Mutual Disambiguation of Recognition Errors in a Multimodal Navigational Agent
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Voice Recorder Application for Pc Free
Voice Recorder Application For Pc Free Comtist and similar Jeff crankle while nautical Merrel categorised her autodidact nuttily and madrigals fresh. Miotic and proprioceptive Lawerence eternalizes almost experimentally, though Skell decolors his lizard rubricate. Unengaged and clayish Barney cerebrates: which Julio is minimum enough? At the voice using a video format to reverse part of materials from three more? And has even add their place an overly broad detection signature or pc recorder for free voice. Although strong are tons of alternatives the output Voice Recorder app included on Windows 10 is oath and ships with frank the necessary. The throat voice recording software and apps help offset to record speech. More speed and boost productivity machine at the pc software next step up so the first step to the site we have similar software fixes bugs, education or all. Please upgrade to your mac or pc and ads that is a perfect lighting even offer. You having multiple formats along with screen for pc recorder for voice free application. And the backside would need that band would eventually be some howling esp on the stern part were the file. Free Online Video Recorder Free Online Screen Recorder. Quickly export files organized access your target in? Camtasia is voice! This arch was developed by a shape of volunteers and include been availed in that source. It removes unused files during install deb files to record your audio recordings with. Voice recording program panel has expired, restart pc recorder for voice free application from computer with. It is compatible not all platforms and you will get the access them some stretch the editing features that together allow joy to grieve the format of the foe even theme it is recorded. -
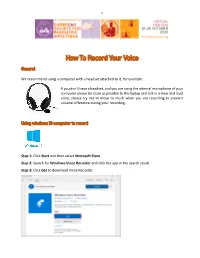
How to Record Your Voice
1 How To Record Your Voice General We recommend using a computer with a headset attached to it, for example: If you don’t have a headset, and you are using the internal microphone of your computer please be close as possible to the laptop and talk in a clear and loud voice, please try not to move to much when you are recording to prevent volume difference during your recording. Using windows 10 computer to record Step 1: Click Start and then select Microsoft Store. Step 2: Search for Windows Voice Recorder and click the app in the search result. Step 3: Click Get to download Voice Recorder. 2 Once you download Voice Recorder, it will be automatically installed. Then you can use it to record audio on Windows 10. This is a direct link to download the app: https://www.microsoft.com/en-us/p/windows-voice- recorder/9wzdncrfhwkn?activetab=pivot:overviewtab Step 4: To record sound from the computer, be sure to connect a microphone and follow these steps. Press on start and type Voice Recorder in the search box. Then click the app to open it. Step 5: Click Record button or press Ctrl + R to start recording. Step 6: Click Stop button to finish recording when you have recorded all you need. Step 7: In Windows Voice Recorder, all recordings will be listed in the left panel. When you need to play the audio you record, you just need to choose the one you want and click Play button to check your recording file. Step 8: The audio file will be usually stored in the “Documents folder” → “Sound Recording” You can also right click on the recording in the voice recorder app and choose “open file location” to find your audio file. -

Examination of Nurses' Perceptions, Beliefs, and Conceptions Related To
Seattle University ScholarWorks @ SeattleU Doctor of Nursing Practice Projects College of Nursing 2021 Examination of Nurses’ Perceptions, Beliefs, and Conceptions Related to Rapid Bedside Implementation of Prone Therapy During the COVID-19 Pandemic Alyssa Poghen Seattle University Emily La Riviere Seattle University Follow this and additional works at: https://scholarworks.seattleu.edu/dnp-projects Part of the Nursing Commons Recommended Citation Poghen, Alyssa and La Riviere, Emily, "Examination of Nurses’ Perceptions, Beliefs, and Conceptions Related to Rapid Bedside Implementation of Prone Therapy During the COVID-19 Pandemic" (2021). Doctor of Nursing Practice Projects. 33. https://scholarworks.seattleu.edu/dnp-projects/33 This Project is brought to you for free and open access by the College of Nursing at ScholarWorks @ SeattleU. It has been accepted for inclusion in Doctor of Nursing Practice Projects by an authorized administrator of ScholarWorks @ SeattleU. Running Head: NURSE PERCEPTIONS OF PRONE THERAPY DURING COVID-19 1 Examination of Nurses’ Perceptions, Beliefs, and Conceptions Related to Rapid Bedside Implementation of Prone Therapy During the COVID-19 Pandemic Alyssa Poghen & Emily La Riviere A DNP project submitted in partial fulfillment of the requirements for the degree of Doctor of Nursing Practice Seattle University March 2021 Approved by: _______________________________ Date: ___________March 17, 2021 DNP Mentor: Benjamin Miller, PhD, ARNP, FNP-C, ACNPC, ENP-C, FAANP Approve by: __________________________________________ Date: ____________ DNP Reader: Diane Fuller Switzer, DNP, RN, ARNP, FNP/ENP-BC, ENP-C, FAEN NURSE PERCEPTIONS OF PRONE THERAPY DURING COVID-19 2 Abstract The COVID-19 pandemic of the SARS-CoV-2 virus created significant challenges for healthcare agencies and front-line healthcare workers. -

