SCALABILITY of SEMANTIC ANALYSIS in NATURAL LANGUAGE PROCESSING Rndr. Radim ˇreh˚Urek Ph.D. Thesis Faculty of Informatics Masa
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Probabilistic Topic Modelling with Semantic Graph
Probabilistic Topic Modelling with Semantic Graph B Long Chen( ), Joemon M. Jose, Haitao Yu, Fajie Yuan, and Huaizhi Zhang School of Computing Science, University of Glasgow, Sir Alwyns Building, Glasgow, UK [email protected] Abstract. In this paper we propose a novel framework, topic model with semantic graph (TMSG), which couples topic model with the rich knowledge from DBpedia. To begin with, we extract the disambiguated entities from the document collection using a document entity linking system, i.e., DBpedia Spotlight, from which two types of entity graphs are created from DBpedia to capture local and global contextual knowl- edge, respectively. Given the semantic graph representation of the docu- ments, we propagate the inherent topic-document distribution with the disambiguated entities of the semantic graphs. Experiments conducted on two real-world datasets show that TMSG can significantly outperform the state-of-the-art techniques, namely, author-topic Model (ATM) and topic model with biased propagation (TMBP). Keywords: Topic model · Semantic graph · DBpedia 1 Introduction Topic models, such as Probabilistic Latent Semantic Analysis (PLSA) [7]and Latent Dirichlet Analysis (LDA) [2], have been remarkably successful in ana- lyzing textual content. Specifically, each document in a document collection is represented as random mixtures over latent topics, where each topic is character- ized by a distribution over words. Such a paradigm is widely applied in various areas of text mining. In view of the fact that the information used by these mod- els are limited to document collection itself, some recent progress have been made on incorporating external resources, such as time [8], geographic location [12], and authorship [15], into topic models. -

Employee Matching Using Machine Learning Methods
Master of Science in Computer Science May 2019 Employee Matching Using Machine Learning Methods Sumeesha Marakani Faculty of Computing, Blekinge Institute of Technology, 371 79 Karlskrona, Sweden This thesis is submitted to the Faculty of Computing at Blekinge Institute of Technology in partial fulfillment of the requirements for the degree of Master of Science in Computer Science. The thesis is equivalent to 20 weeks of full time studies. The authors declare that they are the sole authors of this thesis and that they have not used any sources other than those listed in the bibliography and identified as references. They further declare that they have not submitted this thesis at any other institution to obtain a degree. Contact Information: Author(s): Sumeesha Marakani E-mail: [email protected] University advisor: Prof. Veselka Boeva Department of Computer Science External advisors: Lars Tornberg [email protected] Daniel Lundgren [email protected] Faculty of Computing Internet : www.bth.se Blekinge Institute of Technology Phone : +46 455 38 50 00 SE–371 79 Karlskrona, Sweden Fax : +46 455 38 50 57 Abstract Background. Expertise retrieval is an information retrieval technique that focuses on techniques to identify the most suitable ’expert’ for a task from a list of individ- uals. Objectives. This master thesis is a collaboration with Volvo Cars to attempt ap- plying this concept and match employees based on information that was extracted from an internal tool of the company. In this tool, the employees describe themselves in free flowing text. This text is extracted from the tool and analyzed using Natural Language Processing (NLP) techniques. -
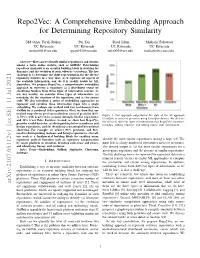
A Comprehensive Embedding Approach for Determining Repository Similarity
Repo2Vec: A Comprehensive Embedding Approach for Determining Repository Similarity Md Omar Faruk Rokon Pei Yan Risul Islam Michalis Faloutsos UC Riverside UC Riverside UC Riverside UC Riverside [email protected] [email protected] [email protected] [email protected] Abstract—How can we identify similar repositories and clusters among a large online archive, such as GitHub? Determining repository similarity is an essential building block in studying the dynamics and the evolution of such software ecosystems. The key challenge is to determine the right representation for the diverse repository features in a way that: (a) it captures all aspects of the available information, and (b) it is readily usable by ML algorithms. We propose Repo2Vec, a comprehensive embedding approach to represent a repository as a distributed vector by combining features from three types of information sources. As our key novelty, we consider three types of information: (a) metadata, (b) the structure of the repository, and (c) the source code. We also introduce a series of embedding approaches to represent and combine these information types into a single embedding. We evaluate our method with two real datasets from GitHub for a combined 1013 repositories. First, we show that our method outperforms previous methods in terms of precision (93% Figure 1: Our approach outperforms the state of the art approach vs 78%), with nearly twice as many Strongly Similar repositories CrossSim in terms of precision using CrossSim dataset. We also see and 30% fewer False Positives. Second, we show how Repo2Vec the effect of different types of information that Repo2Vec considers: provides a solid basis for: (a) distinguishing between malware and metadata, adding structure, and adding source code information. -

