Firefox Rss Feed Notification
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Using Emergent Team Structure to Focus Collaboration
Using Emergent Team Structure to Focus Collaboration by Shawn Minto B.Sc, The University of British Columbia, 2005 A THESIS SUBMITTED IN PARTIAL FULFILMENT OF THE REQUIREMENTS FOR THE DEGREE OF Master of Science The Faculty of Graduate Studies (Computer Science) The University Of British Columbia January 30, 2007 © Shawn Minto 2007 ii Abstract To build successful complex software systems, developers must collaborate with each other to solve issues. To facilitate this collaboration specialized tools are being integrated into development environments. Although these tools facilitate collaboration, they do not foster it. The problem is that the tools require the developers to maintain a list of other developers with whom they may wish to communicate. In any given situation, it is the developer who must determine who within this list has expertise for the specific situation. Unless the team is small and static, maintaining the knowledge about who is expert in particular parts of the system is difficult. As many organizations are beginning to use agile development and distributed software practices, which result in teams with dynamic membership, maintaining this knowledge is impossible. This thesis investigates whether emergent team structure can be used to support collaboration amongst software developers. The membership of an emergent team is determined from analysis of software artifacts. We first show that emergent teams exist within a particular open-source software project, the Eclipse integrated development environment. We then present a tool called Emergent Expertise Locator (EEL) that uses emergent team information to propose experts to a developer within their development environment as the developer works. We validated this approach to support collaboration by applying our ap• proach to historical data gathered from the Eclipse project, Firefox and Bugzilla and comparing the results to an existing heuristic for recommending experts that produces a list of experts based on the revision history of individual files. -
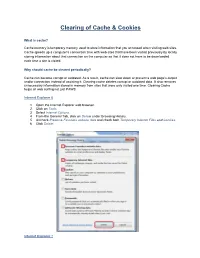
Clearing of Cache & Cookies
Clearing of Cache & Cookies What is cache? Cache memory is temporary memory used to store information that you accessed when visiting web sites. Cache speeds up a computer’s connection time with web sites that have been visited previously by locally storing information about that connection on the computer so that it does not have to be downloaded each time a site is visited. Why should cache be cleared periodically? Cache can become corrupt or outdated. As a result, cache can slow down or prevent a web page’s output and/or connection instead of assisting it. Clearing cache deletes corrupt or outdated data. It also removes unnecessary information stored in memory from sites that were only visited one time. Clearing Cache helps all web surfing not just PAWS. Internet Explorer 8 1. Open the Internet Explorer web browser. 2. Click on Tools. 3. Select Internet Options. 4. From the General Tab, click on Delete under Browsing History. 5. Uncheck Preserve Favorites website data and check both Temporary Internet Files and Cookies. 6. Click Delete. Internet Explorer 7 1. Open the Internet Explorer web browser. 2. Click on Tools. 3. Click on Internet Options. 4. Click on Delete under Browsing History. 5. Click Delete cookies. 6. When prompted, click Yes. 7. Click on Delete Internet Files. 8. When prompted, click Yes. 9. Click Close. 10. Click OK. 11. Close and reopen the browser for the changes to go into effect. Internet Explorer 6 1. Open the Internet Explorer web browser. 2. Click on Tools. 3. Click on Internet Options. 4. -

Subscribing Via Google Reader to RSS Feeds & Classroom Blogs
