Netfilter's Connection Tracking System
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Free and Open Source Software Is Not a “Free for All”: German Court Enforces GPL License Terms
Free and Open Source Software Is Not A “Free For All”: German Court Enforces GPL License Terms The GNU General Public License, computer programs, and to guarantee version 2 (GPLv2) scores another the same rights to the recipients of court victory for the free and/or open works licensed under the GPLv2. source software (FOSS) community. Although the open-source movement The GPLv2 carries important has been active for nearly two conditions, however, most notably— decades, globally there are only and critical for its viability—that any a handful of cases in which a FOSS distribution of software licensed under license has been reviewed by — let the GPLv2 must be accompanied with alone receive the imprimatur of the “complete corresponding machine- enforceability from — a court. The readable source code” or “a written latest case hails from Germany and offer … to give any third party … a serves to underscore the importance complete machine-readable copy of of proper FOSS-license compliance the corresponding source code”. throughout the software development GPLv2, Sections 3(a) and 3(b). process and supply chain, including During a “Hacking for Compliance the obligation of distributors to Workshop” organized in Berlin in 2012 independently verify FOSS-license by the Free Software Foundation compliance representations from their Europe, the source code package for a suppliers. media player with GNU/Linux-based Welte v. Fantec firmware inside was found not to contain the source code for the Harald Welte, founder of gpl- iptables components. It was also violations.org (a non-profit discovered that the source code for organization aiming at the other device components was not the enforcement of GPL license terms), is same version used to compile the the owner of “netfilter/iptables” firmware’s binary code. -

SNMP Trap - Firewall Rules
SNMP Trap - Firewall Rules Article Number: 87 | Rating: 1/5 from 1 votes | Last Updated: Wed, Jan 13, 2021 at 4:42 PM Fir e wall Rule s These steps explain how to check if the Operating System (OS) of the Nagios server has firewall rules enabled to allow inbound SNMP Trap UDP port 162 traffic. The different supported OS's have different firewall commands which are explained as follows. You will need to establish an SSH session to the Nagios server that is receiving SNMP Traps. RHEL 7/8 | C e nt O S 7/8 | O r ac le Linux 7/8 First check the status of the firewall: systemctl status firewalld.service IF the firewall is running , it should product output like: ● firewalld.service - firewalld - dynamic firewall daemon Loaded: loaded (/usr/lib/systemd/system/firewalld.service; enabled; vendor preset: enabled) Active: active (running) since Tue 2018-11-20 10:05:15 AEDT; 1 weeks 0 days ago Docs: man:firewalld(1) Main PID: 647 (firewalld) CGroup: /system.slice/firewalld.service └─647 /usr/bin/python -Es /usr/sbin/firewalld --nofork --nopid IF the firewall is NO T running, it will produce this output: ● firewalld.service - firewalld - dynamic firewall daemon Loaded: loaded (/usr/lib/systemd/system/firewalld.service; enabled; vendor preset: enabled) Active: inactive (dead) since Tue 2018-11-27 14:11:34 AEDT; 965ms ago Docs: man:firewalld(1) Main PID: 647 (code=exited, status=0/SUCCESS) If the firewall is NOT running, this means that inbound traffic is allowed. To ENABLE the firewall on b o o t and to s ta rt it, execute the following commands: systemctl -

