Notes-Cs-604-Computer-Network-Unit
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Building a Network
Building a network Data Communications and Computer Networks Lab EP1100 Ezzeldin Shereen Ming Zeng Peiyue Zhao Version 7.0 (2018) Department of Network and Systems Engineering School of Electrical Engineering and Computer Science KTH, Royal Institute of Technology Laboratory Manual 2 Chapter 1 Introduction 1.1 Purpose of the laboratory The main goal of this laboratory is to give you an overview of the different processes involved in building a network, such as a corporate network. You will have to plan the IP address scheme, configure and test the equipment, as well as configure several applications and servers typical of any corporate network (DNS servers for example). After you have completed the laboratory exercises, you should be familiar with the practical issues of the different concepts explained in the course, as well as with the real equipment used nowadays in computer networks. 1.2 Duties before the lab starts Students are required submit the homeworks before the lab starts. Students missing the homework submission will not be accepted to the lab. 1.2.1 Preparatory quizzes Each student has to complete two online lab entry quizzes, which can be found at the course web page. The quizzes are due on the first lab session, and the third. Their purpose is to check that you have enough theoretical knowledge of the tasks that you will perform in the lab. Since these tasks are not part of the course book, you will have to read this manual and its references carefully to pass the quizzes. 1.3 Rules of behavior in the laboratory 1. -

An Internet Protocol (IP) Address Is a Numerical Label That Is
Computer Communication Networks Lecture No. 5 Computer Network Lectures IP address An Internet Protocol (IP) address is a numerical label that is assigned to devices participating in a computer network, that uses the Internet Protocol for communication between its nodes. An IP address serves two principal functions: 1- host or network interface identification 2- location addressing. Its role has been characterized as follows: "A name indicates what we seek. An address indicates where it is. A route indicates how to get there." The designers of TCP/IP defined an IP address as a 32-bit number and this system, known as Internet Protocol Version 4 or IPv4, is still in use today. However, due to the enormous growth of the Internet and the resulting depletion of available addresses, a new addressing system (IPv6), using 128 bits for the address, was developed in 1995. Although IP addresses are stored as binary numbers, they are usually displayed in human-readable notations, such as 208.77.188.166 (for IPv4), and 2001:db8:0:1234:0:567:1:1 (for IPv6). The Internet Protocol also routes data packets between networks; IP addresses specify the locations of the source and destination nodes in the topology of the routing system. For this purpose, some of the bits in an IP address are used to designate a sub network. As the development of private networks raised the threat of IPv4 address exhaustion, RFC 1918 set aside a group of private address spaces that may be used by anyone on private networks. They are often used with network address translators to connect to the global public Internet. -

Subnet Mask Notation
Subnetting Subnetting is the process of breaking down an IP network into smaller sub- networks called “subnets.” Each subnet is a non-physical description (or ID) for a physical sub-network (usually a switched network of host containing a single router in a multi-router network). In many cases, subnets are created to serve as physical or geographical separations similar to those found between rooms, floors, buildings, or cities. There could be more than one definition for subnetting but perhaps the best explanation is that by default a network id has only one broadcast domain. Subnetting is a process of segmentation of a network id into multiple broadcast domains. Subnetting originally referred to the subdivision of a class-based network into many subnetworks, but now it generally refers to the subdivision of a CIDR block in to smaller CIDR blocks. Subnetting allows single routing entries to refer either to the larger block or to its individual constituents. This permits a single routing entry to be used though most of the Internet, more specific routes only being required for routers in the subnetted block. Most modern subnet definitions are created according to 3 main factors. These include: 1. The number of hosts that needs to exist on the subnet now and in the future. 2. The necessary security controls between networks. 3. The performance required for communications between hosts. Subnet Mask Notation There are two forms of subnet notation, standard notation and CIDR (Classless Internet Domain Routing) notation. Both versions of notation use a base address (or network address) to define the network’s starting point, such as 192.168.1.0. -

