PERFORMANCE IMPROVEMENT of MULTITHREADED JAVA APPLICATIONS EXECUTION on MULTIPROCESSOR SYSTEMS By
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Events, Co-Routines, Continuations and Threads OS (And Application)Execution Models System Building
Events, Co-routines, Continuations and Threads OS (and application)Execution Models System Building General purpose systems need to deal with • Many activities – potentially overlapping – may be interdependent • Activities that depend on external phenomena – may requiring waiting for completion (e.g. disk read) – reacting to external triggers (e.g. interrupts) Need a systematic approach to system structuring © Kevin Elphinstone 2 Construction Approaches Events Coroutines Threads Continuations © Kevin Elphinstone 3 Events External entities generate (post) events. • keyboard presses, mouse clicks, system calls Event loop waits for events and calls an appropriate event handler. • common paradigm for GUIs Event handler is a function that runs until completion and returns to the event loop. © Kevin Elphinstone 4 Event Model The event model only requires a single stack Memory • All event handlers must return to the event loop CPU Event – No blocking Loop – No yielding PC Event SP Handler 1 REGS Event No preemption of handlers Handler 2 • Handlers generally short lived Event Handler 3 Data Stack © Kevin Elphinstone 5 What is ‘a’? int a; /* global */ int func() { a = 1; if (a == 1) { a = 2; } No concurrency issues within a return a; handler } © Kevin Elphinstone 6 Event-based kernel on CPU with protection Kernel-only Memory User Memory CPU Event Loop Scheduling? User PC Event Code SP Handler 1 REGS Event Handler 2 User Event Data Handler 3 Huh? How to support Data Stack multiple Stack processes? © Kevin Elphinstone 7 Event-based kernel on CPU with protection Kernel-only Memory User Memory CPU PC Trap SP Dispatcher User REGS Event Code Handler 1 User-level state in PCB Event PCB Handler 2 A User Kernel starts on fresh Timer Event Data stack on each trap (Scheduler) PCB B No interrupts, no blocking Data Current in kernel mode Thead PCB C Stack Stack © Kevin Elphinstone 8 Co-routines Originally described in: • Melvin E. -

Designing an Ultra Low-Overhead Multithreading Runtime for Nim
Designing an ultra low-overhead multithreading runtime for Nim Mamy Ratsimbazafy Weave [email protected] https://github.com/mratsim/weave Hello! I am Mamy Ratsimbazafy During the day blockchain/Ethereum 2 developer (in Nim) During the night, deep learning and numerical computing developer (in Nim) and data scientist (in Python) You can contact me at [email protected] Github: mratsim Twitter: m_ratsim 2 Where did this talk came from? ◇ 3 years ago: started writing a tensor library in Nim. ◇ 2 threading APIs at the time: OpenMP and simple threadpool ◇ 1 year ago: complete refactoring of the internals 3 Agenda ◇ Understanding the design space ◇ Hardware and software multithreading: definitions and use-cases ◇ Parallel APIs ◇ Sources of overhead and runtime design ◇ Minimum viable runtime plan in a weekend 4 Understanding the 1 design space Concurrency vs parallelism, latency vs throughput Cooperative vs preemptive, IO vs CPU 5 Parallelism is not 6 concurrency Kernel threading 7 models 1:1 Threading 1 application thread -> 1 hardware thread N:1 Threading N application threads -> 1 hardware thread M:N Threading M application threads -> N hardware threads The same distinctions can be done at a multithreaded language or multithreading runtime level. 8 The problem How to schedule M tasks on N hardware threads? Latency vs 9 Throughput - Do we want to do all the work in a minimal amount of time? - Numerical computing - Machine learning - ... - Do we want to be fair? - Clients-server - Video decoding - ... Cooperative vs 10 Preemptive Cooperative multithreading: -

