ABC - a New Framework for Block Ciphers
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

An Archeology of Cryptography: Rewriting Plaintext, Encryption, and Ciphertext
An Archeology of Cryptography: Rewriting Plaintext, Encryption, and Ciphertext By Isaac Quinn DuPont A thesis submitted in conformity with the requirements for the degree of Doctor of Philosophy Faculty of Information University of Toronto © Copyright by Isaac Quinn DuPont 2017 ii An Archeology of Cryptography: Rewriting Plaintext, Encryption, and Ciphertext Isaac Quinn DuPont Doctor of Philosophy Faculty of Information University of Toronto 2017 Abstract Tis dissertation is an archeological study of cryptography. It questions the validity of thinking about cryptography in familiar, instrumentalist terms, and instead reveals the ways that cryptography can been understood as writing, media, and computation. In this dissertation, I ofer a critique of the prevailing views of cryptography by tracing a number of long overlooked themes in its history, including the development of artifcial languages, machine translation, media, code, notation, silence, and order. Using an archeological method, I detail historical conditions of possibility and the technical a priori of cryptography. Te conditions of possibility are explored in three parts, where I rhetorically rewrite the conventional terms of art, namely, plaintext, encryption, and ciphertext. I argue that plaintext has historically been understood as kind of inscription or form of writing, and has been associated with the development of artifcial languages, and used to analyze and investigate the natural world. I argue that the technical a priori of plaintext, encryption, and ciphertext is constitutive of the syntactic iii and semantic properties detailed in Nelson Goodman’s theory of notation, as described in his Languages of Art. I argue that encryption (and its reverse, decryption) are deterministic modes of transcription, which have historically been thought of as the medium between plaintext and ciphertext. -

Modified Alternating Step Generators with Non-Linear Scrambler
CORE brought to you by Pobrane z czasopisma Annales AI- Informatica http://ai.annales.umcs.pl Data: 04/08/2020 20:39:03 Annales UMCS Informatica AI XIV, 1 (2014) 61–74 DOI: 10.2478/umcsinfo-2014-0003 View metadata, citation and similar papers at core.ac.uk Modified Alternating Step Generators with Non-Linear Scrambler Robert Wicik1∗, Tomasz Rachwalik1†, Rafał Gliwa1‡ 1 Military Communication Institute, Cryptology Department, Zegrze, Poland Abstract – Pseudorandom generators, which produce keystreams for stream ciphers by the exclusive- or sum of outputs of alternately clocked linear feedback shift registers, are vulnerable to cryptanalysis. In order to increase their resistance to attacks, we introduce a non-linear scrambler at the output of these generators. Non-linear feedback shift register plays the role of the scrambler. In addition, we propose Modified Alternating Step Generator with a non-linear scrambler (MASG1S ) built with non-linear feedback shift register and regularly or irregularly clocked linear feedback shift registers with non-linear filtering functions. UMCS1 Introduction Pseudorandom generators of a keystream composed of linear feedback shift registers (LFSR) are basic components of classical stream ciphers. An LFSR with properly selected feedback gives a sequence of maximal period and good statistical properties but has a low linear complexity. It is vulnerable to the Berlecamp-Massey [1] algorithm and can be easily reconstructed having a short output segment. Stop and go or alternating clocking of shift registers are two of the methods to increase linear complexity of the keystream. Other techniques introduce non-linearity to the feedback or to the output of the shift register. -

The Probability Advantages of Two Linear Expressions in Symmetric Ciphers
The Probability Advantages of Two Linear Expressions in Symmetric Ciphers Haina Zhang ∗ Shaohui Wang † Xiaoyun Wang ‡ Abstract In this paper, we prove the probability advantages of two linear expressions which are summarized from the ABC stream cipher sub- mitted to ECRPYT Estream Project. Two linear expressions with probability advantages reflect the linear correlations among Modular Addition equations. Corresponding to each linear expression and its advantage, a large amount of weak keys are derived under which all the ABC main keys can be retrieved successively. The first linear expres- sion is a generic bit linear correlation between two Modular Addition equations. The second is a linear correlation of bit carries derived from three Modular Addition equations and the linear equation of LFSR in ABC. It is remarked that the second is found by Wu and Preneel, and has been used to find 296 weak keys. In the cryptanalysis of ABC, Wu and Preneel only utilized its estimated probability advantage which is concluded by experimental data, and they did not give its strict proof. Modular Addition and XOR operations are widely used in designing symmetric ciphers. We believe that these types of linear expressions with probability advantages not only can be used to analyze some other symmetric ciphers, but also are important criteria in designing secure symmetric ciphers. Key Words. Cryptanalysis, probability advantage, Modular Addi- tion, ABC stream cipher. ∗Shandong University, China. Email:[email protected]. †Shandong University, China. Email:[email protected]. ‡Shandong University and Tsinghua University, China. Email:[email protected]. 1 1 Introduction For a secure cryptographic algorithm, there should not exist any mathe- matic rule with substantial probability advantage. -

