Automatic Animation of Discussions in USENET
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Downloadable Email Program for My Pc 32 Best Free Email Clients
downloadable email program for my pc 32 Best Free Email Clients. Here are 32 best free email client software . These let you manage and access all of your email accounts in one single place easily. All these email client software are completely free and can be downloaded to Windows PC. These free software offer various features, like: can be used with IMAP, SMTP, POP3 and Gmail, keeps your emails safe and secure, lets you open various emails simultaneously, provide protection from spam, lets you view your emails offline, manage and access all of your email accounts in one single place, supports PH, LDAP, IMAP4, POP3 and SMPT mail protocols etc. So, go through this list of free email client software and see which ones you like the most. Thunderbird. Thunderbird is a free and handy email client software for your computer. It can be used with IMAP, SMTP, POP3 and Gmail. It will also work with email accounts provided by MS Exchange Server. The user interface of Thunderbird is tabbed. It lets you open various emails simultaneously. Thunderbird keeps your emails safe and secure. It also has special filters for filtering the mail. Windows Live Mail. Windows Live Mail is a free email client for your computer. It works with various email accounts. It lets you access Yahoo, Gmail, Hotmail and emails from different servers which supports POP3 and SMTP. Its security features are excellent it will also provide protection from spam. You can also view your emails offline in this freeware. Zimbra Desktop. Zimbra Desktop is a free email client. -

How to Add an Apple Email Address to Microsoft Outlook
How to add an Apple Email Address to Microsoft Outlook For those of us who use ‘Two Factor Authentication’ with Apple, where you must enter a 6-digit code to access anything Apple, THIS IS THE THING that leads to the problem of connecting your iCloud email address to Outlook!!! How to fix this? 1. Open Outlook and a web browser 2. In the web browser, go to your Apple login page using: https://appleid.apple.com 3. Log in with your usual Apple username and password that you use for your iTunes account 4. If Apple ID Two-Factor Verification required, get 6-number code from iPhone and input the value 5. Once in, scroll down to the Security area, and then look for ‘App Specific Passwords' 6. Click on the link “Generate Password” and then create a name for this specific password (like 'outlook iCloud') and press “Create”. 7. A 16-digit password will be generated for you. Copy that password into memory or write it down. It will look something like this: abcd-efgh-ijkl-mnop 8. In Outlook you will receive an email from Apple titled: “An app-specific password was generated for your Apple ID” This is good. 9. Now go to the Outlook Account Settings window (File/Account Settings/Account Settings) which takes you to “Email Accounts” 10. On the Email tab, choose “New” 11. Enter your Apple email address (either [email protected] or [email protected]) 12. On the same window, press “Advanced options and “Let me set up my account manually” 13. -
Setting up Your E-Mail in Microsoft Entourage
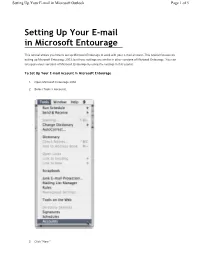
Setting Up Your E-mail in Microsoft Outlook Page 1 of 5 Setting Up Your E-mail in Microsoft Entourage This tutorial shows you how to set up Microsoft Entourage to work with your e-mail account. This tutorial focuses on setting up Microsoft Entourage 2003, but these settings are similar in other versions of Microsoft Entourage. You can set up previous versions of Microsoft Entourage by using the settings in this tutorial. To Set Up Your E-mail Account in Microsoft Entourage 1. Open Microsoft Entourage 2004. 2. Select Tools > Accounts. 3. Click "New." Setting Up Your E-mail in Microsoft Outlook Page 2 of 5 4. If the "Account Setup Assistant" window displays, click "Configure account manually." Setting Up Your E-mail in Microsoft Outlook Page 3 of 5 5. Select POP for the account type and click OK. 6. On the Edit Account window, enter your information as follows: Account name Enter a name for your account, for example: My Mail, Work, or Home. Name Enter your first and last name. E-mail address Enter your e-mail address. Account ID Enter your e-mail address, again. POP server Enter pop.secureserver.net as your incoming server Password Enter the password for your e-mail account. SMTP server Enter smtpout.secureserver.net for your outgoing mail server. Click "Click here for more advanced sending options." NOTE: "smtpout.secureserver.net" is an SMTP relay server. In order to use this server to send e-mails, you must first activate SMTP relay on your e-mail account. Log on to your Manage Email Accounts page to set up SMTP relay. -