Understand Ipv4
LESSON 3.2 98-366 Networking Fundamentals UnderstandUnderstand IPv4IPv4 LESSON 3.2 98-366 Networking Fundamentals Lesson Overview In this lesson, you will learn about: APIPA addressing classful IP addressing and classless IP addressing gateway IPv4 local loopback IP NAT network classes reserved address ranges for local use subnetting static IP LESSON 3.2 98-366 Networking Fundamentals Anticipatory Set 1. Write the address range and broadcast address for the following subnet: Subnet: 192.168.1.128 / 255.255.255.224 Address Range? Subnet Broadcast Address? 2. Check your answer with those provided by the instructor. If it is different, review the method of how you derived the answer with your group and correct your understanding. LESSON 3.2 98-366 Networking Fundamentals IPv4 A connectionless protocol for use on packet-switched Link Layer networks like the Ethernet At the core of standards-based internetworking methods of the Internet Network addressing architecture redesign is underway via classful network design, Classless Inter-Domain Routing, and network address translation (NAT) . Microsoft Windows uses TCP/IP for IP version 4 (a networking protocol suite) to communicate over the Internet with other computers. It interacts with Windows naming services like WINS and security technologies. IPsec helps facilitate the successful and secure transfer of IP packets between computers. An IPv4 address shortage has been developing. LESSON 3.2 98-366 Networking Fundamentals Network Classes Provide a method for interacting with the network All networks have different sizes so IP address space is divided in different classes to meet different requirements. Each class fixes a boundary between the network prefix and the host within the 32-bit address. -

Microsoft® Official Academic Course: Networking Fundamentals, Exam
Microsoft® Official Academic Course Networking Fundamentals, Exam 98-366 VP & PUBLISHER Barry Pruett SENIOR EXECUTIVE EDITOR Jim Minatel MICROSOFT PRODUCT MANAGER Microsoft Learning SENIOR EDITORIAL ASSISTANT Devon Lewis TECHNICAL EDITOR Ron Handlon CHANNEL MARKETING MANAGER Michele Szczesniak CONTENT MANAGEMENT DIRECTOR Lisa Wojcik CONTENT MANAGER Nichole Urban PRODUCTION COORDINATOR Nicole Repasky PRODUCTION EDITOR Umamaheswari Gnanamani COVER DESIGNER Tom Nery COVER PHOTO: © shutterstock/wavebreakmedia Copyright © 2017 by John Wiley & Sons, Inc. All rights reserved. No part of this publication may be reproduced, stored in a retrieval system or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, scanning or otherwise, except as permitted under Sections 107 or 108 of the 1976 United States Copyright Act, without either the prior written permission of the Publisher, or authorization through payment of the appropriate per-copy fee to the Copyright Clearance Center, Inc. 222 Rosewood Drive, Danvers, MA 01923, (978) 750-8400, fax (978) 646-8600. Requests to the Publisher for permission should be addressed to the Permissions Department, John Wiley & Sons, Inc., 111 River Street, Hoboken, NJ 07030-5774, (201) 748-6011, fax (201) 748-6008. To order books or for customer service, please call 1-800-CALL WILEY (225-5945). Microsoft, Active Directory, AppLocker, Bing, BitLocker, Hyper-V, Internet Explorer, Microsoft Intune, Microsoft Office 365, SQL Server, Visual Studio, Windows Azure, Windows, Windows PowerShell, and Windows Server are either registered trademarks or trademarks of Microsoft Corporation in the United States and/or other countries. Other product and company names mentioned herein may be the trademarks of their respective owners. The example companies, organizations, products, domain names, e-mail addresses, logos, people, places, and events depicted herein are fictitious. -

