Music Artist Identification Using Linear Temporal Pyramid Matching
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Songs by Title Karaoke Night with the Patman
Songs By Title Karaoke Night with the Patman Title Versions Title Versions 10 Years 3 Libras Wasteland SC Perfect Circle SI 10,000 Maniacs 3 Of Hearts Because The Night SC Love Is Enough SC Candy Everybody Wants DK 30 Seconds To Mars More Than This SC Kill SC These Are The Days SC 311 Trouble Me SC All Mixed Up SC 100 Proof Aged In Soul Don't Tread On Me SC Somebody's Been Sleeping SC Down SC 10CC Love Song SC I'm Not In Love DK You Wouldn't Believe SC Things We Do For Love SC 38 Special 112 Back Where You Belong SI Come See Me SC Caught Up In You SC Dance With Me SC Hold On Loosely AH It's Over Now SC If I'd Been The One SC Only You SC Rockin' Onto The Night SC Peaches And Cream SC Second Chance SC U Already Know SC Teacher, Teacher SC 12 Gauge Wild Eyed Southern Boys SC Dunkie Butt SC 3LW 1910 Fruitgum Co. No More (Baby I'm A Do Right) SC 1, 2, 3 Redlight SC 3T Simon Says DK Anything SC 1975 Tease Me SC The Sound SI 4 Non Blondes 2 Live Crew What's Up DK Doo Wah Diddy SC 4 P.M. Me So Horny SC Lay Down Your Love SC We Want Some Pussy SC Sukiyaki DK 2 Pac 4 Runner California Love (Original Version) SC Ripples SC Changes SC That Was Him SC Thugz Mansion SC 42nd Street 20 Fingers 42nd Street Song SC Short Dick Man SC We're In The Money SC 3 Doors Down 5 Seconds Of Summer Away From The Sun SC Amnesia SI Be Like That SC She Looks So Perfect SI Behind Those Eyes SC 5 Stairsteps Duck & Run SC Ooh Child SC Here By Me CB 50 Cent Here Without You CB Disco Inferno SC Kryptonite SC If I Can't SC Let Me Go SC In Da Club HT Live For Today SC P.I.M.P. -
112 It's Over Now 112 Only You 311 All Mixed up 311 Down
112 It's Over Now 112 Only You 311 All Mixed Up 311 Down 702 Where My Girls At 911 How Do You Want Me To Love You 911 Little Bit More, A 911 More Than A Woman 911 Party People (Friday Night) 911 Private Number 10,000 Maniacs More Than This 10,000 Maniacs These Are The Days 10CC Donna 10CC Dreadlock Holiday 10CC I'm Mandy 10CC I'm Not In Love 10CC Rubber Bullets 10CC Things We Do For Love, The 10CC Wall Street Shuffle 112 & Ludacris Hot & Wet 1910 Fruitgum Co. Simon Says 2 Evisa Oh La La La 2 Pac California Love 2 Pac Thugz Mansion 2 Unlimited No Limits 20 Fingers Short Dick Man 21st Century Girls 21st Century Girls 3 Doors Down Duck & Run 3 Doors Down Here Without You 3 Doors Down Its not my time 3 Doors Down Kryptonite 3 Doors Down Loser 3 Doors Down Road I'm On, The 3 Doors Down When I'm Gone 38 Special If I'd Been The One 38 Special Second Chance 3LW I Do (Wanna Get Close To You) 3LW No More 3LW No More (Baby I'm A Do Right) 3LW Playas Gon' Play 3rd Strike Redemption 3SL Take It Easy 3T Anything 3T Tease Me 3T & Michael Jackson Why 4 Non Blondes What's Up 5 Stairsteps Ooh Child 50 Cent Disco Inferno 50 Cent If I Can't 50 Cent In Da Club 50 Cent In Da Club 50 Cent P.I.M.P. (Radio Version) 50 Cent Wanksta 50 Cent & Eminem Patiently Waiting 50 Cent & Nate Dogg 21 Questions 5th Dimension Aquarius_Let the sunshine inB 5th Dimension One less Bell to answer 5th Dimension Stoned Soul Picnic 5th Dimension Up Up & Away 5th Dimension Wedding Blue Bells 5th Dimension, The Last Night I Didn't Get To Sleep At All 69 Boys Tootsie Roll 8 Stops 7 Question -

Songs by Artist
