Conceptual Architecture of Mozilla Firefox 6
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Differential Fuzzing the Webassembly
Master’s Programme in Security and Cloud Computing Differential Fuzzing the WebAssembly Master’s Thesis Gilang Mentari Hamidy MASTER’S THESIS Aalto University - EURECOM MASTER’STHESIS 2020 Differential Fuzzing the WebAssembly Fuzzing Différentiel le WebAssembly Gilang Mentari Hamidy This thesis is a public document and does not contain any confidential information. Cette thèse est un document public et ne contient aucun information confidentielle. Thesis submitted in partial fulfillment of the requirements for the degree of Master of Science in Technology. Antibes, 27 July 2020 Supervisor: Prof. Davide Balzarotti, EURECOM Co-Supervisor: Prof. Jan-Erik Ekberg, Aalto University Copyright © 2020 Gilang Mentari Hamidy Aalto University - School of Science EURECOM Master’s Programme in Security and Cloud Computing Abstract Author Gilang Mentari Hamidy Title Differential Fuzzing the WebAssembly School School of Science Degree programme Master of Science Major Security and Cloud Computing (SECCLO) Code SCI3084 Supervisor Prof. Davide Balzarotti, EURECOM Prof. Jan-Erik Ekberg, Aalto University Level Master’s thesis Date 27 July 2020 Pages 133 Language English Abstract WebAssembly, colloquially known as Wasm, is a specification for an intermediate representation that is suitable for the web environment, particularly in the client-side. It provides a machine abstraction and hardware-agnostic instruction sets, where a high-level programming language can target the compilation to the Wasm instead of specific hardware architecture. The JavaScript engine implements the Wasm specification and recompiles the Wasm instruction to the target machine instruction where the program is executed. Technically, Wasm is similar to a popular virtual machine bytecode, such as Java Virtual Machine (JVM) or Microsoft Intermediate Language (MSIL). -

IN-BROWSER BLITZ LITERATURE REVIEWS 1 Submitted to Meta
IN-BROWSER BLITZ LITERATURE REVIEWS 1 Submitted to Meta-Psychology. Participate in open peer review by commenting through hypothes.is directly on this preprint. The full editorial process of all articles under review at Meta-Psychology can be found following this link: https://tinyurl.com/mp-submissions You will find this preprint by searching for the first author's name. Writing a Psychological Blitz Literature Review with Nothing but a Browser Bogdan Cocoş1 1Department of Psychology, University of Bucharest Author Note Correspondence regarding this article should be addressed to Bogdan Cocoş, 90 Panduri Road, Sector 5, 050663, Bucharest, Romania. E-mail: [email protected] https://orcid.org/0000-0003-4098-7551 IN-BROWSER BLITZ LITERATURE REVIEWS 2 Abstract The ways so far of writing literature reviews represent valid, but not sufficient, landmarks, connected to the current technological context. In this sense, this article proposes a research method called blitz literature review, as a way to quickly, transparently, and repeatably consult key references in a particular area of interest, seen as a network composed of elements that are indispensable to such a process. The tutorial consists of six steps explained in detail, easy to follow and reproduce, accompanied by publicly available supplementary material. Finally, the possible implications of this research method are discussed, being brought to the fore a general recommendation regarding the optimization of the citizens’ involvement in the efforts and approaches of open scientific research. Keywords: blitz literature review, open access, open science, research methods IN-BROWSER BLITZ LITERATURE REVIEWS 3 Writing a Psychological Blitz Literature Review with Nothing but a Browser Context The term “blitz literature review” refers to an adaptation of the concept of literature review. -

Servoy Stuff Browser Suite FAQ
