Optimizing Knn for Mapping Vegetation Cover of Arid and Semi-Arid Areas Using Landsat Images
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Download the Major Players in the Potato Industry in China Report
Potential Opportunities for Potato Industry’s Development in China Based on Selected Companies Final Report March 2018 Submitted to: World Potato Congress, Inc. (WPC) Submitted by: CIP-China Center for Asia Pacific (CCCAP) Potential Opportunities for Potato Industry’s Development in China Based on Selected Companies Final Report March 2018 Huaiyu Wang School of Management and Economics, Beijing Institute of Technology 5 South Zhongguancun, Haidian District Beijing 100081, P.R. China [email protected] Junhong Qin Post-doctoral fellow Institute of Vegetables and Flowers Chinese Academy of Agricultural Sciences 12 Zhongguancun South Street Beijing 100081, P.R. China Ying Liu School of Management and Economics, Beijing Institute of Technology 5 South Zhongguancun, Haidian District Beijing 100081, P.R. China Xi Hu School of Management and Economics, Beijing Institute of Technology 5 South Zhongguancun, Haidian District Beijing 100081, P.R. China Alberto Maurer (*) Chief Scientist CIP-China Center for Asia Pacific (CCCAP) Room 709, Pan Pacific Plaza, A12 Zhongguancun South Street Beijing, P.R. China [email protected] (*) Corresponding author TABLE OF CONTENTS Executive Summary ................................................................................................................................... ii Introduction ................................................................................................................................................ 1 1. The Development of Potato Production in China ....................................................................... -

Yi Cui, Jing You, Jiujie Ma, Renmin University of China, [email protected]
The Use and Usefulness of Irrigation Property Reform for Sustainable Agriculture Yi Cui, Jing You, Jiujie Ma, Renmin University of China, [email protected] Selected Poster prepared for presentation at the 2019 Agricultural & Applied Economics Association Annual Meeting, Atlanta, GA, July 21-23 Copyright 2019 by [Yi Cui, Jing You, Jiujie Ma]. All rights reserved. Readers may make verbatim copies of this document for non-commercial purposes by any means, provided that this copyright notice appears on all such copies. The Use and Usefulness of Irrigation Property Reform for Sustainable Agriculture The curfew tolls the knell of parting day, The lowing herd wind slowly o’er the lea The ploughman homeward plods his weary way, And leaves the world to darkness and to me. -- by Thomas Gray Abstract: By utilising a recent reform on irrigation property rights in rural China and a unique plot-crop-level panel dataset with 1,106 plots out of 413 households over the period 2013-2017, we assess the causal impact of irrigation property reform on rural households’ adoption of different irrigation technologies and investigate the underlying mechanisms. The Chinese government piloted a reform of water rights in 2014. Prior to it, irrigation water used for agricultural production was free. After clearly defining and allocating the water rights for each well (either dug, driven or drilled ones) in the village, rural households began to pay water fees in agricultural production in 2015. To address heterogeneous treatment effects conditional on the initial structures of the irrigation property (including the privately-owned, jointly owned between the farmer(s) and the village committee, or collectively owned by the village committee), we apply a difference-in- difference-in-difference (DDD) strategy to the plot panel data, where we compare the evolution of outcomes in villages that have had the reform in villages that have not yet implemented the reform. -

Probing the Spatial Cluster of Meriones Unguiculatus Using the Nest Flea Index Based on GIS Technology
Accepted Manuscript Title: Probing the spatial cluster of Meriones unguiculatus using the nest flea index based on GIS Technology Author: Dafang Zhuang Haiwen Du Yong Wang Xiaosan Jiang Xianming Shi Dong Yan PII: S0001-706X(16)30182-6 DOI: http://dx.doi.org/doi:10.1016/j.actatropica.2016.08.007 Reference: ACTROP 4009 To appear in: Acta Tropica Received date: 14-4-2016 Revised date: 3-8-2016 Accepted date: 6-8-2016 Please cite this article as: Zhuang, Dafang, Du, Haiwen, Wang, Yong, Jiang, Xiaosan, Shi, Xianming, Yan, Dong, Probing the spatial cluster of Meriones unguiculatus using the nest flea index based on GIS Technology.Acta Tropica http://dx.doi.org/10.1016/j.actatropica.2016.08.007 This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain. Probing the spatial cluster of Meriones unguiculatus using the nest flea index based on GIS Technology Dafang Zhuang1, Haiwen Du2, Yong Wang1*, Xiaosan Jiang2, Xianming Shi3, Dong Yan3 1 State Key Laboratory of Resources and Environmental Information Systems, Institute of Geographical Sciences and Natural Resources Research, Chinese Academy of Sciences, Beijing, China. 2 College of Resources and Environmental Science, Nanjing Agricultural University, Nanjing, China. -