Open Source Software Notice
OPEN SOURCE SOFTWARE NOTICE DCS Touch Display Software V2.00.XXX Schüco International KG Karolinenstraße 1-15 33609 Bielefeld OPEN SOURCE SOFTWARE NOTICE Seite 1 von 32 10000507685_02_EN OPEN SOURCE SOFTWARE NOTICE This document contains information about open source software for this product. The rights granted under open source software licenses are granted by the respective right holders. In the event of conflicts between SCHÜCO’S license conditions and the applicable open source licenses, the open source license conditions take precedence over SCHÜCO’S license conditions with regard to the respective open source software. You are allowed to modify SCHÜCO’S proprietary programs and to conduct reverse engineering for the purpose of debugging such modifications, to the extent such programs are linked to libraries licensed under the GNU Lesser General Public License. You are not allowed to distribute information resulting from such reverse engineering or to distribute the modified proprietary programs. The rightholders of the open source software require to refer to the following disclaimer, which shall apply with regard to those rightholders: Warranty Disclaimer THE OPEN SOURCE SOFTWARE IN THIS PRODUCT IS DISTRIBUTED ON AN "AS IS" BASIS AND IN THE HOPE THAT IT WILL BE USEFUL, BUT WITHOUT ANY WARRANTY OF ANY KIND, WITHOUT EVEN THE IMPLIED WARRANTY OF MERCHANTABILITY OR FITNESS FOR A PARTICULAR PURPOSE. SEE THE APPLICABLE LICENSES FOR MORE DETAILS. OPEN SOURCE SOFTWARE NOTICE Seite 2 von 32 10000507685_02_EN Copyright Notices and License Texts (please see the source code for all details) Software: iptables Copyright notice: Copyright (C) 1989, 1991 Free Software Foundation, Inc. Copyright Google, Inc. -

Communicating Between the Kernel and User-Space in Linux Using Netlink Sockets
SOFTWARE—PRACTICE AND EXPERIENCE Softw. Pract. Exper. 2010; 00:1–7 Prepared using speauth.cls [Version: 2002/09/23 v2.2] Communicating between the kernel and user-space in Linux using Netlink sockets Pablo Neira Ayuso∗,∗1, Rafael M. Gasca1 and Laurent Lefevre2 1 QUIVIR Research Group, Departament of Computer Languages and Systems, University of Seville, Spain. 2 RESO/LIP team, INRIA, University of Lyon, France. SUMMARY When developing Linux kernel features, it is a good practise to expose the necessary details to user-space to enable extensibility. This allows the development of new features and sophisticated configurations from user-space. Commonly, software developers have to face the task of looking for a good way to communicate between kernel and user-space in Linux. This tutorial introduces you to Netlink sockets, a flexible and extensible messaging system that provides communication between kernel and user-space. In this tutorial, we provide fundamental guidelines for practitioners who wish to develop Netlink-based interfaces. key words: kernel interfaces, netlink, linux 1. INTRODUCTION Portable open-source operating systems like Linux [1] provide a good environment to develop applications for the real-world since they can be used in very different platforms: from very small embedded devices, like smartphones and PDAs, to standalone computers and large scale clusters. Moreover, the availability of the source code also allows its study and modification, this renders Linux useful for both the industry and the academia. The core of Linux, like many modern operating systems, follows a monolithic † design for performance reasons. The main bricks that compose the operating system are implemented ∗Correspondence to: Pablo Neira Ayuso, ETS Ingenieria Informatica, Department of Computer Languages and Systems. -

Introduction to Linux Virtual Server and High Availability
Outlines Introduction to Linux Virtual Server and High Availability Chen Kaiwang [email protected] December 5, 2011 Chen Kaiwang [email protected] LVS-DR and Keepalived Outlines If you don't know the theory, you don't have a way to be rigorous. Robert J. Shiller http://www.econ.yale.edu/~shiller/ Chen Kaiwang [email protected] LVS-DR and Keepalived Outlines Misery stories I Jul 2011 Too many connections at zongheng.com I Aug 2011 Realserver maintenance at 173.com quiescent persistent connections I Nov 2011 Health check at 173.com I Nov 2011 Virtual service configuration at 173.com persistent session data Chen Kaiwang [email protected] LVS-DR and Keepalived Outlines Outline of Part I Introduction to Linux Virtual Server Configuration Overview Netfilter Architecture Job Scheduling Scheduling Basics Scheduling Algorithms Connection Affinity Persistence Template Persistence Granularity Quirks Chen Kaiwang [email protected] LVS-DR and Keepalived Outlines Outline of Part II HA Basics LVS High Avaliablity Realserver Failover Director Failover Solutions Heartbeat Keepalived Chen Kaiwang [email protected] LVS-DR and Keepalived LVS Intro Job Scheduling Connection Affinity Quirks Part I Introduction to Linux Virtual Server Chen Kaiwang [email protected] LVS-DR and Keepalived LVS Intro Job Scheduling Configuration Overview Connection Affinity Netfilter Architecture Quirks Introduction to Linux Virtual Server Configuration Overview Netfilter Architecture Job Scheduling Scheduling Basics Scheduling Algorithms Connection Affinity Persistence Template Persistence Granularity Quirks Chen Kaiwang [email protected] LVS-DR and Keepalived LVS Intro Job Scheduling Configuration Overview Connection Affinity Netfilter Architecture Quirks A Linux Virtual Serverr (LVS) is a group of servers that appear to the client as one large, fast, reliable (highly available) server. -

