Random Walk Hypothesis on Bucharest Stock Exchange
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Estimating the Price Impact of Market Orders on the Bucharest 8
ESTIMATING THE PRICE IMPACT OF MARKET ORDERS ON THE BUCHAREST 8. STOCK EXCHANGE Mircea BAHNA1 Cosmin-Octavian CEPOI2 Bogdan Andrei DUMITRESCU3 Virgil DAMIAN4 Abstract In this paper, we study the price response when high dimension buy or sell market orders for equities with different levels of liquidity are introduced into a limit order book system. Using high frequency data from five blue-chips listed on the Bucharest Stock Exchange, we capture the interactions between these types of orders and prices by the estimated impulse response functions in a VECM framework. The results reveal that the impact is high and persistent in time for the less liquid equities and is smaller when dealing with liquid ones. Thus, the corresponding prices of less liquid stocks can be easily manipulated by a trader willing to buy or sell significant volumes. This is a very common imbalance in the capital markets of the emerging countries and should be adjusted very quickly by the regulators. Keywords: market impact, market orders, limit orders, cointegration JEL Classification: C22, C53, D53, G10, G14 1. Introduction Trading in capital markets has expanded significantly over the past 30 years, driven mainly by advances in information technology, financial innovation and favoured by globalization and deregulation. Technological progress also has led to a change in the framework within which the transactions are taking place and currently most financial markets worldwide are using an order-driven system based on an electronic limit order book, i.e., a record of all orders, with their corresponding prices and amounts at a given moment in time. -

Over 100 Exchanges Worldwide 'Ring the Bell for Gender Equality in 2021' with Women in Etfs and Five Partner Organizations
OVER 100 EXCHANGES WORLDWIDE 'RING THE BELL FOR GENDER EQUALITY IN 2021’ WITH WOMEN IN ETFS AND FIVE PARTNER ORGANIZATIONS Wednesday March 3, 2021, London – For the seventh consecutive year, a global collaboration across over 100 exchanges around the world plan to hold a bell ringing event to celebrate International Women’s Day 2021 (8 March 2020). The events - which start on Monday 1 March, and will last for two weeks - are a partnership between IFC, Sustainable Stock Exchanges (SSE) Initiative, UN Global Compact, UN Women, the World Federation of Exchanges and Women in ETFs, The UN Women’s theme for International Women’s Day 2021 - “Women in leadership: Achieving an equal future in a COVID-19 world ” celebrates the tremendous efforts by women and girls around the world in shaping a more equal future and recovery from the COVID-19 pandemic. Women leaders and women’s organizations have demonstrated their skills, knowledge and networks to effectively lead in COVID-19 response and recovery efforts. Today there is more recognition than ever before that women bring different experiences, perspectives and skills to the table, and make irreplaceable contributions to decisions, policies and laws that work better for all. Women in ETFs leadership globally are united in the view that “There is a natural synergy for Women in ETFs to celebrate International Women’s Day with bell ringings. Gender equality is central to driving the global economy and the private sector has an important role to play. Our mission is to create opportunities for professional development and advancement of women by expanding connections among women and men in the financial industry.” The list of exchanges and organisations that have registered to hold an in person or virtual bell ringing event are shown on the following pages. -

List of Approved Regulated Stock Exchanges
Index Governance LIST OF APPROVED REGULATED STOCK EXCHANGES The following announcement applies to all equity indices calculated and owned by Solactive AG (“Solactive”). With respect to the term “regulated stock exchange” as widely used throughout the guidelines of our Indices, Solactive has decided to apply following definition: A Regulated Stock Exchange must – to be approved by Solactive for the purpose calculation of its indices - fulfil a set of criteria to enable foreign investors to trade listed shares without undue restrictions. Solactive will regularly review and update a list of eligible Regulated Stock Exchanges which at least 1) are Regulated Markets comparable to the definition in Art. 4(1) 21 of Directive 2014/65/EU, except Title III thereof; and 2) provide for an investor registration procedure, if any, not unduly restricting foreign investors. Other factors taken into account are the limits on foreign ownership, if any, imposed by the jurisdiction in which the Regulated Stock Exchange is located and other factors related to market accessibility and investability. Using above definition, Solactive has evaluated the global stock exchanges and decided to include the following in its List of Approved Regulated Stock Exchanges. This List will henceforth be used for calculating all of Solactive’s equity indices and will be reviewed and updated, if necessary, at least annually. List of Approved Regulated Stock Exchanges (February 2017): Argentina Bosnia and Herzegovina Bolsa de Comercio de Buenos Aires Banja Luka Stock Exchange -