73K October 2013 Songs by Artist 73K October 2013 Title Title Title +44 2 Chainz & Chris Brown 3 Doors Down When Your Heart Stops Countdown Let Me Go Beating 2 Evisa Live For Today 10 Years Oh La La La Loser Beautiful 2 Live Crew Road I'm On, The Through The Iris Do Wah Diddy Diddy When I'm Gone Wasteland Me So Horny When You're Young 10,000 Maniacs We Want Some P---Y! 3 Doors Down & Bob Seger Because The Night 2 Pac Landing In London Candy Everybody Wants California Love 3 Of A Kind Like The Weather Changes Baby Cakes More Than This Dear Mama 3 Of Hearts These Are The Days How Do You Want It Arizona Rain Trouble Me Thugz Mansion Love Is Enough 100 Proof Aged In Soul Until The End Of Time 30 Seconds To Mars Somebody's Been Sleeping 2 Pac & Eminem Closer To The Edge 10cc One Day At A Time Kill, The Donna 2 Pac & Eric Williams Kings And Queens Dreadlock Holiday Do For Love 311 I'm Mandy 2 Pac & Notorious Big All Mixed Up I'm Not In Love Runnin' Amber Rubber Bullets 2 Pistols & Ray J Beyond The Gray Sky Things We Do For Love, The You Know Me Creatures (For A While) Wall Street Shuffle 2 Pistols & T Pain & Tay Dizm Don't Tread On Me We Do For Love She Got It Down 112 2 Unlimited First Straw Come See Me No Limits Hey You Cupid 20 Fingers I'll Be Here Awhile Dance With Me Short Dick Man Love Song It's Over Now 21 Demands You Wouldn't Believe Only You Give Me A Minute 38 Special Peaches & Cream 21st Century Girls Back Where You Belong Right Here For You 21St Century Girls Caught Up In You U Already Know 3 Colours Red Hold On Loosely 112 & Ludacris Beautiful Day If I'd Been The One Hot & Wet 3 Days Grace Rockin' Into The Night 12 Gauge Home Second Chance Dunkie Butt Just Like You Teacher, Teacher 12 Stones 3 Doors Down Wild Eyed Southern Boys Crash Away From The Sun 3LW Far Away Be Like That I Do (Wanna Get Close To We Are One Behind Those Eyes You) 1910 Fruitgum Co. -

Foreign Impales
Page 10 Daily Nebraskan Monday, April 22, 1985 n ri Airii ri CornstockXV 'WW1 will 4 feature vj movie, bands By BM Allen MacLean and the other 15 final- Rock bands, musical comediannes, a ists for Staff Reporter competed the champion- hypnotist and movies are all on the in two ships other events besides agenda for the East Campus Cornstock UN'L junior Mike MacLean spent consecutive kicks: week celebration, which begins today. last weekend "footbagging" in Footbag Freestyle, where scor- Dona Lovegrove, Cornstock chair- based on and Chicago. ing is originality style. woman, said this is the 15th year of for No, he didn't get arrested Footbag Net, where players J s'' Cornstock, a last fling before the school it. As a of the Sack back and doing matter fact, the only pass Hacky forth year ends. five-foo- t reason he was there is because he over a like a "no y net, Previously, Cornstock was a one-da- can better than hands" is footbag anyone volleyball. Competition Y event and the week leading up to it was or.e-on-on- e is like around here. and scored tennis. called Western Week, Lovegrove, a jun- Sack en- MacLean Footbagging, as Hacky said he concentrated ior business administration major, said. thusiasts is the his v.wkouts for finals on i, i know, keeping small, the just A1 But this year the entire week will be pellet-fslle- d leather sack airborne the consecutive kicks event, because called Cornstock Week. knees and where he stood the best East-sponsore- using only your feet, that's The schedule for the UPC d MacLean, a finance major, was chiir.ee of winning. -