Mailstore Server Vs. Office 365 Archiving
MailStore Server vs. Office 365 Archiving The goal of this document is to detail the advantages of using MailStore Server instead of Office 365 archiving for email archiving based on provable facts as opposed to mere assumptions or hearsay. To achieve this goal, only statements about Office 365 archiving that are based on publicly available material published by Microsoft are taken into account. These statements are compared to the capabilities of MailStore Server, based on equally publicly available material published by MailStore Software GmbH. To further enhance the quality of this analysis, all statements (with the exception of those related to pricing) have been extracted from technical specifications and implementation guides to ensure that they are based on current best practice and state of affairs. This document supersedes all previous versions and has been updated to the latest information available in April 2014. Overview No Feature MailStore Server Office 365 Archive 1. Supported versions of All editions of Outlook 2003, Specific editions of Outlook Outlook with access to the 2007, 2010, 2013 1 2007, 2010, 2013 2 archive 2. Supported Office 365 plans All plans that include email 3 Archiving options dependent on plan, with various limits. Additional features can be added to certain plans only 4,5,6 3. Search capabilities Full text search of all Search capabilities readable folders including dependent on the Outlook attachment contents 7 version and edition 8 4. Completeness of the archive Ensured through journaling ° Journaling not available support 9 in all plans 10 ° Office 365 needs external mailbox for journaling 10 The Experts in Email Archiving www.mailstore.com 2 | 7 No Feature MailStore Server Office 365 Archive 5. -

Activid® Activclient®
ActivID® ActivClient® Advanced security client protects workstations and networks with smart cards and smart USB keys HID Global’s ActivID® ActivClient® ensures strong authentication of employees, contractors and suppliers when they access enterprise resources, helping IT managers, security professionals and auditors to manage the risk of unauthorized access to workstations and networks by enabling the deployment of Zero Trust security framework. AT-A-GLANCE ACTIVCLIENT BENEFITS: • Increases security with proven As a market-leading middleware for Microsoft® Outlook®, Adobe technology that is widely adopted smart cards and smart USB keys, Acrobat® and popular web because of its user-friendly, familiar, ATM-like authentication experience ActivID ActivClient consolidates browsers), smart cards, smart card identity credentials (private keys readers and smart USB keys • Optimizes productivity with a single, versatile strong authentication for public key infrastructure [PKI] • Compatibility with major certificate tool for both Windows Login and certificates and symmetric keys for authorities and encryption utilities Remote Access (e.g., PIN-protected one-time password [OTP] generation) PKI certificates or OTPs for VPN) • Simple automated deployment, on a single, secure, portable updates and diagnostics • Improves compliance with device. This capability, combined government and industry with support for a wide range of • An open, standards-based regulations desktop and network applications, architecture, which is easily • Reduces costs with easy -

Oracle® Beehive Oracle Beehive Standards-Based Clients Help Release 2 (2.0)
Oracle® Beehive Oracle Beehive Standards-Based Clients Help Release 2 (2.0) November 2011 Last updated on November 4, 2011 This page contains configuration instructions and other related information for the following standards-based clients supported by Oracle Beehive: Hardware and Software Certification Managing your E-Mails ■ Apple Mail ■ Microsoft Outlook ■ Mozilla Thunderbird Managing Calendar and Task List ■ Apple iCal ■ Mozilla Lightning Using Instant Messaging ■ Apple iChat ■ Pidgin ■ Trillian Pro Accessing Documents (Web Clients and FTP Clients) ■ Browser-based Access ■ Desktop WebDAV Clients ■ Mac OS X Finder Web Access ■ Cadaver ■ Microsoft Windows Web Folders ■ Desktop FTP Clients ■ FileZilla ■ NCFTP ■ SmartFTP ■ Transmit RSS Clients Mobile Access Documentation Accessibility 1 Hardware and Software Certification The hardware and software requirements included in this installation guide were current at the time this guide was published. However, because new platforms and operating system software versions might be certified after this guide is published, review the certification matrix on the My Oracle Support Web site for the most up-to-date list of certified hardware platforms and operating system versions. My Oracle Support is available at the following URL: http://support.oracle.com/ You must register online before using My Oracle Support. Use the following steps to locate the certification information for your platform: 1. After logging in, click the Certifications tab. 2. In the Certification Search pane, on the Search tab, select the following information: ■ Product: Enter the product name or select from the drop-down list of Products. ■ Release: Select the release number of the product. ■ Platform: Select the target platform by choosing from the submenu list. -