An Ideal Match?
24 November 2020 An ideal match? Investigating how well-suited Concurrent ML is to implementing Belief Propagation for Stereo Matching James Cooper [email protected] OutlineI 1 Stereo Matching Generic Stereo Matching Belief Propagation 2 Concurrent ML Overview Investigation of Alternatives Comparative Benchmarks 3 Concurrent ML and Belief Propagation 4 Conclusion Recapitulation Prognostication 5 References Outline 1 Stereo Matching Generic Stereo Matching Belief Propagation 2 Concurrent ML Overview Investigation of Alternatives Comparative Benchmarks 3 Concurrent ML and Belief Propagation 4 Conclusion Recapitulation Prognostication 5 References Outline 1 Stereo Matching Generic Stereo Matching Belief Propagation 2 Concurrent ML Overview Investigation of Alternatives Comparative Benchmarks 3 Concurrent ML and Belief Propagation 4 Conclusion Recapitulation Prognostication 5 References Stereo Matching Generally SM is finding correspondences between stereo images Images are of the same scene Captured simultaneously Correspondences (`disparity') are used to estimate depth SM is an ill-posed problem { can only make best guess Impossible to perform `perfectly' in general case Stereo Matching ExampleI (a) Left camera's image (b) Right camera's image Figure 1: The popular 'Tsukuba' example stereo matching images, so called because they were created by researchers at the University of Tsukuba, Japan. They are probably the most widely-used benchmark images in stereo matching. Stereo Matching ExampleII (a) Ground truth disparity map (b) Disparity map generated using a simple Belief Propagation Stereo Matching implementation Figure 2: The ground truth disparity map for the Tsukuba images, and an example of a possible real disparity map produced by using Belief Propagation Stereo Matching. The ground truth represents what would be expected if stereo matching could be carried out `perfectly'. -

Tcl and Java Performance
Tcl and Java Performance http://ptolemy.eecs.berkeley.edu/~cxh/java/tclblend/scriptperf/scriptperf.html Tcl and Java Performance by H. John Reekie, University of California at Berkeley Christopher Hylands, University of California at Berkeley Edward A. Lee, University of California at Berkeley Abstract Combining scripting languages such as Tcl with lower−level programming languages such as Java offers new opportunities for flexible and rapid software development. In this paper, we benchmark various combinations of Tcl and Java against the two languages alone. We also provide some comparisons with JavaScript. Performance can vary by well over two orders of magnitude. We also uncovered some interesting threading issues that affect performance on the Solaris platform. "There are lies, damn lies and statistics" This paper is a work in progress, we used the information here to give our group some generalizations on the performance tradeoffs between various scripting languages. Updating the timing results to include JDK1.2 with a Just In Time (JIT) compiler would be useful. Introduction There is a growing trend towards integration of multiple languages through scripting. In a famously controversial white paper (Ousterhout 97), John Ousterhout, now of Scriptics Corporation, argues that scripting −− the use of a high−level, untyped, interpreted language to "glue" together components written in a lower−level language −− provides greater reuse benefits that other reuse technologies. Although traditionally a language such as C or C++ has been the lower−level language, more recent efforts have focused on using Java. Recently, Sun Microsystems laboratories announced two products aimed at fulfilling this goal with the Tcl and Java programming languages. -

Engineering Definitional Interpreters
Reprinted from the 15th International Symposium on Principles and Practice of Declarative Programming (PPDP 2013) Engineering Definitional Interpreters Jan Midtgaard Norman Ramsey Bradford Larsen Department of Computer Science Department of Computer Science Veracode Aarhus University Tufts University [email protected] [email protected] [email protected] Abstract In detail, we make the following contributions: A definitional interpreter should be clear and easy to write, but it • We investigate three styles of semantics, each of which leads to may run 4–10 times slower than a well-crafted bytecode interpreter. a family of definitional interpreters. A “family” is characterized In a case study focused on implementation choices, we explore by its representation of control contexts. Our best-performing ways of making definitional interpreters faster without expending interpreter, which arises from a natural semantics, represents much programming effort. We implement, in OCaml, interpreters control contexts using control contexts of the metalanguage. based on three semantics for a simple subset of Lua. We com- • We evaluate other implementation choices: how names are rep- pile the OCaml to 86 native code, and we systematically inves- x resented, how environments are represented, whether the inter- tigate hundreds of combinations of algorithms and data structures. preter has a separate “compilation” step, where intermediate re- In this experimental context, our fastest interpreters are based on sults are stored, and how loops are implemented. natural semantics; good algorithms and data structures make them 2–3 times faster than na¨ıve interpreters. Our best interpreter, cre- • We identify combinations of implementation choices that work ated using only modest effort, runs only 1.5 times slower than a well together. -