Matrix Decompositions and Latent Semantic Indexing
Online edition (c)2009 Cambridge UP DRAFT! © April 1, 2009 Cambridge University Press. Feedback welcome. 403 Matrix decompositions and latent 18 semantic indexing On page 123 we introduced the notion of a term-document matrix: an M N matrix C, each of whose rows represents a term and each of whose column× s represents a document in the collection. Even for a collection of modest size, the term-document matrix C is likely to have several tens of thousands of rows and columns. In Section 18.1.1 we first develop a class of operations from linear algebra, known as matrix decomposition. In Section 18.2 we use a special form of matrix decomposition to construct a low-rank approximation to the term-document matrix. In Section 18.3 we examine the application of such low-rank approximations to indexing and retrieving documents, a technique referred to as latent semantic indexing. While latent semantic in- dexing has not been established as a significant force in scoring and ranking for information retrieval, it remains an intriguing approach to clustering in a number of domains including for collections of text documents (Section 16.6, page 372). Understanding its full potential remains an area of active research. Readers who do not require a refresher on linear algebra may skip Sec- tion 18.1, although Example 18.1 is especially recommended as it highlights a property of eigenvalues that we exploit later in the chapter. 18.1 Linear algebra review We briefly review some necessary background in linear algebra. Let C be an M N matrix with real-valued entries; for a term-document matrix, all × RANK entries are in fact non-negative. -

Latent Semantic Analysis for Text-Based Research
Behavior Research Methods, Instruments, & Computers 1996, 28 (2), 197-202 ANALYSIS OF SEMANTIC AND CLINICAL DATA Chaired by Matthew S. McGlone, Lafayette College Latent semantic analysis for text-based research PETER W. FOLTZ New Mexico State University, Las Cruces, New Mexico Latent semantic analysis (LSA) is a statistical model of word usage that permits comparisons of se mantic similarity between pieces of textual information. This papersummarizes three experiments that illustrate how LSA may be used in text-based research. Two experiments describe methods for ana lyzinga subject's essay for determining from what text a subject learned the information and for grad ing the quality of information cited in the essay. The third experiment describes using LSAto measure the coherence and comprehensibility of texts. One of the primary goals in text-comprehension re A theoretical approach to studying text comprehen search is to understand what factors influence a reader's sion has been to develop cognitive models ofthe reader's ability to extract and retain information from textual ma representation ofthe text (e.g., Kintsch, 1988; van Dijk terial. The typical approach in text-comprehension re & Kintsch, 1983). In such a model, semantic information search is to have subjects read textual material and then from both the text and the reader's summary are repre have them produce some form of summary, such as an sented as sets ofsemantic components called propositions. swering questions or writing an essay. This summary per Typically, each clause in a text is represented by a single mits the experimenter to determine what information the proposition. -

Practice with Python
CSI4108-01 ARTIFICIAL INTELLIGENCE 1 Word Embedding / Text Processing Practice with Python 2018. 5. 11. Lee, Gyeongbok Practice with Python 2 Contents • Word Embedding – Libraries: gensim, fastText – Embedding alignment (with two languages) • Text/Language Processing – POS Tagging with NLTK/koNLPy – Text similarity (jellyfish) Practice with Python 3 Gensim • Open-source vector space modeling and topic modeling toolkit implemented in Python – designed to handle large text collections, using data streaming and efficient incremental algorithms – Usually used to make word vector from corpus • Tutorial is available here: – https://github.com/RaRe-Technologies/gensim/blob/develop/tutorials.md#tutorials – https://rare-technologies.com/word2vec-tutorial/ • Install – pip install gensim Practice with Python 4 Gensim for Word Embedding • Logging • Input Data: list of word’s list – Example: I have a car , I like the cat → – For list of the sentences, you can make this by: Practice with Python 5 Gensim for Word Embedding • If your data is already preprocessed… – One sentence per line, separated by whitespace → LineSentence (just load the file) – Try with this: • http://an.yonsei.ac.kr/corpus/example_corpus.txt From https://radimrehurek.com/gensim/models/word2vec.html Practice with Python 6 Gensim for Word Embedding • If the input is in multiple files or file size is large: – Use custom iterator and yield From https://rare-technologies.com/word2vec-tutorial/ Practice with Python 7 Gensim for Word Embedding • gensim.models.Word2Vec Parameters – min_count: -