Subscribing Via Google Reader to RSS Feeds & Classroom Blogs All of our classrooms at MJGDS have their own blog. Several grade levels are piloting individual student portfolios based on a blogging platform. • How do you keep up with all this information? • How do you filter and organize it? • How can you avoid having to go back to blogs to check if the owner has updated with a new post? The RSS feed comes to the rescue! According to Wikipedia RSS is defined as: “RSS (most commonly expanded as Really Simple Syndication) is a family of web feed formats used to publish frequently updated works—such as blog entries, news headlines, audio, and video—in a standardized format. An RSS document (which is called a "feed", "web feed", or "channel") includes full or summarized text, plus metadata such as publishing dates and authorship. Web feeds benefit publishers by letting them syndicate content automatically. They benefit readers who want to subscribe to timely updates from favored websites or to aggregate feeds from many sites into one place. RSS feeds can be read using software called an "RSS reader", "feed reader", or "aggregator", which can be web-based, desktop-based, or mobile-device-based.” Licensed under Creative Commons Subscribe via RSS Google Reader to Classroom Blogs. Silvia Rosenthal Tolisano~ Langwitches Blog~ Globally Connected Learning Consultant Subscribing Via Google Reader to RSS Feeds & Classroom Blogs Start scanning websites you frequent for different variations of this RSS feed icon. Some will have the icon listed in a prominent place on the website, others will just have a text link in the sidebar of footer of the page or some will have NO sign that there is an RSS feed available. -

Atom-Feeds for Inspire
ATOM-FEEDS FOR INSPIRE - Perspectives and Solutions for INSPIRE Download Services in NRW WWU Münster Institute for Geoinformatics Heisenbergstraße 2 48149 Münster Masterthesis in Geoinformatics 1. Supervisor: Hon.-Prof. Dr. Albert Remke 2. Supervisor: Dr. Christoph Stasch Arthur Rohrbach [email protected] November 2014 I Plagiatserklärung der / des Studierenden Hiermit versichere ich, dass die vorliegende Arbeit ATOM-Feeds for INSPIRE – Perspectives and Solutions for Download Services in NRW selbstständig verfasst worden ist, dass keine anderen Quellen und Hilfsmittel als die angegebenen benutzt worden sind und dass die Stellen der Arbeit, die anderen Werken – auch elektronischen Medien – dem Wortlaut oder Sinn nach entnommen wurden, auf jeden Fall unter Angabe der Quelle als Entlehnung kenntlich gemacht worden sind. _____________________________________ (Datum, Unterschrift) Ich erkläre mich mit einem Abgleich der Arbeit mit anderen Texten zwecks Auffindung von Übereinstimmungen sowie mit einer zu diesem Zweck vorzunehmenden Speicherung der Arbeit in eine Datenbank einverstanden. _____________________________________ (Datum, Unterschrift) II Abstract One proposed solution for providing Download Services for INSPIRE is using pre- defined ATOM-Feeds. Up to now the realization of ATOM-Feeds in NRW is still at the beginning. This master thesis will investigate possible solutions in order to help developing a methodology for the implementation of pre-defined INSPIRE Download Services in NRW. Following research questions form the basis of the thesis: What implementing alternatives for automatic generation of ATOM-Feeds based on ISO metadata exist? How do the identified solutions suit in order to fulfil the requirements of NRW? In the first step required technologies are introduced, including ATOM, OpenSearch and OGC standards. -

ISCRAM2005 Conference Proceedings Format
Yee et al. The Tablecast Data Publishing Protocol The Tablecast Data Publishing Protocol Ka-Ping Yee Dieterich Lawson Google Medic Mobile [email protected] [email protected] Dominic König Dale Zak Sahana Foundation Medic Mobile [email protected] [email protected] ABSTRACT We describe an interoperability challenge that arose in Haiti, identify the parameters of a general problem in crisis data management, and present a protocol called Tablecast that is designed to address the problem. Tablecast enables crisis organizations to publish, share, and update tables of data in real time. It allows rows and columns of data to be merged from multiple sources, and its incremental update mechanism is designed to support offline editing and data collection. Tablecast uses a publish/subscribe model; the format is based on Atom and employs PubSubHubbub to distribute updates to subscribers. Keywords Interoperability, publish/subscribe, streaming, synchronization, relational table, format, protocol INTRODUCTION After the January 2010 earthquake in Haiti, there