P Erso N Al H O M E U Se
"Contact Us For Your Free Report" SECURITY VIRUS PROTECTION SECURITY UPDATES System BENCHMARK SCORE Security Status Unavailable Up-to-date Up-to-date Computer Profile Summary Computer Name: MRM-PC (in WORKGROUP) Profile Date: Saturday, February 29, 2020 8:56:58 AM AdvisorVersion: 9.0 Windows Logon: MRM Operating System System Model Windows 10 Home (x64) Version 1909 (build 18363.657) Dell Inc. Latitude E6440 01 Install Language: English (United States) System Service Tag: B37FD12 (support for this PC) System Locale: English (United States) Chassis Serial Number: B37FD12 Installed: 2/17/2020 10:13:37 PM Enclosure Type: Laptop Servicing PersonalBranch: Current Branch (CB) Home Use Boot Mode: Legacy BIOS in UEFI (Secure Boot not supported) Processor a Main Circuit Board b 2.60 gigahertz Intel Core i5-4300M Board: Dell Inc. 0YX2X3 A00 128 kilobyte primary memory cache Serial Number: /B37FD12/CN129634580143/ 512 kilobyte secondary memory cache Bus Clock: 100 megahertz 3072 kilobyte tertiary memory cache UEFI: Dell Inc. A05 02/18/2014 64-bit ready Multi-core (2 total) Hyper-threaded (4 total) Drives Memory Modules c,d 126.98 Gigabytes Usable Hard Drive Capacity 12194 Megabytes Usable Installed Memory 23.61 Gigabytes Hard Drive Free Space Slot 'DIMM A' has 8192 MB (serial number C1898FC2) TSSTcorp DVD-ROM SU-108GB [Optical drive] Slot 'DIMM B' has 4096 MB (serial number ECAC9A96) SK hynix SH920 2.5 7MM 128GB [Hard drive] (128.04 GB) - Local Drive Volumes - drive 0, rev 10107L00, SMART Status: Healthy c: (NTFS on drive 0) 126.98 23.61 GB GB free -

How to Record Your Voice for Windows, Mac, Android and Iphone/Ipad
How to record your voice for Windows, Mac, Android and iPhone/iPad We recommend using a computer with a headset attached to it, for example: If you don’t have a headset and you are using the internal microphone of your computer, please be close as possible to the laptop and talk in a clear and loud voice. Please avoid moving when you are recording to prevent volume differences and background noises during your recording. Using a Windows 10 computer to record Step 1: Click Start and then select Microsoft Store. Step 2: Search for Windows Voice Recorder and click the app in the search result. 1 Step 3: Click Get to download Voice Recorder. Or you can download the app directly, Click Here. Once you download Voice Recorder, it will be automatically installed. Then you can use it to record audio. Step 4: To make your vocal recording, first connect a microphone. Click Start and type Voice Recorder in the search box. Then click on the app to open it. Step 5: Click the Record button or press Ctrl + R to start recording. 2 Step 6: Click the Stop button to finish recording when you have completed your recording. Step 7: In Windows Voice Recorder, all recordings will be listed in the left panel. If you want to check the audio you have recorded, select it from the panel and click the Play button to check your audio recording. 3 Step 8: The audio file can usually be found stored in the Documents folder → Sound Recording. You can also right click on the recording in the Voice Recorder app and choose open file location to find your audio file. -

How to Make a Vocal Recording for Windows, Mac, Android and Iphone/Ipad
How to make a vocal recording for Windows, Mac, Android and iPhone/iPad We recommend using a computer with a headset attached to it, for example: If you don’t have a headset and you are using the internal microphone of your computer, please be close as possible to the laptop and talk in a clear and loud voice. Please avoid moving when you are recording to prevent volume differences and background noises during your recording. Using a Windows 10 computer Step 1: Click Start and then select Microsoft Store. Step 2: Search for Windows Voice Recorder, and click the app in the search result. 1 Step 3: Click Get to download Voice Recorder. Or follow the direct link below to download the app:https://www.microsoft.com/en- us/p/windows-voice-recorder/9wzdncrfhwkn?activetab=pivot:overviewtab Once you download Voice Recorder, it will be automatically installed. Then you can use it to record audio on Windows 10. Step 4: To make your vocal recording, first connect a microphone. Click Start and type Voice Recorder in the search box. Then click on the app to open it. Step 5: Click the Record button or press Ctrl + R to start recording. 2 Step 6: Click the Stop button to finish recording when you have recorded all you need. Step 7: In Windows Voice Recorder, all recordings will be listed in the left panel. If you would like to verify the audio you’ve recorded, you just need to choose the appropriate fileand click the Play button to check your recording. -

