Building a Domain-Specific Search Engine That Explores Football
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Uefa Europa League - 2018/19 Season Match Press Kits
UEFA EUROPA LEAGUE - 2018/19 SEASON MATCH PRESS KITS José Alvalade - Lisbon Thursday 14 February 2019 21.00CET (20.00 local time) Sporting Clube de Villarreal CF Portugal Round of 32, First leg Last updated 19/04/2019 23:07CET Previous meetings 2 Match background 5 Team facts 7 Squad list 9 Fixtures and results 12 Match-by-match lineups 16 Match officials 18 Legend 20 1 Sporting Clube de Portugal - Villarreal CF Thursday 14 February 2019 - 21.00CET (20.00 local time) Match press kit José Alvalade, Lisbon Previous meetings Head to Head No UEFA competition matches have been played between these two teams Sporting Clube de Portugal - Record versus clubs from opponents' country UEFA Europa League Date Stage Match Result Venue Goalscorers Sporting Clube de Portugal - Club 1-0 12/04/2018 QF Lisbon Montero 28 Atlético de Madrid agg: 1-2 Club Atlético de Madrid - 05/04/2018 QF 2-0 Madrid Koke 1, Griezmann 40 Sporting Clube de Portugal UEFA Champions League Date Stage Match Result Venue Goalscorers FC Barcelona - Sporting Clube Paco Alcácer 59, 05/12/2017 GS 2-0 Barcelona de Portugal Mathieu 90+1 (og) Sporting Clube de Portugal - FC 27/09/2017 GS 0-1 Lisbon Coates 49 (og) Barcelona UEFA Champions League Date Stage Match Result Venue Goalscorers Adrien Silva 80 (P); Sporting Clube de Portugal - Real 22/11/2016 GS 1-2 Lisbon Varane 29, Benzema Madrid CF 87 Real Madrid CF - Sporting Clube Ronaldo 89, Morata 14/09/2016 GS 2-1 Madrid de Portugal 90+4; Bruno César 48 UEFA Europa League Date Stage Match Result Venue Goalscorers Susaeta 17, Ibai Athletic -

2018 Topps Champions League Museum Collection
BASE BASE CARDS 1 Lionel Messi FC BARCELONA 2 Andrés Iniesta FC BARCELONA 3 Dele Alli Tottenham Hotspur 4 Robert Lewandowski FC Bayern München 5 Stephan el-Shaarawy AS Roma 6 Alvaro Morata Chelsea FC 7 Michael Lang FC Basel 1893 8 Eden Hazard Chelsea FC 9 Marcelo Real Madrid C.F. 10 Ederson Manchester City FC 11 Romelu Lukaku Manchester United 12 Danny Rose Tottenham Hotspur 13 Sadio Mané Liverpool FC 14 Mats Hummels FC Bayern München 15 Ryan Babel Beşiktaş J.K. 16 Edin Džeko AS Roma 17 Mohamed Salah Liverpool FC 18 Oğuzhan Özyakup Beşiktaş J.K. 19 Marcus Rashford Manchester United 20 Gareth Bale Real Madrid C.F. 21 Christian Eriksen Tottenham Hotspur 22 Pepe Beşiktaş J.K. 23 Ricardo Quaresma Beşiktaş J.K. 24 Paul Pogba Manchester United 25 Harry Kane Tottenham Hotspur 26 Jesús Navas Sevilla FC 27 Thiago Silva Paris Saint-Germain 28 Ricky van Wolfswinkel FC Basel 1893 29 Aleksandar Kolarov AS Roma 30 Radja Nainggolan AS Roma 31 Kylian Mbappé Paris Saint-Germain 32 Jesús Corona FC Porto 33 Edinson Cavani Paris Saint-Germain 34 César Azpilicueta Chelsea FC 35 Gonzalo Higuaín Juventus 36 Anthony Martial Manchester United 37 Marc-André ter Stegen FC BARCELONA 38 Tomáš Vaclík FC Basel 1893 39 Keylor Navas Real Madrid C.F. 40 David de Gea Manchester United 41 Hugo Lloris Tottenham Hotspur 42 Steven N'Zonzi Sevilla FC 43 Kevin De Bruyne Manchester City FC 44 Vincent Aboubakar FC Porto 45 N'Golo Kanté Chelsea FC 46 Luis Suárez FC BARCELONA 47 Kevin Bua FC Basel 1893 48 Sergio Rico Sevilla FC 49 Marco Asensio Real Madrid C.F. -