Songs by Artist
Sound Master Entertianment Songs by Artist smedenver.com Title Title Title .38 Special 2Pac 4 Him Caught Up In You California Love (Original Version) For Future Generations Hold On Loosely Changes 4 Non Blondes If I'd Been The One Dear Mama What's Up Rockin' Onto The Night Thugz Mansion 4 P.M. Second Chance Until The End Of Time Lay Down Your Love Wild Eyed Southern Boys 2Pac & Eminem Sukiyaki 10 Years One Day At A Time 4 Runner Beautiful 2Pac & Notorious B.I.G. Cain's Blood Through The Iris Runnin' Ripples 100 Proof Aged In Soul 3 Doors Down That Was Him (This Is Now) Somebody's Been Sleeping Away From The Sun 4 Seasons 10000 Maniacs Be Like That Rag Doll Because The Night Citizen Soldier 42nd Street Candy Everybody Wants Duck & Run 42nd Street More Than This Here Without You Lullaby Of Broadway These Are Days It's Not My Time We're In The Money Trouble Me Kryptonite 5 Stairsteps 10CC Landing In London Ooh Child Let Me Be Myself I'm Not In Love 50 Cent We Do For Love Let Me Go 21 Questions 112 Loser Disco Inferno Come See Me Road I'm On When I'm Gone In Da Club Dance With Me P.I.M.P. It's Over Now When You're Young 3 Of Hearts Wanksta Only You What Up Gangsta Arizona Rain Peaches & Cream Window Shopper Love Is Enough Right Here For You 50 Cent & Eminem 112 & Ludacris 30 Seconds To Mars Patiently Waiting Kill Hot & Wet 50 Cent & Nate Dogg 112 & Super Cat 311 21 Questions All Mixed Up Na Na Na 50 Cent & Olivia 12 Gauge Amber Beyond The Grey Sky Best Friend Dunkie Butt 5th Dimension 12 Stones Creatures (For A While) Down Aquarius (Let The Sun Shine In) Far Away First Straw AquariusLet The Sun Shine In 1910 Fruitgum Co. -

Songs by Artist
Songs by Artist Title Title (Hed) Planet Earth 2 Live Crew Bartender We Want Some Pussy Blackout 2 Pistols Other Side She Got It +44 You Know Me When Your Heart Stops Beating 20 Fingers 10 Years Short Dick Man Beautiful 21 Demands Through The Iris Give Me A Minute Wasteland 3 Doors Down 10,000 Maniacs Away From The Sun Because The Night Be Like That Candy Everybody Wants Behind Those Eyes More Than This Better Life, The These Are The Days Citizen Soldier Trouble Me Duck & Run 100 Proof Aged In Soul Every Time You Go Somebody's Been Sleeping Here By Me 10CC Here Without You I'm Not In Love It's Not My Time Things We Do For Love, The Kryptonite 112 Landing In London Come See Me Let Me Be Myself Cupid Let Me Go Dance With Me Live For Today Hot & Wet Loser It's Over Now Road I'm On, The Na Na Na So I Need You Peaches & Cream Train Right Here For You When I'm Gone U Already Know When You're Young 12 Gauge 3 Of Hearts Dunkie Butt Arizona Rain 12 Stones Love Is Enough Far Away 30 Seconds To Mars Way I Fell, The Closer To The Edge We Are One Kill, The 1910 Fruitgum Co. Kings And Queens 1, 2, 3 Red Light This Is War Simon Says Up In The Air (Explicit) 2 Chainz Yesterday Birthday Song (Explicit) 311 I'm Different (Explicit) All Mixed Up Spend It Amber 2 Live Crew Beyond The Grey Sky Doo Wah Diddy Creatures (For A While) Me So Horny Don't Tread On Me Song List Generator® Printed 5/12/2021 Page 1 of 334 Licensed to Chris Avis Songs by Artist Title Title 311 4Him First Straw Sacred Hideaway Hey You Where There Is Faith I'll Be Here Awhile Who You Are Love Song 5 Stairsteps, The You Wouldn't Believe O-O-H Child 38 Special 50 Cent Back Where You Belong 21 Questions Caught Up In You Baby By Me Hold On Loosely Best Friend If I'd Been The One Candy Shop Rockin' Into The Night Disco Inferno Second Chance Hustler's Ambition Teacher, Teacher If I Can't Wild-Eyed Southern Boys In Da Club 3LW Just A Lil' Bit I Do (Wanna Get Close To You) Outlaw No More (Baby I'ma Do Right) Outta Control Playas Gon' Play Outta Control (Remix Version) 3OH!3 P.I.M.P. -