Step-By-Step Strategies and Case Studies for Embedded Software Companies to Adapt to the FOSS Ecosystem Suhyun Kim, Jaehyun Yoo, Myunghwa Lee
Step-by-Step Strategies and Case Studies for Embedded Software Companies to Adapt to the FOSS Ecosystem Suhyun Kim, Jaehyun Yoo, Myunghwa Lee To cite this version: Suhyun Kim, Jaehyun Yoo, Myunghwa Lee. Step-by-Step Strategies and Case Studies for Embed- ded Software Companies to Adapt to the FOSS Ecosystem. 8th International Conference on Open Source Systems (OSS), Sep 2012, Hammamet, Tunisia. pp.48-60, 10.1007/978-3-642-33442-9_4. hal-01519083 HAL Id: hal-01519083 https://hal.inria.fr/hal-01519083 Submitted on 5 May 2017 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Distributed under a Creative Commons Attribution| 4.0 International License Step-by-Step Strategies and Case Studies for Embedded Software Companies to Adapt to the FOSS Ecosystem Suhyun Kim, Jaehyun Yoo, and Myunghwa Lee Software Engineering Lab, Software R&D Center, Samsung Electronics 416 Maetan-Dong, Yeongtong-Gu, Suwon, Gyeonggi-Do 443-742, Korea {suhyun47.kim, sjh.yoo, mhlee}@samsung.com WWW home page: https://opensource.samsung.com Abstract Due to the continuous expansion of the FOSS ecosystem and the introduction of high-quality FOSS, FOSS is increasingly used in consumer electronics (CE) such as smartphones, televisions, and cameras. -

Op E N So U R C E Yea R B O O K 2 0
OPEN SOURCE YEARBOOK 2016 ..... ........ .... ... .. .... .. .. ... .. OPENSOURCE.COM Opensource.com publishes stories about creating, adopting, and sharing open source solutions. Visit Opensource.com to learn more about how the open source way is improving technologies, education, business, government, health, law, entertainment, humanitarian efforts, and more. Submit a story idea: https://opensource.com/story Email us: [email protected] Chat with us in Freenode IRC: #opensource.com . OPEN SOURCE YEARBOOK 2016 . OPENSOURCE.COM 3 ...... ........ .. .. .. ... .... AUTOGRAPHS . ... .. .... .. .. ... .. ........ ...... ........ .. .. .. ... .... AUTOGRAPHS . ... .. .... .. .. ... .. ........ OPENSOURCE.COM...... ........ .. .. .. ... .... ........ WRITE FOR US ..... .. .. .. ... .... 7 big reasons to contribute to Opensource.com: Career benefits: “I probably would not have gotten my most recent job if it had not been for my articles on 1 Opensource.com.” Raise awareness: “The platform and publicity that is available through Opensource.com is extremely 2 valuable.” Grow your network: “I met a lot of interesting people after that, boosted my blog stats immediately, and 3 even got some business offers!” Contribute back to open source communities: “Writing for Opensource.com has allowed me to give 4 back to a community of users and developers from whom I have truly benefited for many years.” Receive free, professional editing services: “The team helps me, through feedback, on improving my 5 writing skills.” We’re loveable: “I love the Opensource.com team. I have known some of them for years and they are 6 good people.” 7 Writing for us is easy: “I couldn't have been more pleased with my writing experience.” Email us to learn more or to share your feedback about writing for us: https://opensource.com/story Visit our Participate page to more about joining in the Opensource.com community: https://opensource.com/participate Find our editorial team, moderators, authors, and readers on Freenode IRC at #opensource.com: https://opensource.com/irc . -