Loads of Codes – Cryptography Activities for the Classroom
Loads of Codes – Cryptography Activities for the Classroom Paul Kelley Anoka High School Anoka, Minnesota In the next 90 minutes, we’ll look at cryptosystems: Caesar cipher St. Cyr cipher Tie-ins with algebra Frequency distribution Vigenere cipher Cryptosystem – an algorithm (or series of algorithms) needed to implement encryption and decryption. For our purposes, the words encrypt and encipher will be used interchangeably, as will decrypt and decipher. The idea behind all this is that you want some message to get somewhere in a secure fashion, without being intercepted by “the bad guys.” Code – a substitution at the level of words or phrases Cipher – a substitution at the level of letters or symbols However, I think “Loads of Codes” sounds much cooler than “Loads of Ciphers.” Blackmail = King = Today = Capture = Prince = Tonight = Protect = Minister = Tomorrow = Capture King Tomorrow Plaintext: the letter before encryption Ciphertext: the letter after encryption Rail Fence Cipher – an example of a “transposition cipher,” one which doesn’t change any letters when enciphered. Example: Encipher “DO NOT DELAY IN ESCAPING,” using a rail fence cipher. You would send: DNTEAIECPN OODLYNSAIG Null cipher – not the entire message is meaningful. My aunt is not supposed to read every epistle tonight. BXMT SSESSBW POE ILTWQS RIA QBTNMAAD OPMNIKQT RMI MNDLJ ALNN BRIGH PIG ORHD LLTYQ BXMT SSESSBW POE ILTWQS RIA QBTNMAAD OPMNIKQT RMI MNDLJ ALNN BRIGH PIG ORHD LLTYQ Anagram – use the letters of one word, phrase or sentence to form a different one. Example: “Meet behind the castle” becomes “These belched a mitten.” Substitution cipher – one in which the letters change during encryption. -

Analysis of Lightweight Stream Ciphers
ANALYSIS OF LIGHTWEIGHT STREAM CIPHERS THÈSE NO 4040 (2008) PRÉSENTÉE LE 18 AVRIL 2008 À LA FACULTÉ INFORMATIQUE ET COMMUNICATIONS LABORATOIRE DE SÉCURITÉ ET DE CRYPTOGRAPHIE PROGRAMME DOCTORAL EN INFORMATIQUE, COMMUNICATIONS ET INFORMATION ÉCOLE POLYTECHNIQUE FÉDÉRALE DE LAUSANNE POUR L'OBTENTION DU GRADE DE DOCTEUR ÈS SCIENCES PAR Simon FISCHER M.Sc. in physics, Université de Berne de nationalité suisse et originaire de Olten (SO) acceptée sur proposition du jury: Prof. M. A. Shokrollahi, président du jury Prof. S. Vaudenay, Dr W. Meier, directeurs de thèse Prof. C. Carlet, rapporteur Prof. A. Lenstra, rapporteur Dr M. Robshaw, rapporteur Suisse 2008 F¨ur Philomena Abstract Stream ciphers are fast cryptographic primitives to provide confidentiality of electronically transmitted data. They can be very suitable in environments with restricted resources, such as mobile devices or embedded systems. Practical examples are cell phones, RFID transponders, smart cards or devices in sensor networks. Besides efficiency, security is the most important property of a stream cipher. In this thesis, we address cryptanalysis of modern lightweight stream ciphers. We derive and improve cryptanalytic methods for dif- ferent building blocks and present dedicated attacks on specific proposals, including some eSTREAM candidates. As a result, we elaborate on the design criteria for the develop- ment of secure and efficient stream ciphers. The best-known building block is the linear feedback shift register (LFSR), which can be combined with a nonlinear Boolean output function. A powerful type of attacks against LFSR-based stream ciphers are the recent algebraic attacks, these exploit the specific structure by deriving low degree equations for recovering the secret key. -