A Football Journal by Football Radar Analysts
FFoooottbbaallll RRAADDAARR RROOLLIIGGAANN JJOOUURRNNAALL IISSSSUUEE FFOOUURR a football journal BY football radar analysts X Contents GENERATION 2019: YOUNG PLAYERS 07 Football Radar Analysts profile rising stars from around the globe they tip to make it big in 2019. the visionary of nice 64 New ownership at OGC Nice has resulted in the loss of visionary President Jean-Pierre Rivere. Huddersfield: a new direction 68 Huddersfield Town made the bold decision to close their academy, could it be a good idea? koncept, Kompetenz & kapital 34 Stepping in as Leipzig coach once more, Ralf Rangnick's modern approach again gets results. stabaek's golden generation 20 Struggling Stabaek's heavy focus on youth reaps rewards in Norway's Eliteserien. bruno and gedson 60 FR's Portuguese analysts look at two players named Fernandes making waves in Liga Nos. j.league team of the season 24 The 2018 season proved as unpredictable as ever but which players stood out? Skov: THE DANISH SNIPER 38 A meticulous appraisal of Danish winger Robert Skov's dismantling of the Superligaen. europe's finishing school 43 Belgium's Pro League has a reputation for producing world class talent, who's next? AARON WAN-BISSAKA 50 The Crystal Palace full back is a talented young footballer with an old fashioned attitude. 21 under 21 in ligue 1 74 21 young players to keep an eye on in a league ideally set up for developing youth. milan's next great striker? 54 Milan have a history of legendary forwards, can Patrick Cutrone become one of them? NICOLO BARELLA: ONE TO WATCH 56 Cagliari's midfielder has become crucial for both club and country. -

Resultado Final Da Prova Objetiva E Resultado Da Prova
GOVERNO DO ESTADO DO RIO DE JANEIRO COMPANHIA ESTADUAL DE ÁGUAS E ESGOTOS - CEDAE EDITAL DISPÕE SOBRE A SELEÇÃO PÚBLICA PARA PROVIMENTO DE EMPREGOS PÚBLICOS E PREENCHIMENTO DE VAGAS DE NÍVEIS UNIVERSITÁRIO E MÉDIO TÉCNICO, SOB O REGIME CLT, DA COMPANHIA ESTADUAL DE ÁGUAS E ESGOTOS DO ESTADO DO RIO DE JANEIRO - CEDAE O Presidente da Companhia Estadual de Água e Esgoto - CEDAE, no uso das atribuições que lhe são conferidas pela Legislação em vigor, torna públicos o Resultado do julgamento dos Pedidos de Recontagem de Pontos da Prova Objetiva, o Resultado Final da Seleção Pública para todos os empregos, exceto Advogado, o Resultado Final da Prova Objetiva para Advogado e o Resultado Preliminar da Prova Discursiva para Advogado, da Seleção Pública para preenchimento de vagas e provimento de empregos públicos de Níveis Universitário e Médio Técnico, sob o regime da Consolidação das Leis do Trabalho – CLT, da Companhia Estadual de Águas e Esgotos do Estado do Rio de Janeiro – CEDAE. 1. Resultado do Julgamento dos Pedidos de Recontagem de Pontos da Prova Objetiva Analisados os Pedidos de Recontagem de Pontos, foi julgada procedente a seguinte correção: Cargo: Advogado Candidata: EDNA LUCIA GUERRA LOFRANO Inscrição: 721792 Tipo de Vaga - Deficiente Pontuação total - 26 Português - 2 Conhecimentos Específicos - 24 2. Resultado Final da Seleção Pública, com a classificação dos candidatos aprovados, para todos os empregos, exceto Advogado Nível Superior Analista de Qualidade Biologo e Biomedico - Regular class Inscricao nome Objetiva espe port info>= -

