A Strategy to Support IE from NL at Production Time
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
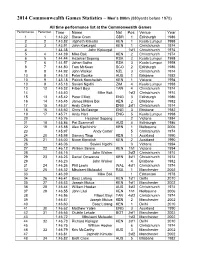
2014 Commonwealth Games Statistics – Men's 800M
2014 Commonwealth Games Statistics – Men’s 800m (880yards before 1970) All time performance list at the Commonwealth Games Performance Performer Time Name Nat Pos Venue Year 1 1 1:43.22 Steve Cram GBR 1 Edinburgh 1986 2 2 1:43.82 Japheth Kimutai KEN 1 Kuala Lumpur 1998 3 3 1:43.91 John Kipkurgat KEN 1 Christchurch 1974 4 1:44.38 John Kipkurgat 1sf1 Christchurch 1974 5 4 1:44.39 Mike Boit KEN 2 Christchurch 1974 6 5 1:44.44 Hezekiel Sepeng RSA 2 Kuala Lumpur 1998 7 6 1:44.57 Johan Botha RSA 3 Kuala Lumpur 1998 8 7 1:44.80 Tom McKean SCO 2 Edinburgh 1986 9 8 1:44.92 John Walker NZL 3 Christchurch 1974 10 9 1:45.18 Peter Bourke AUS 1 Brisbane 1982 10 9 1:45.18 Patrick Konchellah KEN 1 Victoria 1994 10 9 1:45.18 Savieri Ngidhi ZIM 4 Kuala Lumpur 1998 13 12 1:45.32 Filbert Bayi TAN 4 Christchurch 1974 14 1:45.40 Mike Boit 1sf2 Christchurch 1974 15 13 1:45.42 Peter Elliott ENG 3 Edinburgh 1986 16 14 1:45.45 James Maina Boi KEN 2 Brisbane 1982 17 15 1:45.57 Andy Carter ENG 2sf1 Christchurch 1974 18 16 1:45.60 Chris McGeorge ENG 3 Brisbane 1982 19 17 1:45.71 Andy Hart ENG 5 Kuala Lumpur 1998 20 1:45.76 Hezekiel Sepeng 2 Victoria 1994 21 18 1:45.86 Pat Scammell AUS 4 Edinburgh 1986 22 19 1:45.88 Alex Kipchirchir KEN 1 Melbourne 2006 23 1:45.97 Andy Carter 5 Christchurch 1974 24 20 1:45.98 Sammy Tirop KEN 1 Auckland 1990 25 21 1:46.00 Nixon Kiprotich KEN 2 Auckland 1990 26 1:46.06 Savieri Ngidhi 3 Victoria 1994 27 22 1:46.12 William Serem KEN 1h1 Victoria 1994 28 1:46.15 John Walker 2sf2 Christchurch 1974 29 23 1:46.23 Daniel Omwanza KEN 3sf1 Christchurch -

All Time Men's World Ranking Leader
All Time Men’s World Ranking Leader EVER WONDER WHO the overall best performers have been in our authoritative World Rankings for men, which began with the 1947 season? Stats Editor Jim Rorick has pulled together all kinds of numbers for you, scoring the annual Top 10s on a 10-9-8-7-6-5-4-3-2-1 basis. First, in a by-event compilation, you’ll find the leaders in the categories of Most Points, Most Rankings, Most No. 1s and The Top U.S. Scorers (in the World Rankings, not the U.S. Rankings). Following that are the stats on an all-events basis. All the data is as of the end of the 2019 season, including a significant number of recastings based on the many retests that were carried out on old samples and