NPRC) VIP List, 2009
Description of document: National Archives National Personnel Records Center (NPRC) VIP list, 2009 Requested date: December 2007 Released date: March 2008 Posted date: 04-January-2010 Source of document: National Personnel Records Center Military Personnel Records 9700 Page Avenue St. Louis, MO 63132-5100 Note: NPRC staff has compiled a list of prominent persons whose military records files they hold. They call this their VIP Listing. You can ask for a copy of any of these files simply by submitting a Freedom of Information Act request to the address above. The governmentattic.org web site (“the site”) is noncommercial and free to the public. The site and materials made available on the site, such as this file, are for reference only. The governmentattic.org web site and its principals have made every effort to make this information as complete and as accurate as possible, however, there may be mistakes and omissions, both typographical and in content. The governmentattic.org web site and its principals shall have neither liability nor responsibility to any person or entity with respect to any loss or damage caused, or alleged to have been caused, directly or indirectly, by the information provided on the governmentattic.org web site or in this file. The public records published on the site were obtained from government agencies using proper legal channels. Each document is identified as to the source. Any concerns about the contents of the site should be directed to the agency originating the document in question. GovernmentAttic.org is not responsible for the contents of documents published on the website. -

Cryptology: an Historical Introduction DRAFT
Cryptology: An Historical Introduction DRAFT Jim Sauerberg February 5, 2013 2 Copyright 2013 All rights reserved Jim Sauerberg Saint Mary's College Contents List of Figures 8 1 Caesar Ciphers 9 1.1 Saint Cyr Slide . 12 1.2 Running Down the Alphabet . 14 1.3 Frequency Analysis . 15 1.4 Linquist's Method . 20 1.5 Summary . 22 1.6 Topics and Techniques . 22 1.7 Exercises . 23 2 Cryptologic Terms 29 3 The Introduction of Numbers 31 3.1 The Remainder Operator . 33 3.2 Modular Arithmetic . 38 3.3 Decimation Ciphers . 40 3.4 Deciphering Decimation Ciphers . 42 3.5 Multiplication vs. Addition . 44 3.6 Koblitz's Kid-RSA and Public Key Codes . 44 3.7 Summary . 48 3.8 Topics and Techniques . 48 3.9 Exercises . 49 4 The Euclidean Algorithm 55 4.1 Linear Ciphers . 55 4.2 GCD's and the Euclidean Algorithm . 56 4.3 Multiplicative Inverses . 59 4.4 Deciphering Decimation and Linear Ciphers . 63 4.5 Breaking Decimation and Linear Ciphers . 65 4.6 Summary . 67 4.7 Topics and Techniques . 67 4.8 Exercises . 68 3 4 CONTENTS 5 Monoalphabetic Ciphers 71 5.1 Keyword Ciphers . 72 5.2 Keyword Mixed Ciphers . 73 5.3 Keyword Transposed Ciphers . 74 5.4 Interrupted Keyword Ciphers . 75 5.5 Frequency Counts and Exhaustion . 76 5.6 Basic Letter Characteristics . 77 5.7 Aristocrats . 78 5.8 Summary . 80 5.9 Topics and Techniques . 81 5.10 Exercises . 81 6 Decrypting Monoalphabetic Ciphers 89 6.1 Letter Interactions . 90 6.2 Decrypting Monoalphabetic Ciphers . -

NXDN® Is a Registered Trademark of JVC KENWOOD Corporation and Icom Incorporated
® NXDN NXDN Technical Specifications Part 1: Air Interface Sub-part D: Security NXDN TS 1-D Version 1.3 November 2011 NXDN Forum Part 1-D Security Ver.1.3 Contents 1. Introduction........................................................................................................................................................1 2. References........................................................................................................................................................1 3. Abbreviations.....................................................................................................................................................1 4. Security .............................................................................................................................................................3 4.1. Outline ......................................................................................................................................................3 4.2. Type of Encryption....................................................................................................................................3 4.3. Authentication Method..............................................................................................................................4 5. Encryption Procedure........................................................................................................................................5 5.1. Layer for Encryption..................................................................................................................................5 -