An Early Evidence on Csr Reporting in the Context of Covid-19
Journal of Public Administration, Finance and Law AN EARLY EVIDENCE ON CSR REPORTING IN THE CONTEXT OF COVID-19 Oana Cristina STOICA Bucharest University of Economic Studies, Accounting Doctoral School Bucharest, Romania [email protected] Abstract: This study has investigated whether companies listed on Bucharest Stock Exchange have been prepared for Covid-19 risk and what are the measures and initiatives taken by them in terms of sustainability. Using a sample of seven listed companies that meet the criteria required by the Directive EU/95/2014 for disclosing non-financial information, the present paper has found that companies have mostly not been prepared for such a risk, but they immediately responded and have taken measures in order to protect their employees. In terms of social initiatives, only one company in the sample disclosed such information which is most related to supporting medical institution to combat and treat Covid-19. Keywords: CSR reporting, Covid-19, employees, social initiatives This article was presented at 12th edition of the Annual International Conference Globalization and Higher Education in Economics and Business Administration (GEBA 2020), held at the Alexandru Ioan Cuza University, Faculty of Economics and Business Administration in Iasi, Romania from the 22nd to 23rd of October 2020 INTRODUCTION Non-financial reporting is likely to provide a better picture of a firm’s performance (Wang and Sarkis, 2017) in comparison with financial reporting only. In the past few years, investors and other stakeholders which are interested in corporate information about firm’s business model, long-term strategy and value creation have started to give an increasingly attention on this type of reports. -
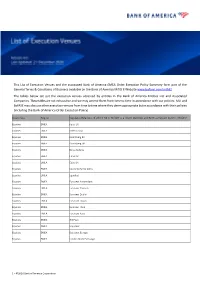
Bofa List of Execution Venues
This List of Execution Venues and the associated Bank of America EMEA Order Execution Policy Summary form part of the General Terms & Conditions of Business available on the Bank of America MifID II Website www.bofaml.com/mifid2 The tables below set out the execution venues accessed by entities in the Bank of America Entities List and Associated Companies. These tables are not exhaustive and we may amend them from time to time in accordance with our policies. MLI and BofASE may also use other execution venues from time to time where they deem appropriate but in accordance with their policies (including the Bank of America Order Execution Policy). Asset class Region Regulated Markets of which MLI / BofASE is a direct member and MTFs accessed by MLI / BofASE Equities EMEA Aquis UK Equities EMEA Athex Group Equities EMEA Bloomberg BV Equities EMEA Bloomberg UK Equities EMEA Borsa Italiana Equities EMEA Cboe BV Equities EMEA Cboe UK Equities EMEA Deutsche Borse Xetra Equities EMEA Equiduct Equities EMEA Euronext Amsterdam Equities EMEA Euronext Brussels Equities EMEA Euronext Dublin Equities EMEA Euronext Lisbon Equities EMEA Euronext Oslo Equities EMEA Euronext Paris Equities EMEA ITG Posit Equities EMEA Liquidnet Equities EMEA Liquidnet Europe Equities EMEA London Stock Exchange 1 – ©2020 Bank of America Corporation Asset class Region Regulated Markets of which MLI / BofASE is a direct member and MTFs accessed by MLI / BofASE Equities EMEA NASDAQ OMX Nordic – Helsinki Equities EMEA NASDAQ OMX Nordic – Stockholm Equities EMEA NASDAQ OMX -