resulted in doping positives. (as of April 13, 2020) Event-By-Event Tabulations 100 METERS Most Points 1. Carl Lewis 123; 2. Asafa Powell 98; 3. Linford Christie 93; 4. Justin Gatlin 90; 5. Usain Bolt 85; 6. Maurice Greene 69; 7. Dennis Mitchell 65; 8. Frank Fredericks 61; 9. Calvin Smith 58; 10. Valeriy Borzov 57. Most Rankings 1. Lewis 16; 2. Powell 13; 3. Christie 12; 4. tie, Fredericks, Gatlin, Mitchell & Smith 10. Consecutive—Lewis 15. Most No. 1s 1. Lewis 6; 2. tie, Bolt & Greene 5; 4. Gatlin 4; 5. tie, Bob Hayes & Bobby Morrow 3. Consecutive—Greene & Lewis 5. 200 METERS Most Points 1. Frank Fredericks 105; 2. Usain Bolt 103; 3. Pietro Mennea 87; 4. Michael Johnson 81; 5. -

Men's 200M Final 23.08.2020
Men's 200m Final 23.08.2020 Start list 200m Time: 17:10 Records Lane Athlete Nat NR PB SB 1 Richard KILTY GBR 19.94 20.34 WR 19.19 Usain BOLT JAM Olympiastadion, Berlin 20.08.09 2 Mario BURKE BAR 19.97 20.08 20.78 AR 19.72 Pietro MENNEA ITA Ciudad de México 12.09.79 3 Felix SVENSSON SWE 20.30 20.73 20.80 NR 20.30 Johan WISSMAN SWE Stuttgart 23.09.07 WJR 19.93 Usain BOLT JAM Hamilton 11.04.04 4 Jan VELEBA CZE 20.46 20.64 20.64 MR 19.77 Michael JOHNSON USA 08.07.96 5 Silvan WICKI SUI 19.98 20.45 20.45 DLR 19.26 Yohan BLAKE JAM Boudewijnstadion, Bruxelles 16.09.11 6 Adam GEMILI GBR 19.94 19.97 20.56 SB 19.76 Noah LYLES USA Stade Louis II, Monaco 14.08.20 7 Bruno HORTELANO-ROIG ESP 20.04 20.04 8 Elijah HALL USA 19.32 20.11 20.69 2020 World Outdoor list 19.76 +0.7 Noah LYLES USA Stade Louis II, Monaco (MON) 14.08.20 19.80 +1.0 Kenneth BEDNAREK USA Montverde, FL (USA) 10.08.20 Medal Winners Stockholm previous 19.96 +1.0 Steven GARDINER BAH Clermont, FL (USA) 25.07.20 20.22 +0.8 Divine ODUDURU NGR Clermont, FL (USA) 25.07.20 2019 - IAAF World Ch. in Athletics Winners 20.23 +0.1 Clarence MUNYAI RSA Pretoria (RSA) 13.03.20 1. Noah LYLES (USA) 19.83 19 Aaron BROWN (CAN) 20.06 20.24 +0.8 André DE GRASSE CAN Clermont, FL (USA) 25.07.20 2. -

Doha 2018: Compact Athletes' Bios (PDF)
Men's 200m Diamond Discipline 04.05.2018 Start list 200m Time: 20:36 Records Lane Athlete Nat NR PB SB 1 Rasheed DWYER JAM 19.19 19.80 20.34 WR 19.19 Usain BOLT JAM Berlin 20.08.09 2 Omar MCLEOD JAM 19.19 20.49 20.49 AR 19.97 Femi OGUNODE QAT Bruxelles 11.09.15 NR 19.97 Femi OGUNODE QAT Bruxelles 11.09.15 3 Nethaneel MITCHELL-BLAKE GBR 19.94 19.95 WJR 19.93 Usain BOLT JAM Hamilton 11.04.04 4 Andre DE GRASSE CAN 19.80 19.80 MR 19.85 Ameer WEBB USA 06.05.16 5 Ramil GULIYEV TUR 19.88 19.88 DLR 19.26 