Using Natural Language Processing Techniques to Inform Research on Nanotechnology Nastassja A
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Using Nanoinformatics Methods for Automatically Identifying Relevant Nanotoxicology Entities from the Literature
Hindawi Publishing Corporation BioMed Research International Volume 2013, Article ID 410294, 9 pages http://dx.doi.org/10.1155/2013/410294 Research Article Using Nanoinformatics Methods for Automatically Identifying Relevant Nanotoxicology Entities from the Literature Miguel García-Remesal,1, 2 Alejandro García-Ruiz,2 David Pérez-Rey,1, 2 Diana de la Iglesia,2 and Víctor Maojo1, 2 1 �epartamento de Inteli�encia Arti�cial, Facultad de Informática, Universidad Politécnica de Madrid, Boadilla del Monte, 28660 Madrid, Spain 2 Biomedical Informatics Group, Facultad de Informática, Universidad Politécnica de Madrid, Boadilla del Monte, 28660 Madrid, Spain Correspondence should be addressed to Miguel García-Remesal; mgarcia�infomed.dia.�.upm.es Received 8 May 2012; Revised 3 July 2012; Accepted 10 July 2012 Academic Editor: Raffaele Calogero Copyright © 2013 Miguel García-Remesal et al. is is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. Nanoinformatics is an emerging research �eld that uses informatics techni�ues to collect, process, store, and retrieve data, information, and knowledge on nanoparticles, nanomaterials, and nanodevices and their potential applications in health care. In this paper, we have focused on the solutions that nanoinformatics can provide to facilitate nanotoxicology research. For this, we have taken a computational approach to automatically recognize and extract nanotoxicology-related entities from the scienti�c literature. e desired entities belong to four different categories: nanoparticles, routes of exposure, toxic effects, and targets. e entity recognizer was trained using a corpus that we speci�cally created for this purpose and was validated by two nanomedicine/nanotoxicology experts. -
Nanoinformatics 2015.Pptx
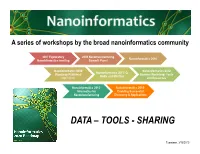
A series of workshops by the broad nanoinformatics community 2007 Exploratory 2009 Nanomanufacturing Nanoinformatics 2010 Nanoinformatics meeting Summit Panel Nanoinformatics 2020 Nanoinformatics 2012 Nanoinformatics 2011: Q- Roadmap Published Summer Workshop: Tools SARs and MinChar (April 2011) and Resources Nanoinformatics 2013: Nanoinformatics 2015: Informatics for Enabling Successful Nanomanufacturing Discovery & Applications DATA – TOOLS - SHARING Tuominen, 3/19/2015 2015 “Enabling Successful Discovery and Applications” NNN Workshop: January 26-28, 2015; Arlington VA o Nanoinformatics Tutorial o Session 1: Purpose-driven Nanoinformatics o Session 2: Inventory of Nanoinformatics Data and Tools o Session 3: Nanoinformatics for Design of Materials, Manufacturing, and Products o Session 4: Nanoinformatics for Risk o Poster Presentations and Discussion o Session 5: Uncertainty Quantification and Informatics Robustness o Session 6: Sharing and Conceptual Integration of Data Elements Across Resources o Nanoinformatics Charette http://nanoinformatics.org/2015/agenda Tuominen, 3/19/2015 2015 “Enabling Successful Discovery and Applications” Nanoinformatics Tutorial o Mark Tuominen – “Broad introduction to science informatics and lab automation strategies” o Yoram Cohen – “Assessing Environmental Impact Analysis” o Mark Hoover – “ONAMI, NIL, Good Nano Guide, Nanomaterials Registry” o Gerhard Klimeck – “nanoHub” • Covered some fundamentals and current status • Generated discussions on overarching purpose and strategy Tuominen, 3/19/2015 Science Informatics Information Automatic In the broadest sense, we try to—as much as currently possible —automate working with the information associated with science. • To more broadly leverage the information already gathered. • To reduce uncertainty and assist in decision-making • To better automate processes that build science. • To save time and money. • To help assure safety for people and the environment. -