Compliance with the Romanian Corporate Governance Code
Journal of Public Administration, Finance and Law COMPLIANCE WITH THE ROMANIAN CORPORATE GOVERNANCE CODE. EVIDENCES FROM THE COMPANIES LISTED ON BUCHAREST STOCK EXCHANGE Georgeta VINTILĂ Raluca-Georgiana MOSCU The Bucharest University of Economic The Bucharest University of Economic Studies Studies Bucharest, Romania Bucharest, Romania [email protected] [email protected] Abstract: The work aims to conduct a study on how corporate governance principles and recommendations are applied in Romania for companies listed on the Bucharest Stock Exchange. In the first part of the work, corporate governance principles and recommendations are presented as they appear in the statement of conformity "Comply or Explain" and Governance Code of BSE and it is subject to verification how companies listed on BSE meet these governance principles and recommendations and where no criteria is fulfilled it is given the explanation which is offered by the company’s management. To verify compliance with corporate governance recommendations in Romania we selected a sample of 55 companies listed on the BSE, using public information provided by website BSE (annual reports of 2013, the Comply or Explain statement of 2013). Research methodology is based on an index of corporate governance (CG Index) on the implementation of the principles of corporate governance code by listed companies in Romania. Thus the main research tool is a corporate governance index, calculated based on the framework proposed by the authors, and the results of the study consist -

Rulebook of the Bucharest Stock Exchange
The Bucharest Stock Exchange Rulebook Approved by R.N.S.C. Decision No.720/17.05.2007 RRULEBOOK OF THE BBUCHAREST SSTOCK EEXCHANGE 2 The Bucharest Stock Exchange Rulebook Approved by R.N.S.C. Decision No.720/17.05.2007 TTABLE OOF CONTENTS DEFINITION OF TERMS PART 1 THE REGULATED SPOT MARKET TITLE I: PARTICIPANTS Chapter I General Provisions ……………………………………………… 19 Chapter II Procedures Regarding the Granting of the Participant Status and the Permission to trade on the BVB …………………………………. 19 Section 1 Investment Firms ………………………………………………….. 19 Section 2 Credit Institutions ….……………………………………………… 21 Section 3 Access to the BVB system from Authorized Participant Branches ……………………………………….. 21 Chapter III Withdrawal of Access to the BVB trading system ………………….. 21 Section 1 Withdrawal of Access to The BVB Trading System- On Request …………………………………………………… 22 Section 2 Withdrawal of Access to the BVB Trading System- As a Result of a RNSC or BVB Sanction ………………… 22 Section 3 Withdrawal of Access to the BVB Trading System- As a Result of the Participant’s Inactivity ……………….. 23 Chapter IV Participant Obligations ……………………………………………….. 23 Section 1 Exchange Tied Agents Obligations ……………………………… 23 Section 2 Obligations Concerning the Participants’ Activity…... ………. 24 Section 3 Obligations Concerning Notifications to the BVB …………… 25 Section 4 Obligations Regarding Participant Fees ………………………. 26 3 The Bucharest Stock Exchange Rulebook Approved by R.N.S.C. Decision No.720/17.05.2007 Chapter V 26 Sanctions for Illegal Acts Committed to the BVB Legal Scheme ….. Section 1 General Considerations ………………………………………….. 26 Section 2 Illegal acts against the BVB Legal Scheme ……………………. 27 Section 3 Sanctions ……………………………………………………….…... 28 General Provisions 28 Administrative-Disciplinary Sanctions 28 Patrimonial Sanctions 29 Section 4 Identifying, Registering and Investigating Illegal Acts. -