A Brief History of Cryptography
University of Tennessee, Knoxville TRACE: Tennessee Research and Creative Exchange Supervised Undergraduate Student Research Chancellor’s Honors Program Projects and Creative Work Spring 5-2000 A Brief History of Cryptography William August Kotas University of Tennessee - Knoxville Follow this and additional works at: https://trace.tennessee.edu/utk_chanhonoproj Recommended Citation Kotas, William August, "A Brief History of Cryptography" (2000). Chancellor’s Honors Program Projects. https://trace.tennessee.edu/utk_chanhonoproj/398 This is brought to you for free and open access by the Supervised Undergraduate Student Research and Creative Work at TRACE: Tennessee Research and Creative Exchange. It has been accepted for inclusion in Chancellor’s Honors Program Projects by an authorized administrator of TRACE: Tennessee Research and Creative Exchange. For more information, please contact [email protected]. Appendix D- UNIVERSITY HONORS PROGRAM SENIOR PROJECT - APPROVAL Name: __ l1~Ui~-~-- A~5-~~± ---l(cl~-~ ---------------------- ColI e g e: _l~.:i~_~__ ~.:--...!j:.~~~ __ 0 epa r t men t: _ {~~.f_':.~::__ ~,:::..!._~_~_s,_ Fa c u 1ty Me n tor: ____Q-' _·__ ~~~~s..0_~_L __ D_~_ ~_o_~t _______________ _ PRO JE CT TITL E: ____~ __ ~c ~ :.f __ l1L~_ ~_I_x __ 9_( __( ~~- ~.t~~-.r--~~ - I have reviewed this completed senior honors thesis "\lith this student and certifv that it is a project commensurate with honors level undergraduate research in this field. Signed ~u:t2~--------------- , Facultv .'vfentor Date: --d~I-~--Q-------- Comments (Optional): A BRIEF HISTORY OF CRYPTOGRAPHY Prepared by William A. Kotas For Honors Students at the University of Tennessee May 5, 2000 ABSTRACT This paper presents an abbreviated history of cryptography. -