Thread Scheduling in Multi-Core Operating Systems Redha Gouicem
Thread Scheduling in Multi-core Operating Systems Redha Gouicem To cite this version: Redha Gouicem. Thread Scheduling in Multi-core Operating Systems. Computer Science [cs]. Sor- bonne Université, 2020. English. tel-02977242 HAL Id: tel-02977242 https://hal.archives-ouvertes.fr/tel-02977242 Submitted on 24 Oct 2020 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Ph.D thesis in Computer Science Thread Scheduling in Multi-core Operating Systems How to Understand, Improve and Fix your Scheduler Redha GOUICEM Sorbonne Université Laboratoire d’Informatique de Paris 6 Inria Whisper Team PH.D.DEFENSE: 23 October 2020, Paris, France JURYMEMBERS: Mr. Pascal Felber, Full Professor, Université de Neuchâtel Reviewer Mr. Vivien Quéma, Full Professor, Grenoble INP (ENSIMAG) Reviewer Mr. Rachid Guerraoui, Full Professor, École Polytechnique Fédérale de Lausanne Examiner Ms. Karine Heydemann, Associate Professor, Sorbonne Université Examiner Mr. Etienne Rivière, Full Professor, University of Louvain Examiner Mr. Gilles Muller, Senior Research Scientist, Inria Advisor Mr. Julien Sopena, Associate Professor, Sorbonne Université Advisor ABSTRACT In this thesis, we address the problem of schedulers for multi-core architectures from several perspectives: design (simplicity and correct- ness), performance improvement and the development of application- specific schedulers. -

Open Programming Language Interpreters
Open Programming Language Interpreters Walter Cazzolaa and Albert Shaqiria a Università degli Studi di Milano, Italy Abstract Context: This paper presents the concept of open programming language interpreters, a model to support them and a prototype implementation in the Neverlang framework for modular development of programming languages. Inquiry: We address the problem of dynamic interpreter adaptation to tailor the interpreter’s behaviour on the task to be solved and to introduce new features to fulfil unforeseen requirements. Many languages provide a meta-object protocol (MOP) that to some degree supports reflection. However, MOPs are typically language-specific, their reflective functionality is often restricted, and the adaptation and application logic are often mixed which hardens the understanding and maintenance of the source code. Our system overcomes these limitations. Approach: We designed a model and implemented a prototype system to support open programming language interpreters. The implementation is integrated in the Neverlang framework which now exposes the structure, behaviour and the runtime state of any Neverlang-based interpreter with the ability to modify it. Knowledge: Our system provides a complete control over interpreter’s structure, behaviour and its runtime state. The approach is applicable to every Neverlang-based interpreter. Adaptation code can potentially be reused across different language implementations. Grounding: Having a prototype implementation we focused on feasibility evaluation. The paper shows that our approach well addresses problems commonly found in the research literature. We have a demon- strative video and examples that illustrate our approach on dynamic software adaptation, aspect-oriented programming, debugging and context-aware interpreters. Importance: Our paper presents the first reflective approach targeting a general framework for language development. -