Data Shepherding in Nanotechnology. the Exposure Field Campaign Template
nanomaterials Article Data Shepherding in Nanotechnology. The Exposure Field Campaign Template Irini Furxhi 1,2,* , Antti Joonas Koivisto 3,4,5 , Finbarr Murphy 1,2 , Sara Trabucco 6, Benedetta Del Secco 6 and Athanasios Arvanitis 7 1 Transgero Limited, Cullinagh, Newcastle West, V42V384 Limerick, Ireland; [email protected] 2 Department of Accounting and Finance, Kemmy Business School, University of Limerick, V94T9PX Limerick, Ireland 3 Air Pollution Management, Willemoesgade 16, st tv, DK-2100 Copenhagen, Denmark; [email protected] 4 ARCHE Consulting, Liefkensstraat 35D, B-9032 Wondelgem, Belgium 5 Institute for Atmospheric and Earth System Research (INAR), University of Helsinki, PL 64, FI-00014 Helsinki, Finland 6 Institute of Atmospheric Sciences and Climate (CNR-ISAC) Via Gobetti 101, 40129 Bologna, Italy; [email protected] (S.T.); [email protected] (B.D.S.) 7 Environmental Informatics Research Group, Department of Mechanical Engineering, Aristotle University of Thessaloniki, 54124 Thessaloniki, Greece; [email protected] * Correspondence: [email protected] Abstract: In this paper, we demonstrate the realization process of a pragmatic approach on develop- ing a template for capturing field monitoring data in nanomanufacturing processes. The template serves the fundamental principles which make data scientifically Findable, Accessible, Interoperable and Reusable (FAIR principles), as well as encouraging individuals to reuse it. In our case, the data shepherds’ (the guider of data) template creation workflow consists of the following steps: (1) Identify relevant stakeholders, (2) Distribute questionnaires to capture a general description of the Citation: Furxhi, I.; Koivisto, A.J.; data to be generated, (3) Understand the needs and requirements of each stakeholder, (4) Interactive Murphy, F.; Trabucco, S.; Del Secco, B.; Arvanitis, A. -

Nanoinformatics: Developing New Computing Applications for Nanomedicine
Computing (2012) 94:521–539 DOI 10.1007/s00607-012-0191-2 Nanoinformatics: developing new computing applications for nanomedicine Victor Maojo · Martin Fritts · Fernando Martin-Sanchez · Diana De la Iglesia · Raul E. Cachau · Miguel Garcia-Remesal · Jose Crespo · Joyce A. Mitchell · Alberto Anguita · Nathan Baker · Jose Maria Barreiro · Sonia E. Benitez · Guillermo De la Calle · Julio C. Facelli · Peter Ghazal · Antoine Geissbuhler · Fernando Gonzalez-Nilo · Norbert Graf · Pierre Grangeat · Isabel Hermosilla · Rada Hussein · Josipa Kern · Sabine Koch · Yannick Legre · Victoria Lopez-Alonso · Guillermo Lopez-Campos · Luciano Milanesi · Vassilis Moustakis · Cristian Munteanu · Paula Otero · Alejandro Pazos · David Perez-Rey · George Potamias · Ferran Sanz · Casimir Kulikowski Received: 16 November 2011 / Accepted: 30 January 2012 / Published online: 7 March 2012 © The Author(s) 2012. This article is published with open access at Springerlink.com Abstract Nanoinformatics has recently emerged to address the need of computing applications at the nano level. In this regard, the authors have participated in various initiatives to identify its concepts, foundations and challenges. While nanomaterials V. Maojo (B) · D. De la Iglesia · M. Garcia-Remesal · J. Crespo · A. Anguita · J. M. Barreiro · G. De la Calle · D. Perez-Rey Biomedical Informatics Group, Departamento de Inteligencia Artificial, Faculdad de Informática, Universidad Politécnica de Madrid, Boadilla del Monte, 28660 Madrid, Spain e-mail: vmaojo@fi.upm.es M. Fritts SAIC-Frederick Inc., National Cancer Institute at Frederick, Frederick, MD, USA F. Martin-Sanchez Health and Biomedical Informatics Research Laboratory Medical School-IBES, The University of Melbourne, Parkville, VIC, Australia R. E. Cachau Advanced Biomedical Computing Center, National Cancer Institute, SAIC-Frederick Inc., Frederick, MD, USA J. -