Yohan BLAKE JAM Bruxelles 16.09.11 6 Jereem RICHARDS TTO 19.77 19.97 20.12 SB 19.69 Clarence MUNYAI RSA Pretoria 16.03.18 7 Noah LYLES USA 19.32 19.90 8 Aaron BROWN CAN 19.80 20.00 20.18 2018 World Outdoor list 19.69 -0.5 Clarence MUNYAI RSA Pretoria 16.03.18 19.75 +0.3 Steven GARDINER BAH Coral Gables, FL 07.04.18 Medal Winners Doha previous Winners 20.00 +1.9 Ncincihli TITI RSA Columbia 21.04.18 20.01 +1.9 Luxolo ADAMS RSA Paarl 22.03.18 16 Ameer WEBB (USA) 19.85 2017 - London IAAF World Ch. in 20.06 -1.4 Michael NORMAN USA Tempe, AZ 07.04.18 14 Nickel ASHMEADE (JAM) 20.13 Athletics 20.07 +1.9 Anaso JOBODWANA RSA Paarl 22.03.18 12 Walter DIX (USA) 20.02 20.10 +1.0 Isaac MAKWALA BOT Gaborone 29.04.18 1. -

Golden Spike Ostrava 2009 Mestský Stadion 17.06.2009 Start List 800M Men - B-Race
Golden Spike Ostrava 2009 Mestský Stadion 17.06.2009 Start list 800m Men - B-Race 17 JUN 2009 Start Time: 16:10 WORLD RECORD 1:41.11 Wilson Kipketer DEN Cologne (GER) 24 AUG 1997 WORLD LEAD 1:43.09 Abubaker Kaki Khamis SUD Doha (QAT) 8 MAY 2009 MEETING RECORD 1:43.24 Wilfred Bungei KEN Ostrava (CZE) 12 JUN 2003 Lane Name Nat Date of Birth PB SB Result Rank 1 CAPEK Martin CZE 11 JUL 1989 1:50.21 1:50.26 1 HOŠEK Martin CZE 7 JUL 1987 1:50.48 1:50.48 2 KAPLAN Miroslav CZE 5 SEP 1986 1:48.50 1:49.70 2 HRSTKA Martin CZE 1 APR 1989 1:48.29 1:49.09 3 PAPADOPOULOS Efthuimios GRE 29 APR 1983 1:46.56 1:49.14 3 PELIKÁN Jozef SVK 29 JUL 1984 1:48.03 1:50.22 4 KAZI Tamás HUN 16 MAY 1985 1:47.16 1:46.15 4 NGOEPE Samson RSA 28 JAN 1985 1:45.49 1:46.22 5 KIPCHOGE Gilbert KEN 4 MAY 1983 1:44.52 1:47.64 6 CZAPIEWSKI Pawel POL 30 MAR 1978 1:43.22 1:46.78 7 KIVUNA Jackson KEN 11 AUG 1988 1:45.29 1:46.32 7 RISELEY Jeffrey AUS 11 NOV 1986 1:46.35 1:47.58 8 SVOBODA Richard CZE 20 NOV 1982 1:48.81 1:50.27 8 JELÍNEK Petr (PM) CZE 25 MAY 1988 All Time Best Performers 2009 Best Performers 1:41.11 Wilson Kipketer DEN Köln (GER) 24 AUG 1997 1:43.09 Abubaker Kaki SUD Doha (QAT) 8 MAY 1:41.73 Sebastian Coe GBR Firenze (ITA) 10 JUN 1981 1:43.17 Asbel Kipruto Kiprop KEN Doha (QAT) 8 MAY 1:41.77 Joaquim Cruz BRA Köln (GER) 26 AUG 1984 1:43.36 Amine Laalou MAR Hengelo (NED) 1 JUN 1:42.28 Sammy Koskei KEN Köln (GER) 26 AUG 1984 1:43.53 David Lekuta Rudisha KEN Hengelo (NED) 1 JUN 1:42.34 Wilfred Bungei KEN Rieti (ITA) 8 SEP 2002 1:43.66 Mohammed Al-Salhi KSA Doha (QAT) 8 -

Men's 200M Diamond Discipline 26.08.2021