Servoy Stuff Browser Suite FAQ Servoy Stuff Browser Suite FAQ Please read carefully: the following contains important information about the use of the Browser Suite in its current version. What is it? It is a suite of native bean components and plugins all Servoy-Aware and tightly integrated with the Servoy platform: - a browser bean - a flash player bean - a html editor bean - a client plugin to rule them all - a server plugin to setup a few admin flags - an installer to help deployment What version of Servoy is supported? - Servoy 5+ Servoy 4.1.8+ will be supported, starting with version 0.9.40+, except for Mac OS X developer (client will work though) What OS/platforms are currently supported? In Developer: - Windows all platform - Mac OS X 10.5+ - Linux GTK based In Smart client: - Windows all platform - Mac OS X 10.5+ - Linux GTK based The web client is not currently supported, although a limited support might come in the future if there is enough demand for it… What Java versions are currently supported? - Windows: java 5 or java 6 (except updates 10 to 14) – 32 and 64-bit - Mac OS X: java 5 or java 6 – 32 and 64-bit - Linux: java 6 (except updates 10 to 14) – 32 and 64-bit Where can I get it? http://www.servoyforge.net/projects/browsersuite What is it made of? It is build on the powerful DJ-NativeSwing project ( http://djproject.sourceforge.net/ns ) v0.9.9 This library is using the Eclipse SWT project ( http://www.eclipse.org/swt ) v3.6.1 And various other projects like the JNA project ( https://jna.dev.java.net/ ) v3.2.4 The XULRunner -

Rich Media Web Application Development I Week 1 Developing Rich Media Apps Today’S Topics
IGME-330 Rich Media Web Application Development I Week 1 Developing Rich Media Apps Today’s topics • Tools we’ll use – what’s the IDE we’ll be using? (hint: none) • This class is about “Rich Media” – we’ll need a “Rich client” – what’s that? • Rich media Plug-ins v. Native browser support for rich media • Who’s in charge of the HTML5 browser API? (hint: no one!) • Where did HTML5 come from? • What are the capabilities of an HTML5 browser? • Browser layout engines • JavaScript Engines Tools we’ll use • Browsers: • Google Chrome - assignments will be graded on Chrome • Safari • Firefox • Text Editor of your choice – no IDE necessary • Adobe Brackets (available in the labs) • Notepad++ on Windows (available in the labs) • BBEdit or TextWrangler on Mac • Others: Atom, Sublime • Documentation: • https://developer.mozilla.org/en-US/docs/Web/API/Document_Object_Model • https://developer.mozilla.org/en-US/docs/Web/API/Canvas_API/Tutorial • https://developer.mozilla.org/en-US/docs/Web/JavaScript/Guide What is a “Rich Client” • A traditional “web 1.0” application needs to refresh the entire page if there is even the smallest change to it. • A “rich client” application can update just part of the page without having to reload the entire page. This makes it act like a desktop application - see Gmail, Flickr, Facebook, ... Rich Client programming in a web browser • Two choices: • Use a plug-in like Flash, Silverlight, Java, or ActiveX • Use the built-in JavaScript functionality of modern web browsers to access the native DOM (Document Object Model) of HTML5 compliant web browsers. -

Browsers and Their Use in Smart Devices
TALLINN UNIVERSITY OF TECHNOLOGY School of Information Technologies Alina Kogai 179247IACB Browsers and their use in smart devices Bachelor’s thesis Supervisor: Vladimir Viies Associate Professor Tallinn 2020 TALLINNA TEHNIKAÜLIKOOL Infotehnoloogia teaduskond Alina Kogai 179247IACB Brauserid ja nende kasutamine nutiseadmetes Bakalaureusetöö Juhendaja: Vladimir Viies Dotsent Tallinn 2020 Author’s declaration of originality I hereby certify that I am the sole author of this thesis. All the used materials, references to the literature and the work of others have been referred to. This thesis has not been presented for examination anywhere else. Author: Alina Kogai 30.11.2020 3 BAKALAUREUSETÖÖ ÜLESANDEPÜSTITUS Kuupäev: 23.09.2020 Üliõpilase ees- ja perekonnanimi: Alina Kogai Üliõpilaskood: 179247IACB Lõputöö teema: Brauserid ja nende kasutamine nutiseadmetes Juhendaja: Vladimir Viies Kaasjuhendaja: Lahendatavad küsimused ning lähtetingimused: Populaarsemate brauserite analüüs. Analüüs arvestada: mälu kasutus, kiirus turvalisus ja privaatsus, brauserite lisad. Valja toodate brauseri valiku kriteeriumid ja soovitused. Lõpetaja allkiri (digitaalselt allkirjastatud) 4 Abstract The aim of this bachelor's thesis is to give recommendations on which web browser is best suited for different user groups on different platforms. The thesis presents a methodology for evaluating browsers which are available on all platforms based on certain criteria. Tests on PC, mobile and tablet were performed for methodology demonstration. To evaluate the importance of the criteria a survey was conducted. The results are used to make recommendations to Internet user groups on the selection of the most suitable browser for different platforms. This thesis is written in English and is 43 pages long, including 5 chapters, 20 figures and 18 tables. 