Community-Driven Organisation of Metadata Schemas to Support FAIR Nanoscience Data
nanomaterials Article Metadata Stewardship in Nanosafety Research: Community-Driven Organisation of Metadata Schemas to Support FAIR Nanoscience Data Anastasios G. Papadiamantis 1,2,* , Frederick C. Klaessig 3 , Thomas E. Exner 4 , Sabine Hofer 5 , Norbert Hofstaetter 5 , Martin Himly 5 , Marc A. Williams 6, Philip Doganis 7 , Mark D. Hoover 8 , Antreas Afantitis 2 , Georgia Melagraki 2 , Tracy S. Nolan 9 , John Rumble 10,11 , Dieter Maier 12 and Iseult Lynch 1,* 1 School of Geography, Earth and Environmental Sciences, University of Birmingham, Birmingham B15 2TT, UK 2 Novamechanics Ltd., 1065 Nicosia, Cyprus; [email protected] (A.A.); [email protected] (G.M.) 3 Pennsylvania Bio Nano Systems, Doylestown, PA 18901, USA; [email protected] 4 Edelweiss Connect, CH-4057 Basel, Switzerland; [email protected] 5 Department of Biosciences, Paris Lodron University of Salzburg, 5020 Salzburg, Austria; [email protected] (S.H.); [email protected] (N.H.); [email protected] (M.H.) 6 U.S. Army Public Health Center (APHC), Aberdeen Proving Ground—South, Aberdeen, MD 21010, USA; [email protected] 7 School of Chemical Engineering, National Technical University of Athens, 157 80 Athens, Greece; [email protected] 8 Mark D Hoover LLC, Morgantown, WV 26505, USA; [email protected] 9 Department of Biomedical Informatics, University of Arkansas for Medical Sciences, Little Rock, AR 72205, USA; [email protected] 10 R&R Data Services, Gaithersburg, MD -

Nanoinformatics: a New Area of Research in Nanomedicine
International Journal of Nanomedicine Dovepress open access to scientific and medical research Open Access Full Text Article REVIEW Nanoinformatics: a new area of research in nanomedicine Victor Maojo1 Abstract: Over a decade ago, nanotechnologists began research on applications of nanomaterials Martin Fritts2,3 for medicine. This research has revealed a wide range of different challenges, as well as many Diana de la Iglesia1 opportunities. Some of these challenges are strongly related to informatics issues, dealing, Raul E Cachau4 for instance, with the management and integration of heterogeneous information, defining Miguel Garcia-Remesal1 nomenclatures, taxonomies and classifications for various types of nanomaterials, and research Joyce A Mitchell5 on new modeling and simulation techniques for nanoparticles. Nanoinformatics has recently emerged in the USA and Europe to address these issues. In this paper, we present a review of Casimir Kulikowski6 nanoinformatics, describing its origins, the problems it addresses, areas of interest, and examples 1 Biomedical Informatics Group, of current research initiatives and informatics resources. We suggest that nanoinformatics could Departamento de Inteligencia Artificial, Facultad de Informática, accelerate research and development in nanomedicine, as has occurred in the past in other fields. Universidad Politécnica de For instance, biomedical informatics served as a fundamental catalyst for the Human Genome 2 Madrid, Spain; SAIC-Frederick Project, and other genomic and –omics projects, as well -

Nanoinformatics: Emerging Databases and Available Tools
Int. J. Mol. Sci. 2014, 15, 7158-7182; doi:10.3390/ijms15057158 OPEN ACCESS International Journal of Molecular Sciences ISSN 1422-0067 www.mdpi.com/journal/ijms Review Nanoinformatics: Emerging Databases and Available Tools Suresh Panneerselvam and Sangdun Choi * Department of Molecular Science and Technology, Ajou University, Suwon 443-749, Korea; E-Mail: [email protected] * Author to whom correspondence should be addressed; E-Mail: [email protected]; Tel.: +82-31-219-2600; Fax: +82-31-219-1615. Received: 17 February 2014; in revised form: 28 March 2014 / Accepted: 9 April 2014 / Published: 25 April 2014 Abstract: Nanotechnology has arisen as a key player in the field of nanomedicine. Although the use of engineered nanoparticles is rapidly increasing, safety assessment is also important for the beneficial use of new nanomaterials. Considering that the experimental assessment of new nanomaterials is costly and laborious, in silico approaches hold promise. Several major challenges in nanotechnology indicate a need for nanoinformatics. New database initiatives such as ISA-TAB-Nano, caNanoLab, and Nanomaterial Registry will help in data sharing and developing data standards, and, as the amount of nanomaterials data grows, will provide a way to develop methods and tools specific to the nanolevel. In this review, we describe emerging databases and tools that should aid in the progress of nanotechnology research. Keywords: biomedical informatics; databases; molecular simulations; nanoinformatics; nanomedicine; nanotechnology; QSAR; text mining 1. Introduction Nanotechnology enables the design and assembly of components with dimensions ranging from 1 to 100 nanometers (nm) [1]. The word nano, which is derived from the Greek word for dwarf, has been part of the scientific nomenclature since 1960 [2]. -

Good Afternoon. Welcome to Today's Webinar. I'm Stacy Standridge, Deputy Director of the National Nanotechnology Coordination Office (NNCO)
NNCO 2019 NanoEHS Webinar Series November 12, 2019 Global Harmonization of Nanoinformatics: A Case Study in Convergence and Team Science Dr. Christine Ogilvie Hendren Dr. Fred Klaessig Executive Director, Center for the Manager, Pennsylvania Environmental Implications of Bio Nano Systems NanoTechnology (CEINT), Duke University Welcome by Dr. Stacey Standridge Deputy Director, National Nanotechnology Coordination Office >> Stacey Standridge: Good afternoon. Welcome to today's webinar. I'm Stacy Standridge, Deputy Director of the National Nanotechnology Coordination Office (NNCO). Thank you for joining us for this final webinar in the 2019 NanoEHS Webinar series. The series examined areas of significant progress in nanoEHS research and was among the activities marking the 15th anniversary of the authorization of the NNI. For another perspective on nanoEHS scientific advances in the last 15 years, you may also be interested in a Nature Nanotechnology Commentary published last week, authored in part by Lisa Friedersdorf and Rhema Bjorkland from our office. I actually have to step off about halfway through the webinar today, so Rhema is also going to skillfully handle the Q&A portion of the webinar at the end of this discussion. Today's presentation will offer insights into how teams of informaticists, EHS scientists, and computational experts have advanced the potential for informatics to support EHS assessments and safer-by-design capabilities. I am sincerely pleased today to introduce our speakers, Dr. Christine Ogilvie Hendren of Duke University and Dr. Fred Klaessig of Pennsylvania Bio Nano Systems. Fred and Christine have been among the leaders in these collaborative efforts. Before I turn it over to them, please remember to visit nano.gov for more information on upcoming webinars. -

Nanotechnology Knowledge Infrastructure: Enabling National Leadership in Sustainable Design
NNI Signature Initiative: Nanotechnology Knowledge Infrastructure May 14, 2012 NSTC COMMITTEE ON TECHNOLOGY SUBCOMMITTEE ON NANOSCALE SCIENCE, ENGINEERING, AND TECHNOLOGY Nanotechnology Signature Initiative Nanotechnology Knowledge Infrastructure: Enabling National Leadership in Sustainable Design Collaborating Agencies:i CPSC, DOD, EPA, FDA, NASA, NIH, NIOSH, NIST, NSF, OSHA National Need Addressed Nanotechnology solves global challenges by generating and applying new multidisciplinary knowledge of nanoscale phenomena and engineered nanoscale materials, structures, and products. The data underlying this new knowledge are vast, disconnected, and challenging to integrate into the broad scientific body of knowledge. The Federal agencies participating in the National Nanotecnology Initiative (NNI)—in conjunction with the broader nanoscale science, engineering, and technology communities—have identified the building of a formal knowledge infrastructure as critical to sustainable progress in nanotechnology [1-4]. This reflects a desire to coordinate existing NNI member agency programmatic efforts that accelerate the vetting of new knowledge and that enable effective data utilization. Nanoinformatics is the science and practice of developing and implementing effective mechanisms for the nanotechnology community to collect, validate, store, share, mine, analyze, model, and apply nanotechnology information. Nanoinformatics is integrated throughout the entire nanotechnology landscape, impacting all aspects of research, development, and application. -

The 22Nd NSC Newsletter Contents
DOI: www.nanosafetycluster.eu Issue 22: March 2021 Welcome to the 22nd NSC Newsletter Contents Once again, your continued and much appreciated WELCOME 1 contributions have enabled the production of another NSC NEWS 2 rich NSC Community newsletter and detailed snapshots News from the NSC Coordination Team 2 of recent and forthcoming NSC and related activities. NSC Education and Training Days videos 3 NSC NEW PROJECTS 6 In this issue, our Coordination Team update highlights, The flight of the Phoenix 6 among other activities, the NanoHarmony webinar being Bringing you SUNSHINE 7 held on 17th March, and the recent innovative A HARMLESS Kick-off 8 developments of the Safe-By-Design initiatives. Ready for Take-off: DIAGONAL 8 Meanwhile, for those who would like to follow up on the NSC PROJECT NEWS 9 NSC Education and Training days at nanoSAFE, the ASINA Monitoring Campaign 9 NanoHarmony webinar 17th March 11 videos are now available on our Youtube Channel (p3) as PATROLS: International Women in Science Day 12 a playlist. PATROLS holds stakeholder workshop 13 The New Projects section introduces four new initiatives NanoCommons nanosafety e-infrastructure 15 that are working from the Safe & Sustainable by Design NanoSolveIT highlights 17 and Safety Innovation Approach perspectives. Following SABYDOMA’s 1st Legal Workshop on Safe-by-Design 19 this, Project News brings you the latest updates from a SabyNA DSS Survey 21 SbD4Nano Project Updates 22 number of current initiatives (see contents). From p.26, CHARISMA Highlights 23 you can discover more about five micro-/nano-plastics DaNa Showcases New Website with Spotlight Research 24 projects that kick off next month with the aim of finding BIORIMA Holds a Demonstration 25 out more about the health impacts of mnps on the IN OTHER NEWS 26 human body. -

