High-Performance Graphics with Directx in Racket∗
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Interaction Between Web Browsers and Script Engines
IT 12 058 Examensarbete 45 hp November 2012 Interaction between web browsers and script engines Xiaoyu Zhuang Institutionen för informationsteknologi Department of Information Technology Abstract Interaction between web browser and the script engine Xiaoyu Zhuang Teknisk- naturvetenskaplig fakultet UTH-enheten Web browser plays an important part of internet experience and JavaScript is the most popular programming language as a client side script to build an active and Besöksadress: advance end user experience. The script engine which executes JavaScript needs to Ångströmlaboratoriet Lägerhyddsvägen 1 interact with web browser to get access to its DOM elements and other host objects. Hus 4, Plan 0 Browser from host side needs to initialize the script engine and dispatch script source code to the engine side. Postadress: This thesis studies the interaction between the script engine and its host browser. Box 536 751 21 Uppsala The shell where the engine address to make calls towards outside is called hosting layer. This report mainly discussed what operations could appear in this layer and Telefon: designed testing cases to validate if the browser is robust and reliable regarding 018 – 471 30 03 hosting operations. Telefax: 018 – 471 30 00 Hemsida: http://www.teknat.uu.se/student Handledare: Elena Boris Ämnesgranskare: Justin Pearson Examinator: Lisa Kaati IT 12 058 Tryckt av: Reprocentralen ITC Contents 1. Introduction................................................................................................................................ -

PDF Xpansion SDK Reference
PDF Xpansion SDK 12 Reference soft Xpansion GmbH & Co. KG ● Königsallee 45, 44789 Bochum [email protected] ● www.soft-xpansion.com TABLE OF CONTENTS INTRODUCTION ................................................................................................................................................................ 5 System Requirements ................................................................................................................................................... 6 Installation of SDK ........................................................................................................................................................ 6 Contents of SDK package ........................................................................................................................................ 6 Reference SDK libraries in Your Projects .................................................................................................................... 7 Replace Trial License ................................................................................................................................................ 8 Update of SDK Files ................................................................................................................................................. 8 SDK Samples................................................................................................................................................................ 9 Redistribution of PDF Xpansion .................................................................................................................................... -

MAXPRO Microsoft Windows Patches.Book
MAXPRO® VMS and NVR Approved Microsoft® Windows Patches Technical Notes MICROSOFT® WINDOWS PATCHES TESTED WITH MAXPRO®NVR AND MAXPRO®VMS Overview The purpose of this document is to identify the patches that have been delivered by Microsoft® Windows and which have been tested against the current shipping ver- sions of MAXPRO®NVR and MAXPRO®VMS with no adverse effects being observed. If you have questions concerning the information in this document, please contact Honeywell Technical Support. See the back cover for contact information. Windows Patches Tested with MAXPRO®NVR till the Month of: June, 2020 Windows Patches Tested with MAXPRO®VMS till the Month of: June, 2020 This document contains: Section See... • June - 2020- Microsoft® Windows Patches Tested with MAXPRO®NVR on page 5 Windows 10 (Enterprise) • June - 2020- Microsoft® Windows Patches Tested with MAXPRO®VMS Server/ Client on Windows 2016 Standard and Windows 10 (Enterprise) page 5 • May - 2020- Microsoft® Windows Patches Tested with MAXPRO®NVR on page 5 Windows 10 (Enterprise) • May - 2020- Microsoft® Windows Patches Tested with MAXPRO®VMS Server/ Client on Windows 2016 Standard and Windows 10 (Enterprise) page 5 • April - 2020- Microsoft® Windows Patches Tested with MAXPRO®VMS Server/ page 7 Client on Windows 2016 Standard and Windows 10 (Enterprise) • April - 2020- Microsoft® Windows Patches Tested with MAXPRO®NVR on Windows 10 (Enterprise) page 7 • March - 2020- Microsoft® Windows Patches Tested with MAXPRO®VMS Server/ page 8 Client on Windows 2016 Standard and Windows 10 (Enterprise) • March - 2020- Microsoft® Windows Patches Tested with MAXPRO®NVR on Windows 10 (Enterprise) page 8 • February - 2020- Microsoft® Windows Patches Tested with MAXPRO®VMS Server/ page 8 Client on Windows 2016 Standard and Windows 10 (Enterprise) • February - 2020- Microsoft® Windows Patches Tested with MAXPRO®NVR on Windows 10 (Enterprise) page 8 800-19154V9-K_Microsoft Windows Patches 1 Section See.. -
Advanced Computer Graphics to Do Motivation Real-Time Rendering
To Do Advanced Computer Graphics § Assignment 2 due Feb 19 § Should already be well on way. CSE 190 [Winter 2016], Lecture 12 § Contact us for difficulties etc. Ravi Ramamoorthi http://www.cs.ucsd.edu/~ravir Motivation Real-Time Rendering § Today, create photorealistic computer graphics § Goal: interactive rendering. Critical in many apps § Complex geometry, lighting, materials, shadows § Games, visualization, computer-aided design, … § Computer-generated movies/special effects (difficult or impossible to tell real from rendered…) § Until 10-15 years ago, focus on complex geometry § CSE 168 images from rendering competition (2011) § § But algorithms are very slow (hours to days) Chasm between interactivity, realism Evolution of 3D graphics rendering Offline 3D Graphics Rendering Interactive 3D graphics pipeline as in OpenGL Ray tracing, radiosity, photon mapping § Earliest SGI machines (Clark 82) to today § High realism (global illum, shadows, refraction, lighting,..) § Most of focus on more geometry, texture mapping § But historically very slow techniques § Some tweaks for realism (shadow mapping, accum. buffer) “So, while you and your children’s children are waiting for ray tracing to take over the world, what do you do in the meantime?” Real-Time Rendering SGI Reality Engine 93 (Kurt Akeley) Pictures courtesy Henrik Wann Jensen 1 New Trend: Acquired Data 15 years ago § Image-Based Rendering: Real/precomputed images as input § High quality rendering: ray tracing, global illumination § Little change in CSE 168 syllabus, from 2003 to -