IP Addressing
Introducing TCP/IP: Host Identifiers Multiple levels of naming • Highest level: human readable names • Domain names names like www.google.com • IP level: IP addresss • Two types : V4 or V6 A unified network requires a universal communication service. • Lowest level: machine addresses • Format depends on the lin,/physical layer • Many physical layers conform to the Ethernet standard • Ethernet frame includes a 6 octet source MAC address and 6 octet dst MAC address in the MAC header •In TCP/IP terminology, a Host is a computer that communicates with another computer using TCP/IP •The network between Host 1 and Host 2 can range from •directly connected by a physical cable (serial cable or USB cable). •This type of network is ‘point-to-point’ •Directly connected to the same Local Area Network (like Ethernet) •This type of network is ‘broadcast’ network- many Hosts can attach to the network. •When one Host sends, all Hosts receive. •A Host should ‘accept’ the frame only if the destination MAC address is 1)that of Host 2; 2)A broadcast (dst MAC address of all 1’s) •Indirectly connected - this means there is >1 network which implies there is a router •The Internet - implied indirectly connected. Host 1 generates frames over each link, contained in each frame is an IP datagram. •An IP network is able to deliver an IP datagram to the destination network specified in the IP header’s destination network field •A TCP/IP network is a number of autonomous networks that operate in a manner presenting a unified network to end users Host Identifiers •Host -
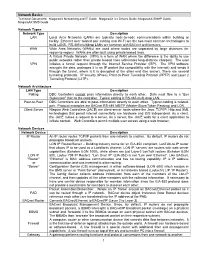
Niagaraax Networking and IT Guide; Niagaraax 3.X Drivers Guide; Niagaraax SNMP Guide; Niagaraax SMS Guide
Network Basics Technical Documents: NiagaraAX Networking and IT Guide; NiagaraAX 3.x Drivers Guide; NiagaraAX SNMP Guide; NiagaraAX SMS Guide Network Types Network Type Description LAN Local Area Networks (LANs) are typically node-to-node communications within building or facility. Ethernet over twisted pair cabling and Wi-Fi are the two most common technologies to build LANS. RS-485 multidrop LANs are common with BACnet architectures. WAN Wide Area Networks (WANs) are used where nodes are separated by large distances (ie, region-to-region). WANs are often built using private leased lines. A Virtual Private Network (VPN) is a form of WAN where the difference is the ability to use public networks rather than private leased lines (eliminates long-distance charges). The user VPN initiates a tunnel request through the Internet Service Provider (ISP). The VPN software encrypts the data, packages it in an IP packet (for compatibility with the Internet) and sends it through the tunnel, where is it is decrypted at the other end (the server). There are several tunneling protocols: IP security (IPsec), Point-to-Point Tunneling Protocol (PPTP) and Layer 2 Tunneling Protocol (L2TP). Network Architecture LAN Type Description Polling DDC Controllers cannot pass information directly to each other. Data must flow to a “Bus Supervisor” then to the controller. Typical cabling is RS-485 multi-drop LAN. Peer-to-Peer DDC Controllers are able to pass information directly to each other. Typical cabling is twisted- pair. Protocol examples are BACnet RS-485 MS/TP (Master-Slave/Token Passing) and LON. Client-Server Niagara Web Controllers (JACE) are client-server hosts where the Java, TCP/IP, Http and XML technologies that permit internet connectivity are hardware and O/S independent. -

Computer Networks a Computer Network Consists of Two Or More
Computer Networks A computer network consists of two or more computing devices that are connected in order to share the components of your network (its resources) and the information you store there. The most basic computer network (which consists of just two connected computers) can expand and become more usable when additional computers join and add their resources to those being shared. The first computer, yours, is commonly referred to as your local computer. It is more likely to be used as a location where you do work, a workstation, than as a storage or controlling location, a server. As more and more computers are connected to a network and share their resources, the network becomes a more powerful tool, because employees using a network with more information and more capability are able to accomplish more through those added computers or additional resources. The real power of networking computers becomes apparent if you envision your own network growing and then connecting it with other distinct networks, enabling communication and resource sharing across both networks. That is, one network can be connected to another network and become a more powerful tool because of the greater resources. Models of network Computing The three models for network computing are as follows: Centralized computing. Distributed computing. Collaborative or cooperative computing. Centralized Network Computing Model In the centralized network computing model, the clients use the resources of high-capacity servers to process information. In this model, the clients are also referred to as dumb terminals with very low or no processing capability. The clients only connect to the server and not to each other. -

Chapter 8 Classful IP Addressing Classful IP Addressing
8/19/2010 Chapter 8 Advanced TCP/IP Network Design Classful IP Addressing There are three basic classes of addresses known as class A, B, or C networks Classful IP Addressing Classful addresses are broken apart on octet boundaries. The first few bits of each segment address is used to denote the address class of the segment. The class ID plus network ID portions of the IP address are known as the network prefix, the network number, or the major network. 1 8/19/2010 Subnetting When IP address classes were established, networks were composed of a relatively small number of relatively expensive computers. As time went on and the PC exploded into LAN’s, the strict boundaries of the classful addressing address classes became restrictive and forced an inefficient allocation of addresses. Class C address with its limit of 254 hosts per network is too small for most organizations, while a Class B address with its limit of 65,534 hosts per subnet is too large. Subnetting Networks grew and needed to be divided or segmented in order to improve traffic flow. Routers join two separate networks. Networks that are separated by routers must have different network IDs so that the router can distinguish between them. This accelerated the depletion of IP addresses. RFC 950 RFC 950 gave users a way to subnet, or provide a third layer of organization or hierarchy between the existing network ID and the existing host ID. Since the network IDs could not be altered, the only choice was to “borrow” some of the host ID bits. -

