent programming. For certain appli- cations, an asynchronous model may yield performance benefits over traditional multithreading. Much of the material presented in this document is taken from Dave Peticola’s excellent introduction to Twisted1, a Python framework for asynchronous programming. 1 The Models We will start by reviewing two (hopefully) familiar models in order to contrast them with the asynchronous model. By way of illustration we will imagine a program that consists of three conceptually distinct tasks which must be performed to complete the program. Note I am using task in the non-technical sense of something that needs to be done. The first model we will look at is the single-threaded synchronous model, in Figure 1 below: Figure 1: The single-threaded synchronous model This is the simplest style of programming. Each task is performed one at a time, with one finishing completely before another is started. And if the tasks are always performed in a definite order, the imple- mentation of a later task can assume that all earlier tasks have finished without errors, with all their output available for use — a definite simplification in logic. We can contrast the single-threaded synchronous model with the multi-threaded synchronous model illustrated in Figure 2. In this model, each task is performed in a separate thread of control. The threads are managed by the operating system and may, on a system with multiple processors or multiple cores, run truly concurrently, 1http://krondo.com/?page_id=1327 1 CS168 Async Programming Figure 2: The threaded model or may be interleaved together on a single processor. -

Thread Scheduling in Multi-Core Operating Systems Redha Gouicem
Thread Scheduling in Multi-core Operating Systems Redha Gouicem To cite this version: Redha Gouicem. Thread Scheduling in Multi-core Operating Systems. Computer Science [cs]. Sor- bonne Université, 2020. English. tel-02977242 HAL Id: tel-02977242 https://hal.archives-ouvertes.fr/tel-02977242 Submitted on 24 Oct 2020 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Ph.D thesis in Computer Science Thread Scheduling in Multi-core Operating Systems How to Understand, Improve and Fix your Scheduler Redha GOUICEM Sorbonne Université Laboratoire d’Informatique de Paris 6 Inria Whisper Team PH.D.DEFENSE: 23 October 2020, Paris, France JURYMEMBERS: Mr. Pascal Felber, Full Professor, Université de Neuchâtel Reviewer Mr. Vivien Quéma, Full Professor, Grenoble INP (ENSIMAG) Reviewer Mr. Rachid Guerraoui, Full Professor, École Polytechnique Fédérale de Lausanne Examiner Ms. Karine Heydemann, Associate Professor, Sorbonne Université Examiner Mr. Etienne Rivière, Full Professor, University of Louvain Examiner Mr. Gilles Muller, Senior Research Scientist, Inria Advisor Mr. Julien Sopena, Associate Professor, Sorbonne Université Advisor ABSTRACT In this thesis, we address the problem of schedulers for multi-core architectures from several perspectives: design (simplicity and correct- ness), performance improvement and the development of application- specific schedulers. -

Comparison of Concurrency Frameworks for the Java Virtual Machine
Universität Ulm Fakultät für Ingenieurwissenschaften und Informatik Institut für Verteilte Systeme, Bachelorarbeit im Studiengang Informatik Comparison of Concurrency Frameworks for the Java Virtual Machine Thomas Georg Kühner vorgelegt am 25. Oktober 2013 VS-B13-2013 Gutachter Prof. Dr. Frank Kargl Fassung vom: December 8, 2013 cbnd Diese Arbeit ist lizensiert unter der Creative Commons Namensnennung-Keine kommerzielle Nutzung-Keine Bearbeitung 3.0 Deutschland Lizenz. Nähere Informationen finden Sie unter: http://creativecommons.org/licenses/by-nc-nd/3.0/de/ oder senden Sie einen Brief an: Creative Commons, 171 Second Street, Suite 300, San Francisco, California, 94105, USA. Contents 1. Introduction 1 1.1. Motivation..........................................1 1.2. Scope of this Thesis.....................................2 1.3. Methodology........................................2 1.4. Road Map for this thesis..................................2 2. Basics and Background about Concurrency and Concurrent Programming3 2.1. Terminology.........................................3 2.2. Small History of Concurrency Theory..........................5 2.3. General Programming Models for Concurrency....................6 2.4. Traditional Concurrency Issues..............................7 2.4.1. Race Condition...................................7 2.4.2. Dead-Lock......................................8 2.4.3. Starvation......................................8 2.4.4. Priority Inversion..................................9 2.5. Summary...........................................9 -