Netkernel: Making Network Stack Part of the Virtualized Infrastructure
NetKernel: Making Network Stack Part of the Virtualized Infrastructure Zhixiong Niu Hong Xu Peng Cheng Microsoft Research City University of Hong Kong Microsoft Research Qiang Su Yongqiang Xiong Tao Wang Dongsu Han City University of Hong Kong Microsoft Research New York University KAIST Keith Winstein Stanford University Abstract We argue that the current division of labor between appli- This paper presents a system called NetKernel that decou- cation and network infrastructure is becoming increasingly ples the network stack from the guest virtual machine and inadequate, especially in a private cloud setting. The central offers it as an independent module. NetKernel represents a issue is that the network stack is controlled solely by indi- new paradigm where network stack can be managed as part of vidual guest VM; the operator has almost zero visibility or the virtualized infrastructure. It provides important efficiency control. This leads to efficiency problems that manifest in vari- benefits: By gaining control and visibility of the network stack, ous aspects of running the cloud network. Firstly, the operator operator can perform network management more directly and is unable to orchestrate resource allocation at the end-points flexibly, such as multiplexing VMs running different applica- of the network fabric, resulting in low resource utilization. It tions to the same network stack module to save CPU. Users remains difficult today for the operator to meet or define per- also benefit from the simplified stack deployment and better formance SLAs despite much prior work [17,28,35,41,56,57], performance. For example mTCP can be deployed without as she cannot precisely provision resources just for the net- API change to support nginx natively, and shared memory work stack or control how the stack consumes these resources. -
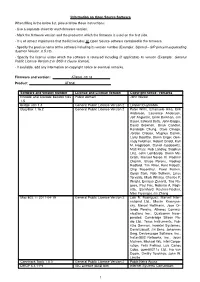
Information on Open Source Software When Filling in The
Information on Open Source Software When filling in the below list, please follow these instructions: - Use a separate sheet for each firmware version. - Mark the firmware version and the product in which the firmware is used on the first side. - It is of utmost importance that the list includes all Open Source software contained in the firmware. - Specify the precise name of the software including its version number (Example: Siproxd – SIP proxy/masquerading daemon Version: 0.5.10). - Specify the license under which the software is released including (if applicable) its version (Example: General Public License Version 2 or BSD-3 clause license). - If available, add any information on copyright notice or eventual remarks. Firmware and version: AT904L-03.18 Product: AT904L Software and version number License and License Version Copyright notice / remarks Encode and Decode base64 files Public domain John Walker 1.5 bridge-utils 1.4 General Public License Version 2 Lennert Buytenhek BusyBox 1.16.2 General Public License Version 2 Peter Willis, Emanuele Aina, Erik Andersen, Laurence Anderson, Jeff Angielski, Enrik Berkhan, Jim Bauer, Edward Betts, John Beppu, David Brownell, Brian Candler, Randolph Chung, Dave Cinege, Jordan Crouse, Magnus Damm, Larry Doolittle, Glenn Engel, Gen- nady Feldman, Robert Griebl, Karl M. Hegbloom, Daniel Jacobowitz, Matt Kraai, Rob Landley, Stephan Linz, John Lombardo, Glenn Mc- Grath, Manuel Novoa III, Vladimir Oleynik, Bruce Perens, Rodney Radford, Tim Riker, Kent Robotti, Chip Rosenthal, Pavel Roskin, Gyepi Sam, Rob Sullivan, Linus Torvalds, Mark Whitley, Charles P. Wright, Enrique Zanardi, Tito Ra- gusa, Paul Fox, Roberto A. Fogli- etta, Bernhard Reutner-Fischer, Mike Frysinger, Jie Zhang Mac 802.11 2011-04-19 General Public License Version 2 Luis R. -

Licensing Information User Manual Oracle® ILOM
Licensing Information User Manual ® Oracle ILOM Firmware Release 3.2.x October 2018 Part No: E62005-12 October 2018 Licensing Information User Manual Oracle ILOM Firmware Release 3.2.x Part No: E62005-12 Copyright © 2016, 2018, Oracle and/or its affiliates. License Restrictions Warranty/Consequential Damages Disclaimer This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. Warranty Disclaimer The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. Restricted Rights Notice If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs (including any operating system, integrated software, any programs embedded, installed or activated on delivered hardware, and modifications of such programs) and Oracle computer documentation or other Oracle data delivered to or accessed by U.S. Government -

