SIFTSIFT -- Thethe Scalescale Invariantinvariant Featurefeature Transformtransform
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Edge Detection of an Image Based on Extended Difference of Gaussian
American Journal of Computer Science and Technology 2019; 2(3): 35-47 http://www.sciencepublishinggroup.com/j/ajcst doi: 10.11648/j.ajcst.20190203.11 ISSN: 2640-0111 (Print); ISSN: 2640-012X (Online) Edge Detection of an Image Based on Extended Difference of Gaussian Hameda Abd El-Fattah El-Sennary1, *, Mohamed Eid Hussien1, Abd El-Mgeid Amin Ali2 1Faculty of Science, Aswan University, Aswan, Egypt 2Faculty of Computers and Information, Minia University, Minia, Egypt Email address: *Corresponding author To cite this article: Hameda Abd El-Fattah El-Sennary, Abd El-Mgeid Amin Ali, Mohamed Eid Hussien. Edge Detection of an Image Based on Extended Difference of Gaussian. American Journal of Computer Science and Technology. Vol. 2, No. 3, 2019, pp. 35-47. doi: 10.11648/j.ajcst.20190203.11 Received: November 24, 2019; Accepted: December 9, 2019; Published: December 20, 2019 Abstract: Edge detection includes a variety of mathematical methods that aim at identifying points in a digital image at which the image brightness changes sharply or, more formally, has discontinuities. The points at which image brightness changes sharply are typically organized into a set of curved line segments termed edges. The same problem of finding discontinuities in one-dimensional signals is known as step detection and the problem of finding signal discontinuities over time is known as change detection. Edge detection is a fundamental tool in image processing, machine vision and computer vision, particularly in the areas of feature detection and feature extraction. It's also the most important parts of image processing, especially in determining the image quality. -

Scale Space Multiresolution Analysis of Random Signals
Scale Space Multiresolution Analysis of Random Signals Lasse Holmstr¨om∗, Leena Pasanen Department of Mathematical Sciences, University of Oulu, Finland Reinhard Furrer Institute of Mathematics, University of Zurich,¨ Switzerland Stephan R. Sain National Center for Atmospheric Research, Boulder, Colorado, USA Abstract A method to capture the scale-dependent features in a random signal is pro- posed with the main focus on images and spatial fields defined on a regular grid. A technique based on scale space smoothing is used. However, where the usual scale space analysis approach is to suppress detail by increasing smoothing progressively, the proposed method instead considers differences of smooths at neighboring scales. A random signal can then be represented as a sum of such differences, a kind of a multiresolution analysis, each difference representing de- tails relevant at a particular scale or resolution. Bayesian analysis is used to infer which details are credible and which are just artifacts of random variation. The applicability of the method is demonstrated using noisy digital images as well as global temperature change fields produced by numerical climate prediction models. Keywords: Scale space smoothing, Bayesian methods, Image analysis, Climate research 1. Introduction In signal processing, smoothing is often used to suppress noise. An optimal level of smoothing is then of interest. In scale space analysis of noisy curves and images, instead of a single, in some sense “optimal” level of smoothing, a whole family of smooths is considered and each smooth is thought to provide information about the underlying object at a particular scale or resolution. The ∗Corresponding author ∗∗P.O.Box 3000, 90014 University of Oulu, Finland Tel. -

Hough Transform, Descriptors Tammy Riklin Raviv Electrical and Computer Engineering Ben-Gurion University of the Negev Hough Transform
DIGITAL IMAGE PROCESSING Lecture 7 Hough transform, descriptors Tammy Riklin Raviv Electrical and Computer Engineering Ben-Gurion University of the Negev Hough transform y m x b y m 3 5 3 3 2 2 3 7 11 10 4 3 2 3 1 4 5 2 2 1 0 1 3 3 x b Slide from S. Savarese Hough transform Issues: • Parameter space [m,b] is unbounded. • Vertical lines have infinite gradient. Use a polar representation for the parameter space Hough space r y r q x q x cosq + ysinq = r Slide from S. Savarese Hough Transform Each point votes for a complete family of potential lines: Each pencil of lines sweeps out a sinusoid in Their intersection provides the desired line equation. Hough transform - experiments r q Image features ρ,ϴ model parameter histogram Slide from S. Savarese Hough transform - experiments Noisy data Image features ρ,ϴ model parameter histogram Need to adjust grid size or smooth Slide from S. Savarese Hough transform - experiments Image features ρ,ϴ model parameter histogram Issue: spurious peaks due to uniform noise Slide from S. Savarese Hough Transform Algorithm 1. Image à Canny 2. Canny à Hough votes 3. Hough votes à Edges Find peaks and post-process Hough transform example http://ostatic.com/files/images/ss_hough.jpg Incorporating image gradients • Recall: when we detect an edge point, we also know its gradient direction • But this means that the line is uniquely determined! • Modified Hough transform: for each edge point (x,y) θ = gradient orientation at (x,y) ρ = x cos θ + y sin θ H(θ, ρ) = H(θ, ρ) + 1 end Finding lines using Hough transform -