You Can Configure Microsoft Outlook to Access Your Office 365 Account by Setting up an Exchange Connection
You can configure Microsoft Outlook to access your Office 365 account by setting up an Exchange connection. An Exchange connection provides access your email, calendar, contacts, and tasks in Outlook. You can also set up Outlook to access your email by using IMAP. However, if you use IMAP you can only access your email from Outlook, not your calendar, contacts, and tasks. Notes: ▪ Office 365 is designed to work with any version of Microsoft Office in mainstream support. Get Outlook for Windows Outlook is included with Microsoft Office 365. Faculty and staff with a Thiel ID and undergraduate students with an Office 365 account can download Microsoft Office for Windows via webmail for free. Please visit the Solution Center webpage for more information. Configure Outlook for Windows 1. Open Outlook. 2. At the Welcome screen, click Next. 3. When asked if you want to set up Outlook to connect to an email account, select Yes and then click Next. 4. The Auto Account Setup wizard opens. Enter your name, your email address using your ID#@thiel.edu, and your Thiel ID network password. Then, click Next 5. Outlook will complete the setup for your account, which might take several minutes. When you are notified that your account was successfully configured, click Finish. 6. You may need to restart Outlook for the changes to take effect. Change offline access setting You can use Outlook on your laptop or desktop computer when you’re not connected to the Internet. Email, calendar, and other items are kept in an Outlook data file on your computer so you can work offline. -

Operating System and Browser Requirements
Operating System and Browser Requirements This chapter lists the system requirements for end users to host and access meetings. • Common System Requirements, page 1 • Windows Operating System Requirements, page 2 • Mac Operating System Requirements, page 3 • Mobile Device Operating Systems Requirements, page 4 • Cisco WebEx Meetings Application and Productivity Tools Compatibility Matrix, page 4 Common System Requirements System requirements common to all browsers and operating systems. Client and Browser Requirements • JavaScript and cookies enabled • Java 6 and Java 7 (for web browsers that support Java) enabled • Cisco WebEx plug-ins enabled for Chrome 32 and later and Firefox 27 and later • Plug-ins enabled in Safari • Active X enabled and unblocked for Microsoft Internet Explorer (recommended) Cisco WebEx Meetings Server System Requirements Release 1.5 1 Operating System and Browser Requirements Windows Operating System Requirements Note Because of Google and Mozilla policy changes, starting with Chrome 32 and Firefox 27, it might be necessary for users to manually enable the WebEx plug-in when using these browsers1 to join a WebEx meeting or to play a WebEx recording. More information and instructions can be found at https:// support.webex.com/webex/meetings/en_US/chrome-firefox-join-faq.htm. If a client is using a browser other than the specified versions of Chrome or Firefox and have Java enabled, the Cisco WebEx Meetings application automatically downloads onto the client system the first time that client starts or joins a meeting. We recommend that you direct all clients to install the latest update for your Java version. SSL and TLS Requirements Configure Internet settings on all user computers to use SSL and TLS encryption. -

Outlook Integration Implementation Guide
Outlook Integration Implementation Guide Salesforce, Winter ’22 @salesforcedocs Last updated: August 30, 2021 © Copyright 2000–2021 salesforce.com, inc. All rights reserved. Salesforce is a registered trademark of salesforce.com, inc., as are other names and marks. Other marks appearing herein may be trademarks of their respective owners. CONTENTS Outlook Integration . 1 Outlook Integration System Requirements . 2 Set Up the Integration with Outlook . 4 Guidelines for Setting Up the Outlook Integration . 5 Microsoft Exchange Server Setup for the Outlook Integration . 7 Turn On the Outlook Integration in Salesforce . 8 Deploy the Outlook Integration to Users . 9 Enable Event Type Selections to Log Events from Outlook or Gmail . 10 Enhanced Email and the Outlook Integration . 11 Add Salesforce Inbox Features to the Outlook Integration . 12 OUTLOOK INTEGRATION The Salesforce integration with Outlook is one of a suite of products that give sales reps the power to work from their email applications, while keeping Salesforce data up to date. The integration provides Salesforce data directly within Outlook, and the ability to log emails and events to Salesforce records. Add Einstein Activity Capture to automate email and event logging and to sync contacts and calendar events between Salesforce and Outlook. To learn more about other products available, see Salesforce Help. For security considerations for the Outlook integration, see Salesforce Email Integration Security Guide. For security considerations for Einstein Activity Capture, see the Einstein Activity Capture Security Guide. This guide discusses the Exchange server settings, Salesforce setup, and a short client-side procedure required to set up the integration. The initial setup requires a Salesforce administrator, the IT pro who maintains your Microsoft Exchange server, and the sales reps running the integration in Outlook. -
Recommended Browsers for the Microsoft Outlook Web App UITS Recommends Using the Most Up-To-Date Browser That Is Compatible with Your Operating System
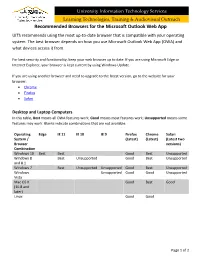
University Information Technology Services Learning Technologies, Training & Audiovisual Outreach Recommended Browsers for the Microsoft Outlook Web App UITS recommends using the most up-to-date browser that is compatible with your operating system. The best browser depends on how you use Microsoft Outlook Web App (OWA) and what devices access it from. For best security and functionality, keep your web browser up to date. If you are using Microsoft Edge or Internet Explorer, your browser is kept current by using Windows Update. If you are using another browser and need to upgrade to the latest version, go to the website for your browser: • Chrome • Firefox • Safari Desktop and Laptop Computers In this table, Best means all OWA features work; Good means most features work; Unsupported means some features may work. Blanks indicate combinations that are not available. Operating Edge IE 11 IE 10 IE 9 Firefox Chrome Safari System / (Latest) (Latest) (Latest two Browser versions) Combination Windows 10 Best Best Good Best Unsupported Windows 8 Best Unsupported Good Best Unsupported and 8.1 Windows 7 Best Unsupported Unsupported Good Best Unsupported Windows Unsupported Good Good Unsupported Vista Mac OS X Good Best Good (10.8 and later) Linux Good Good Page 1 of 2 University Information Technology Services Learning Technologies, Training & Audiovisual Outreach Tablets In this table, Best means all OWA features work; Good means most features work; Unsupported means some features may work. Blanks indicate combinations that are not available. Operating Edge Internet Firefox Chrome Safari Other Native system / Explorer (Latest) (Latest) Browser browser (Latest) combination Windows 10 Best Best Good Best Unsupported Windows 8 Best Good Best Unsupported and 8.1 Android Unsupported Unsupported Unsupported (Latest) iOS (Latest) Unsupported Unsupported Good Smartphones In this table, Best means you can use the touch-enabled Mobile Viewer; Good means you can use a menu- driven Mobile Viewer; Unsupported means some features may work. -