Men's 200m Diamond Discipline 26.08.2021 Start list 200m Time: 21:35 Records Lane Athlete Nat NR PB SB 1 Eseosa Fostine DESALU ITA 19.72 20.13 20.29 WR 19.19 Usain BOLT JAM Olympiastadion, Berlin 20.08.09 2 Isiah YOUNG USA 19.32 19.86 19.99 AR 19.72 Pietro MENNEA ITA Ciudad de México 12.09.79 3 Yancarlos MARTÍNEZ DOM 20.17 20.17 20.17 NR 19.98 Alex WILSON SUI La Chaux-de-Fonds 30.06.19 WJR* 19.84 Erriyon KNIGHTON USA Hayward Field, Eugene, OR 27.06.21 4Aaron BROWN CAN19.6219.9519.99WJR 19.88 Erriyon KNIGHTON USA Hayward Field, Eugene, OR 26.06.21 5Fred KERLEY USA19.3219.9019.90MR 19.50 Noah LYLES USA 05.07.19 6Kenneth BEDNAREKUSA19.3219.6819.68DLR 19.26 Yohan BLAKE JAM Boudewijnstadion, Bruxelles 16.09.11 7 Steven GARDINER BAH 19.75 19.75 20.24 SB 19.52 Noah LYLES USA Hayward Field, Eugene, OR 21.08.21 8William REAIS SUI19.9820.2420.26 2021 World Outdoor list 19.52 +1.5 Noah LYLES USA Eugene, OR (USA) 21.08.21 Medal Winners Road To The Final 19.62 -0.5 André DE GRASSE CAN Olympic Stadium, Tokyo (JPN) 04.08.21 1Aaron BROWN (CAN) 25 19.68 -0.5 Kenneth BEDNAREK USA Olympic Stadium, Tokyo (JPN) 04.08.21 2021 - The XXXII Olympic Games 2Kenneth BEDNAREK (USA) 23 19.81 +0.8 Terrance LAIRD USA Austin, TX (USA) 27.03.21 1. André DE GRASSE (CAN) 19.62 3André DE GRASSE (CAN) 21 19.84 +0.3 Erriyon KNIGHTON USA Eugene, OR (USA) 27.06.21 2. -

BRONZO 2016 Usain Bolt
OLIMPIADI L'Albo d'Oro delle Olimpiadi Atletica Leggera UOMINI 100 METRI ANNO ORO - ARGENTO - BRONZO 2016 Usain Bolt (JAM), Justin Gatlin (USA), Andre De Grasse (CAN) 2012 Usain Bolt (JAM), Yohan Blake (JAM), Justin Gatlin (USA) 2008 Usain Bolt (JAM), Richard Thompson (TRI), Walter Dix (USA) 2004 Justin Gatlin (USA), Francis Obikwelu (POR), Maurice Greene (USA) 2000 Maurice Greene (USA), Ato Boldon (TRI), Obadele Thompson (BAR) 1996 Donovan Bailey (CAN), Frank Fredericks (NAM), Ato Boldon (TRI) 1992 Linford Christie (GBR), Frank Fredericks (NAM), Dennis Mitchell (USA) 1988 Carl Lewis (USA), Linford Christie (GBR), Calvin Smith (USA) 1984 Carl Lewis (USA), Sam Graddy (USA), Ben Johnson (CAN) 1980 Allan Wells (GBR), Silvio Leonard (CUB), Petar Petrov (BUL) 1976 Hasely Crawford (TRI), Don Quarrie (JAM), Valery Borzov (URS) 1972 Valery Borzov (URS), Robert Taylor (USA), Lennox Miller (JAM) 1968 James Hines (USA), Lennox Miller (JAM), Charles Greene (USA) 1964 Bob Hayes (USA), Enrique Figuerola (CUB), Harry Jeromé (CAN) 1960 Armin Hary (GER), Dave Sime (USA), Peter Radford (GBR) 1956 Bobby-Joe Morrow (USA), Thane Baker (USA), Hector Hogan (AUS) 1952 Lindy Remigino (USA), Herb McKenley (JAM), Emmanuel McDonald Bailey (GBR) 1948 Harrison Dillard (USA), Norwood Ewell (USA), Lloyd LaBeach (PAN) 1936 Jesse Owens (USA), Ralph Metcalfe (USA), Martinus Osendarp (OLA) 1932 Eddie Tolan (USA), Ralph Metcalfe (USA), Arthur Jonath (GER) 1928 Percy Williams (CAN), Jack London (GBR), Georg Lammers (GER) 1924 Harold Abrahams (GBR), Jackson Scholz (USA), Arthur -