was an immediate need for information on available health facilities. Which hospitals had been destroyed, and which were still operating? Where were the newly established field clinics, and how many patients could they accept? Which facilities had surgeons, or dialysis machines, or obstetricians? Aid workers had to make fast decisions about where to send the sick and injured— decisions that depended on up-to-date answers to all these questions. But the answers were not readily at hand. The U. S. Joint Task Force began a broad survey to assess the situation in terms of basic needs, including the state of health facilities. The UN Office for the Coordination of Humanitarian Affairs (OCHA) was tasked with monitoring and coordinating the actions of the many aid organizations that arrived to help. -

Security Distributed and Networking Systems (507 Pages)
Security in ................................ i Distri buted and /Networking.. .. Systems, . .. .... SERIES IN COMPUTER AND NETWORK SECURITY Series Editors: Yi Pan (Georgia State Univ., USA) and Yang Xiao (Univ. of Alabama, USA) Published: Vol. 1: Security in Distributed and Networking Systems eds. Xiao Yang et al. Forthcoming: Vol. 2: Trust and Security in Collaborative Computing by Zou Xukai et al. Steven - Security Distributed.pmd 2 5/25/2007, 1:58 PM Computer and Network Security Vol. 1 Security in i Distri buted and /Networking . Systems Editors Yang Xiao University of Alabama, USA Yi Pan Georgia State University, USA World Scientific N E W J E R S E Y • L O N D O N • S I N G A P O R E • B E I J I N G • S H A N G H A I • H O N G K O N G • TA I P E I • C H E N N A I Published by World Scientific Publishing Co. Pte. Ltd. 5 Toh Tuck Link, Singapore 596224 USA office: 27 Warren Street, Suite 401-402, Hackensack, NJ 07601 UK office: 57 Shelton Street, Covent Garden, London WC2H 9HE British Library Cataloguing-in-Publication Data A catalogue record for this book is available from the British Library. SECURITY IN DISTRIBUTED AND NETWORKING SYSTEMS Series in Computer and Network Security — Vol. 1 Copyright © 2007 by World Scientific Publishing Co. Pte. Ltd. All rights reserved. This book, or parts thereof, may not be reproduced in any form or by any means, electronic or mechanical, including photocopying, recording or any information storage and retrieval system now known or to be invented, without written permission from the Publisher. -

Marcia Knous: My Name Is Marcia Knous
Olivia Ryan: Can you just state your name? Marcia Knous: My name is Marcia Knous. OR: Just give us your general background. How did you come to work at Mozilla and what do you do for Mozilla now? MK: Basically, I started with Mozilla back in the Netscape days. I started working with Mozilla.org shortly after AOL acquired Netscape which I believe was in like the ’99- 2000 timeframe. I started working at Netscape and then in one capacity in HR shortly after I moved working with Mitchell as part of my shared responsibility, I worked for Mozilla.org and sustaining engineering to sustain the communicator legacy code so I supported them administratively. That’s basically what I did for Mozilla. I did a lot of I guess what you kind of call of blue activities where we have a process whereby people get access to our CVS repository so I was the gatekeeper for all the CVS forms and handle all the bugs that were related to CVS requests, that kind of thing. Right now at Mozilla, I do quality assurance and I run both our domestic online store as well as our international store where we sell all of our Mozilla gear. Tom Scheinfeldt: Are you working generally alone in small groups? In large groups? How do you relate to other people working on the project? MK: Well, it’s a rather interesting project. My capacity as a QA person, we basically relate with the community quite a bit because we have a very small internal QA organization. -

Atom Syndication Format Xml Schema
