28 Matrix Operations
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Recursive Approach in Sparse Matrix LU Factorization
51 Recursive approach in sparse matrix LU factorization Jack Dongarra, Victor Eijkhout and the resulting matrix is often guaranteed to be positive Piotr Łuszczek∗ definite or close to it. However, when the linear sys- University of Tennessee, Department of Computer tem matrix is strongly unsymmetric or indefinite, as Science, Knoxville, TN 37996-3450, USA is the case with matrices originating from systems of Tel.: +865 974 8295; Fax: +865 974 8296 ordinary differential equations or the indefinite matri- ces arising from shift-invert techniques in eigenvalue methods, one has to revert to direct methods which are This paper describes a recursive method for the LU factoriza- the focus of this paper. tion of sparse matrices. The recursive formulation of com- In direct methods, Gaussian elimination with partial mon linear algebra codes has been proven very successful in pivoting is performed to find a solution of Eq. (1). Most dense matrix computations. An extension of the recursive commonly, the factored form of A is given by means technique for sparse matrices is presented. Performance re- L U P Q sults given here show that the recursive approach may per- of matrices , , and such that: form comparable to leading software packages for sparse ma- LU = PAQ, (2) trix factorization in terms of execution time, memory usage, and error estimates of the solution. where: – L is a lower triangular matrix with unitary diago- nal, 1. Introduction – U is an upper triangular matrix with arbitrary di- agonal, Typically, a system of linear equations has the form: – P and Q are row and column permutation matri- Ax = b, (1) ces, respectively (each row and column of these matrices contains single a non-zero entry which is A n n A ∈ n×n x where is by real matrix ( R ), and 1, and the following holds: PPT = QQT = I, b n b, x ∈ n and are -dimensional real vectors ( R ). -

Lecture 5 - Triangular Factorizations & Operation Counts
Lecture 5 - Triangular Factorizations & Operation Counts LU Factorization We have seen that the process of GE essentially factors a matrix A into LU. Now we want to see how this factorization allows us to solve linear systems and why in many cases it is the preferred algorithm compared with GE. Remember on paper, these methods are the same but computationally they can be different. First, suppose we want to solve A~x = ~b and we are given the factorization A = LU. It turns out that the system LU~x = ~b is \easy" to solve because we do a forward solve L~y = ~b and then back solve U~x = ~y. We have seen that we can easily implement the equations for the back solve and for homework you will write out the equations for the forward solve. Example If 0 2 −1 2 1 0 1 0 0 1 0 2 −1 2 1 A = @ 4 1 9 A = LU = @ 2 1 0 A @ 0 3 5 A 8 5 24 4 3 1 0 0 1 solve the linear system A~x = ~b where ~b = (0; −5; −16)T . ~ We first solve L~y = b to get y1 = 0, 2y1 +y2 = −5 implies y2 = −5 and 4y1 +3y2 +y3 = −16 T implies y3 = −1. Now we solve U~x = ~y = (0; −5; −1) . Back solving yields x3 = −1, 3x2 + 5x3 = −5 implies x2 = 0 and finally 2x1 − x2 + 2x3 = 0 implies x1 = 1 giving the solution (1; 0; −1)T . If GE and LU factorization are equivalent on paper, why would one be computationally advantageous in some settings? Recall that when we solve A~x = ~b by GE we must also multiply the right hand side by the Gauss transformation matrices. -