How Latent Is Latent Semantic Analysis?
How Latent is Latent Semantic Analysis? Peter Wiemer-Hastings University of Memphis Department of Psychology Campus Box 526400 Memphis TN 38152-6400 [email protected]* Abstract In the late 1980's, a group at Bellcore doing re- search on information retrieval techniques developed a Latent Semantic Analysis (LSA) is a statisti• statistical, corpus-based method for retrieving texts. cal, corpus-based text comparison mechanism Unlike the simple techniques which rely on weighted that was originally developed for the task of matches of keywords in the texts and queries, their information retrieval, but in recent years has method, called Latent Semantic Analysis (LSA), cre• produced remarkably human-like abilities in a ated a high-dimensional, spatial representation of a cor• variety of language tasks. LSA has taken the pus and allowed texts to be compared geometrically. Test of English as a Foreign Language and per• In the last few years, several researchers have applied formed as well as non-native English speakers this technique to a variety of tasks including the syn• who were successful college applicants. It has onym section of the Test of English as a Foreign Lan• shown an ability to learn words at a rate sim• guage [Landauer et al., 1997], general lexical acquisi• ilar to humans. It has even graded papers as tion from text [Landauer and Dumais, 1997], selecting reliably as human graders. We have used LSA texts for students to read [Wolfe et al., 1998], judging as a mechanism for evaluating the quality of the coherence of student essays [Foltz et a/., 1998], and student responses in an intelligent tutoring sys• the evaluation of student contributions in an intelligent tem, and its performance equals that of human tutoring environment [Wiemer-Hastings et al., 1998; raters with intermediate domain knowledge. -

Navigating Dbpedia by Topic Tanguy Raynaud, Julien Subercaze, Delphine Boucard, Vincent Battu, Frederique Laforest
Fouilla: Navigating DBpedia by Topic Tanguy Raynaud, Julien Subercaze, Delphine Boucard, Vincent Battu, Frederique Laforest To cite this version: Tanguy Raynaud, Julien Subercaze, Delphine Boucard, Vincent Battu, Frederique Laforest. Fouilla: Navigating DBpedia by Topic. CIKM 2018, Oct 2018, Turin, Italy. hal-01860672 HAL Id: hal-01860672 https://hal.archives-ouvertes.fr/hal-01860672 Submitted on 23 Aug 2018 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Fouilla: Navigating DBpedia by Topic Tanguy Raynaud, Julien Subercaze, Delphine Boucard, Vincent Battu, Frédérique Laforest Univ Lyon, UJM Saint-Etienne, CNRS, Laboratoire Hubert Curien UMR 5516 Saint-Etienne, France [email protected] ABSTRACT only the triples that concern this topic. For example, a user is inter- Navigating large knowledge bases made of billions of triples is very ested in Italy through the prism of Sports while another through the challenging. In this demonstration, we showcase Fouilla, a topical prism of Word War II. For each of these topics, the relevant triples Knowledge Base browser that offers a seamless navigational expe- of the Italy entity differ. In such circumstances, faceted browsing rience of DBpedia. We propose an original approach that leverages offers no solution to retrieve the entities relative to a defined topic both structural and semantic contents of Wikipedia to enable a if the knowledge graph does not explicitly contain an adequate topic-oriented filter on DBpedia entities. -

Document and Topic Models: Plsa
10/4/2018 Document and Topic Models: pLSA and LDA Andrew Levandoski and Jonathan Lobo CS 3750 Advanced Topics in Machine Learning 2 October 2018 Outline • Topic Models • pLSA • LSA • Model • Fitting via EM • pHITS: link analysis • LDA • Dirichlet distribution • Generative process • Model • Geometric Interpretation • Inference 2 1 10/4/2018 Topic Models: Visual Representation Topic proportions and Topics Documents assignments 3 Topic Models: Importance • For a given corpus, we learn two things: 1. Topic: from full vocabulary set, we learn important subsets 2. Topic proportion: we learn what each document is about • This can be viewed as a form of dimensionality reduction • From large vocabulary set, extract basis vectors (topics) • Represent document in topic space (topic proportions) 푁 퐾 • Dimensionality is reduced from 푤푖 ∈ ℤ푉 to 휃 ∈ ℝ • Topic proportion is useful for several applications including document classification, discovery of semantic structures, sentiment analysis, object localization in images, etc. 4 2 10/4/2018 Topic Models: Terminology • Document Model • Word: element in a vocabulary set • Document: collection of words • Corpus: collection of documents • Topic Model • Topic: collection of words (subset of vocabulary) • Document is represented by (latent) mixture of topics • 푝 푤 푑 = 푝 푤 푧 푝(푧|푑) (푧 : topic) • Note: document is a collection of words (not a sequence) • ‘Bag of words’ assumption • In probability, we call this the exchangeability assumption • 푝 푤1, … , 푤푁 = 푝(푤휎 1 , … , 푤휎 푁 ) (휎: permutation) 5 Topic Models: Terminology (cont’d) • Represent each document as a vector space • A word is an item from a vocabulary indexed by {1, … , 푉}. We represent words using unit‐basis vectors. -