Comparison of Concurrency Frameworks for the Java Virtual Machine
Universität Ulm Fakultät für Ingenieurwissenschaften und Informatik Institut für Verteilte Systeme, Bachelorarbeit im Studiengang Informatik Comparison of Concurrency Frameworks for the Java Virtual Machine Thomas Georg Kühner vorgelegt am 25. Oktober 2013 VS-B13-2013 Gutachter Prof. Dr. Frank Kargl Fassung vom: December 8, 2013 cbnd Diese Arbeit ist lizensiert unter der Creative Commons Namensnennung-Keine kommerzielle Nutzung-Keine Bearbeitung 3.0 Deutschland Lizenz. Nähere Informationen finden Sie unter: http://creativecommons.org/licenses/by-nc-nd/3.0/de/ oder senden Sie einen Brief an: Creative Commons, 171 Second Street, Suite 300, San Francisco, California, 94105, USA. Contents 1. Introduction 1 1.1. Motivation..........................................1 1.2. Scope of this Thesis.....................................2 1.3. Methodology........................................2 1.4. Road Map for this thesis..................................2 2. Basics and Background about Concurrency and Concurrent Programming3 2.1. Terminology.........................................3 2.2. Small History of Concurrency Theory..........................5 2.3. General Programming Models for Concurrency....................6 2.4. Traditional Concurrency Issues..............................7 2.4.1. Race Condition...................................7 2.4.2. Dead-Lock......................................8 2.4.3. Starvation......................................8 2.4.4. Priority Inversion..................................9 2.5. Summary...........................................9 -

Threading and GUI Issues for R
Threading and GUI Issues for R Luke Tierney School of Statistics University of Minnesota March 5, 2001 Contents 1 Introduction 2 2 Concurrency and Parallelism 2 3 Concurrency and Dynamic State 3 3.1 Options Settings . 3 3.2 User Defined Options . 5 3.3 Devices and Par Settings . 5 3.4 Standard Connections . 6 3.5 The Context Stack . 6 3.5.1 Synchronization . 6 4 GUI Events And Blocking IO 6 4.1 UNIX Issues . 7 4.2 Win32 Issues . 7 4.3 Classic MacOS Issues . 8 4.4 Implementations To Consider . 8 4.5 A Note On Java . 8 4.6 A Strategy for GUI/IO Management . 9 4.7 A Sample Implementation . 9 5 Threads and GUI’s 10 6 Threading Design Space 11 6.1 Parallelism Through HL Threads: The MXM Options . 12 6.2 Light-Weight Threads: The XMX Options . 12 6.3 Multiple OS Threads Running One At A Time: MSS . 14 6.4 Variations on OS Threads . 14 6.5 SMS or MXS: Which To Choose? . 14 7 Light-Weight Thread Implementation 14 1 March 5, 2001 2 8 Other Issues 15 8.1 High-Level GUI Interfaces . 16 8.2 High-Level Thread Interfaces . 16 8.3 High-Level Streams Interfaces . 16 8.4 Completely Random Stuff . 16 1 Introduction This document collects some random thoughts on runtime issues relating to concurrency, threads, GUI’s and the like. Some of this is extracted from recent R-core email threads. I’ve tried to provide lots of references that might be of use. -