Exploring the Dynamic Spatio-Temporal Correlations Between PM2.5 Emissions from Different Sources and Urban Expansion in Beijing-Tianjin-Hebei Region
Article Exploring the Dynamic Spatio-Temporal Correlations between PM2.5 Emissions from Different Sources and Urban Expansion in Beijing-Tianjin-Hebei Region Shen Zhao 1,2 and Yong Xu 1,2,* 1 Institute of Geographic Sciences and Natural Resources Research, Chinese Academy of Sciences, Beijing 100101, China; [email protected] 2 College of Resources and Environment, University of Chinese Academy of Sciences, Beijing 100049, China * Correspondence: [email protected] Abstract: Due to rapid urbanization globally more people live in urban areas and, simultaneously, more people are exposed to the threat of environmental pollution. Taking PM2.5 emission data as the intermediate link to explore the correlation between corresponding sectors behind various PM2.5 emission sources and urban expansion in the process of urbanization, and formulating effective policies, have become major issues. In this paper, based on long temporal coverage and high- quality nighttime light data seen from the top of the atmosphere and recently compiled PM2.5 emissions data from different sources (transportation, residential and commercial, industry, energy production, deforestation and wildfire, and agriculture), we built an advanced Bayesian spatio- temporal autoregressive model and a local regression model to quantitatively analyze the correlation between PM2.5 emissions from different sources and urban expansion in the Beijing-Tianjin-Hebei region. Our results suggest that the overall urban expansion in the study area maintained gradual growth from 1995 to 2014, with the fastest growth rate during 2005 to 2010; the urban expansion maintained a significant positive correlation with PM2.5 emissions from transportation, energy Citation: Zhao, S.; Xu, Y. -

Comparison of Wind Erosion Based on Measurements and SWEEP
Soil & Tillage Research 165 (2017) 169–180 Contents lists available at ScienceDirect Soil & Tillage Research journa l homepage: www.elsevier.com/locate/still Comparison of wind erosion based on measurements and SWEEP simulation: A case study in Kangbao County, Hebei Province, China a b, c d a Zhang Jia-Qiong , Zhang Chun-Lai *, Chang Chun-Ping , Wang Ren-De , Liu Gang a State Key Laboratory of Soil Erosion and Dryland Farming on Loess Plateau, Institute of Soil and Water Conservation, Northwest A&F University, Yangling, Shaanxi 712100, China b State Key Laboratory of Earth Surface Processes and Resource Ecology, Beijing Normal University, Beijing 100875, China c College of Resource and Environment Sciences/Hebei Key Laboratory of Environmental Change and Ecological Construction, Hebei Normal University, Shijiazhuang 050024, China d Institute of Geographical Sciences, Hebei Science College, Shijiazhuang, Hebei 050000, China A R T I C L E I N F O A B S T R A C T Article history: Received 3 January 2016 Farmland especially dry farmland managed in traditional ways has high wind erosion risk and Received in revised form 8 August 2016 contributes mainly to dust emission in arid area. Modeling predicting provides a general view to soil Accepted 9 August 2016 erosion susceptibility, and is very helpful for the understanding of potential spatial source of wind Available online xxx erosion. This study applied the Single-event Wind Erosion Evaluation Program (SWEEP) to predict soil wind erosion of farmland in the study area. SWEEP is a standalone version of the erosion sub-model from Keywords: the Wind Erosion Prediction System (WEPS). -