DAN KELLY's Ipod 80S PLAYLIST It's the End of The
DAN KELLY’S iPOD 80s PLAYLIST It’s The End of the 70s Cherry Bomb…The Runaways (9/76) Anarchy in the UK…Sex Pistols (12/76) X Offender…Blondie (1/77) See No Evil…Television (2/77) Police & Thieves…The Clash (3/77) Dancing the Night Away…Motors (4/77) Sound and Vision…David Bowie (4/77) Solsbury Hill…Peter Gabriel (4/77) Sheena is a Punk Rocker…Ramones (7/77) First Time…The Boys (7/77) Lust for Life…Iggy Pop (9/7D7) In the Flesh…Blondie (9/77) The Punk…Cherry Vanilla (10/77) Red Hot…Robert Gordon & Link Wray (10/77) 2-4-6-8 Motorway…Tom Robinson (11/77) Rockaway Beach…Ramones (12/77) Statue of Liberty…XTC (1/78) Psycho Killer…Talking Heads (2/78) Fan Mail…Blondie (2/78) This is Pop…XTC (3/78) Who’s Been Sleeping Here…Tuff Darts (4/78) Because the Night…Patty Smith Group (4/78) Ce Plane Pour Moi…Plastic Bertrand (4/78) Do You Wanna Dance?...Ramones (4/78) The Day the World Turned Day-Glo…X-Ray Specs (4/78) The Model…Kraftwerk (5/78) Keep Your Dreams…Suicide (5/78) Miss You…Rolling Stones (5/78) Hot Child in the City…Nick Gilder (6/78) Just What I Needed…The Cars (6/78) Pump It Up…Elvis Costello (6/78) Airport…Motors (7/78) Top of the Pops…The Rezillos (8/78) Another Girl, Another Planet…The Only Ones (8/78) All for the Love of Rock N Roll…Tuff Darts (9/78) Public Image…PIL (10/78) My Best Friend’s Girl…the Cars (10/78) Here Comes the Night…Nick Gilder (11/78) Europe Endless…Kraftwerk (11/78) Slow Motion…Ultravox (12/78) Roxanne…The Police (2/79) Lucky Number (slavic dance version)…Lene Lovich (3/79) Good Times Roll…The Cars (3/79) Dance -

Steve's Karaoke Songbook
Steve's Karaoke Songbook Artist Song Title Artist Song Title +44 WHEN YOUR HEART STOPS INVISIBLE MAN BEATING WAY YOU WANT ME TO, THE 10 YEARS WASTELAND A*TEENS BOUNCING OFF THE CEILING 10,000 MANIACS CANDY EVERYBODY WANTS A1 CAUGHT IN THE MIDDLE MORE THAN THIS AALIYAH ONE I GAVE MY HEART TO, THE THESE ARE THE DAYS TRY AGAIN TROUBLE ME ABBA DANCING QUEEN 10CC THINGS WE DO FOR LOVE, THE FERNANDO 112 PEACHES & CREAM GIMME GIMME GIMME 2 LIVE CREW DO WAH DIDDY DIDDY I DO I DO I DO I DO I DO ME SO HORNY I HAVE A DREAM WE WANT SOME PUSSY KNOWING ME, KNOWING YOU 2 PAC UNTIL THE END OF TIME LAY ALL YOUR LOVE ON ME 2 PAC & EMINEM ONE DAY AT A TIME MAMMA MIA 2 PAC & ERIC WILLIAMS DO FOR LOVE SOS 21 DEMANDS GIVE ME A MINUTE SUPER TROUPER 3 DOORS DOWN BEHIND THOSE EYES TAKE A CHANCE ON ME HERE WITHOUT YOU THANK YOU FOR THE MUSIC KRYPTONITE WATERLOO LIVE FOR TODAY ABBOTT, GREGORY SHAKE YOU DOWN LOSER ABC POISON ARROW ROAD I'M ON, THE ABDUL, PAULA BLOWING KISSES IN THE WIND WHEN I'M GONE COLD HEARTED 311 ALL MIXED UP FOREVER YOUR GIRL DON'T TREAD ON ME KNOCKED OUT DOWN NEXT TO YOU LOVE SONG OPPOSITES ATTRACT 38 SPECIAL CAUGHT UP IN YOU RUSH RUSH HOLD ON LOOSELY STATE OF ATTRACTION ROCKIN' INTO THE NIGHT STRAIGHT UP SECOND CHANCE WAY THAT YOU LOVE ME, THE TEACHER, TEACHER (IT'S JUST) WILD-EYED SOUTHERN BOYS AC/DC BACK IN BLACK 3T TEASE ME BIG BALLS 4 NON BLONDES WHAT'S UP DIRTY DEEDS DONE DIRT CHEAP 50 CENT AMUSEMENT PARK FOR THOSE ABOUT TO ROCK (WE SALUTE YOU) CANDY SHOP GIRLS GOT RHYTHM DISCO INFERNO HAVE A DRINK ON ME I GET MONEY HELLS BELLS IN DA -