P15 Layout 1
THURSDAY, SEPTEMBER 28, 2017 SPORTS Roma grind out 2-1 win at battling Qarabag BAKU: Roma ended its poor away “We should have finished it off in the the visitors a seventh minute lead underside of the bar on its way in. Eusebio Di Francesco brought on record in the Champions League with a first half, instead we conceded the goal when goalkeeper Ibrahim Sehic poor- It was Dzeko’s sixth goal in his past experienced midfielder Daniele De labored 2-1 victory at Qarabag yester- and we suffered. But at the end we got ly punched a corner straight at four matches. However, Roma paid the Rossi in an attempt to gain more con- day. Kostas Manolas and Edin Dzeko the three points.” Lorenzo Pellegrini, who volleyed it in price for its complacency when trol of the match. gave Roma a comfortable 2-0 lead Though Roma had only won one of for Manolas’ diving header. Maxime Gonalons was caught in pos- The home side almost snatched an inside the opening quarter of an hour, its past 13 matches on its travels in Roma doubled its advantage eight session by Dino Ndlovu who sent in a equalizer in the final minute but but Pedro Henrique reduced the deficit the competition, beating Basel in minutes later with a well-worked move through ball for Henrique to blast into Ndlovu headed just past the left post. in the 28th minute with Qarabag’s first 2009, it was hopeful of ending that that ended with Stephan El Shaarawy the back of the net. -

What Characteristics Do Sporting Cp Members Perceive for the Next Board President?
WHAT CHARACTERISTICS DO SPORTING CP MEMBERS PERCEIVE FOR THE NEXT BOARD PRESIDENT? Francisco Martins Bação Saraiva 80023 MMA2 Case Study of Master in Marketing Supervisor: Prof. José Pedro da Cunha Catalão Dionísio, Prof. Associado ISCTE Business School, Departamento de Marketing, Operações e Gestão Geral October 2019 WHAT CHARACTERISTICS DO SPORTING CP FANS PERCEIVE FOR THE NEXT BOARD PRESIDENT? Página | 2 WHAT CHARACTERISTICS DO SPORTING CP FANS PERCEIVE FOR THE NEXT BOARD PRESIDENT? Acknowledgments First of all, I want to thank Professor Pedro Dionísio for accepting to guide me throughout all the phases of this case study. I want to thank him for all the availability demonstrated, the knowledge transmitted, but also for all the support, encouragement and rigour when I most needed it. And for all those who contributed to this project being part of the focus groups with their contribution with the necessary information they were a tremendous help. To my family – my parents and my sister – for their support during this journey, for all the concern, comprehension and the emotional support and investment made since the first moment. To Beatriz Morais, that during this journey was able to understand all the phases of this long path and gave her support every time I asked for. To my friends from university, that throughout during this journey gave their strength and motivation working side by side. An especial word to Manuel Ramalho and Duarte Silva that were always here to incentive my work. To my childhood friends, especially for the comprehension in all those times when I was not able to join them while I was working to reach this stage. -