5 Annotatsioon Brauserid ja nende kasutamine nutiseadmetes Selle bakalaureuse töö eesmärk on anda nõuandeid selle kohta, milline veebibrauser erinevatel platvormitel sobib erinevate kasutajagruppide jaoks kõige parem. -
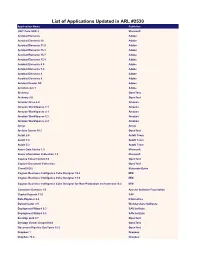
List of Applications Updated in ARL #2530
List of Applications Updated in ARL #2530 Application Name Publisher .NET Core SDK 2 Microsoft Acrobat Elements Adobe Acrobat Elements 10 Adobe Acrobat Elements 11.0 Adobe Acrobat Elements 15.1 Adobe Acrobat Elements 15.7 Adobe Acrobat Elements 15.9 Adobe Acrobat Elements 6.0 Adobe Acrobat Elements 7.0 Adobe Application Name Acrobat Elements 8 Adobe Acrobat Elements 9 Adobe Acrobat Reader DC Adobe Acrobat.com 1 Adobe Alchemy OpenText Alchemy 9.0 OpenText Amazon Drive 4.0 Amazon Amazon WorkSpaces 1.1 Amazon Amazon WorkSpaces 2.1 Amazon Amazon WorkSpaces 2.2 Amazon Amazon WorkSpaces 2.3 Amazon Ansys Ansys Archive Server 10.1 OpenText AutoIt 2.6 AutoIt Team AutoIt 3.0 AutoIt Team AutoIt 3.2 AutoIt Team Azure Data Studio 1.9 Microsoft Azure Information Protection 1.0 Microsoft Captiva Cloud Toolkit 3.0 OpenText Capture Document Extraction OpenText CloneDVD 2 Elaborate Bytes Cognos Business Intelligence Cube Designer 10.2 IBM Cognos Business Intelligence Cube Designer 11.0 IBM Cognos Business Intelligence Cube Designer for Non-Production environment 10.2 IBM Commons Daemon 1.0 Apache Software Foundation Crystal Reports 11.0 SAP Data Explorer 8.6 Informatica DemoCreator 3.5 Wondershare Software Deployment Wizard 9.3 SAS Institute Deployment Wizard 9.4 SAS Institute Desktop Link 9.7 OpenText Desktop Viewer Unspecified OpenText Document Pipeline DocTools 10.5 OpenText Dropbox 1 Dropbox Dropbox 73.4 Dropbox Dropbox 74.4 Dropbox Dropbox 75.4 Dropbox Dropbox 76.4 Dropbox Dropbox 77.4 Dropbox Dropbox 78.4 Dropbox Dropbox 79.4 Dropbox Dropbox 81.4 -

Flash Player and Linux
Flash Player and Linux Ed Costello Engineering Manager Adobe Flash Player Tinic Uro Sr. Software Engineer Adobe Flash Player 2007 Adobe Systems Incorporated. All Rights Reserved. Overview . History and Evolution of Flash Player . Flash Player 9 and Linux . On the Horizon 2 2007 Adobe Systems Incorporated. All Rights Reserved. Flash on the Web: Yesterday 3 2006 Adobe Systems Incorporated. All Rights Reserved. Flash on the Web: Today 4 2006 Adobe Systems Incorporated. All Rights Reserved. A Brief History of Flash Player Flash Flash Flash Flash Linux Player 5 Player 6 Player 7 Player 9 Feb 2001 Dec 2002 May 2004 Jan 2007 Win/ Flash Flash Flash Flash Flash Flash Flash Mac Player 3 Player 4 Player 5 Player 6 Player 7 Player 8 Player 9 Sep 1998 Jun 1999 Aug 2000 Mar 2002 Sep 2003 Aug 2005 Jun 2006 … Vector Animation Interactivity “RIAs” Developers Expressive Performance & Video & Standards Simple Actions, ActionScript Components, ActionScript Filters, ActionScript 3.0, Movie Clips, 1.0 Video (H.263) 2.0 Blend Modes, New virtual Motion Tween, (ECMAScript High-!delity machine MP3 ed. 3), text, Streaming Video (ON2) video 5 2007 Adobe Systems Incorporated. All Rights Reserved. Widest Reach . Ubiquitous, cross-platform, rich media and rich internet application runtime . Installed on 98% of internet- connected desktops1 . Consistently reaches 80% penetration within 12 months of release2 . Flash Player 9 reached 80%+ penetration in <9 months . YUM-savvy updater to support rapid/consistent Linux penetration 1. Source: Millward-Brown September 2006. Mature Market data. 2. Source: NPD plug-in penetration study 6 2007 Adobe Systems Incorporated. All Rights Reserved. -