FBK Games 2021
FBK Games 2021 Hengelo (NED), 6 June 2021 START LIST OFFICIAL Javelin Throw 600g Mix (National) June 6 2021 13:35 ORDER BIB NAME COUNTRY DATE of BIRTH PERSONAL BEST SEASON BEST Tom Egbers NED 11 Nov 99 76.92 Jurriaan Wouters NED 18 Apr 93 77.16 Mart Ten Berge NED 27 Apr 91 79.92 Dario Podda NED 24 Apr 01 69.48 Lisanne Schol NED 22 Jun 91 60.92 Tosca Smit NED 22 Mar 00 51.58 Dewi Lafontaine NED 8 Jan 99 50.34 Danien Ten Berge NED 28 Dec 92 53.21 Noah Verduin NED 18 Jun 03 50.34 Marleen Baas NED 13 Aug 04 47.71 Page 1 of 1 Issued at Saturday, June 5, 2021 7:53 PM FBK Games 2021 Hengelo (NED), 6 June 2021 START LIST OFFICIAL Shot Put 4kg Mix (National) June 6 2021 13:45 ORDER BIB NAME COUNTRY DATE of BIRTH PERSONAL BEST SEASON BEST Matyas Kerekgyarto NED 25 Aug 03 15.76 Ruben Rolvink NED 25 Aug 02 16.93 Bjorn Van Kins NED 15 Jun 00 16.85 Mattijs Mols NED 22 Apr 00 18.21 Sven Poelman NED 5 Jun 97 19.45 Lotte Haest NED 5 May 04 14.74 Jaybre Wau NED 18 Jul 04 14.72 Alida Van Daalen NED 12 Apr 02 16.77 Benthe König NED 7 Apr 98 17.06 Jessica Schilder NED 19 Mar 99 18.47 Page 1 of 1 Issued at Saturday, June 5, 2021 7:53 PM FBK Games 2021 Hengelo (NED), 6 June 2021 START LIST OFFICIAL 100 Metres Men (National) RESULT NAME COUNTRY DATE VENUE WL 9.88 Trayvon BROMELL USA 30 Apr 2021 Jax Track at Hodges Stadium, Jacksonville, FL MR 9.95 Richard Tompson TTO 1 Jun 2009 June 6 2021 13:55 LANE BIB NAME COUNTRY DATE of BIRTH PERSONAL BEST SEASON BEST 1 Justin Verheul NED 1999 10.65 10.65 2 Elvis Afrifa NED 30 Nov 97 10.50 10.57 3 Churandy Martina NED 3 -

Men's 800M Promotional 25.05.2018
Men's 800m Promotional 25.05.2018 Start list 800m Time: 19:52 Records Lane Athlete Nat NR PB SB 1 Kyle LANGFORD GBR 1:41.73 1:45.16 1:45.16 WR 1:40.91 David RUDISHA KEN London 09.08.12 2 Ferguson Cheruiyot ROTICH KEN 1:40.91 1:42.84 1:46.76 AR 1:42.60 Johnny GRAY USA Koblenz 28.08.85 NR 1:42.60 Johnny GRAY USA Koblenz 28.08.85 3 Wyclife KINYAMAL KEN 1:40.91 1:43.91 1:43.91 WJR 1:41.73 Nijel AMOS BOT London 09.08.12 4 Kipyegon BETT KEN 1:40.91 1:43.76 1:48.32 MR 1:43.63 Nijel AMOS BOT 31.05.14 5 Adam KSZCZOT POL 1:43.22 1:43.30 1:46.70 DLR 1:41.54 David RUDISHA KEN Paris 06.07.12 