2018 Topps Museum UEFA Champions League Soccer
2018 Museum Collection UEFA Champions League Team Checklist 22 Teams - 20 with Hits (Sevilla FC and AC Roma = base only) Player Set Card # Team Print Run Fabinho Auto - Archival + Parallels AA-F AS Monaco FC Unknown + 151 Fabinho Auto Relic - Momentous Material + Parallels AJR-F AS Monaco FC 175 or less Fabinho Auto Relic - Museum + Parallels MAR-F AS Monaco FC 250 or less Jemerson Auto - Archival + Parallels AA-JE AS Monaco FC Unknown + 151 Jemerson Auto Relic - Momentous Material + Parallels AJR-J AS Monaco FC 175 or less Jemerson Auto Relic - Museum + Parallels MAR-J AS Monaco FC 250 or less João Moutinho Auto - Archival + Parallels AA-JM AS Monaco FC Unknown + 151 João Moutinho Auto - Dual Player + Emerald 1/1 Parallel ADA-FM AS Monaco FC 26 or less João Moutinho Auto - Framed + Parallels FA-JM AS Monaco FC 76 or less João Moutinho Auto Relic - Momentous Material + Parallels AJR-JMO AS Monaco FC 175 or less João Moutinho Auto Relic - Museum + Parallels MAR-JMO AS Monaco FC 250 or less João Moutinho Auto Relic - Single Player Triple Relic + Parallels MTR-JMO AS Monaco FC 36 João Moutinho Relic - Meaningful Material Single Relic + Parallels MMSR-JMO AS Monaco FC 250 or less João Moutinho Relic - Momentous Material Prime Patch + 1/1 Emerald Parallel MMPP-JMO AS Monaco FC 11 or less João Moutinho Relic - Single Player Triple Relics + Parallels MTR-JMO AS Monaco FC 101 or less Radamel Falcao Auto - Archival + Parallels AA-RF AS Monaco FC Unknown + 151 Radamel Falcao Auto - Dual Player + Emerald 1/1 Parallel ADA-FM AS Monaco FC 26 or less -

Uefa Champions League
UEFA CHAMPIONS LEAGUE - 2021/22 SEASON MATCH PRESS KITS (First leg: 1-2) Phillips Stadium - Eindhoven Tuesday 24 August 2021 PSV Eindhoven 21.00CET (21.00 local time) SL Benfica Play-off, Second leg Last updated 15/09/2021 16:37CET UEFA CHAMPIONS LEAGUE OFFICIAL SPONSORS Previous meetings 2 Match background 5 Squad list 8 Match officials 12 Fixtures and results 13 Match-by-match lineups 16 Team facts 18 Legend 20 1 PSV Eindhoven - SL Benfica Tuesday 24 August 2021 - 21.00CET (21.00 local time) Match press kit Phillips Stadium, Eindhoven Previous meetings Head to Head UEFA Champions League Date Stage Match Result Venue Goalscorers Rafa Silva 10, Weigl 18/08/2021 PO SL Benfica - PSV Eindhoven 2-1 Lisbon 42; Gakpo 51 UEFA Europa League Date Stage Match Result Venue Goalscorers Dzsudzsák 17, Lens 2-2 14/04/2011 QF PSV Eindhoven - SL Benfica Eindhoven 25; Luisão 45+2, agg: 3-6 Cardozo 63 (P) Aimar 37, Salvio 45, 07/04/2011 QF SL Benfica - PSV Eindhoven 4-1 Lisbon 52, Saviola 90+4; Labyad 80 UEFA Champions League Date Stage Match Result Venue Goalscorers Khokhlov 41, Van 09/12/1998 GS PSV Eindhoven - SL Benfica 2-2 Eindhoven Nistelrooy 89; Nuno Gomes 47 (P), 64 Nuno Gomes 47, 30/09/1998 GS SL Benfica - PSV Eindhoven 2-1 Lisbon João Pinto 76; Rommedahl 70 European Champions Clubs' Cup Date Stage Match Result Venue Goalscorers 0-0 25/05/1988 F PSV Eindhoven - SL Benfica Stuttgart (aet, 6-5 pens) UEFA Cup Winners' Cup Date Stage Match Result Venue Goalscorers Jesus Coelho 24; W. -