![Browser Versions Carry 10.5 Bits of Identifying Information on Average [Forthcoming Blog Post]](https://docslib.b-cdn.net/cover/0737/browser-versions-carry-10-5-bits-of-identifying-information-on-average-forthcoming-blog-post-190737.webp)
Browser Versions Carry 10.5 Bits of Identifying Information on Average [Forthcoming Blog Post]
Browser versions carry 10.5 bits of identifying information on average [forthcoming blog post] Technical Analysis by Peter Eckersley This is part 3 of a series of posts on user tracking on the modern web. You can also read part 1 and part 2. Whenever you visit a web page, your browser sends a "User Agent" header to the website saying what precise operating system and browser you are using. We recently ran an experiment to see to what extent this information could be used to track people (for instance, if someone deletes their browser cookies, would the User Agent, alone or in combination with some other detail, be enough to re-create their old cookie?). Our experiment to date has shown that the browser User Agent string usually carries 5-15 bits of identifying information (about 10.5 bits on average). That means that on average, only one person in about 1,500 (210.5) will have the same User Agent as you. On its own, that isn't enough to recreate cookies and track people perfectly, but in combination with another detail like an IP address, geolocation to a particular ZIP code, or having an uncommon browser plugin installed, the User Agent string becomes a real privacy problem. User Agents: An Example of Browser Characteristics Doubling As Tracking Tools When we analyse the privacy of web users, we usually focus on user accounts, cookies, and IP addresses, because those are the usual means by which a request to a web server can be associated with other requests and/or linked back to an individual human being, computer, or local network. -

A Testing Strategy for Html5 Parsers
A TESTING STRATEGY FOR HTML5 PARSERS A DISSERTATION SUBMITTED TO THE UNIVERSITY OF MANCHESTER FOR THE DEGREE OF MASTER OF SCIENCE IN THE FACULTY OF ENGINEERING AND PHYSICAL SCIENCES 2015 By Jose´ Armando Zamudio Barrera School of Computer Science Contents Abstract 9 Declaration 10 Copyright 11 Acknowledgements 12 Dedication 13 Glossary 14 1 Introduction 15 1.1 Aim . 16 1.2 Objectives . 16 1.3 Scope . 17 1.4 Team organization . 17 1.5 Dissertation outline . 17 1.6 Terminology . 18 2 Background and theory 19 2.1 Introduction to HTML5 . 19 2.1.1 HTML Historical background . 19 2.1.2 HTML versus the draconian error handling . 20 2.2 HTML5 Parsing Algorithm . 21 2.3 Testing methods . 23 2.3.1 Functional testing . 23 2.3.2 Oracle testing . 25 2.4 Summary . 26 2 3 HTML5 parser implementation 27 3.1 Design . 27 3.1.1 Overview . 27 3.1.2 State design pattern . 29 3.1.3 Tokenizer . 31 3.1.4 Tree constructor . 32 3.1.5 Error handling . 34 3.2 Building . 34 3.3 Testing . 35 3.3.1 Tokenizer . 35 3.3.2 Tree builder . 36 3.4 Summary . 37 4 Test Framework 38 4.1 Design . 38 4.1.1 Architecture . 38 4.1.2 Adapters . 39 4.1.3 Comparator and plurality agreement . 41 4.2 Building . 42 4.2.1 Parser adapters implementations . 43 4.2.2 Preparing the input . 43 4.2.3 Comparator . 44 4.3 Other framework features . 45 4.3.1 Web Interface . 45 4.3.2 Tracer . -

CA Network Flow Analysis Release Notes
CA Network Flow Analysis Release Notes Release 9.1.3 This Documentation, which includes embedded help systems and electronically distributed materials, (hereinafter referred to as the “Documentation”) is for your informational purposes only and is subject to change or withdrawal by CA at any time. This Documentation may not be copied, transferred, reproduced, disclosed, modified or duplicated, in whole or in part, without the prior written consent of CA. This Documentation is confidential and proprietary information of CA and may not be disclosed by you or used for any purpose other than as may be permitted in (i) a separate agreement between you and CA governing your use of the CA software to which the Documentation relates; or (ii) a separate confidentiality agreement between you and CA. Notwithstanding the foregoing, if you are a licensed user of the software product(s) addressed in the Documentation, you