中国(家きんの加熱処理肉等) 2016/9/21 更新 No. NAME ADDRESS 1100/03015 BEIJING DAFA CHIA TAI CO.,LTD YANGZHEN D
中国(家きんの加熱処理肉等) 2016/9/21 更新 No. NAME ADDRESS YANGZHEN DUZHUANG, SHUNYI DISTRICT, 1100/03015 BEIJING DAFA CHIA TAI CO.,LTD BEIJING CITY, CHINA BEIJING DAFA CHIA TAI CO.,LTD. FURTHER YANGZHEN DUZHUANG, SHUNYI DISTRICT, 1100/03025 PROCESSING PLANT BEIJING CITY, CHINA XIAOTANGSHAN TOWN, CHANGPING DISTRICT, 1100/03039 BEIJING JIAYI FOOD JOINT FACTORY BEIJING BEIJING ER SHANG MOQI ZHONGHONG NO.233, NANGAO VILLAGE CUIGEZHUANG 1100/15006 FOODS CO.,LTD. TOWNSHIP CHAOYANG DISTRICT BEIJING, CHINA TIANJIN DONGTIAN FOODS PROCESSING NO.8 XINWANG ROAD, SHUANGQIAOHE TOWN, 1200/03009 CO.,LTD. JINNAN DISTRICT, TIANJIN, CHINA TIANJIN TEDA TIANQUAN QUICK FROZEN 1200/29002 NO.11, JINGU ROAD, TANGGU DISTRICT, TIANJIN FOODSTUFFS CO.,LTD. TIANJIN GREATWALL QUICK FROZEN FOOD 1200/29009 LIUDAOKOU, WUQING COUNTY, TIANJIN CO.,LTD. 1200/29012 TIANJIN SHIYOU FOODSTUFFS CO.,LTD. SICUNDIAN, WUQING COUNTY, TIANJIN NO.319 SHENGLINAN STREET, SHIJIAZHUANG 1300/03036 SHIJIAZHUANG DEYUAN FOOD CO., LTD. CITY, HEBEI NO.171, MUSLIM BUSINESS TRADE STREET, 1300/03105 HUSI FOOD COMPANY LTD. XIADIAN TOWN, DACHANG HUI AUTONOMY COUNTY, HEBEI PROVINCE, CHINA QINHUANGDAO CHIA TAI CO.,LTD. FOOD NO.30, GUANCHENGDONG ROAD,SHANHAIGUAN 1300/03133 PLANT (THE SECOND COOKED FOOD DISTRICT, QINHUANGDAO, HEBEI PLANT) KANGBAO BAILU MEAT CO., LTD. THE NO.134,GONGYE STREET, KANGBAO COUNTY, 1300/03152 SECOND FACTORY HEBEI LUANPING HUADU JIAYI FOOD JOINT NO.9 HEBIN ROAD, LUANPING TOWN, LUANPING 1300/03158 FACTORY COUNTY, CHENGDE CITY, HEBEI PROVINCE AIRPLANE SOUTH ROAD, ZHENGDING, 1300/08040 SHIJIAZHUANG HUIKANG FOOD CO.,LTD. SHIJIAZHUANG, HEBEI HEBEI FOODSTUFFS I/E (GROUP) 1300/29002 HENGSHUI TIANYANG COLD STORAGE NO.8, JINGDA ROAD, HENGSHUI, HEBEI PLANT SHIJIAZHUANG ECONOMICS & TECHNICAL 1300/29020 DEVELOPMENT ZONE GREATWALL NO.1, YANGZI ROAD, SHIJIAZHUANG ETDZ, HEBEI FOODSTUFFS CO., LTD. -

Minimum Wage Standards in China August 11, 2020
Minimum Wage Standards in China August 11, 2020 Contents Heilongjiang ................................................................................................................................................. 3 Jilin ............................................................................................................................................................... 3 Liaoning ........................................................................................................................................................ 4 Inner Mongolia Autonomous Region ........................................................................................................... 7 Beijing......................................................................................................................................................... 10 Hebei ........................................................................................................................................................... 11 Henan .......................................................................................................................................................... 13 Shandong .................................................................................................................................................... 14 Shanxi ......................................................................................................................................................... 16 Shaanxi ...................................................................................................................................................... -

China Unicom Corporate Social Responsibility Report 2015
)NOTG;TOIUS )UXVUXGZK9UIOGR8KYVUTYOHOROZ_ 8KVUXZ /SVRKSKTZOTM4K]/JKGYZU)USVUYK'4K])NGVZKX 'JJ 4U,OTGTIOGR9ZXKKZ>OINKTM*OYZXOIZ(KOPOTM NZZV ]]]INOTG[TOIUSIUS Contents Coordinated Development and Report Description 02 Cooperative Operation 39 Common Development in China and Abroad 40 Message from the Chairman 03 Boost Regional Coordination 43 Bridge Digital Divide 44 )NOTG;TOIUS)UXVUXGZK9UIOGR8KYVUTYOHOROZ_8KVUXZ Purify Network Environment 45 )NOTG;TOIUS)UXVUXGZK9UIOGR8KYVUTYOHOROZ_8KVUXZ Corporate Profile 04 Corporate Governance 04 Shareholding Structure 06 Development in a Green and Development Strategy 06 Environment-Friendly Manner 46 Organizational Structure 07 Promote Green Operations 47 Brand System 08 Strengthen Energy-Saving Management 48 Electromagnetic Radiation Management 50 Co-Construction of Infrastructure 50 Corporate Social Responsibility (CSR) Management 09 CSR Development Goal 10 Open Development and Win-Win CSR Organizational Structure 10 Cooperation 51 CSR Topics 11 Strategic Investment Cooperation 52 Communication on CSR 12 Develop With the Industry 54 Business Operation in Line with Laws and Regulations 13 Share Development, Boost Equality Party Organization Construction 14 and Harmony 56 Risk Control 15 Support Employees’ Development 57 Corporate governance in alignment with Help regional development 64 laws and regulations 15 Assist community development 67 Fighting Corruption and Upholding Integrity 15 Audit and Supervision 16 Workplace Safety 16 Looking Forward in 2016 71 Innovative Development for A Better- quality -