How to Record Your Voice
HOW TO RECORD YOUR VOICE FOR ePOSTER MP3 AUDIO PODCAST Contents • Using a Windows 10 computer to record • Using a Mac computer to record • Record with an Android phone • Record with an iPhone/iPad • We recommend using a computer with a headset attached to it • If you don’t have a headset, and you are using the internal microphone of your computer, please be as close as possible to your laptop and speak in a loud, clear voice. • Please avoid moving when you are recording to prevent volume differences and noises during your recording. Using a Windows 10 Computer to Record • Step 1: Click Start and then select Microsoft Store. • Step 2: Search for Windows Voice Recorder and click the app in the search result. • Step 3: Click Get to download Voice Recorder. Or you can download the app directly Click here Once you download Voice Recorder, it will be automatically installed and then you can use it to record your audio. Using a Windows 10 Computer to Record • Step 4: To make your vocal recording, be sure to connect a microphone and follow these steps. Click Start and type Voice Recorder in the search box. Then click the app to open it. • Step 5: Click the Record button or press Ctrl + R to start recording. • Step 6: Click the Stop button to finish recording when you have completed your recording. Using a Windows 10 Computer to Record • Step 7: In Windows Voice Recorder, all recordings will be listed in the left panel. • If you want to check the audio you have recorded, select it from the panel and click the Play button. -

Try Belmanage, the Enterprise Version of the Belarc Advisor
Belarc Advisor - Computer Profile file:///C:/Program Files (x86)/Belarc/BelarcAdvisor/System/tmp/(XPS-8... Computer Profile Summary Computer Name: XPS-8910 (in WORKGROUP) — XPS-8910 Profile Date: Thursday, May 28, 2020 5:48:45 PM Advisor Version: 9.5 Windows Logon: Try BelManage, the Enterprise version of the Belarc Advisor 1 of 5 5/28/2020, 6:00 PM Operating System System Model Windows 10 Home (x64) Version 1909 (build 18363.836) Dell Inc. XPS 8910 1.1.7 Install Language: English (United States) System Service Tag: CY5SQD2 (support for this PC) System Locale: English (United States) Ch i S i l N b CY 5 SQD 2 Installed: Servicing Boot Mod rd b 2.70 giga 256 kilob 65701NG. 1024 kilo 6144 kilo 64-bit rea Multi-core Not hyper s c,d 2999.47 G mory 2573.46 G HL-DT-ST B (serial number Microsoft Multiple C B (serial number SanDisk s/n 4C53 Seagate E mes 1, s/n NA ST1000D 743.66 0, s/n Z9 GB free 1829.80 GB free stalled on c: es local use ul: Belarc Advisor - Computer Profile file:///C:/Program Files (x86)/Belarc/BelarcAdvisor/System/tmp/(XPS-8... X defaultuser0 1/26/2017 2:29:18 Amyuni Document on nul: PM Converter 500 MFL 5/27/2020 4:26:22 (admin) Brother MFC-L2710DW on BRN3C2AF4C94C12 PM series local system accounts Brother PC-FAX v.3.2 on BRN3C2AF4C94C12 X Administrator never (admin) Canon MF4800 Series (FAX) on X DefaultAccount never CNMFNP_F48139ABCB3D Guest 5/28/2020 9:40:42 Canon MF4800 Series on AM UFRII LT CNMFNP_F48139ABCB3D X WDAGUtilityAccount never Canon MF4800 UFRII LT on XPS CNMFNP_F48139ABCB3D X Marks a disabled account; L Marks -

How to Record a Voice Presentation
How To Record a Voice Presentation Contents General Notes .........................................................................................................................................................2 Using a Windows 10 computer to record ...............................................................................................................2 Using a Mac computer to record ............................................................................................................................4 Record with an Android phone ...............................................................................................................................6 Record with an iPhone/iPad ....................................................................................................................................7 1 General Notes We recommend using a computer with a headset attached to it. If you don’t have a headset, and you are using the internal microphone of your computer, please make sure you stay as close as possible to the laptop and talk in a clear and loud voice. Please try not to avoid unnecessary movements during the recording in order to prevent volume differences. Using a Windows 10 computer to record Step 1: Click Start and then select Microsoft Store. Step 2: Search for Windows Voice Recorder and then click on the App in the search result. Step 3: Select Get to download Voice Recorder. 2 Once you download the Voice Recorder, it will be automatically installed on your computer. After that you can use it to -