Contact Groups in Microsoft Outlook 2010
Nonprofit Technology Collaboration Contact Groups in Microsoft Outlook 2010 What are Contact Groups? A contact group is a collection of contacts in your email. It provides an easy way to send e-mail messages to a group of people. For example, if you frequently send messages to the marketing team, you can create a contact group – called “Marketing Team” – that contains the e-mail addresses of everyone on that team. A message sent to this contact group goes to all recipients listed in the contact group. You can include contact groups in email messages, task requests, meeting requests, and even in other contact groups. Note: Prior to Outlook 2010, contact groups are referred to as Distribution List in 2007. Create the Contact Group 1. On the Outlook home page, click the Contacts Button, located in the left pane. Right-Click the white space and click New Contact Group. 2. In the name box enter a meaningful name for your group. Press the Enter key on your keyboard. This will cause the title at the top of your window to change to the name you have just entered. I.E. “Marketing Team”. Your contact group is now created; you can begin to add email contacts to your contact group. Last Updated: 10/26/2012 Contact Groups Page 1 of 11 Nonprofit Technology Collaboration Add Contacts to Your Contact Group Once your contact group has been saved in the contacts folder you can begin adding email contacts to your contact group. In this section and in the following, we demonstrate the use of adding members from the address book, manually entering new contacts, and copying contacts from an email message. -

Microsoft Outlook Contact Configuration for Fax Recipients
PureConnect® 2020 R1 Generated: 18-February-2020 Microsoft Outlook Contact Content last updated: 08-May-2019 Configuration for Fax See Change Log for summary of changes. Recipients Technical Reference Abstract This document contains instructions for enabling public Outlook contacts to appear as Fax Viewer recipients. For the latest version of this document, see the PureConnect Documentation Library at: http://help.genesys.com/cic. For copyright and trademark information, see https://help.genesys.com/cic/desktop/copyright_and_trademark_information.htm. 1 Table of Contents Table of Contents 2 Introduction 3 Configuring a Public Outlook Contacts Folder 4 Configuring a Private Outlook Contacts Folder 7 Selecting an Outlook Contact as a Fax Recipient 8 Change Log 10 2 Introduction You can configure Outlook contacts through Interaction Administrator so they appear in an address book in Interaction Fax where users can select them as fax recipients. Administrators can use this feature to configure a public Outlook Contacts folder available to all users. In addition, users can select their private Outlook contacts from their local computers as fax recipients. Configuring a Public Outlook Contacts Folder Configuring a Private Outlook Contacts Folder Selecting an Outlook Contact as a Fax Recipient 3 Configuring a Public Outlook Contacts Folder System administrators should follow these steps to configure a public Outlook Contacts folder to appear in Interaction Fax: 1. On the Outlook File menu, select File > New > Folder. The Create a New Folder dialog box displays. 2. In the Create New Folder dialog box, enter the name Contacts. 3. In the Folder contains drop-down menu, select Contact Items. 4.