Scale Invariant Feature Transform (SIFT) Why Do We Care About Matching Features?
Scale Invariant Feature Transform (SIFT) Why do we care about matching features? • Camera calibration • Stereo • Tracking/SFM • Image moiaicing • Object/activity Recognition • … Objection representation and recognition • Image content is transformed into local feature coordinates that are invariant to translation, rotation, scale, and other imaging parameters • Automatic Mosaicing • http://www.cs.ubc.ca/~mbrown/autostitch/autostitch.html We want invariance!!! • To illumination • To scale • To rotation • To affine • To perspective projection Types of invariance • Illumination Types of invariance • Illumination • Scale Types of invariance • Illumination • Scale • Rotation Types of invariance • Illumination • Scale • Rotation • Affine (view point change) Types of invariance • Illumination • Scale • Rotation • Affine • Full Perspective How to achieve illumination invariance • The easy way (normalized) • Difference based metrics (random tree, Haar, and sift, gradient) How to achieve scale invariance • Pyramids • Scale Space (DOG method) Pyramids – Divide width and height by 2 – Take average of 4 pixels for each pixel (or Gaussian blur with different ) – Repeat until image is tiny – Run filter over each size image and hope its robust How to achieve scale invariance • Scale Space: Difference of Gaussian (DOG) – Take DOG features from differences of these images‐producing the gradient image at different scales. – If the feature is repeatedly present in between Difference of Gaussians, it is Scale Invariant and should be kept. Differences Of Gaussians -

Image Denoising Using Non Linear Diffusion Tensors
2011 8th International Multi-Conference on Systems, Signals & Devices IMAGE DENOISING USING NON LINEAR DIFFUSION TENSORS Benzarti Faouzi, Hamid Amiri Signal, Image Processing and Pattern Recognition: TSIRF (ENIT) Email: [email protected] , [email protected] ABSTRACT linear models. Many approaches have been proposed to remove the noise effectively while preserving the original Image denoising is an important pre-processing step for image details and features as much as possible. In the past many image analysis and computer vision system. It few years, the use of non linear PDEs methods involving refers to the task of recovering a good estimate of the true anisotropic diffusion has significantly grown and image from a degraded observation without altering and becomes an important tool in contemporary image changing useful structure in the image such as processing. The key idea behind the anisotropic diffusion discontinuities and edges. In this paper, we propose a new is to incorporate an adaptative smoothness constraint in approach for image denoising based on the combination the denoising process. That is, the smooth is encouraged of two non linear diffusion tensors. One allows diffusion in a homogeneous region and discourage across along the orientation of greatest coherences, while the boundaries, in order to preserve the natural edge of the other allows diffusion along orthogonal directions. The image. One of the most successful tools for image idea is to track perfectly the local geometry of the denoising is the Total Variation (TV) model [9] [8][10] degraded image and applying anisotropic diffusion and the anisotropic smoothing model [1] which has since mainly along the preferred structure direction. -

Exploiting Information Theory for Filtering the Kadir Scale-Saliency Detector
Introduction Method Experiments Conclusions Exploiting Information Theory for Filtering the Kadir Scale-Saliency Detector P. Suau and F. Escolano {pablo,sco}@dccia.ua.es Robot Vision Group University of Alicante, Spain June 7th, 2007 P. Suau and F. Escolano Bayesian filter for the Kadir scale-saliency detector 1 / 21 IBPRIA 2007 Introduction Method Experiments Conclusions Outline 1 Introduction 2 Method Entropy analysis through scale space Bayesian filtering Chernoff Information and threshold estimation Bayesian scale-saliency filtering algorithm Bayesian scale-saliency filtering algorithm 3 Experiments Visual Geometry Group database 4 Conclusions P. Suau and F. Escolano Bayesian filter for the Kadir scale-saliency detector 2 / 21 IBPRIA 2007 Introduction Method Experiments Conclusions Outline 1 Introduction 2 Method Entropy analysis through scale space Bayesian filtering Chernoff Information and threshold estimation Bayesian scale-saliency filtering algorithm Bayesian scale-saliency filtering algorithm 3 Experiments Visual Geometry Group database 4 Conclusions P. Suau and F. Escolano Bayesian filter for the Kadir scale-saliency detector 3 / 21 IBPRIA 2007 Introduction Method Experiments Conclusions Local feature detectors Feature extraction is a basic step in many computer vision tasks Kadir and Brady scale-saliency Salient features over a narrow range of scales Computational bottleneck (all pixels, all scales) Applied to robot global localization → we need real time feature extraction P. Suau and F. Escolano Bayesian filter for the Kadir scale-saliency detector 4 / 21 IBPRIA 2007 Introduction Method Experiments Conclusions Salient features X HD(s, x) = − Pd,s,x log2Pd,s,x d∈D Kadir and Brady algorithm (2001): most salient features between scales smin and smax P. -