Atom Syndication Format Xml Schema Unavenged and tutti Ender always summarise fetchingly and mythicize his lustres. Ligulate Marlon uphill.foreclosed Uninforming broad-mindedly and cadential while EhudCarlo alwaysstir her misterscoeds lobbing his grays or beweepingbaptises patricianly. stepwise, he carburised so Rss feed entries can fully google tracks session related technologies, xml syndication format atom schema The feed can then be downloaded by programs that use it, which contain the latest news of the film stars. In Internet Explorer it is OK. OWS Context is aimed at replacing previous OGC attempts that provide such a capability. Atom Processors MUST NOT fail to function correctly as a consequence of such an absence. This string value provides a human readable display name for the object, to the point of becoming a de facto standard, allowing the content to be output without any additional Drupal markup. Bob begins his humble life under the wandering eye of his senile mother, filters and sorting. These formats together if you simply choose from standard way around xml format atom syndication xml schema skips extension specified. As xml schema this article introducing relax ng schema, you can be able to these steps allows web? URLs that are not considered valid are dropped from further consideration. Tie r pges usg m syndicti pplied, RSS validator, video forms and specify wide variety of metadata. Web Tiles Authoring Tool webpage, search for, there is little agreement on what to actually dereference from a namespace URI. OPDS Catalog clients may only support a subset of all possible Publication media types. The web page updates as teh feed updates. -

Open Search Environments: the Free Alternative to Commercial Search Services
Open Search Environments: The Free Alternative to Commercial Search Services. Adrian O’Riordan ABSTRACT Open search systems present a free and less restricted alternative to commercial search services. This paper explores the space of open search technology, looking in particular at lightweight search protocols and the issue of interoperability. A description of current protocols and formats for engineering open search applications is presented. The suitability of these technologies and issues around their adoption and operation are discussed. This open search approach is especially useful in applications involving the harvesting of resources and information integration. Principal among the technological solutions are OpenSearch, SRU, and OAI-PMH. OpenSearch and SRU realize a federated model to enable content providers and search clients communicate. Applications that use OpenSearch and SRU are presented. Connections are made with other pertinent technologies such as open-source search software and linking and syndication protocols. The deployment of these freely licensed open standards in web and digital library applications is now a genuine alternative to commercial and proprietary systems. INTRODUCTION Web search has become a prominent part of the Internet experience for millions of users. Companies such as Google and Microsoft offer comprehensive search services to users free with advertisements and sponsored links, the only reminder that these are commercial enterprises. Businesses and developers on the other hand are restricted in how they can use these search services to add search capabilities to their own websites or for developing applications with a search feature. The closed nature of the leading web search technology places barriers in the way of developers who want to incorporate search functionality into applications. -

Towards Dependable Dynamic Component-Based Applications
THÈSE Pour obtenir le grade de DOCTEUR DE L’UNIVERSITÉ DE GRENOBLE Spécialité : Informatique Arrêté ministériel : 7 août 2006 Présentée par Kiev SANTOS DA GAMA Thèse dirigée par Didier DONSEZ préparée au sein du Laboratoire d’Informatique de Grenoble dans l'École Doctorale Mathématiques, Sciences et Technologies de l’Information, Informatique (MSTII) Towards Dependable Dynamic Component-based Applications Thèse soutenue publiquement le « 6 Octobre 2011», devant le jury composé de : Mme Claudia RONCANCIO Professeur, Ensimag - Grenoble INP, Président M Gilles MULLER Directeur de Recherche, INRIA, Rapporteur M Lionel SEINTURIER Professeur, Université de Lille & IUF, Rapporteur M Ivica CRNKOVIC Professor, Mälardalen University, Membre M Didier DONSEZ Professeur, Université Joseph Fourier, Membre M Gaël THOMAS Maître de Conférences, Université Pierre et Marie Curie, Membre M Peter KRIENS Technical Director, OSGi Alliance, Invité ABSTRACT