中国(偶蹄類の加熱処理肉等) 2021/5/25通知 No. NAME
中国(偶蹄類の加熱処理肉等) 2021/5/25通知 No. NAME ADDRESS TEMPORARY HUANG GANG NO.670, SHUN HUANG ROAD, SUN HE 1100/03009 BEIJING HORMEL FOODS CO.,LTD. COUNTY, CHAOYANG DISTRICT, BEIJING, CHINA 1100/03015 BEIJING DAFA CHIA TAI CO.,LTD YANGZHEN DUZHUANG, SHUNYI DISTRICT, BEIJING CITY, CHINA 1100/03039 BEIJING JIAYI FOOD JOINT FACTORY XIAOTANGSHAN TOWN, CHANGPING DISTRICT, BEIJING BEIJING ER SHANG MOQI ZHONGHONG FOODS NO. 233 NANGAO VILLAGE CUIGEZHUANG TOWNSHIP CHAOYANG 1100/15006 CO.,LTD. DISTRICT BEIJING, CHINA 1200/01025 TIANJIN LINGCHUAN FOOD CO.,LTD XINKOU INDUSTRIAL ZONE BY ROAD NO.18, XIQING DISTRICT, TIANJIN TIANJIN 3RD FOOD PRODUCTS PROCESSING 1200/03001 HANJIASHU, BEICHEN DISTRICT, TIANJIN FACTORY 1200/03008 TIANJIN MEAT PRODUCTS PROCESSING COMPLEX NO.8, YUEJIN ROAD, DONGLI DISTRICT, TIANJIN NO.8 XINWANG ROAD, SHUANGQIAOHE TOWN, JINNAN DISTRICT, 1200/03009 TIANJIN DONGTIAN FOODS PROCESSING CO., LTD TIANJIN, CHINA TIANJIN TEDA TIANQUAN QUICK FROZEN 1200/29002 NO.11, JINGU ROAD, TANGGU DISTRICT, TIANJIN FOODSTUFFS CO.,LTD. 1200/29005 TIANJIN GUOSHI FOOD CO., LTD. LANGYUAN VILLAGE, BEICHEN DISTRICT, TIANJIN 1200/29012 TIANJIN SHIYOU FOODSTUFFS CO.,LTD. SICUNDIAN, WUQING COUNTY, TIANJIN 1200/29016 TIANJIN NICKY FOODSTUFFS CO., LTD. 13 STREET, EXPORT PROCESSING ZONE, TIANJIN NO.171, MUSLIM BUSINESS TRADE STREET, XIADIAN TOWN, DACHANG 1300/03105 HEBEI SUPERB FOODS CO., LTD HUI AUTONOMY COUNTY, HEBEI PROVINCE, CHINA KANGBAO BAILU MEAT CO., LTD. THE SECOND 1300/03152 NO.134, GONGYE STREET, KANGBAO COUNTY, HEBEI FACTORY NO.9 HEBIN ROAD, LUANPINGTOWN, LUANPING COUNTY, CHENGDE 1300/03158 LUANPING HUADU JIAYI FOOD JOINT FACTORY CITY, HEBEI PROVINCE SHIJIAZHUANG DEYUAN FOOD CO.,LTD. 1300/03160 NO.77, XINYUANXI ROAD, LUANCHENG DISTRICT, SHIJIAZHUANG, HEBEI LUANCHENG BRANCH 1300/08040 SHIJIAZHUANG HUIKANG FOOD CO.,LTD. -
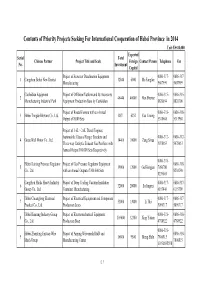
Contents of Priority Projects Seeking for International Cooperation Of
Contents of Priority Projects Seeking For International Cooperation of Hebei Province in 2014 Unit:US$10,000 Expected Serial Total Chinese Partner Project Title and Scale Foreign Contact Person Telephone Fax No. Investment Capital Project of Seawater Desalination Equipment 0086-317- 0086-317- 1 Cangzhou Bohai New District 12840 6000 Ma Fangfan Manufacturing 5607999 5607999 Caofeidian Equipment Project of Offshore Platform and Its Accessory 0086-315- 0086-315- 2 46440 40000 Han Shuxue Manufacturing Industrial Park Equipment Production Base by Caofeidian 8820034 8820706 Project of Roots Blowers with an Annual 0086-318- 0086-318- 3 Hebei Tongde Blowers Co., Ltd. 8871 6252 Cao Liming Output of 8,000 Sets 5318668 5313968 Project of 1.6L~2.4L Diesel Engines, Automobile Chassis Hanger Brackets and 0086-312- 0086-312- 4 Great Wall Motor Co., Ltd. 14466 10000 Zang Sixue Three-way Catalytic Exhaust Gas Purifiers with 5078653 5078653 Annual Output 100,000 Sets Respectively 0086-318- Hebei Ruixing Pressure Regulator Project of Gas Pressure Regulator Equipment 0086-318- 5 19000 12000 Gu Hongjun 7056780 Co., Ltd. with an Annual Output of 300,000 Sets 8230290 8239001 Cangzhou Huida Heavy Industry Project of Deep Cooling Vacuum Insulation 0086-317- 0086-317- 6 32000 20000 Su Jingrui Group Co., Ltd. Container Manufacturing 6193444 6193309 Hebei Chuanglong Electrical Project of Electrical Equipment and Component 0086-317- 0086-317- 7 53000 13000 Li Hui Product Co., Ltd. Production Lines 5096317 5096317 Hebei Kunteng Industry Group Project of Electromechanical Equipment 0086-318- 0086-318- 8 109600 32380 Xing Yukun Co., Ltd. Production Base 4788922 4788922 0086-318- Hebei Zhenxing Jinyuan Wire Project of Anping Wire-mesh R&D and 0086-318- 9 16800 9500 Meng Shilu 7800815 Mesh Group Manufacturing Center 7800815 13931835598 (1) Contents of Priority Projects Seeking For International Cooperation of Hebei Province in 2014 Unit:US$10,000 Expected Serial Total Chinese Partner Project Title and Scale Foreign Contact Person Telephone Fax No. -