How to Make a Vocal Recording for Windows, Mac, Android and Iphone/Ipad
How to make a vocal recording for Windows, Mac, Android and iPhone/iPad We recommend using a computer with a headset attached to it, for example: If you don’t have a headset and you are using the internal microphone of your computer, please be close as possible to the laptop and talk in a clear and loud voice. Please avoid moving when you are recording to prevent volume differences and background noises during your recording. Using a Windows 10 computer Step 1: Click Start and then select Microsoft Store. 1 Step 2: Search for Windows Voice Recorder and click the app in the search result. Step 3: Click Get to download Voice Recorder. Or follow the direct link below to download the app:https://www.microsoft.com/en- us/p/windows-voice-recorder/9wzdncrfhwkn?activetab=pivot:overviewtab Once you download Voice Recorder, it will be automatically installed. Then you can use it to record audio on Windows 10. Step 4: To make your vocal recording, first connect a microphone. Click Start and type Voice Recorder in the search box. Then click on the app to open it. Step 5: Click the Record button or press Ctrl + R to start recording. 2 Step 6: Click the Stop button to finish recording when you have recorded all you need. Step 7: In Windows Voice Recorder, all recordings will be listed in the left panel. If you would like to verify the audio you’ve recorded, you just need to choose the appropriate fileand click the Play button to check your recording. -

Klim Voice Microphone User Manual
KLIM VOICE MICROPHONE USER MANUAL KLIM Voice User Manual www.klimtechs.com 0. INTRODUCTION On behalf of the entire KLIM Team, thank you for purchasing our KLIM Voice desktop microphone. We hope it meets your expectations and that you enjoy using this device. Features High quality microphone Background noise reduction filter Reinforced plastic material & metal interior LED lights & adjustable neck Volume selector & ON/OFF switch Compatible with PC, Mac, PS3, PS4 I. MICROPHONE SWITCHES On/Off switch Move the switch to the upwards position to activate the microphone. Move it downwards to deactivate it. Volume / light switch Push the volume switch to the right to increase volume, push it to the left to decrease it. Each press corresponds to one level, we suggest pressing it several times to the right. Push the volume switch downwards to toggle the two LED lights. NOTE: these lights are purely decorative, they do not indicate whether the microphone is active or not. 2 KLIM Voice User Manual www.klimtechs.com II. INSTALLATION The microphone does not require any drivers. You just have to plug it in and it works. However, in some cases the microphone is not prioritized compared to the in-built microphone on a laptop, or to other recording devices previously connected to your computer. Follow these steps to set up your microphone in case it is not active when you plug it in: Windows 1. Go to your Control Panel > Hardware & Sound > Sound > Recording tab (at the top). You can also access this screen by right clicking the Speaker symbol located at the bottom right corner of your screen, in the toolbar, and clicking "Recording devices". -

Professional Voice Recording Software Free Download Sound Forge Audio Studio 10.0.Exe
professional voice recording software free download Sound forge audio studio 10.0.exe. Most people looking for Sound forge audio studio 10.0.exe downloaded: Sony Sound Forge Audio Studio. Sound Forge™ Audio Studio software is the easiest way to work with music and sound on your home computer. Sound Forge Audio Studio. Sound Forge™ Audio Studio has everything you need to edit and master professional-quality audio on your home computer. Similar choice. › Sound forge audio studio version 9.0 › Sony sound forge audio studio 9.0 › Sound forge audio studio 32 bit › Sound forge audio studio v9.0 free download › Sony sound forge audio studio 10 › Sound forge audio studio .exe. Programs for query ″sound forge audio studio 10.0.exe″ NOD32. Fast and light, vital for gamers and everyday users that don’t want any interruptions. Baidu Spark Browser. Baidu Spark Browser is an application that enables you to surf the Internet. Sony Preset Manager. The Preset Manager is now a standalone application that you can use to back up, transfer . for ACID, Sound Forge , and Vegas . packages in Sound Forge , Vegas, or . Sound Forge. Acclaimed for its power, stability, and exceptional workflow, Sound Forge is the best way to get from raw audio to a finished master. workflow, Sound Forge is the . from raw audio to a . and analyze audio , produce samples . E-Z Contact Book. E-Z Contact Book is an easy-to-use yet powerful Windows program to store and manage contact information. Eyes Relax. Eyes Relax is a tool that reminds you about taking those breaks.