Qcontext, and Supporting Multiple Event Loop Threads in QEMU
IBM Linux Technology Center QContext, and Supporting Multiple Event Loop Threads in QEMU Michael Roth [email protected] © 2006 IBM Corporation IBM Linux Technology Center QEMU Threading Model Overview . Historically (earlier this year), there were 2 main types of threads in QEMU: . vcpu threads – handle execution of guest code, and emulation of hardware access (pio/mmio) and other trapped instructions . QEMU main loop (iothread) – everything else (mostly) GTK/SDL/VNC UIs QMP/HMP management interfaces Clock updates/timer callbacks for devices device I/O on behalf of vcpus © 2006 IBM Corporation IBM Linux Technology Center QEMU Threading Model Overview . All core qemu code protected by global mutex . vcpu threads in KVM_RUN can run concurrently thanks to address space isolation, but attempt to acquire global mutex immediately after an exit . Iothread requires global mutex whenever it's active © 2006 IBM Corporation IBM Linux Technology Center High contention as threads or I/O scale vcpu 1 vcpu 2 vcpu n iothread . © 2006 IBM Corporation IBM Linux Technology Center QEMU Thread Types . vcpu threads . iothread . virtio-blk-dataplane thread Drives a per-device AioContext via aio_poll Handles event fd callbacks for virtio-blk virtqueue notifications and linux_aio completions Uses port of vhost's vring code, doesn't (currently) use core QEMU code, doesn't require global mutex Will eventually re-use QEMU block layer code © 2006 IBM Corporation IBM Linux Technology Center QEMU Block Layer Features . Multiple image format support . Snapshots . Live Block Copy . Live Block migration . Drive-mirroring . Disk I/O limits . Etc... © 2006 IBM Corporation IBM Linux Technology Center More dataplane in the future . -

The Design and Use of the ACE Reactor an Object-Oriented Framework for Event Demultiplexing
The Design and Use of the ACE Reactor An Object-Oriented Framework for Event Demultiplexing Douglas C. Schmidt and Irfan Pyarali g fschmidt,irfan @cs.wustl.edu Department of Computer Science Washington University, St. Louis 631301 1 Introduction create concrete event handlers by inheriting from the ACE Event Handler base class. This class specifies vir- This article describes the design and implementation of the tual methods that handle various types of events, such as Reactor pattern [1] contained in the ACE framework [2]. The I/O events, timer events, signals, and synchronization events. Reactor pattern handles service requests that are delivered Applications that use the Reactor framework create concrete concurrently to an application by one or more clients. Each event handlers and register them with the ACE Reactor. service of the application is implemented by a separate event Figure 1 shows the key components in the ACE Reactor. handler that contains one or more methods responsible for This figure depicts concrete event handlers that implement processing service-specific requests. In the implementation of the Reactor pattern described in this paper, event handler dispatching is performed REGISTERED 2: accept() by an ACE Reactor.TheACE Reactor combines OBJECTS 5: recv(request) 3: make_handler() the demultiplexing of input and output (I/O) events with 6: process(request) other types of events, such as timers and signals. At Logging Logging Logging Logging Handler Acceptor LEVEL thecoreoftheACE Reactor implementation is a syn- LEVEL Handler Handler chronous event demultiplexer, such as select [3] or APPLICATION APPLICATION Event Event WaitForMultipleObjects [4]. When the demulti- Event Event Handler Handler Handler plexer indicates the occurrence of designated events, the Handler ACE Reactor automatically dispatches the method(s) of 4: handle_input() 1: handle_input() pre-registered event handlers, which perform application- specified services in response to the events.