Zhangjiakou Energy Transformation Strategy 2050
Supported by: Supported by: CHINA NATIONAL RENEWABLE ENERGY CENTRE based on a decision of the German Bundestag based on a decision of the German Bundestag ZHANGJIAKOU ENERGY TRANSFORMATION STRATEGY 2050 ZHANGJIAKOU Energy Transformation Strategy 2050 ZHANGJIAKOU Pathway to a low-carbon future Energy Transformation Strategy 2050 PATHWAY TO A LOW-CARBON TO FUTURE PATHWAY www.irena.org 2019 © IRENA 2019 © IRENA 2019 Unless otherwise stated, material in this publication may be freely used, shared, copied, reproduced, printed and/or stored, provided that appropriate acknowledgement is given to IRENA as the source and copyright holder. Material in this publication that is attributed to third parties may be subject to separate terms of use and restrictions, and appropriate permissions from these third parties may need to be secured before any use of such material. ISBN 978-92-9260-157-7 Citation: Available for download: www.irena.org/publications For further information or to provide feedback: [email protected] DISCLAIMER About IRENA The International Renewable Energy Agency (IRENA) is an intergovernmental organisation that supports countries in their transition to a sustainable energy future, and serves as the principal platform for international co-operation, a centre of excellence, and a repository of policy, technology, resource and financial knowledge on renewable energy. IRENA promotes the widespread adoption and sustainable use of all forms of renewable energy, including bioenergy, geothermal, hydropower, ocean, solar and wind energy, in the pursuit of sustainable development, energy access, energy security and low-carbon economic growth and prosperity. www.irena.org About CNREC China National Renewable Energy Centre (CNREC) is the national institution for assisting China’s energy authorities in renewable energy policy research, and industrial management and co-ordination. -

Minimum Wage Standards in China June 28, 2018
Minimum Wage Standards in China June 28, 2018 Contents Heilongjiang .................................................................................................................................................. 3 Jilin ................................................................................................................................................................ 3 Liaoning ........................................................................................................................................................ 4 Inner Mongolia Autonomous Region ........................................................................................................... 7 Beijing ......................................................................................................................................................... 10 Hebei ........................................................................................................................................................... 11 Henan .......................................................................................................................................................... 13 Shandong .................................................................................................................................................... 14 Shanxi ......................................................................................................................................................... 16 Shaanxi .......................................................................................................................................................