Gensim Is Robust in Nature and Has Been in Use in Various Systems by Various People As Well As Organisations for Over 4 Years
Gensim i Gensim About the Tutorial Gensim = “Generate Similar” is a popular open source natural language processing library used for unsupervised topic modeling. It uses top academic models and modern statistical machine learning to perform various complex tasks such as Building document or word vectors, Corpora, performing topic identification, performing document comparison (retrieving semantically similar documents), analysing plain-text documents for semantic structure. Audience This tutorial will be useful for graduates, post-graduates, and research students who either have an interest in Natural Language Processing (NLP), Topic Modeling or have these subjects as a part of their curriculum. The reader can be a beginner or an advanced learner. Prerequisites The reader must have basic knowledge about NLP and should also be aware of Python programming concepts. Copyright & Disclaimer Copyright 2020 by Tutorials Point (I) Pvt. Ltd. All the content and graphics published in this e-book are the property of Tutorials Point (I) Pvt. Ltd. The user of this e-book is prohibited to reuse, retain, copy, distribute or republish any contents or a part of contents of this e-book in any manner without written consent of the publisher. We strive to update the contents of our website and tutorials as timely and as precisely as possible, however, the contents may contain inaccuracies or errors. Tutorials Point (I) Pvt. Ltd. provides no guarantee regarding the accuracy, timeliness or completeness of our website or its contents including this tutorial. If you discover any errors on our website or in this tutorial, please notify us at [email protected] ii Gensim Table of Contents About the Tutorial .......................................................................................................................................... -

Software Framework for Topic Modelling with Large
Software Framework for Topic Modelling Radim Řehůřek and Petr Sojka NLP Centre, Faculty of Informatics, Masaryk University, Brno, Czech Republic {xrehurek,sojka}@fi.muni.cz http://nlp.fi.muni.cz/projekty/gensim/ the available RAM, in accordance with While an intuitive interface is impor- Although evaluation of the quality of NLP Framework for VSM the current trends in NLP (see e.g. [3]). tant for software adoption, it is of course the obtained similarities is not the subject rather trivial and useless in itself. We have of this paper, it is of course of utmost Large corpora are ubiquitous in today’s Intuitive API. We wish to minimise the therefore implemented some of the popular practical importance. Here we note that it world and memory quickly becomes the lim- number of method names and interfaces VSM methods, Latent Semantic Analysis, is notoriously hard to evaluate the quality, iting factor in practical applications of the that need to be memorised in order to LSA and Latent Dirichlet Allocation, LDA. as even the preferences of different types Vector Space Model (VSM). In this paper, use the package. The terminology is The framework is heavily documented of similarity are subjective (match of main we identify a gap in existing implementa- NLP-centric. and is available from http://nlp.fi. topic, or subdomain, or specific wording/- tions of many of the popular algorithms, Easy deployment. The package should muni.cz/projekty/gensim/. This plagiarism) and depends on the motivation which is their scalability and ease of use. work out-of-the-box on all major plat- website contains sections which describe of the reader. -

Word2vec and Beyond Presented by Eleni Triantafillou
Word2vec and beyond presented by Eleni Triantafillou March 1, 2016 The Big Picture There is a long history of word representations I Techniques from information retrieval: Latent Semantic Analysis (LSA) I Self-Organizing Maps (SOM) I Distributional count-based methods I Neural Language Models Important take-aways: 1. Don't need deep models to get good embeddings 2. Count-based models and neural net predictive models are not qualitatively different source: http://gavagai.se/blog/2015/09/30/a-brief-history-of-word-embeddings/ Continuous Word Representations I Contrast with simple n-gram models (words as atomic units) I Simple models have the potential to perform very well... I ... if we had enough data I Need more complicated models I Continuous representations take better advantage of data by modelling the similarity between the words Continuous Representations source: http://www.codeproject.com/Tips/788739/Visualization-of- High-Dimensional-Data-using-t-SNE Skip Gram I Learn to predict surrounding words I Use a large training corpus to maximize: T 1 X X log p(w jw ) T t+j t t=1 −c≤j≤c; j6=0 where: I T: training set size I c: context size I wj : vector representation of the jth word Skip Gram: Think of it as a Neural Network Learn W and W' in order to maximize previous objective Output layer y1,j W'N×V Input layer Hidden layer y2,j xk WV×N hi W'N×V N-dim V-dim W'N×V yC,j C×V-dim source: "word2vec parameter learning explained." ([4]) CBOW Input layer x1k WV×N Output layer Hidden layer x W W' 2k V×N hi N×V yj N-dim V-dim WV×N xCk C×V-dim source: