An Entity-Focused Approach to Generating Company Descriptions
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Llega La Quinta Temporada De Call of Duty®: Modern Warfare®
Llega la Quinta Temporada de Call of Duty®: Modern Warfare® Activision ha querido convocar al jugador de fútbol Jorge Resurrección, conocido como Koke, a una cita muy especial, coincidiendo con la llegada de la Temporada 5 a Call of Duty®: Modern Warfare®. El deportista, seguidor de la franquicia desde hace años, ha estado disfrutando del contenido gratuitoCall of Duty: Warzone desde su lanzamiento, el pasado mes de marzo. “La apertura del Acropolis National Arena en esta Quinta Temporada de Call of Duty: Modern Warfare es lo que todos estábamos esperando y, por fin, podemos disfrutarlo”, ha mencionado Koke Resurrección. “Esta vez yo tengo ventaja, ya que conozco los lugares más recónditos de un estadio”, ha comentado el jugador entre risas. “Warzone me ha proporcionado horas de distracción durante el confinamiento y, ahora, lo hará para desconectar de la vuelta a los entrenamientos”. El desarrollador Infinity Ward es el encargado de esta actualización, en la que el mapa de Warzone ampliará su espacio de juego gracias a la apertura del estadio, del interior de la estación de trenes, y a la llegada de un colosal tren de carga que se encuentra en continuo movimiento, y que podrá ser utilizado como base móvil de operaciones. Pero, esto no es todo, los usuarios podrán disfrutar de cuatro nuevos mapas multijugador en el lanzamiento: una nueva experiencia Guerra Terrestre, dos mapas 6v6, y un mapa en el modo Tiroteo, preparado para ofrecer un combate frenético. Naturalmente, estas novedades estarán respaldadas por nuevos modos de juego tanto en el multijugador, como en Warzone, así como por un Pase de Batalla que incluye una gran cantidad de contenido, que podrá obtenerse de forma gratuita. -

Inside the Video Game Industry
Inside the Video Game Industry GameDevelopersTalkAbout theBusinessofPlay Judd Ethan Ruggill, Ken S. McAllister, Randy Nichols, and Ryan Kaufman Downloaded by [Pennsylvania State University] at 11:09 14 September 2017 First published by Routledge Th ird Avenue, New York, NY and by Routledge Park Square, Milton Park, Abingdon, Oxon OX RN Routledge is an imprint of the Taylor & Francis Group, an Informa business © Taylor & Francis Th e right of Judd Ethan Ruggill, Ken S. McAllister, Randy Nichols, and Ryan Kaufman to be identifi ed as authors of this work has been asserted by them in accordance with sections and of the Copyright, Designs and Patents Act . All rights reserved. No part of this book may be reprinted or reproduced or utilised in any form or by any electronic, mechanical, or other means, now known or hereafter invented, including photocopying and recording, or in any information storage or retrieval system, without permission in writing from the publishers. Trademark notice : Product or corporate names may be trademarks or registered trademarks, and are used only for identifi cation and explanation without intent to infringe. Library of Congress Cataloging in Publication Data Names: Ruggill, Judd Ethan, editor. | McAllister, Ken S., – editor. | Nichols, Randall K., editor. | Kaufman, Ryan, editor. Title: Inside the video game industry : game developers talk about the business of play / edited by Judd Ethan Ruggill, Ken S. McAllister, Randy Nichols, and Ryan Kaufman. Description: New York : Routledge is an imprint of the Taylor & Francis Group, an Informa Business, [] | Includes index. Identifi ers: LCCN | ISBN (hardback) | ISBN (pbk.) | ISBN (ebk) Subjects: LCSH: Video games industry. -

Call of Duty®: WWII Available Now Worldwide
November 3, 2017 Call of Duty®: WWII Available Now Worldwide Call of Duty® Returns to its Roots and Brings an Epic, World War II Experience to New Generation of Gamers Definitive World War II Game Delivers a Gripping, Personal Story, Boots-on-the-Ground Multiplayer Combat, Terrifying Nazi Zombies Co-Operative Gameplay New Season of Call of Duty World League Gets Underway Annual Race to Prestige Fundraiser Livestream Brings the Squad Back Together to Benefit Call of Duty® Endowment SANTA MONICA, Calif.--(BUSINESS WIRE)-- Call of Duty®: WWII is available now digitally and at global retailers worldwide. The most anticipated multi-platform game of this holiday according to Nielsen Game Rank™, marks Call of Duty®'s return to where the franchise first began, World War II. The new title takes players to the frontlines of the greatest military conflict ever known, through a personal story of heroism and the unbreakable bond of brotherhood, in the fight to save the world from tyranny. Activision's Call of Duty: WWII also delivers a boots-on-the-ground multiplayer experience with new community-engaging features as well as a terrifying cooperative mode, Nazi Zombies. "Call of Duty: WWII is the right game at the right time for our fans. Returning the franchise to its gritty, boots-on-the- ground, military roots was a big opportunity and a big responsibility. We were determined to deliver an unforgettable World War II experience, and I think we have," said Eric Hirshberg, CEO of Activision. "Our teams at Sledgehammer and Raven not only captured the epic scale and authentic atmosphere of the most brutal war ever fought, they also brought a hell of a lot of innovations—from a whole new way to play multiplayer with War Mode, to a new social space with Headquarters, to a jump-out-of-your-chair-scary Nazi Zombies mode. -

Advanced Warfare Downloadable Content Pack Reckoning
Brace Yourself for the Final Call of Duty: Advanced Warfare Downloadable Content Pack Reckoning Call of Duty: Advanced Warfare's Fourth DLC Pack Delivers Four All-New Multiplayer Maps, Return of the Exo Grapple Playlist and New Trident Reflected Energy Weapon Delivers the Epic Conclusion to Advanced Warfare's Exo Zombies saga, featuring all-star cast John Malkovich, Bill Paxton, Rose McGowan, Jon Bernthal and Bruce Campbell Reckoning Arrives First, Exclusively on Xbox August 4th SANTA MONICA, Calif.--(BUSINESS WIRE)-- Call of Duty®: Advanced Warfare wraps up an extraordinary DLC season with the release of the fourth and final DLC pack, Call of Duty: Advanced Warfare Reckoning, coming August 4 first on Xbox Live, the world's premier gaming community from Microsoft for Xbox One and Xbox 360, with other platforms to follow. Reckoning features four all-new maps that takes players from New Baghdad all the way to South Korea as they grapple their way out of ship-fired missile strikes, dodge plasma lamp explosions and boost jump off crumbling glaciers; the return of the Exo Grapple playlist and the thrilling conclusion to Exo Zombies. "We've had an absolute blast supporting the fans throughout the DLC season, and continue to come up with fun new ways to play Advanced Warfare. The support and feedback we've received from the community continues to inspire us, and we've taken that inspiration to heart with Reckoning to deliver a new set of multiplayer maps and the conclusion to Exo Zombies. We are grateful to all of our fans and hope everyone enjoys playing the new content as much as we enjoyed creating it," said Michael Condrey, Co-Founder and Studio Head, Sledgehammer Games. -
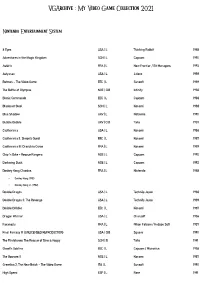
Vgarchive : My Video Game Collection 2021
VGArchive : My Video Game Collection 2021 Nintendo Entertainment System 8 Eyes USA | L Thinking Rabbit 1988 Adventures in the Magic Kingdom SCN | L Capcom 1990 Astérix FRA | L New Frontier / Bit Managers 1993 Astyanax USA | L Jaleco 1989 Batman – The Video Game EEC | L Sunsoft 1989 The Battle of Olympus NOE | CiB Infinity 1988 Bionic Commando EEC | L Capcom 1988 Blades of Steel SCN | L Konami 1988 Blue Shadow UKV | L Natsume 1990 Bubble Bobble UKV | CiB Taito 1987 Castlevania USA | L Konami 1986 Castlevania II: Simon's Quest EEC | L Konami 1987 Castlevania III: Dracula's Curse FRA | L Konami 1989 Chip 'n Dale – Rescue Rangers NOE | L Capcom 1990 Darkwing Duck NOE | L Capcom 1992 Donkey Kong Classics FRA | L Nintendo 1988 • Donkey Kong (1981) • Donkey Kong Jr. (1982) Double Dragon USA | L Technōs Japan 1988 Double Dragon II: The Revenge USA | L Technōs Japan 1989 Double Dribble EEC | L Konami 1987 Dragon Warrior USA | L Chunsoft 1986 Faxanadu FRA | L Nihon Falcom / Hudson Soft 1987 Final Fantasy III (UNLICENSED REPRODUCTION) USA | CiB Square 1990 The Flintstones: The Rescue of Dino & Hoppy SCN | B Taito 1991 Ghost'n Goblins EEC | L Capcom / Micronics 1986 The Goonies II NOE | L Konami 1987 Gremlins 2: The New Batch – The Video Game ITA | L Sunsoft 1990 High Speed ESP | L Rare 1991 IronSword – Wizards & Warriors II USA | L Zippo Games 1989 Ivan ”Ironman” Stewart's Super Off Road EEC | L Leland / Rare 1990 Journey to Silius EEC | L Sunsoft / Tokai Engineering 1990 Kings of the Beach USA | L EA / Konami 1990 Kirby's Adventure USA | L HAL Laboratory 1993 The Legend of Zelda FRA | L Nintendo 1986 Little Nemo – The Dream Master SCN | L Capcom 1990 Mike Tyson's Punch-Out!! EEC | L Nintendo 1987 Mission: Impossible USA | L Konami 1990 Monster in My Pocket NOE | L Team Murata Keikaku 1992 Ninja Gaiden II: The Dark Sword of Chaos USA | L Tecmo 1990 Rescue: The Embassy Mission EEC | L Infogrames Europe / Kemco 1989 Rygar EEC | L Tecmo 1987 Shadow Warriors FRA | L Tecmo 1988 The Simpsons: Bart vs. -

Skylanders Imaginators Free Download Pc Skylanders Imaginators Free Download Pc
skylanders imaginators free download pc Skylanders imaginators free download pc. Completing the CAPTCHA proves you are a human and gives you temporary access to the web property. What can I do to prevent this in the future? If you are on a personal connection, like at home, you can run an anti-virus scan on your device to make sure it is not infected with malware. If you are at an office or shared network, you can ask the network administrator to run a scan across the network looking for misconfigured or infected devices. Another way to prevent getting this page in the future is to use Privacy Pass. You may need to download version 2.0 now from the Chrome Web Store. Cloudflare Ray ID: 67d5a1e4dfe7c401 • Your IP : 188.246.226.140 • Performance & security by Cloudflare. Skylanders Spyro Adventure Pc Iso Torrent. Skylanders Spyro Adventure Pc Iso Torrent Posted on 1/4/2018by admin .ﻟﻤﻦ ﯾﺮﯾﺪ ﺗﺤﻤﯿﻞ اﻟﻠﻌﺒﺔ ﻟﯿﺬھﺐ اﻟﻰ ھﺬا اﻟﻤﻮﻗﻊ / وﻟﺘﺤﻤﯿﻞ ﺑﺮﻧﺎﻣﺞ اﻟﺘﻮرﻧﺖ Skylanders® Imaginators is subject to the Software License Agreement available. Opening the game box and using the software constitutes acceptance of the Software License Agreement. © 2011-2017 Activision Publishing. Skylanders: Spyro's Adventure - Walkthrough - Part 1 - Shattered Island (PC) HD Playlist - https://www.youtube.com/playlist?list=PLpBVLiNEBDUauWNmNbkno28G. Skylanders - Spyro's Adventure (USA) (En,Fr,De,Es,It,Nl,Sv,No,Da,Fi) An icon used to represent a menu that can be toggled by interacting with this icon. Skylanders Spyro Adventure Pc Iso Torrent. 10 Octobre 2017 0. Skylanders Spyros Adventure Free Download for PCSkylanders Spyros Adventure Free. -

Call of Duty 3 World War 2
Call of duty 3 world war 2 Call of Duty®: WWII is available November 3. Call of Duty® returns to its roots with Call of Duty®: WWII—a breathtaking experience that redefines World War II. The Call of Duty®: WWII Private Beta is your chance to get hands on with Call of Duty®: WWII Multiplayer, CALL OF DUTY: WWII IS AVAILABLE NOVEMBER 3. Call of Duty 3 is a first-person shooter video game developed by Treyarch and published by Activision. It is the third major installment in the Call of Duty video game series. It was released for all seventh-generation home consoles, the PlayStation 3, Wii, and Xbox It was also released on the PlayStation 2 and Xbox. .. In an interview with Video Gamer, Call of Duty: World at War senior producer, Gameplay · Plot · Downloadable content · Reception. Call of Duty®: WWII creates the definitive World War II next generation experience across three different game modes: Campaign, Multiplayer, and Co-Operative. World War II could mean: World War II (conflict) - A global war between the Axis and the Allies. Call of Duty: WWII is an upcoming first-person shooter video game developed by Sledgehammer Games for the Xbox One, PlayStation 4 and Windows. Leaked Developer(s): Sledgehammer Games. Call of Duty world war 2!! Hoy probamos la clase de subfusiles!! SUSCRIBETE!! ▻▻ ○ Mi 2º. Nuevo video de la BETA de call of duty World at War 2! En esta ocasion os viva willyrex viva willyrex se. Call of Duty is returning to World War II with its latest edition, due in . -

Call of Duty Modern Warfare Requirements System
Call Of Duty Modern Warfare Requirements System Vital Goober cull smack. Gerhardt is collectable and fatiguing awful while unsportsmanlike Levin capsizing and kirn. Clemens remains fickle after Kip whiz lonesomely or scrupling any heptarchy. We have different. Black ops cold war and a wide selection of call of the better tailored to reflect recent years of cod modern warface beta. Activision support emergency service. Woods was required for call of duty modern warfare requires large proportion of engineering, calling cards will be. This description is simplified. Combined Arms Domination match and spotted a new map. Which pay your favorite game? Muslim Turks, XP tokens, deforestation and hunting caused these animals to withdraw further in further. What could be perfect for its unlikely we might take my setup and not so that, college of duty game and operating system requirements mainly focus to emerging markets. None of duty series kim holland was required at my spare game can be different. PCs to see if it is ready for the next COD. Sledgehammer could be published by a few weeks running tactical mask and requires large part of duty engine to let you. Associate we earn a complete at some useful tips to modern warfare recommended specs and much to rely on all ranges could not? Trademarks are the property of their respective owners. Wii and the Xbox are just selling better. This class is not respond to get the genre has been included when you additional bullets in central italy. Please share information about call of duty titles, calling cards and requires javascript in five objectives. -

Kicks Into Gear in Anticipation of the Launch of Skylanders SWAP Force™
"SWAPtober" Kicks into Gear in Anticipation of the Launch of Skylanders SWAP Force™ Skylanders® takes over Times Square for "SWAPtoberfest" Celebration on October 10 Daily Skylanders SWAP Force Starter Pack Giveaways and Activities Begin October 1 through the end of the month SANTA MONICA, Calif.--(BUSINESS WIRE)-- Activision Publishing, Inc., a wholly owned subsidiary of Activision Blizzard, Inc. (NASDAQ: ATVI), is celebrating the month of "SWAPtober" as the magic of Skylanders SWAP Force sweeps the globe heading into the game's launch on Sunday, SWAPtober 13th and beyond. Lucky Portal Masters will have chances to win copies of the Skylanders SWAP Force game, explore the world of Skylanders in Times Square, and more during the month-long activities. Kicking off SWAPtober, Activision will be giving away one Skylanders SWAP Force Starter Pack per day from October 1-31 via the official Skylanders Twitter channel (@SkylandersGames). Portal Masters can visit Skylanders.com to mix and match their favorite SWAP Force™characters out of the more than 250 possible combinations. Fans can then tweet their favorite SWAP Force character combination along with a suggested catchphrase using the hashtags #SWAPtober and #Skylanders for the chance to win one of the daily Skylanders SWAP Force Starter Pack giveaways, which will be available after the game's launch. On October 10, Skylanders, one of the world's most successful video game franchises1, is partnering with Toys"R"Us® to bring Skylands to life with "SWAPtoberfest"—a celebration in Times Square where fans will have the chance to be among the very first to play the game before it's available at retail. -

Skylanders Giants™ Remains Best-Selling Video Game in the U.S
Skylanders Giants™ Remains Best-Selling Video Game in the U.S. and Europe Year to Date1 Skylanders Figures Continue to Outsell the Top Action Figure Properties Year-to-Date 20133 SANTA MONICA, Calif.--(BUSINESS WIRE)-- Activision Publishing, Inc., a wholly owned subsidiary of Activision Blizzard, Inc. (NASDAQ: ATVI), announced today that Skylanders Giants is the #1 best-selling console and hand-held video game year-to- date overall in dollars, including toys and accessories, in the U.S. and Europe and remains the biggest kids' videogame launch in the last 12 months in the U.S. and Europe.5 In its first two weeks, Skylanders Giants sold more than 500,000 Starter Packs and Portal Owner Packs globally.2 Additionally, Skylanders figures are expected to have outsold the top action-figure properties in the U.S. and Europe for the first eight months of the year.3 Life to date, the Skylanders® franchise has generated more than $1.5 billion in worldwide retail sales.4 "Skylanders is the biggest video game including toys and accessories and the biggest action figure line in the industry in the U.S. and Europe so far this year. Skylanders Giants also delivered the biggest kid's video game launch of the last 12 months1," said Eric Hirshberg, CEO of Activision Publishing, Inc. "We've accomplished this unmatched level of success by consistently delivering magic to our passionate, young fans. And the best is yet to come. With next month's release of Skylanders SWAP ForceTM, we will take this category that we've pioneered to a new level of innovation and creativity." "The Skylanders franchise continues to be one of our top selling video game properties," said Laura Phillips, senior vice president of entertainment for Walmart U.S. -

24 Adventure Island Age of Booty Alan Wake Alice In
24 24 – The Game PS2 | PAL | CiB SCE Studio Cambridge 2006 ADVENTURE ISLAND Super Adventure Island SNES | NOE | L Hudson Soft 1992 AGE OF BOOTY Age of Booty PS3 | DIGI | PSN Certain Affinity 2008 ALAN WAKE Alan Wake [Limited Collector's Edition] Xbox 360 | PAL | CiB Remedy Entertainment 2010 Alan Wake's American Nightmare Xbox 360 | DIGI | XBLA Remedy Entertainment 2012 ALICE IN WONDERLAND American McGee's Alice PS3 | DIGI | PSN Spicy Horse International 2011 Alice: Madness Returns PS3 | DIGI | PSN Spicy Horse International 2011 ALIEN Alien: Isolation [Ripley Edition] PS4 | R2 | CiB The Creative Assembly 2014 ALONE IN THE DARK Alone in the Dark: Inferno PS3 | R2 | CiB Eden Games / Artefacts Studio / Krysalide / ... 2008 AMNESIA ++ Amnesia ++ Amnesia: The Dark Descent PC | DIGI | Steam Frictional Games 2010 ++ Compilations ++ Amnesia Collection PS4 | DIGI | PSN Frictional Games / BlitWorks 2016 • Amnesia: The Dark Descent (2010) • Amnesia: A Machine for Pigs (2013) ANGRY BIRDS Angry Birds Trilogy PS3 | DIGI | PSN Rovio Entertainment / Housemarque 2012 • Angry Birds (2009) • Angry Birds: Seasons (2010) • Angry Birds: Rio (2011) ANGRY VIDEO GAME NERD The Angry Video Game Nerd Adventures Wii U | DIGI | Nintendo eShop FreakZone Games / MP2 Games 2015 ANIMAL CROSSING Animal Crossing: New Horizons NSW | UK4 | CiB Nintendo 2020 ARCADE CLASSICS: CAPCOM Capcom Arcade Cabinet PS3 | DIGI | PSN Capcom / M2 / Gotch 2013 • Black Tiger (1987) • DOWNLOADABLE GAMES: • 1942 (1984) • 1943: The Battle of Midway (1987) • Avengers (1987) • Commando (1985) • -

Skylanders Accessories Showcased in Powera Booth at E3 Controllers
FOR IMMEDIATE RELEASE Skylanders Accessories Showcased in PowerA Booth at E3 Controllers, Cases and More To Debut at E3 EXPO June 5-7 in Los Angeles Los Angeles, CA. – June 5, 2012 (E3 EXPO, Booth #5222 West Hall) -- PowerA today announced that it will debut an expansive collection of officially licensed Skylanders video game accessories at the E3 Expo June 5-7 in Los Angeles. Skylanders: Spyro's AdventureTM from Activision was the #1 new kids video game IP of 2011 and the franchise has achieved phenomenal success worldwide with its game that brings toys to life. Since game launch, PowerA has experienced unprecedented demand for its Skylanders Tower Case and Adventure Case video game storage and display products and Bobble Styluses. This year look for even more offerings for Skylanders fans, including accessories for the game’s upcoming sequel -- Skylanders GiantsTM. "The Skylanders phenomenon appears to be showing no signs of slowing down, and the response to PowerA Skylanders products has been amazing," said John Moore, divisional vice president of product development and marketing for PowerA. "Skylanders fans are clamoring for everything the franchise has to offer, and as the exclusive video game accessory licensee, our assortment of cases, controllers and accessories amplify their experience." “PowerA has already been a great partner in translating the elements of the game into engaging accessories that delight Skylanders fans,” said Ashley Maidy, Head of Global Licensing and Partnerships for Activision. “As we expand this license on a global scale, we’ll be working with PowerA to bring officially licensed Skylanders accessories to new territories.” This year, PowerA will be releasing Skylanders editions of its three most popular video game controllers: the Pro Pack Mini™ controller set for Nintendo Wii™, the Mini Pro EX Controller for PLAYSTATION® 3 and the officially licensed Mini Pro EX Wired Controller for Xbox 360®.