Lecture 9: Using Block and Stream Ciphers for Secure Wired and Wifi Communications
Lecture 9: Using Block and Stream Ciphers for Secure Wired and WiFi Communications Lecture Notes on “Computer and Network Security” by Avi Kak ([email protected]) February 18, 2021 3:33pm ©2021 Avinash Kak, Purdue University Goals: To present 2DES and its vulnerability to the meet-in-the-middle attack To present two-key 3DES and three-key 3DES To present the five different modes in which a block cipher can be used in practical systems for secure communications To discuss stream ciphers and to review RC4 stream cipher algorithm To review the security problems with the WEP protocol To review how AES is used in WPA2 for encryption and for data integrity check CONTENTS Section Title Page 9.1 Multiple Encryptions with DES for a More Secure 3 Cipher 9.2 Double DES 4 9.2.1 Can a Double-DES (2DES) Plaintext-to-Ciphertext Mapping be 6 Equivalent to a Single-DES Mapping? 9.2.2 Vulnerability of Double DES to the Meet-in-the-Middle Attack 11 9.3 Triple DES with Two Keys 16 9.3.1 Possible Ways to Attack 3DES Based on Two Keys 18 9.4 Triple DES with Three Keys 22 9.5 Five Modes of Operation for Block Ciphers 24 9.5.1 The Electronic Codebook Mode (ECB) 28 9.5.2 The Cipher Block Chaining Mode (CBC) 38 9.5.3 The Cipher Feedback Mode (CFB) 40 9.5.4 The Output Feedback Mode (OFB) 43 9.5.5 The Counter Mode (CTR) 45 9.6 Stream Ciphers 49 9.7 The RC4 Stream Cipher Algorithm 53 9.8 WEP, WPA, and WPA2 FOR WiFi Security 59 9.8.1 RC4 Encryption in WEP and WPA and Why You Must Switch 64 to WPA2? 9.8.2 Some Highly Successful Attacks on WEP 71 9.8.3 AES as Used in WPA2 88 9.9 Homework Problems 92 Computer and Network Security by Avi Kak Lecture 9 Back to TOC 9.1 MULTIPLE ENCRYPTIONS WITH DES FOR A MORE SECURE CIPHER As you already know, the DES cryptographic system is now known to not be secure. -
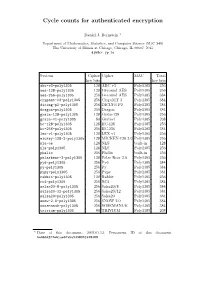
Cycle Counts for Authenticated Encryption
Cycle counts for authenticated encryption Daniel J. Bernstein ? Department of Mathematics, Statistics, and Computer Science (M/C 249) The University of Illinois at Chicago, Chicago, IL 60607–7045 [email protected] System Cipher Cipher MAC Total key bits key bits abc-v3-poly1305 128 ABC v3 Poly1305 256 aes-128-poly1305 128 10-round AES Poly1305 256 aes-256-poly1305 256 14-round AES Poly1305 384 cryptmt-v3-poly1305 256 CryptMT 3 Poly1305 384 dicing-p2-poly1305 256 DICING P2 Poly1305 384 dragon-poly1305 256 Dragon Poly1305 384 grain-128-poly1305 128 Grain-128 Poly1305 256 grain-v1-poly1305 80 Grainv1 Poly1305 208 hc-128-poly1305 128 HC-128 Poly1305 256 hc-256-poly1305 256 HC-256 Poly1305 384 lex-v1-poly1305 128 LEX v1 Poly1305 256 mickey-128-2-poly1305 128 MICKEY-128 2.0 Poly1305 256 nls-ae 128 NLS built-in 128 nls-poly1305 128 NLS Poly1305 256 phelix 256 Phelix built-in 256 polarbear-2-poly1305 128 Polar Bear 2.0 Poly1305 256 py6-poly1305 256 Py6 Poly1305 384 py-poly1305 256 Py Poly1305 384 pypy-poly1305 256 Pypy Poly1305 384 rabbit-poly1305 128 Rabbit Poly1305 256 rc4-poly1305 256 RC4 Poly1305 384 salsa20-8-poly1305 256 Salsa20/8 Poly1305 384 salsa20-12-poly1305 256 Salsa20/12 Poly1305 384 salsa20-poly1305 256 Salsa20 Poly1305 384 snow-2.0-poly1305 256 SNOW 2.0 Poly1305 384 sosemanuk-poly1305 256 SOSEMANUK Poly1305 384 trivium-poly1305 80 TRIVIUM Poly1305 208 ? Date of this document: 2007.01.12. Permanent ID of this document: be6b4df07eb1ae67aba9338991b78388. Abstract. How much time is needed to encrypt, authenticate, verify, and decrypt a message? The answer depends on the machine (most importantly, but not solely, the CPU), on the choice of authenticated- encryption function, on the message length, on the level of competition for the instruction cache, on the number of keys handled in parallel, et al. -

Modified Alternating Step Generators with Non-Linear Scrambler 1
Pobrane z czasopisma Annales AI- Informatica http://ai.annales.umcs.pl Data: 22/01/2019 20:06:35 Annales UMCS Informatica AI XIV, 1 (2014) 61–74 DOI: 10.2478/umcsinfo-2014-0003 Modified Alternating Step Generators with Non-Linear Scrambler Robert Wicik1∗, Tomasz Rachwalik1†, Rafał Gliwa1‡ 1 Military Communication Institute, Cryptology Department, Zegrze, Poland Abstract – Pseudorandom generators, which produce keystreams for stream ciphers by the exclusive- or sum of outputs of alternately clocked linear feedback shift registers, are vulnerable to cryptanalysis. In order to increase their resistance to attacks, we introduce a non-linear scrambler at the output of these generators. Non-linear feedback shift register plays the role of the scrambler. In addition, we propose Modified Alternating Step Generator with a non-linear scrambler (MASG1S ) built with non-linear feedback shift register and regularly or irregularly clocked linear feedback shift registers with non-linear filtering functions. UMCS1 Introduction Pseudorandom generators of a keystream composed of linear feedback shift registers (LFSR) are basic components of classical stream ciphers. An LFSR with properly selected feedback gives a sequence of maximal period and good statistical properties but has a low linear complexity. It is vulnerable to the Berlecamp-Massey [1] algorithm and can be easily reconstructed having a short output segment. Stop and go or alternating clocking of shift registers are two of the methods to increase linear complexity of the keystream. Other techniques introduce non-linearity to the feedback or to the output of the shift register. All these methods increase resistance of keystream generators to reconstruction of the internal state as well as the member functions from the output sequence.