6 Nijel AMOS BOT 1:41.73 1:41.73 1:44.65 SB 1:43.25 Michael SARUNI KEN Tucson, AZ 28.04.18 7 Emmanuel Kipkurui KORIR KEN 1:40.91 1:43.10 1:45.21 8 Erik SOWINSKI USA 1:42.60 1:44.58 1:46.21 9 Harun ABDA USA 1:42.60 1:45.55 1:47.87 2018 World Outdoor list 1:43.25 Michael SARUNI KEN Tucson, AZ 28.04.18 1:43.91 Wyclife KINYAMAL KEN Shanghai 12.05.18 1:43.95 Jonathan KITILIT KEN Shanghai 12.05.18 Medal Winners Eugene previous Winners 1:44.65 Nijel AMOS BOT Palo Alto 31.03.18 1:44.91 Cornelius TUWEI KEN Nairobi 17.02.18 2017 - London IAAF World Ch. -

Men's 200M Final 14.08.2020
Men's 200m Final 14.08.2020 Start list 200m Time: 21:32 Records Lane Athlete Nat NR PB SB 1 Marvin RENÉ FRA 19.80 20.59 WR 19.19 Usain BOLT JAM Olympiastadion, Berlin 20.08.09 2 Mouhamadou FALL FRA 19.80 20.34 21.81 AR 19.72 Pietro MENNEA ITA Ciudad de México 12.09.79 3 Mario BURKE BAR 19.97 20.08 NR 21.89 Sébastien GATTUSO MON Marsa 05.06.03 WJR 19.93 Usain BOLT JAM Hamilton 11.04.04 4 Josephus LYLES USA 19.32 20.24 20.24 MR 19.65 Noah LYLES USA 20.07.18 5 Adam GEMILI GBR 19.94 19.97 DLR 19.26 Yohan BLAKE JAM Boudewijnstadion, Bruxelles 16.09.11 6 Ramil GULIYEV TUR 19.76 19.76 SB 19.80 Kenneth BEDNAREK USA Montverde, FL 10.08.20 7 Noah LYLES USA 19.32 19.50 19.94 8 Deniz ALMAS GER 20.20 20.88 20.88 2020 World Outdoor list 19.80 +1.0 Kenneth BEDNAREK USA Montverde, FL (USA) 10.08.20 19.94 +0.8 Noah LYLES USA Clermont, FL (USA) 25.07.20 Medal Winners Monaco previous 19.96 +1.0 Steven GARDINER BAH Clermont, FL (USA) 25.07.20 20.22 +0.8 Divine ODUDURU NGR Clermont, FL (USA) 25.07.20 2019 - IAAF World Ch. in Athletics Winners 20.23 +0.1 Clarence MUNYAI RSA Pretoria (RSA) 13.03.20 1. Noah LYLES (USA) 19.83 18 Noah LYLES (USA) 19.65 20.24 +0.8 André DE GRASSE CAN Clermont, FL (USA) 25.07.20 2. -

2013 World Championships Statistics – Men's 800M by K Ken Nakamura
2013 World Championships Statistics – Men’s 800m by K Ken Nakamura The records to look for in Moskva: 1) Can Mohamed Aman become the first World Youth medalist to win a medal at the Worlds? 2) The best medal by the US is bronze. Can Solomon or Symmonds to better? All time Performance List at the World Championships Performance Performer Time Name Nat Pos Venue Year 1 1 1:43.06 Billy Konchellah KEN 1 Roma 1987 2 2 1:43.30 Wilson Kipketer DEN 1 Sevilla 1999 3 3 1:43:32 Hezekiel Sepeng RSA 2 Sevilla 1999 4 1:43.38 Wilson Kipketer 1 Athinai 1997 5 4 1:43.41 Peter Elliott GBR 2 Roma 1987 6 5 1:43.65 Willi Wülbeck FRG 1 Helsinki 1983 7 6 1:43.70 Andre