Framework for Automatic Information Extraction from Research Papers on Nanocrystal Devices
Framework for automatic information extraction from research papers on nanocrystal devices Thaer M. Dieb*1, Masaharu Yoshioka1, Shinjiro Hara2 and Marcus C. Newton3 Full Research Paper Open Access Address: Beilstein J. Nanotechnol. 2015, 6, 1872–1882. 1Graduate School of Information Science and Technology, Hokkaido doi:10.3762/bjnano.6.190 University, Kita 14, Nishi 9, Kita-ku, Sapporo, Hokkaido, 060-0814, Japan, 2Research Center for Integrated Quantum Electronics, Received: 31 March 2015 Hokkaido University, Kita 13, Nishi 8, Sapporo 060-8628, Japan and Accepted: 20 August 2015 3Physics & Astronomy, University of Southampton, Southampton, Published: 07 September 2015 SO17 1BJ, UK This article is part of the Thematic Series "Nanoinformatics for Email: environmental health and biomedicine". Thaer M. Dieb* - [email protected] Guest Editor: R. Liu * Corresponding author © 2015 Dieb et al; licensee Beilstein-Institut. Keywords: License and terms: see end of document. annotated corpus; automatic information extraction; nanocrystal device development; nanoinformatics; text mining Abstract To support nanocrystal device development, we have been working on a computational framework to utilize information in research papers on nanocrystal devices. We developed an annotated corpus called “ NaDev” (Nanocrystal Device Development) for this purpose. We also proposed an automatic information extraction system called “NaDevEx” (Nanocrystal Device Automatic Informa- tion Extraction Framework). NaDevEx aims at extracting information from research -

Nanoinformatics: New Challenges for Biomedical Informatics at the Nano Level
Medical Informatics in a United and Healthy Europe 987 K.-P. Adlassnig et al. (Eds.) IOS Press, 2009 © 2009 European Federation for Medical Informatics. All rights reserved. doi:10.3233/978-1-60750-044-5-987 Nanoinformatics: New Challenges for Biomedical Informatics at the Nano Level Diana DE LA IGLESIA a,1 , Stefano CHIESA a, Josipa KERN b, Victor MAOJO a, Fernando MARTIN-SANCHEZ c, George POTAMIAS d, Vassilis MOUSTAKIS d, Joyce A. MITCHELL e a Biomedical Informatics Group, Departamento de Inteligencia Artificial, Facultad de Informatica, Universidad Politecnica de Madrid, Spain b Department of Medical Statistics, Epidemiology and Medical Informatics, Andrija Stampar School of Public Health, Zagreb University Medical School, Croatia c Department of Medical Bioinformatics, Institute of Health Carlos III, Madrid, Spain d Institute of Computer Science, FORTH, Heraklion, Crete, Greece e Biomedical Informatics Department, University of Utah, USA Abstract. Over the last decades Nanotechnology has promised to advance science and technology in many areas. Within medicine, Nanomedicine promises to deliver new methods for diagnosis, prognosis and therapy. As the amount of available information is rapidly growing, new Biomedical Informatics approaches have to be developed to satisfy the increasing demand on data and knowledge management. In 2007, a new sub-discipline, already named “Nanoinformatics”, was created with support from the US National Science Foundation. In Europe, a project named ACTION-Grid was launched in 2008 with support from the European Commission to analyze the challenges and agenda for developing Nanoinformatics as a discipline related to Nanotechnology, Biomedicine and Informatics. For MIE 2009, members of this consortium proposed a workshop to discuss the scientific and strategic issues associated with this topic.