Corkscrew Pointe
Corkscrew Pointe Artist Title Disc Number Track # 10,000 Maniacs More Than This 10218 master 2 These Are The Days 10191 Master 1 Trouble Me 10191 Master 2 10Cc I'm Not In Love 10046 master 1 The Things We Do For Love 10227 Master 1 112 Dance With Me (Radio Version) 10120 master 112 12 Gauge Dunkie Butt 10104 master 12 1910 Fruitgum Co. 1, 2, 3 Red Light 10124 Master 1910 2 Live Crew Me So Horny 10020 master 2 We Want Some P###Y 10136 Master 2 2 Pac Changes 10105 master 2 20 Fingers Short #### Man 10120 master 20 3 Doors Down Away From The Sun 10131 master 3 Be Like That (Radio Version) 10210 master 3 Kryptonite May 06 2010 3 Loser 10118 master 3 311 All Mixed Up Mar 23 2010 311 Down 10209 Master 311 Love Song 10232 master 311 38 Special Caught Up In You 10203 38 Rockin' Into The Night 10132 Master 38 Teacher, Teacher 10130 Master 38 Wild-eyed Southern Boys 10140 Master 38 3Lw No More (Baby I'ma Do Right) (Radio 10127 Master 1 Version) 4 Non Blondes What's Up 10217 master 4 42Nd Street (Broadway Version) 42Nd Street 10227 Master 2 1 of 216 Corkscrew Pointe Artist Title Disc Number Track # 42Nd Street (Broadway Version) We're In The Money Mar 24 2010 14 50 Cent If I Can't 10104 master 50 In Da Club 10022 master 50 Just A Lil' Bit 10136 Master 50 P.I.M.P. (Radio Version) 10092 master 50 Wanksta 10239 master 50 50 Cent and Mobb Deep Outta Control (Remix Version) 10195 master 50 50 Cent and Nate Dogg 21 Questions 10105 master 50 50 Cent and The Game How We Do (Radio Version) 10236 master 1 69 Boyz Tootsee Roll 10105 master 69 98° Give Me Just One Night (Una Noche) 10016 master 4 I Do (Cherish You) 10128 Master 1 A Chorus Line What I Did For Love (Movie Version) 10094 master 2 A Flock Of Seagulls I Ran (So Far Away) May 04 2010 1 A Perfect Circle Judith 10209 Master 312 The Hollow 10198 master 1 A Taste Of Honey Boogie Oogie Oogie 10213 master 1 A Taste Of Honey Sukiyaki 10096 master 1 A Teens Bouncing Off The Ceiling (Upside Down) 10016 master 5 A.B. -

DAN KELLY's Ipod 80S PLAYLIST It's the End of The
DAN KELLY’S iPOD 80s PLAYLIST It’s The End of the 70s Cherry Bomb…The Runaways (9/76) Anarchy in the UK…Sex Pistols (12/76) X Offender…Blondie (1/77) See No Evil…Television (2/77) Police & Thieves…The Clash (3/77) Dancing the Night Away…Motors (4/77) Sound and Vision…David Bowie (4/77) Solsbury Hill…Peter Gabriel (4/77) Sheena is a Punk Rocker…Ramones (7/77) First Time…The Boys (7/77) Lust for Life…Iggy Pop (9/7D7) In the Flesh…Blondie (9/77) The Punk…Cherry Vanilla (10/77) Red Hot…Robert Gordon & Link Wray (10/77) 2-4-6-8 Motorway…Tom Robinson (11/77) Rockaway Beach…Ramones (12/77) Statue of Liberty…XTC (1/78) Psycho Killer…Talking Heads (2/78) Fan Mail…Blondie (2/78) Who’s Been Sleeping Here…Tuff Darts (4/78) Because the Night…Patty Smith Group (4/78) Touch and Go…Magazine (4/78) Ce Plane Pour Moi…Plastic Bertrand (4/78) Do You Wanna Dance?...Ramones (4/78) The Day the World Turned Day-Glo…X-Ray Specs (4/78) The Model…Kraftwerk (5/78) Keep Your Dreams…Suicide (5/78) Miss You…Rolling Stones (5/78) Hot Child in the City…Nick Gilder (6/78) Just What I Needed…The Cars (6/78) Pump It Up…Elvis Costello (6/78) Sex Master…Squeeze (7/78) Surrender…Cheap Trick (7/78) Top of the Pops…The Rezillos (8/78) Another Girl, Another Planet…The Only Ones (8/78) All for the Love of Rock N Roll…Tuff Darts (9/78) Public Image…PIL (10/78) I Wanna Be Sedated (megamix)…The Ramones (10/78) My Best Friend’s Girl…the Cars (10/78) Here Comes the Night…Nick Gilder (11/78) Europe Endless…Kraftwerk (11/78) Slow Motion…Ultravox (12/78) I See Red…Split Enz (12/78) Roxanne…The -