may print or otherwise make available a reasonable number of copies of the Documentation for internal use by you and your employees in connection with that software, provided that all CA copyright notices and legends are affixed to each reproduced copy. The right to print or otherwise make available copies of the Documentation is limited to the period during which the applicable license for such software remains in full force and effect. Should the license terminate for any reason, it is your responsibility to certify in writing to CA that all copies and partial copies of the Documentation have been returned to CA or destroyed. TO THE EXTENT PERMITTED BY APPLICABLE LAW, CA PROVIDES THIS DOCUMENTATION “AS IS” WITHOUT WARRANTY OF ANY KIND, INCLUDING WITHOUT LIMITATION, ANY IMPLIED WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE, OR NONINFRINGEMENT. -
Open Source Software Notice
Open Source Software Notice This document describes open source software contained in LG Smart TV SDK. Introduction This chapter describes open source software contained in LG Smart TV SDK. Terms and Conditions of the Applicable Open Source Licenses Please be informed that the open source software is subject to the terms and conditions of the applicable open source licenses, which are described in this chapter. | 1 Contents Introduction............................................................................................................................................................................................. 4 Open Source Software Contained in LG Smart TV SDK ........................................................... 4 Revision History ........................................................................................................................ 5 Terms and Conditions of the Applicable Open Source Licenses..................................................................................... 6 GNU Lesser General Public License ......................................................................................... 6 GNU Lesser General Public License ....................................................................................... 11 Mozilla Public License 1.1 (MPL 1.1) ....................................................................................... 13 Common Public License Version v 1.0 .................................................................................... 18 Eclipse Public License Version -

Security Analysis of Firefox Webextensions
6.857: Computer and Network Security Due: May 16, 2018 Security Analysis of Firefox WebExtensions Srilaya Bhavaraju, Tara Smith, Benny Zhang srilayab, tsmith12, felicity Abstract With the deprecation of Legacy addons, Mozilla recently introduced the WebExtensions API for the development of Firefox browser extensions. WebExtensions was designed for cross-browser compatibility and in response to several issues in the legacy addon model. We performed a security analysis of the new WebExtensions model. The goal of this paper is to analyze how well WebExtensions responds to threats in the previous legacy model as well as identify any potential vulnerabilities in the new model. 1 Introduction Firefox release 57, otherwise known as Firefox Quantum, brings a large overhaul to the open-source web browser. Major changes with this release include the deprecation of its initial XUL/XPCOM/XBL extensions API to shift to its own WebExtensions API. This WebExtensions API is currently in use by both Google Chrome and Opera, but Firefox distinguishes itself with further restrictions and additional functionalities. Mozilla’s goals with the new extension API is to support cross-browser extension development, as well as offer greater security than the XPCOM API. Our goal in this paper is to analyze how well the WebExtensions model responds to the vulnerabilities present in legacy addons and discuss any potential vulnerabilities in the new model. We present the old security model of Firefox extensions and examine the new model by looking at the structure, permissions model, and extension review process. We then identify various threats and attacks that may occur or have occurred before moving onto recommendations.