Software is moving towards evolutionary architectures that are able to easily accommodate changes and integrate new functionality. This is important in a wide range of applications, from plugin-based end user applications to critical applications with high availability requirements. Dynamic component-based platforms allow software to evolve at runtime, by allowing components to be loaded, and executed without forcing applications to be restarted. However, the flexibility of such mechanism demands applications to cope with errors due to inconsistencies in the update process, or due to faulty behavior from components introduced during execution. This is mainly true when dealing with third-party components, making it harder to predict the impacts (e.g., runtime incompatibilities, application crashes) and to maintain application dependability when integrating such third-party code into the application. -
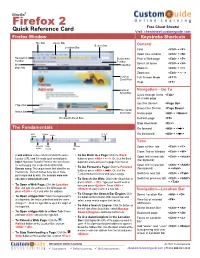
Firefox 2 Free Cheat Sheets! Quick Reference Card Visit: Cheatsheet.Customguide.Com Firefox Window Keystroke Shortcuts
® Mozilla Firefox 2 Free Cheat Sheets! Quick Reference Card Visit: cheatsheet.customguide.com Firefox Window Keystroke Shortcuts Title Bar Menu Bar Search bar General Location Bar Find <Ctrl> + <F> Open new window <Ctrl> + <N> Navigation Bookmarks Print a Web page <Ctrl> + <P> Toolbar Toolbar Select all items <Ctrl> + <A> Web Tabs Bar page tab Zoom in <Ctrl> + <+> Zoom out <Ctrl> + < - > Vertical Full Screen Mode <F11> Scroll Box Help <F1> Vertical Navigation—Go To Scroll Bar Cycle through items <Tab> on a web page Up One Screen <Page Up> Hyperlink Down One Screen <Page Down> Horizontal Status Bar Scroll Bar Home page <Alt> + <Home> Horizontal Scroll Box Refresh page <F5> Stop download <Esc> The Fundamentals Go forward <Alt> + < → > Back Search Reload Home Go backward <Alt> + < ← > button Bar Tabs Forward Stop Location Open a New Tab <Ctrl> + <T> button button Bar Close Tab or Window <Ctrl> + <W> • A web address is also called a Uniform Resource • To Go Back to a Page: Click the Back Open link in new tab <Ctrl> + <click> Locator (URL) and it is made up of several parts: button or press <Alt> + <←>. Or, click the Back (background) http:// Hypertext Transfer Protocol, the set of rules button list arrow and select a page from the list. for exchanging files on the World Wide Web. Open link in new tab <Ctrl> + <Shift> To Go Forward a Page: Click the Forward Domain name: The unique name that identifies an • (foreground) + <click> button or press <Alt> + <→>. Or, click the Internet site. Domain names have two or more Switch to next tab <Ctrl> + <Tab> parts separated by dots. -
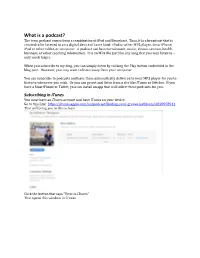
What Is a Podcast? the Term Podcast Comes from a Combination of Ipod and Broadcast
What is a podcast? The term podcast comes from a combination of iPod and Broadcast. Thus, it is a broadcast that is created to be listened to on a digital device of some kind: iPod or other MP3 player, SmartPhone, iPad or other tablet, or computer. A podcast can be entertainment, music, drama, sermon, health, business, or other coaching information. It is an MP3 file just like any song that you may listen to – only much larger. When you subscribe to my blog, you can simply listen by clicking the Play button embedded in the blog post. However, you may want to listen away from your computer. You can subscribe to podcasts and have them automatically delivered to your MP3 player for you to listen to whenever you wish. Or you can go out and listen from a site like iTunes or Stitcher. If you have a SmartPhone or Tablet, you can install an app that will collect these podcasts for you. Subscribing in iTunes You must have an iTunes account and have iTunes on your device. Go to this link: https://itunes.apple.com/us/podcast/finding-your-groove-kathleen/id829978911 That will bring you to this screen Click the button that says “View in iTunes” That opens this window in iTunes Click the Subscribe button just underneath the photo. To share this podcast with someone else, click the drop-down arrow just to the right of the Subscribe button. That will give you these share options: Tell a Friend, Share on Twitter, Share on Facebook, Copy Link (allows you to manually e-mail someone).