Bucher SUI 1 Edmonton 2001 8 7 1:43.76 Jose Luiz Barbosa BRA 3 Roma 1987 9 8 1:43.91 David Rudisha KEN 1 Daegu 2011 10 1:43.99 Billy Konchellah 1 Tokyo 1991 11 9 1:44.00 Norberto Tellez CUB 2 Athinai 1997 12 10 1:44.18 Djabir Said-Guerni ALG 3 Sevilla 1999 13 11 1:44.20 Rob Druppers NED 2 Helsinki 1983 13 1:44.20 David Rudisha 1sf3 Daegu 2011 15 1:44.24 Jose Luiz Barbosa 2 Tokyo 1991 15 12 1:44.24 Rashid Ramzi BRN 1 Helsinki 2005 17 13 1:44.25 Rich Kenah USA 3 Athinai 1997 18 14 1:44.26 Patrick Konchellah KEN 4 Athinai 1997 18 14 1:44.26 Yuriy Borzakovskiy RUS 1sf1 Helsinki 2005 20 16 1:44.27 Joaquim Cruz BRA 3 Helsinki 1983 21 1:44.30 Rashid Ramzi 2sf1 Helsinki 2005 22 17 1:44.33 Gary Reed CAN 1sf3 Helsinki 2005 23 18 1:44.41 Wilfred Bungei KEN 2sf3 Helsinki 2005 23 18 1:44.41 Abubaker Kaki SUD 2 Daegu 2011 25 1:44.47 Andre Bucher 1sf2 Edmonton 2001 26 1:44.49 Yuriy Borzakovskiy 3 Daegu 2011 27 -

2019 World Championships Statistics – Men's
2019 World Championships Statistics – Men’s 800m by K Ken Nakamura The records to look for in Doha: 1) Can Amos become second runner (after Mulaudzi) to win both CWG and World Championships? 2) Can Donovan Brazer win first gold for the US at 800m in the World Championships? Summary: All time Performance List at the World Championships Performance Performer Time Name Nat Pos Venue Year 1 1 1:43.06 Billy Konch ellah KEN 1 Roma 1987 2 2 1:43.30 Wilson Kipketer DEN 1 Sevilla 1999 3 3 1:43.31 Mohammed A man ETH 1 Moskva 2013 4 4 1:43:32 Hezekiel Sepeng RSA 2 Sevilla 1999 5 1:43.38 Wilson Kipketer 1 Athinai 1997 6 5 1:43.41 Peter Elliott GBR 2 Roma 1987 7 6 1:43.55 Nick Symmonds USA 2 Moskva 2013 8 7 1:43.65 Willi Wülbeck FRG 1 Helsinki 1983 9 8 1:43.70 Andre Bucher SUI 1 Edmonton 2001 10 9 1:43.76 Jose Luiz Barbosa BRA 3 Roma 1987 10 9 1:43.76 Ayanleh Souleiman DJI 3 Moskva 2013 Margin of Victory Difference Name Nat Venue Year Max 0.85 second Andre Bucher SUI Edmonton 2001 0.62 second Wilson Kipketer DEN Athinai 1997 Min 0.01 second Alfred Kirwa Yego KEN Osaka 2007 0.02 second Wilson Kipketer DEN Sevilla 1999 Best Marks for Places in the World Championships Pos Time Name Nat Venue Year 1 1:43.06 Billy Konchellah KEN Roma 1987 2 1:4 3.32 Hezekiel Sepeng RSA Sevilla 1999 1:43.41 Peter Elliott GBR Roma 1987 3 1:43:76 Jose Luiz Barbosa BRA Roma 1987 Ayanleh Souleiman DJI Moskva 2013 4 1:44.08 Marcin Lewandowski POL Moskva 2013 1:44.26 Patrick Konchellah KEN Athinai 1997 All time Performance List at the World Championships Performance Performer