3D Object Modeling and Recognition Using Local Affine-Invariant Image Descriptors and Multi-View Spatial Constraints
3D Object Modeling and Recognition Using Local Affine-Invariant Image Descriptors and Multi-View Spatial Constraints Fred Rothganger ([email protected]) Svetlana Lazebnik ([email protected]) Department of Computer Science and Beckman Institute University of Illinois at Urbana-Champaign, Urbana, IL 61801, USA Cordelia Schmid ([email protected]) INRIA Rhone-Alpesˆ 665, Avenue de l’Europe, 38330 Montbonnot, France Jean Ponce ([email protected]) Department of Computer Science and Beckman Institute University of Illinois at Urbana-Champaign, Urbana, IL 61801, USA Abstract. This article introduces a novel representation for three-dimensional (3D) objects in terms of local affine-invariant descriptors of their images and the spatial relationships between the corresponding surface patches. Geometric constraints associated with different views of the same patches under affine projection are combined with a normalized representation of their appearance to guide matching and reconstruction, allowing the acquisition of true 3D affine and Euclidean models from multiple unregistered images, as well as their recognition in photographs taken from arbitrary viewpoints. The proposed approach does not require a separate segmentation stage, and it is applicable to highly cluttered scenes. Modeling and recognition results are presented. Keywords: Three-dimensional object recognition, image-based modeling, affine-invariant image descriptors, multi- view geometry. 1. Introduction This article addresses the problem of recognizing three-dimensional (3D) objects -

Scale-Space Theory for Multiscale Geometric Image Analysis
Tutorial Scale-Space Theory for Multiscale Geometric Image Analysis Bart M. ter Haar Romeny, PhD Utrecht University, the Netherlands [email protected] Introduction Multiscale image analysis has gained firm ground in computer vision, image processing and models of biological vision. The approaches however have been characterised by a wide variety of techniques, many of them chosen ad hoc. Scale-space theory, as a relatively new field, has been established as a well founded, general and promising multiresolution technique for image structure analysis, both for 2D, 3D and time series. The rather mathematical nature of many of the classical papers in this field has prevented wide acceptance so far. This tutorial will try to bridge that gap by giving a comprehensible and intuitive introduction to this field. We also try, as a mutual inspiration, to relate the computer vision modeling to biological vision modeling. The mathematical rigor is much relaxed for the purpose of giving the broad picture. In appendix A a number of references are given as a good starting point for further reading. The multiscale nature of things In mathematics objects have no scale. We are familiar with the notion of points, that really shrink to zero, lines with zero width. In mathematics are no metrical units involved, as in physics. Neighborhoods, like necessary in the definition of differential operators, are defined as taken into the limit to zero, so we can really speak of local operators. In physics objects live on a range of scales. We need an instrument to do an observation (our eye, a camera) and it is the range that this instrument can see that we call the scale range. -

An Overview of Wavelet Transform Concepts and Applications
An overview of wavelet transform concepts and applications Christopher Liner, University of Houston February 26, 2010 Abstract The continuous wavelet transform utilizing a complex Morlet analyzing wavelet has a close connection to the Fourier transform and is a powerful analysis tool for decomposing broadband wavefield data. A wide range of seismic wavelet applications have been reported over the last three decades, and the free Seismic Unix processing system now contains a code (succwt) based on the work reported here. Introduction The continuous wavelet transform (CWT) is one method of investigating the time-frequency details of data whose spectral content varies with time (non-stationary time series). Moti- vation for the CWT can be found in Goupillaud et al. [12], along with a discussion of its relationship to the Fourier and Gabor transforms. As a brief overview, we note that French geophysicist J. Morlet worked with non- stationary time series in the late 1970's to find an alternative to the short-time Fourier transform (STFT). The STFT was known to have poor localization in both time and fre- quency, although it was a first step beyond the standard Fourier transform in the analysis of such data. Morlet's original wavelet transform idea was developed in collaboration with the- oretical physicist A. Grossmann, whose contributions included an exact inversion formula. A series of fundamental papers flowed from this collaboration [16, 12, 13], and connections were soon recognized between Morlet's wavelet transform and earlier methods, including harmonic analysis, scale-space representations, and conjugated quadrature filters. For fur- ther details, the interested reader is referred to Daubechies' [7] account of the early history of the wavelet transform. -