Using the Component Object Model Interface
MQSeries for Windows NT V5R1 IBM Using the Component Object Model Interface SC34-5387-01 MQSeries for Windows NT V5R1 IBM Using the Component Object Model Interface SC34-5387-01 Note! Before using this information and the product it supports, be sure to read the general information under Appendix B, “Notices” on page 151. Second edition (April 1999) This edition applies to MQSeries for Windows NT V5.1 and to any subsequent releases and modifications until otherwise indicated in new editions. Copyright International Business Machines Corporation 1997,1999. All rights reserved. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents Contents About this book ..................................... v Who this book is for ................................... v MQSeries publications . vi MQSeries cross-platform publications ....................... vi MQSeries platform-specific publications ...................... ix MQSeries Level 1 product publications ....................... x Softcopy books . x MQSeries information available on the Internet .................. xii Where to find more information about ActiveX ................... xii Summary of changes ................................. xiii Changes for this edition ................................ xiii Chapter 1. Introduction . 1 MQSeries Automation Classes for ActiveX overview ................ 1 Chapter 2. Designing and programming using MQSeries Automation Classes for ActiveX .................................. 3 Designing -

(RUNTIME) a Salud Total
Windows 7 Developer Guide Published October 2008 For more information, press only: Rapid Response Team Waggener Edstrom Worldwide (503) 443-7070 [email protected] Downloaded from www.WillyDev.NET The information contained in this document represents the current view of Microsoft Corp. on the issues discussed as of the date of publication. Because Microsoft must respond to changing market conditions, it should not be interpreted to be a commitment on the part of Microsoft, and Microsoft cannot guarantee the accuracy of any information presented after the date of publication. This guide is for informational purposes only. MICROSOFT MAKES NO WARRANTIES, EXPRESS OR IMPLIED, IN THIS SUMMARY. Complying with all applicable copyright laws is the responsibility of the user. Without limiting the rights under copyright, no part of this document may be reproduced, stored in or introduced into a retrieval system, or transmitted in any form, by any means (electronic, mechanical, photocopying, recording or otherwise), or for any purpose, without the express written permission of Microsoft. Microsoft may have patents, patent applications, trademarks, copyrights or other intellectual property rights covering subject matter in this document. Except as expressly provided in any written license agreement from Microsoft, the furnishing of this document does not give you any license to these patents, trademarks, copyrights, or other intellectual property. Unless otherwise noted, the example companies, organizations, products, domain names, e-mail addresses, logos, people, places and events depicted herein are fictitious, and no association with any real company, organization, product, domain name, e-mail address, logo, person, place or event is intended or should be inferred. -
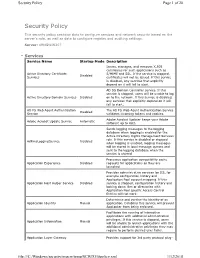
Security Policy Page 1 of 20
Security Policy Page 1 of 20 Security Policy This security policy contains data to configure services and network security based on the server’s role, as well as data to configure registry and auditing settings. Server: VENGWIN207 Services Service Name Startup Mode Description Issues, manages, and removes X.509 certificates for such applications such as Active Directory Certificate S/MIME and SSL. If the service is stopped, Disabled Services certificates will not be issued. If this service is disabled, any services that explicitly depend on it will fail to start. AD DS Domain Controller service. If this service is stopped, users will be unable to log Active Directory Domain Services Disabled on to the network. If this service is disabled, any services that explicitly depend on it will fail to start. AD FS Web Agent Authentication The AD FS Web Agent Authentication Service Disabled Service validates incoming tokens and cookies. Adobe Acrobat Updater keeps your Adobe Adobe Acrobat Update Service Automatic software up to date. Sends logging messages to the logging database when logging is enabled for the Active Directory Rights Management Services role. If this service is disabled or stopped AdRmsLoggingService Disabled when logging is enabled, logging messages will be stored in local message queues and sent to the logging database when the service is started. Processes application compatibility cache Application Experience Disabled requests for applications as they are launched Provides administrative services for IIS, for example configuration history and Application Pool account mapping. If this Application Host Helper Service Disabled service is stopped, configuration history and locking down files or directories with Application Pool specific Access Control Entries will not work. -