Ready; T=0.01/0.01 21:14:10 Ipl 160 Clear Zipl V1.8.0-44.45.2 Interactive Boot Menu
Ready; T=0.01/0.01 21:14:10 ipl 160 clear zIPL v1.8.0-44.45.2 interactive boot menu 0. default (ipl) 1. ipl Note: VM users please use '#cp vi vmsg <number> <kernel-parameters>' Please choose (default will boot in 10 seconds): Booting default (ipl)... Initializing cgroup subsys cpuset Initializing cgroup subsys cpu Linux version 2.6.32.36-0.5-default (geeko@buildhost) (gcc version 4.3.4 [gcc-4_3- branch revision 152973] (SUSE Linux) ) #1 SMP 2011 -04-14 10:12:31 +0200 setup.1a06a7: Linux is running as a z/VM guest operating system in 64-bit mode Zone PFN ranges: DMA 0x00000000 -> 0x00080000 Normal 0x00080000 -> 0x00080000 Movable zone start PFN for each node early_node_map[1] active PFN ranges 0: 0x00000000 -> 0x00020000 PERCPU: Embedded 11 pages/cpu @0000000000e92000 s12544 r8192 d24320 u65536 pcpu-alloc: s12544 r8192 d24320 u65536 alloc=16*4096 pcpu-alloc: [0] 00 [0] 01 [0] 02 [0] 03 [0] 04 [0] 05 [0] 06 [0] 07 pcpu-alloc: [0] 08 [0] 09 [0] 10 [0] 11 [0] 12 [0] 13 [0] 14 [0] 15 pcpu-alloc: [0] 16 [0] 17 [0] 18 [0] 19 [0] 20 [0] 21 [0] 22 [0] 23 pcpu-alloc: [0] 24 [0] 25 [0] 26 [0] 27 [0] 28 [0] 29 [0] 30 [0] 31 pcpu-alloc: [0] 32 [0] 33 [0] 34 [0] 35 [0] 36 [0] 37 [0] 38 [0] 39 pcpu-alloc: [0] 40 [0] 41 [0] 42 [0] 43 [0] 44 [0] 45 [0] 46 [0] 47 pcpu-alloc: [0] 48 [0] 49 [0] 50 [0] 51 [0] 52 [0] 53 [0] 54 [0] 55 pcpu-alloc: [0] 56 [0] 57 [0] 58 [0] 59 [0] 60 [0] 61 [0] 62 [0] 63 Built 1 zonelists in Zone order, mobility grouping on. -

Nftables Och Iptables En Jämförelse Av Latens Nftables and Iptables a Comparison in Latency
NFtables and IPtables Jonas Svensson Eidsheim NFtables och IPtables En jämförelse av latens NFtables and IPtables A Comparison in Latency Bachelors Degree Project in Computer Science Network and Systems Administration, G2E, 22.5 hp IT604G Jonas Svensson Eidsheim [email protected] Examiner Jonas Gamalielsson Supervisor Johan Zaxmy Abstract Firewalls are one of the essential tools to secure any network. IPtables has been the de facto firewall in all Linux systems, and the developers behind IPtables are also responsible for its intended replacement, NFtables. Both IPtables and NFtables are firewalls developed to filter packets. Some services are heavily dependent on low latency transport of packets, such as VoIP, cloud gaming, storage area networks and stock trading. This work is aiming to compare the latency between the selected firewalls while under generated network load. The network traffic is generated by iPerf and the latency is measured by using ping. The measurement of the latency is done on ping packets between two dedicated hosts, one on either side of the firewall. The measurement was done on two configurations one with regular forwarding and another with PAT (Port Address Translation). Both configurations are measured while under network load and while not under network load. Each test is repeated ten times to increase the statistical power behind the conclusion. The results gathered in the experiment resulted in NFtables being the firewall with overall lower latency both while under network load and not under network load. Abstrakt Brandväggen är ett av de viktigaste verktygen för att säkra upp nätverk. IPtables har varit den främst använda brandväggen i alla Linux-system och utvecklarna bakom IPtables är också ansvariga för den avsedda ersättaren, NFtables.