A Hybrid Approach of Compiler and Interpreter Achal Aggarwal, Dr
International Journal of Scientific & Engineering Research, Volume 5, Issue 6, June-2014 1022 ISSN 2229-5518 A Hybrid Approach of Compiler and Interpreter Achal Aggarwal, Dr. Sunil K. Singh, Shubham Jain Abstract— This paper essays the basic understanding of compiler and interpreter and identifies the need of compiler for interpreted languages. It also examines some of the recent developments in the proposed research. Almost all practical programs today are written in higher-level languages or assembly language, and translated to executable machine code by a compiler and/or assembler and linker. Most of the interpreted languages are in demand due to their simplicity but due to lack of optimization, they require comparatively large amount of time and space for execution. Also there is no method for code minimization; the code size is larger than what actually is needed due to redundancy in code especially in the name of identifiers. Index Terms— compiler, interpreter, optimization, hybrid, bandwidth-utilization, low source-code size. —————————— —————————— 1 INTRODUCTION order to reduce the complexity of designing and building • Compared to machine language, the notation used by Icomputers, nearly all of these are made to execute relatively programming languages closer to the way humans simple commands (but do so very quickly). A program for a think about problems. computer must be built by combining some very simple com- • The compiler can spot some obvious programming mands into a program in what is called machine language. mistakes. Since this is a tedious and error prone process most program- • Programs written in a high-level language tend to be ming is, instead, done using a high-level programming lan- shorter than equivalent programs written in machine guage. -
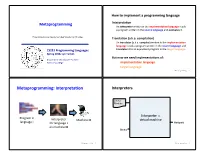
Metaprogramming: Interpretaaon Interpreters
How to implement a programming language Metaprogramming InterpretaAon An interpreter wriDen in the implementaAon language reads a program wriDen in the source language and evaluates it. These slides borrow heavily from Ben Wood’s Fall ‘15 slides. TranslaAon (a.k.a. compilaAon) An translator (a.k.a. compiler) wriDen in the implementaAon language reads a program wriDen in the source language and CS251 Programming Languages translates it to an equivalent program in the target language. Spring 2018, Lyn Turbak But now we need implementaAons of: Department of Computer Science Wellesley College implementaAon language target language Metaprogramming 2 Metaprogramming: InterpretaAon Interpreters Source Program Interpreter = Program in Interpreter Machine M virtual machine language L for language L Output on machine M Data Metaprogramming 3 Metaprogramming 4 Metaprogramming: TranslaAon Compiler C Source x86 Target Program C Compiler Program if (x == 0) { cmp (1000), $0 Program in Program in x = x + 1; bne L language A } add (1000), $1 A to B translator language B ... L: ... x86 Target Program x86 computer Output Interpreter Machine M Thanks to Ben Wood for these for language B Data and following pictures on machine M Metaprogramming 5 Metaprogramming 6 Interpreters vs Compilers Java Compiler Interpreters No work ahead of Lme Source Target Incremental Program Java Compiler Program maybe inefficient if (x == 0) { load 0 Compilers x = x + 1; ifne L } load 0 All work ahead of Lme ... inc See whole program (or more of program) store 0 Time and resources for analysis and opLmizaLon L: ... (compare compiled C to compiled Java) Metaprogramming 7 Metaprogramming 8 Compilers... whose output is interpreted Interpreters.. -

Bioinformatics: a Practical Guide to the Analysis of Genes and Proteins, Second Edition Andreas D
BIOINFORMATICS A Practical Guide to the Analysis of Genes and Proteins SECOND EDITION Andreas D. Baxevanis Genome Technology Branch National Human Genome Research Institute National Institutes of Health Bethesda, Maryland USA B. F. Francis Ouellette Centre for Molecular Medicine and Therapeutics Children’s and Women’s Health Centre of British Columbia University of British Columbia Vancouver, British Columbia Canada A JOHN WILEY & SONS, INC., PUBLICATION New York • Chichester • Weinheim • Brisbane • Singapore • Toronto BIOINFORMATICS SECOND EDITION METHODS OF BIOCHEMICAL ANALYSIS Volume 43 BIOINFORMATICS A Practical Guide to the Analysis of Genes and Proteins SECOND EDITION Andreas D. Baxevanis Genome Technology Branch National Human Genome Research Institute National Institutes of Health Bethesda, Maryland USA B. F. Francis Ouellette Centre for Molecular Medicine and Therapeutics Children’s and Women’s Health Centre of British Columbia University of British Columbia Vancouver, British Columbia Canada A JOHN WILEY & SONS, INC., PUBLICATION New York • Chichester • Weinheim • Brisbane • Singapore • Toronto Designations used by companies to distinguish their products are often claimed as trademarks. In all instances where John Wiley & Sons, Inc., is aware of a claim, the product names appear in initial capital or ALL CAPITAL LETTERS. Readers, however, should contact the appropriate companies for more complete information regarding trademarks and registration. Copyright ᭧ 2001 by John Wiley & Sons, Inc. All rights reserved. No part of this publication may be reproduced, stored in a retrieval system or transmitted in any form or by any means, electronic or mechanical, including uploading, downloading, printing, decompiling, recording or otherwise, except as permitted under Sections 107 or 108 of the 1976 United States Copyright Act, without the prior written permission of the Publisher.