Tts (Transport Trade Services) Becomes the First Cargo Carrier Listed on Bucharest Stock Exchange, Following an Ipo Worth Ron 288Mn
PRESS RELEASE JUNE 14TH, 2021 TTS (TRANSPORT TRADE SERVICES) BECOMES THE FIRST CARGO CARRIER LISTED ON BUCHAREST STOCK EXCHANGE, FOLLOWING AN IPO WORTH RON 288MN • TTS (Transport Trade Services), the largest Romanian carrier on the Danube, went public on the Bucharest Stock Exchange following an initial public offering, through which the company's shareholders sold 50% of the shares for RON 288mn. • Radu Hanga, Bucharest Stock Exchange President: "The listing of the largest Romanian carrier on the Danube proves, once again, that offers with a significant dimension can be carried out on Bucharest Stock Exchange and that investors are willing to place their money in companies with a promising future". • Adrian Tanase, Bucharest Stock Exchange CEO: “A public offer such as the one carried out by TTS represents a test for the company, it is an evaluation made by the entire capital market community. Today’s listing is a validation of the company by the investors”. • Petru Stefanut, TTS CEO: “The experience of the IPO and the direct communication with the investors were beneficial for the company. After 2017, we have restructured and improved the organization of the company with good results, marked by the growth and stabilization of the EBITDA”. • Stanciu Ion, Deputy CEO, and member of Board: "In the future, we are confident that TTS will maintain its performance and position gained on the Danube transportation with the mission of reducing the carbon emissions." • Constantin Bruma, Swiss Capital: “We are glad that we contributed to the listing of a champion of the Romanian economy on Bucharest Stock Exchange. -

Romanian Capital Market Developments
CEE REGION FUNDING CHALLENGES EUROFI VIEWS MAGAZINE - BUCHAREST AVRIL 2019 The Romanian capital market has started On attracting entrepreneurs towards in 2014 an ambitious reform in order listing, Bucharest Stock Exchange is to be upgraded to emerging market running in 2019 the 3rd edition of Made in status by global index providers and, Romania project, targeting 15 companies since September 2018, it is only one for the growth of the Romanian economy step away (as far as market liquidity) by and their success stories. the FTSE Russell classification. As per About attracting foreign investors in the FTSE Russell country classification Romania, Bucharest Stock Exchange review, the Romanian capital market has extended in the last years the range was maintained on the Emerging Market of targeted investors as well as the geo- Watchlist and is one step closer to obtain graphical region, initiated and took part the upgrade. The single outstanding in more roadshows and investor confe- criterion is Liquidity – sufficient broad rences, launched InvestingRomania.com market liquidity to support sizeable information portal. global investment. FTSE upgraded from In parallel, the projects on qualitative ‘Not Met’ to ‘Restricted’ the Liquidity improvement of the market are quasi criterion, following an improvement in permanent, like increasing the degree broad market liquidity. of corporate governance compliance for The global index provider MSCI published listed companies, within the framework on June 20, 2018, its latest Global Market of an EBRD supported project. Accessibility Review. The report stated that Romania continued its efforts to improve the liquidity and participation Lucian Anghel in the stock market by lowering trading fees and encouraging more market Chairman, makers to boost market activity, and that notable activities for the Romanian Bucharest Stock Exchange equity market also included the launch of Issuers Reporting Information System, where listed companies were able to release their communication to the Romanian market efficiently. -

The Development of the Romanian Capital Market Related to Poor Corporate Governance Principles and Minority Shareholders’ Protection
THE DEVELOPMENT OF THE ROMANIAN 10. CAPITAL MARKET: EVIDENCES ON INFORMATION EFFICIENCY Victor DRAGOT* Andreea STOIAN** Daniel Traian PELE*** Eugen MITRIC**** Malik BENSAFTA***** Abstract1 The Romanian capital market has considerably grown in the last decade. This study reveals new evidences regarding informational efficiency of this market. Applying Multiple Variance Ratio test to random walk hypothesis, assuming, on the one hand homoskedasticity, and on the other hand heteroskedasticity, it was found that for most of the stock prices the random walk hypothesis cannot be rejected. Consequently, the returns are not predictable by using the series of historical returns. Based on these results, there are not enough reasons to reject the Efficient Market Hypothesis in its weak form. Keywords: information, capital markets, market efficiency, random walk, predictability of returns, Romania JEL Classification: G14, P34 * Ph.D., Professor, Academy of Economic Studies, Bucharest, Department of Finance, [email protected], [email protected]. ** Ph.D., Lecturer, Academy of Economic Studies, Bucharest, Department of Finance, [email protected]. *** Ph.D., Lecturer, Academy of Economic Studies, Bucharest, Department of Statistics and Econometrics, [email protected], www.danielpele.ase.ro. **** Ph.D., Lecturer, Academy of Economic Studies, Bucharest, Department of Finance, [email protected]. ***** Ph.D., GERCIE, Université François Rabelais de Tours, [email protected]. 1 The authors are grateful for the useful comments provided by Cosmin erbnescu, Andrei Stnculescu and the two anonymous referees. The remaining errors are ours. This research was supported by the Romanian Ministry of Education and Research – National Authority for Scientific Research (NASR) through the RTD National Programme CEEX, Grant No. -