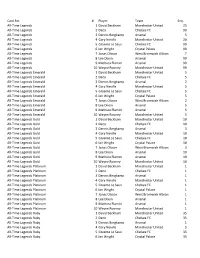
Card Set # Player Team Seq. All-Time Legends 1 David Beckham
Card Set # Player Team Seq. All-Time Legends 1 David Beckham Manchester United 25 All-Time Legends 2 Deco Chelsea FC 99 All-Time Legends 3 Dennis Bergkamp Arsenal 5 All-Time Legends 4 Gary Neville Manchester United 20 All-Time Legends 5 Graeme Le Saux Chelsea FC 99 All-Time Legends 6 Ian Wright Crystal Palace 99 All-Time Legends 7 Jonas Olsson West Bromwich Albion 7 All-Time Legends 8 Lee Dixon Arsenal 99 All-Time Legends 9 Mathieu Flamini Arsenal 99 All-Time Legends 10 Wayne Rooney Manchester United 99 All-Time Legends Emerald 1 David Beckham Manchester United 5 All-Time Legends Emerald 2 Deco Chelsea FC 5 All-Time Legends Emerald 3 Dennis Bergkamp Arsenal 2 All-Time Legends Emerald 4 Gary Neville Manchester United 5 All-Time Legends Emerald 5 Graeme Le Saux Chelsea FC 5 All-Time Legends Emerald 6 Ian Wright Crystal Palace 5 All-Time Legends Emerald 7 Jonas Olsson West Bromwich Albion 2 All-Time Legends Emerald 8 Lee Dixon Arsenal 5 All-Time Legends Emerald 9 Mathieu Flamini Arsenal 5 All-Time Legends Emerald 10 Wayne Rooney Manchester United 5 All-Time Legends Gold 1 David Beckham Manchester United 10 All-Time Legends Gold 2 Deco Chelsea FC 10 All-Time Legends Gold 3 Dennis Bergkamp Arsenal 3 All-Time Legends Gold 4 Gary Neville Manchester United 10 All-Time Legends Gold 5 Graeme Le Saux Chelsea FC 10 All-Time Legends Gold 6 Ian Wright Crystal Palace 10 All-Time Legends Gold 7 Jonas Olsson West Bromwich Albion 3 All-Time Legends Gold 8 Lee Dixon Arsenal 10 All-Time Legends Gold 9 Mathieu Flamini Arsenal 10 All-Time Legends Gold 10 Wayne -

European Qualifiers
EUROPEAN QUALIFIERS - 2019/20 SEASON MATCH PRESS KITS Stade Josy Barthel - Luxembourg Sunday 17 November 2019 15.00CET (15.00 local time) Luxembourg Group B - Matchday 10 Portugal Last updated 17/11/2019 13:48CET EUROPEAN QUALIFIERS OFFICIAL SPONSORS Previous meetings 2 Squad list 4 Head coach 6 Match officials 7 Match-by-match lineups 8 Legend 10 1 Luxembourg - Portugal Sunday 17 November 2019 - 15.00CET (15.00 local time) Match press kit Stade Josy Barthel, Luxembourg Previous meetings Head to Head 2020 UEFA European Championship Stage Date Match Result Venue Goalscorers reached Bernardo Silva 16, 11/10/2019 QR (GS) Portugal - Luxembourg 3-0 Lisbon Ronaldo 65, Gonçalo Guedes 89 FIFA World Cup Stage Date Match Result Venue Goalscorers reached Varela 30, Nani 37, 15/10/2013 QR (GS) Portugal - Luxembourg 3-0 Coimbra Hélder Postiga 79 Da Mota 14; Ronaldo 07/09/2012 QR (GS) Luxembourg - Portugal 1-2 Luxembourg 27, Hélder Postiga 54 FIFA World Cup Stage Date Match Result Venue Goalscorers reached Jorge Andrade 24, Ricardo Carvalho 30, 03/09/2005 QR (GS) Portugal - Luxembourg 6-0 Faro-Loulé Pauleta 38, 57, Simão 80, 85 Federspiel 11 (og), 17/11/2004 QR (GS) Luxembourg - Portugal 0-5 Luxembourg Ronaldo 27, Maniche 51, Pauleta 66, 83 FIFA World Cup Stage Date Match Result Venue Goalscorers reached Rui Águas 43, 51, 11/10/1989 QR (GS) Luxembourg - Portugal 0-3 Saarbrucken Barros 72 16/11/1988 QR (GS) Portugal - Luxembourg 1-0 Porto Fernando Gomes 31 FIFA World Cup Stage Date Match Result Venue Goalscorers reached Schmit 27, 53, 56, 84; 08/10/1961 -