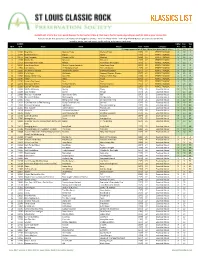
KLASSICS LIST Criteria
KLASSICS LIST criteria: 8 or more points (two per fan list, two for U-Man A-Z list, two to five for Top 95, depending on quartile); 1984 or prior release date Sources: ten fan lists (online and otherwise; see last page for details) + 2011-12 U-Man A-Z list + 2014 Top 95 KSHE Klassics (as voted on by listeners) sorted by points, Fan Lists count, Top 95 ranking, artist name, track name SLCRPS UMan Fan Top ID # ID # Track Artist Album Year Points Category A-Z Lists 95 35 songs appeared on all lists, these have green count info >> X 10 n 1 12404 Blue Mist Mama's Pride Mama's Pride 1975 27 PERFECT KLASSIC X 10 1 2 12299 Dead And Gone Gypsy Gypsy 1970 27 PERFECT KLASSIC X 10 2 3 11672 Two Hangmen Mason Proffit Wanted 1969 27 PERFECT KLASSIC X 10 5 4 11578 Movin' On Missouri Missouri 1977 27 PERFECT KLASSIC X 10 6 5 11717 Remember the Future Nektar Remember the Future 1973 27 PERFECT KLASSIC X 10 7 6 10024 Lake Shore Drive Aliotta Haynes Jeremiah Lake Shore Drive 1971 27 PERFECT KLASSIC X 10 9 7 11654 Last Illusion J.F. Murphy & Salt The Last Illusion 1973 27 PERFECT KLASSIC X 10 12 8 13195 The Martian Boogie Brownsville Station Brownsville Station 1977 27 PERFECT KLASSIC X 10 13 9 13202 Fly At Night Chilliwack Dreams, Dreams, Dreams 1977 27 PERFECT KLASSIC X 10 14 10 11696 Mama Let Him Play Doucette Mama Let Him Play 1978 27 PERFECT KLASSIC X 10 15 11 11547 Tower Angel Angel 1975 27 PERFECT KLASSIC X 10 19 12 11730 From A Dry Camel Dust Dust 1971 27 PERFECT KLASSIC X 10 20 13 12131 Rosewood Bitters Michael Stanley Michael Stanley 1972 27 PERFECT -

Artist Title
O'Shuck Song List Ads Sept 2021 2021/09/20 Artist Title & The Mysterians 96 Tears (Hed) Planet Earth Bartender ´til Tuesday Voices Carry 10 CC I´m Not In Love The Things We Do For Love 10 Years Wasteland 10,000 Maniacs Because The Night More Than This These Are The Days Trouble Me 112 Dance With Me (Radio Version) Peaches And Cream (Radio Version) 12 Gauge Dunkie Butt 12 Stones We Are One 1910 Fruitgum Co. 1, 2, 3 Red Light 2 Live Crew Me So Horny We Want Some PUSSY (EXPLICIT) 2 Pac California Love (Original Version) Changes Dear Mama Until The End Of Time (Radio Version) 20 Fingers Short Dick Man (EXPLICIT) 3 Doors Down Away From The Sun Be Like That (Radio Version) Here Without You It´s Not My Time Kryptonite Landing In London Let Me Go Live For Today Loser The Road I´m On When I´m Gone When You´re Young (Chart Buster) Sorted by Artist Page: 1 O'Shuck Song List Ads Sept 2021 2021/09/20 Artist Title When You´re Young (Pop Hits Monthly) 30 Seconds To Mars The Kill 311 All Mixed Up Amber Down Love Song 38 Special Caught Up In You Hold On Loosely Rockin´ Into The Night Second Chance Teacher, Teacher Wild-eyed Southern Boys 3LW No More (Baby I´ma Do Right) (Radio Version) 3oh!3 Don´t Trust Me 3oh!3 & Kesha My First Kiss 4 Non Blondes What´s Up 42nd Street (Broadway Version) 42Nd Street We´re In The Money 5 Seconds Of Summer Amnesia 50 Cent If I Can´t In Da Club Just A Lil´ Bit P.I.M.P.