Sun Opengl 1.3 for Solaris Implementation and Performance Guide
Sun™ OpenGL 1.3 for Solaris™ Implementation and Performance Guide Sun Microsystems, Inc. www.sun.com Part No. 817-2997-11 November 2003, Revision A Submit comments about this document at: http://www.sun.com/hwdocs/feedback Copyright 2003 Sun Microsystems, Inc., 4150 Network Circle, Santa Clara, California 95054, U.S.A. All rights reserved. Sun Microsystems, Inc. has intellectual property rights relating to technology that is described in this document. In particular, and without limitation, these intellectual property rights may include one or more of the U.S. patents listed at http://www.sun.com/patents and one or more additional patents or pending patent applications in the U.S. and in other countries. This document and the product to which it pertains are distributed under licenses restricting their use, copying, distribution, and decompilation. No part of the product or of this document may be reproduced in any form by any means without prior written authorization of Sun and its licensors, if any. Third-party software, including font technology, is copyrighted and licensed from Sun suppliers. Parts of the product may be derived from Berkeley BSD systems, licensed from the University of California. UNIX is a registered trademark in the U.S. and in other countries, exclusively licensed through X/Open Company, Ltd. Sun, Sun Microsystems, the Sun logo, SunSoft, SunDocs, SunExpress, and Solaris are trademarks, registered trademarks, or service marks of Sun Microsystems, Inc. in the U.S. and other countries. All SPARC trademarks are used under license and are trademarks or registered trademarks of SPARC International, Inc. -

Summary Both the Desktop Graphics And
Summary Both the desktop graphics and animated film industries are striving to create spectacular, lifelike worlds. Film quality realism requires complicated per-pixel operations, previously impractical for desktop graphics which must render frames as fast as 60 times per second. The 3D Blaster GeForce2 GTS is the first Graphics Processing Unit (GPU) with the 3D performance and enhanced feature set necessary to approach this distinct level of realism. The 3D Blaster GeForce2 GTS is a State of the Art 3D Graphics Accelerator. The combination between Nvidia’s 2nd Generation Transform & Lighting (T&L) Architecture and the Nvidia Shading Rasterizer (NSR) produces one of the most stunning and realistic visuals ever seen on screen. The integrated NSR makes advanced per-pixel shading capabilities possible. This breakthrough technology has the ability to process seven pixel operations in a single pass on each of four pixel pipelines, simultaneously. The end result of this is to allow individual pixel control of colour, shadow, light, reflectivity, emissivity, specularity, loss, dirt, and other visual and material components used to create amazingly realistic objects and environments. Per-pixel shading delivers the next-generation of visual realism by going beyond the limited texture mapping techniques of previous graphics processors. • New HyperTexel architecture delivers 1.6 gigatexels per second for staggering frame rates and high- performance anti-aliasing • New NVIDIA Shading Rasterizer (NSR) delivers per pixel shading and lighting for rich, -