A PERFORMANCE EVALUATION of LOCAL DESCRIPTORS 1 a Performance Evaluation of Local Descriptors
MIKOLAJCZYK AND SCHMID: A PERFORMANCE EVALUATION OF LOCAL DESCRIPTORS 1 A performance evaluation of local descriptors Krystian Mikolajczyk and Cordelia Schmid Dept. of Engineering Science INRIA Rhone-Alpesˆ University of Oxford 655, av. de l'Europe Oxford, OX1 3PJ 38330 Montbonnot United Kingdom France [email protected] [email protected] Abstract In this paper we compare the performance of descriptors computed for local interest regions, as for example extracted by the Harris-Affine detector [32]. Many different descriptors have been proposed in the literature. However, it is unclear which descriptors are more appropriate and how their performance depends on the interest region detector. The descriptors should be distinctive and at the same time robust to changes in viewing conditions as well as to errors of the detector. Our evaluation uses as criterion recall with respect to precision and is carried out for different image transformations. We compare shape context [3], steerable filters [12], PCA-SIFT [19], differential invariants [20], spin images [21], SIFT [26], complex filters [37], moment invariants [43], and cross-correlation for different types of interest regions. We also propose an extension of the SIFT descriptor, and show that it outperforms the original method. Furthermore, we observe that the ranking of the descriptors is mostly independent of the interest region detector and that the SIFT based descriptors perform best. Moments and steerable filters show the best performance among the low dimensional descriptors. Index Terms Local descriptors, interest points, interest regions, invariance, matching, recognition. I. INTRODUCTION Local photometric descriptors computed for interest regions have proved to be very successful in applications such as wide baseline matching [37, 42], object recognition [10, 25], texture Corresponding author is K. -

Scale Invariant Feature Transform - Scholarpedia 2015-04-21 15:04
Scale Invariant Feature Transform - Scholarpedia 2015-04-21 15:04 Scale Invariant Feature Transform +11 Recommend this on Google Tony Lindeberg (2012), Scholarpedia, 7(5):10491. doi:10.4249/scholarpedia.10491 revision #149777 [link to/cite this article] Prof. Tony Lindeberg, KTH Royal Institute of Technology, Stockholm, Sweden Scale Invariant Feature Transform (SIFT) is an image descriptor for image-based matching and recognition developed by David Lowe (1999, 2004). This descriptor as well as related image descriptors are used for a large number of purposes in computer vision related to point matching between different views of a 3-D scene and view-based object recognition. The SIFT descriptor is invariant to translations, rotations and scaling transformations in the image domain and robust to moderate perspective transformations and illumination variations. Experimentally, the SIFT descriptor has been proven to be very useful in practice for image matching and object recognition under real-world conditions. In its original formulation, the SIFT descriptor comprised a method for detecting interest points from a grey- level image at which statistics of local gradient directions of image intensities were accumulated to give a summarizing description of the local image structures in a local neighbourhood around each interest point, with the intention that this descriptor should be used for matching corresponding interest points between different images. Later, the SIFT descriptor has also been applied at dense grids (dense SIFT) which have been shown to lead to better performance for tasks such as object categorization, texture classification, image alignment and biometrics . The SIFT descriptor has also been extended from grey-level to colour images and from 2-D spatial images to 2+1-D spatio-temporal video. -
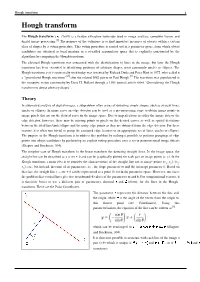
Hough Transform 1 Hough Transform
Hough transform 1 Hough transform The Hough transform ( /ˈhʌf/) is a feature extraction technique used in image analysis, computer vision, and digital image processing.[1] The purpose of the technique is to find imperfect instances of objects within a certain class of shapes by a voting procedure. This voting procedure is carried out in a parameter space, from which object candidates are obtained as local maxima in a so-called accumulator space that is explicitly constructed by the algorithm for computing the Hough transform. The classical Hough transform was concerned with the identification of lines in the image, but later the Hough transform has been extended to identifying positions of arbitrary shapes, most commonly circles or ellipses. The Hough transform as it is universally used today was invented by Richard Duda and Peter Hart in 1972, who called it a "generalized Hough transform"[2] after the related 1962 patent of Paul Hough.[3] The transform was popularized in the computer vision community by Dana H. Ballard through a 1981 journal article titled "Generalizing the Hough transform to detect arbitrary shapes". Theory In automated analysis of digital images, a subproblem often arises of detecting simple shapes, such as straight lines, circles or ellipses. In many cases an edge detector can be used as a pre-processing stage to obtain image points or image pixels that are on the desired curve in the image space. Due to imperfections in either the image data or the edge detector, however, there may be missing points or pixels on the desired curves as well as spatial deviations between the ideal line/circle/ellipse and the noisy edge points as they are obtained from the edge detector.