Uefa Champions League - 2021/22 Season Match Press Kits
UEFA CHAMPIONS LEAGUE - 2021/22 SEASON MATCH PRESS KITS Estádio José Alvalade - Lisbon Wednesday 15 September 2021 21.00CET (20.00 local time) Sporting Clube de AFC Ajax Portugal Group C - Matchday 1 Last updated 29/09/2021 17:35CET UEFA CHAMPIONS LEAGUE OFFICIAL SPONSORS Previous meetings 2 Match background 5 Squad list 8 Match officials 12 Fixtures and results 13 Match-by-match lineups 16 Competition facts 17 Team facts 19 Legend 21 1 Sporting Clube de Portugal - AFC Ajax Wednesday 15 September 2021 - 21.00CET (20.00 local time) Match press kit Estádio José Alvalade, Lisbon Previous meetings Head to Head UEFA Cup Date Stage Match Result Venue Goalscorers AFC Ajax - Sporting Clube de 1-2 Verkuyl 80; Pereira 05/10/1988 R1 Amsterdam Portugal agg: 3-6 21, Ribeiro 87 Oceano 5, Bacinello Sporting Clube de Portugal - 20 (P), Barbosa 24, 07/09/1988 R1 4-2 Lisbon AFC Ajax Litos 76 (P); Pettersson 16, 79 Home Away Final Total Pld W D L Pld W D L Pld W D L Pld W D L GF GA Sporting Clube de Portugal 1 1 0 0 1 1 0 0 0 0 0 0 2 2 0 0 6 3 AFC Ajax 1 0 0 1 1 0 0 1 0 0 0 0 2 0 0 2 3 6 Sporting Clube de Portugal - Record versus clubs from opponents' country UEFA Europa League Date Stage Match Result Venue Goalscorers Luiz Phellype 9, Sporting Clube de Portugal - 28/11/2019 GS 4-0 Lisbon Bruno Fernandes 16, PSV Eindhoven 64 (P), Mathieu 43 Malen 19, Coates 25 PSV Eindhoven - Sporting Clube (og), Baumgartl 48; 19/09/2019 GS 3-2 Eindhoven de Portugal Bruno Fernandes 38 (P), Pedro Mendes 82 UEFA Europa League Date Stage Match Result Venue Goalscorers Sporting -

SL Benfica Vitória FC
JORNADA 7 SL Benfica Vitória FC Sábado, 28 de Setembro 2019 - 19:00 Estádio do Sport Lisboa e Benfica (Luz), Lisboa ORGANIZADOR POWERED BY Jornada 7 SL Benfica X Vitória FC 2 Confronto histórico Ver mais detalhes SL Benfica 119 28 30 Vitória FC GOLOS / MÉDIA VITÓRIAS EMPATES VITÓRIAS GOLOS / MÉDIA 458 golos marcados, uma média de 2,59 golos/jogo 67% 16% 17% 188 golos marcados, uma média de 1,06 golos/jogo TOTAL SL BENFICA (CASA) VITÓRIA FC (CASA) CAMPO NEUTRO J SLB E VFC GOLOS SLB E VFC GOLOS SLB E VFC GOLOS SLB E VFC GOLOS Total 177 119 28 30 458 188 73 10 5 275 71 45 18 24 181 115 1 0 1 2 2 Liga NOS 142 102 23 17 389 145 61 8 2 232 58 41 15 15 157 87 0 0 0 0 0 Taça de Portugal 21 11 2 8 44 30 8 1 0 27 7 3 1 7 16 21 0 0 1 1 2 Supertaça Cândido de Oliveira 1 1 0 0 1 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 0 Allianz Cup 4 1 2 1 7 5 1 1 0 4 1 0 1 1 3 4 0 0 0 0 0 Campeonato de Lisboa 9 4 1 4 17 8 3 0 3 12 5 1 1 1 5 3 0 0 0 0 0 J=Jogos, E=Empates, SLB=SL Benfica, VFC=Vitória FC FACTOS SL BENFICA FACTOS VITÓRIA FC TOTAIS TOTAIS 67% derrotas 67% vitórias 63% em que marcou 89% em que marcou 89% em que sofreu golos 63% em que sofreu golos MÁXIMO MÁXIMO 2 Jogos a vencer 1999-02-16 -> 1999-05-10 10 Jogos a vencer 1946-03-03 -> 1950-04-23 26 Jogos sem vencer 1935-01-20 -> 1951-01-28 4 Jogos sem vencer 1925-12-06 -> 1927-03-20 10 Jogos a perder 1946-03-03 -> 1950-04-23 2 Jogos a perder 1999-02-16 -> 1999-05-10 4 Jogos sem perder 1925-12-06 -> 1927-03-20 26 Jogos sem perder 1935-01-20 -> 1951-01-28 RECORDES SL BENFICA: MAIOR VITÓRIA EM CASA I Divisão 1953/54