The Problem with European Stock Markets
THE PROBLEM WITH EUROPEAN STOCK MARKETS Analysis of the fragmented stock exchange landscape in Europe, how it is holding back growth in capital markets – and what we can do about it March 2021 by William Wright & Eivind Friis Hamre SUMMARY It is not new news that Europe has a complex patchwork of equity markets, stock exchanges and post-trade infrastructure, but this short paper paints this problem in particularly stark terms. The genesis of this paper came from two simple thought experiments: first, can we draw a diagram of the structure of European equity markets on one page? And second, what would the US stock market look like if every state has its own stock exchange? If you read nothing else in this report, please look at the map of the US market on page three and the diagram of European equity markets on page six. Here is a quick summary of this paper: > The elephant in the room The complex patchwork of European equity markets is a huge obstacle to building bigger and better capital markets at a time when the European economy needs them more than ever. We can tinker at the edges with the detail of regulation, but so as long as Europe has 22 different stock exchange groups operating 35 different exchange for listings, 41 exchanges for trading, and nearly 40 different CCPs and CSDs, not much will change. > Punching below its weight The European equity market is less than half the size of the US but has three times as many exchange groups; more than 10 times as many exchanges for listings; more than twice as many exchanges for trading; and roughly 20 times as many post-trade infrastructure providers. -
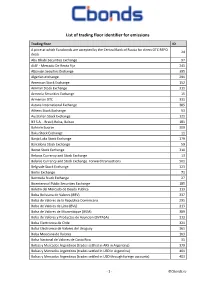
List of Trading Floor Identifier for Emissions
List of trading floor identifier for emissions Trading floor ID A price at which Eurobonds are accepted by the Central Bank of Russia for direct OTC REPO 24 deals Abu Dhabi Securities Exchange 97 AIAF - Mercado De Renta Fija 241 Albanian Secuities Exchange 395 Algerian exchange 291 American Stock Exchange 152 Amman Stock Exchange 311 Armenia Securities Exchange 15 Armenian OTC 331 Astana International Exchange 385 Athens Stock Exchange 53 Australian Stock Exchange 121 B3 S.A. - Brasil, Bolsa, Balcao 181 Bahrain Bourse 309 Baku Stock Exchange 11 Banja Luka Stock Exchange 179 Barcelona Stock Exchange 59 Beirut Stock Exchange 310 Belarus Currency and Stock Exchange 13 Belarus Currency and Stock Exchange. Forward transactions 501 Belgrade Stock Exchange 123 Berlin Exchange 71 Bermuda Stock Exchange 27 Bicentennial Public Securities Exchange 185 Boletin del Mercado de Deuda Publica 113 Bolsa Boliviana de Valores (BBV) 337 Bolsa de Valores de la Republica Dominicana 295 Bolsa de Valores de Lima (BVL) 213 Bolsa de Valores de Mozambique (BVM) 389 Bolsa de Valores y Productos de Asuncion (BVPASA) 313 Bolsa Electronica de Chile 321 Bolsa Electronica de Valores del Uruguay 361 Bolsa Mexicana de Valores 103 Bolsa Nacional de Valores de Costa Rica 31 Bolsas y Mercados Argentinos (trades settled in ARS in Argentina) 379 Bolsas y Mercados Argentinos (trades settled in USD in Argentina) 401 Bolsas y Mercados Argentinos (trades settled in USD through foreign accounts) 403 - 1 - ©Cbonds.ru Trading floor ID BondSpot 69 Borsa Istanbul (International Bonds