IP Addresses: Classful Addressing
Chapter 4 CSC465 – Computer Networks Spring 2004 IP Addresses: Dr. J. Harrison Classful Addressing These slides were produced almost entirely from material by Behrouz Forouzan for the text “TCP/IP Protocol Suite (2nd Edition)”, McGraw Hill Publisher Classful Network Layer IP Address Space Addressing • To allow global communication, each Internet •232 = 4,294,967,296 device requires a unique identifier • Actual number much less due to self-imposed – Like unique phone number (country/area/local) restrictions • In the IP layer of TCP/IP, the ID is 32-bits • Uniquely and universally defines the connection of a host or router to the Internet • Classful addressing is one addressing mechanism of IPv4 • Classless addressing to be discussed Figure 4-1 Dotted-decimal notation Hexadecimal Notation 0111 0101 1001 0101 0001 1101 1110 1010 75 95 1D EA 0x75951DEA 1 Example 1 Change the following IP address from binary The binary, decimal, and notation to dotted-decimal notation. hexadecimal number 10000001 00001011 00001011 11101111 systems are reviewed in Appendix B. Appendix B. Solution 129.11.11.239 Example 2 Example 3 Change the following IP address from Find the error, if any, in the following IP dotted-decimal notation to binary notation. address: 111.56.45.78 111.56.045.78 Solution Solution 01101111 00111000 00101101 01001110 There are no leading zeroes in dotted-decimal notation (045). Example 3 (continued) Example 4 Find the error, if any, in the following IP Change the following IP addresses from address: binary notation to hexadecimal notation. 75.45.301.14 10000001 00001011 00001011 11101111 Solution Solution In dotted-decimal notation, 0X810B0BEF or 810B0BEF each number is less than or 16 equal to 255; 301 is outside this range. -

Ipv4 Addressing and Subnetting V1.41 – Aaron Balchunas 1
IPv4 Addressing and Subnetting v1.41 – Aaron Balchunas 1 - IPv4 Addressing and Subnetting - Hardware Addressing A hardware address is used to uniquely identify a host within a local network. Hardware addressing is a function of the Data-Link layer of the OSI model (Layer-2). Ethernet utilizes the 48-bit MAC address as its hardware address. The MAC address is often hardcoded on physical network interfaces, though some interfaces support changing the MAC address using special utilities. In virtualization environments, dynamically assigning MAC addresses is very common. A MAC address is most often represented in hexadecimal, using one of two accepted formats: 00:43:AB:F2:32:13 0043.ABF2.3213 The first six hexadecimal digits of a MAC address identify the manufacturer of the physical network interface. This is referred to as the OUI (Organizational Unique Identifier). The last six digits uniquely identify the host itself, and are referred to as the host ID . The MAC address has one shortcoming – it contains no hierarchy. MAC addresses provide no mechanism to create boundaries between networks. There is no method to distinguish one network from another. This lack of hierarchy poses significant difficulties to network scalability. If only Layer-2 hardware addressing existed, all hosts would technically exist on the same network. Internetworks like the Internet could not exist, as it would be impossible to separate my network from your network. Imagine if the entire Internet existed purely as a single Layer-2 switched network. Switches, as a rule, will forward a broadcast out every port. With billions of hosts on the Internet, the resulting broadcast storms would be devastating. -

Chapter 4: Outline
Chapter 4: outline Router two key router functions: 4.1 introduction 4.5 routing algorithms run routing algorithms/protocol (RIP, OSPF, BGP) 4.2 virtual circuit and . link state datagram networks . distance vector forwarding datagrams from incoming to outgoing link 4.3 what’s inside a router . hierarchical routing 4.4 IP: Internet Protocol 4.6 routing in the Internet . datagram format RIP . IPv4 addressing . OSPF . ICMP . BGP . IPv6 4.7 broadcast and multicast routing Network Layer 4-21 Network Layer 4-22 Router architecture overview Input port functions Main components: Line card . Input ports/Interfaces lookup, link forwarding . Switching fabric line layer switch termination protocol fabric . Output ports/Interfaces (receive) . Routing processor: (1)executing routing protocol, queueing (2)maintaining routing information, forwarding tables, etc. physical layer: bit-level reception Network layer – decentralized switching: data link layer: decapsulation, error Packet forwarding = decide which output checking, etc line to forward each packet based on packet header. queuing: if datagrams arrive faster than forwarding rate into switch fabric Network Layer 4-23 Network Layer 4-24 data link layer: Switching fabrics Output port encapsulation, physical layer: address mapping, etc bit-level forwarding Switching fabric function – transfer packets between input and output line cards datagram switch buffer link Types of switching fabric fabric layer line protocol termination . Via memory: datagram is received through input port, (send) stored