The Component Object Model Specification Version 0.9 October 24, 1995
http://scottge.wordpress.com The Component Object Model Specification Version 0.9 October 24, 1995 This document contains the specification to the Component Object Model (COM), an architecture and supporting infrastructure for building, using, and evolving component software in a robust manner. This specification contains the standard APIs supported by the COM Library, the standard suites of interfaces supported or used by software written in a COM environment, along with the network protocols used by COM in support of distributed computing. This specification is still in draft form, and thus subject to change. Note: This document is an early release of the final specification. It is meant to specify and accompany software that is still in development. Some of the information in this documentation may be inaccurate or may not be an accurate representation of the functionality of the final specification or software. Microsoft assumes no responsibility for any damages that might occur either directly or indirectly from these inaccuracies. Microsoft may have trademarks, copyrights, patents or pending patent applications, or other intellectual property rights covering subject matter in this document. The furnishing of this document does not give you a license to these trademarks, copyrights, patents, or other intellectual property rights. Copyright ? 1992-95 Microsoft Corporation. All Rights Reserved The Component Object Model Specification The Component Object Model The Component Object Model Specification Draft Version 0.9, October 24, 1995 Microsoft Corporation and Digital Equipment Corporation Copyright ? 1992-95 Microsoft Corporation. Microsoft does not make any representation or warranty regarding the Specification or any product or item developed based on the Specification. -

Beginning .NET Game Programming in En
Beginning .NET Game Programming in en DAVID WELLER, ALEXANDRE SANTOS LOBAo, AND ELLEN HATTON APress Media, LLC Beginning .NET Game Programming in C# Copyright @2004 by David Weller, Alexandre Santos Lobao, and Ellen Hatton Originally published by APress in 2004 All rights reserved. No part of this work may be reproduced or transmitted in any form or by any means, electronic or mechanical, including photocopying, recording, or by any information storage or retrieval system, without the prior written permission of the copyright owner and the publisher. ISBN 978-1-59059-319-6 ISBN 978-1-4302-0721-4 (eBook) DOI 10.1007/978-1-4302-0721-4 Trademarked names may appear in this book. Rather than use a trademark symbol with every occurrence of a trademarked name, we use the names only in an editorial fashion and to the benefit of the trademark owner, with no intention of infringement of the trademark. Technical Reviewers: Andrew Jenks, Kent Sharkey, Tom Miller Editorial Board: Steve Anglin, Dan Appleman, Gary Cornell, James Cox, Tony Davis, John Franklin, Chris Mills, Steve Rycroft, Dominic Shakeshaft, Julian Skinner, Jim Sumser, Karen Watterson, Gavin Wray, John Zukowski Assistant Publisher: Grace Wong Project Manager: Sofia Marchant Copy Editor: Ami Knox Production Manager: Kari Brooks Production Editor: JanetVail Proofreader: Patrick Vincent Compositor: ContentWorks Indexer: Rebecca Plunkett Artist: Kinetic Publishing Services, LLC Cover Designer: Kurt Krames Manufacturing Manager: Tom Debolski The information in this book is distributed on an "as is" basis, without warranty. Although every precaution has been taken in the preparation of this work, neither the author(s) nor Apress shall have any liability to any person or entity with respect to any loss or damage caused or alleged to be caused directly or indirectly by the information contained in this work. -

Programming with Windows Forms
A P P E N D I X A ■ ■ ■ Programming with Windows Forms Since the release of the .NET platform (circa 2001), the base class libraries have included a particular API named Windows Forms, represented primarily by the System.Windows.Forms.dll assembly. The Windows Forms toolkit provides the types necessary to build desktop graphical user interfaces (GUIs), create custom controls, manage resources (e.g., string tables and icons), and perform other desktop- centric programming tasks. In addition, a separate API named GDI+ (represented by the System.Drawing.dll assembly) provides additional types that allow programmers to generate 2D graphics, interact with networked printers, and manipulate image data. The Windows Forms (and GDI+) APIs remain alive and well within the .NET 4.0 platform, and they will exist within the base class library for quite some time (arguably forever). However, Microsoft has shipped a brand new GUI toolkit called Windows Presentation Foundation (WPF) since the release of .NET 3.0. As you saw in Chapters 27-31, WPF provides a massive amount of horsepower that you can use to build bleeding-edge user interfaces, and it has become the preferred desktop API for today’s .NET graphical user interfaces. The point of this appendix, however, is to provide a tour of the traditional Windows Forms API. One reason it is helpful to understand the original programming model: you can find many existing Windows Forms applications out there that will need to be maintained for some time to come. Also, many desktop GUIs simply might not require the horsepower offered by WPF.