LU Factorization LU Decomposition LU Decomposition: Motivation LU Decomposition
LU Factorization LU Decomposition To further improve the efficiency of solving linear systems Factorizations of matrix A : LU and QR A matrix A can be decomposed into a lower triangular matrix L and upper triangular matrix U so that LU Factorization Methods: Using basic Gaussian Elimination (GE) A = LU ◦ Factorization of Tridiagonal Matrix ◦ LU decomposition is performed once; can be used to solve multiple Using Gaussian Elimination with pivoting ◦ right hand sides. Direct LU Factorization ◦ Similar to Gaussian elimination, care must be taken to avoid roundoff Factorizing Symmetrix Matrices (Cholesky Decomposition) ◦ errors (partial or full pivoting) Applications Special Cases: Banded matrices, Symmetric matrices. Analysis ITCS 4133/5133: Intro. to Numerical Methods 1 LU/QR Factorization ITCS 4133/5133: Intro. to Numerical Methods 2 LU/QR Factorization LU Decomposition: Motivation LU Decomposition Forward pass of Gaussian elimination results in the upper triangular ma- trix 1 u12 u13 u1n 0 1 u ··· u 23 ··· 2n U = 0 0 1 u3n . ···. 0 0 0 1 ··· We can determine a matrix L such that LU = A , and l11 0 0 0 l l 0 ··· 0 21 22 ··· L = l31 l32 l33 0 . ···. . l l l 1 n1 n2 n3 ··· ITCS 4133/5133: Intro. to Numerical Methods 3 LU/QR Factorization ITCS 4133/5133: Intro. to Numerical Methods 4 LU/QR Factorization LU Decomposition via Basic Gaussian Elimination LU Decomposition via Basic Gaussian Elimination: Algorithm ITCS 4133/5133: Intro. to Numerical Methods 5 LU/QR Factorization ITCS 4133/5133: Intro. to Numerical Methods 6 LU/QR Factorization LU Decomposition of Tridiagonal Matrix Banded Matrices Matrices that have non-zero elements close to the main diagonal Example: matrix with a bandwidth of 3 (or half band of 1) a11 a12 0 0 0 a21 a22 a23 0 0 0 a32 a33 a34 0 0 0 a43 a44 a45 0 0 0 a a 54 55 Efficiency: Reduced pivoting needed, as elements below bands are zero. -

LU-Factorization 1 Introduction 2 Upper and Lower Triangular Matrices
MAT067 University of California, Davis Winter 2007 LU-Factorization Isaiah Lankham, Bruno Nachtergaele, Anne Schilling (March 12, 2007) 1 Introduction Given a system of linear equations, a complete reduction of the coefficient matrix to Reduced Row Echelon (RRE) form is far from the most efficient algorithm if one is only interested in finding a solution to the system. However, the Elementary Row Operations (EROs) that constitute such a reduction are themselves at the heart of many frequently used numerical (i.e., computer-calculated) applications of Linear Algebra. In the Sections that follow, we will see how EROs can be used to produce a so-called LU-factorization of a matrix into a product of two significantly simpler matrices. Unlike Diagonalization and the Polar Decomposition for Matrices that we’ve already encountered in this course, these LU Decompositions can be computed reasonably quickly for many matrices. LU-factorizations are also an important tool for solving linear systems of equations. You should note that the factorization of complicated objects into simpler components is an extremely common problem solving technique in mathematics. E.g., we will often factor a polynomial into several polynomials of lower degree, and one can similarly use the prime factorization for an integer in order to simply certain numerical computations. 2 Upper and Lower Triangular Matrices We begin by recalling the terminology for several special forms of matrices. n×n A square matrix A =(aij) ∈ F is called upper triangular if aij = 0 for each pair of integers i, j ∈{1,...,n} such that i>j. In other words, A has the form a11 a12 a13 ··· a1n 0 a22 a23 ··· a2n A = 00a33 ··· a3n . -

Fast Matrix Multiplication
Fast matrix multiplication Yuval Filmus May 3, 2017 1 Problem statement How fast can we multiply two square matrices? To make this problem precise, we need to fix a computational model. The model that we use is the unit cost arithmetic model. In this model, a program is a sequence of instructions, each of which is of one of the following forms: 1. Load input: tn xi, where xi is one of the inputs. 2. Load constant: tn c, where c 2 R. 3. Arithmetic operation: tn ti ◦ tj, where i; j < n, and ◦ 2 f+; −; ·; =g. In all cases, n is the number of the instruction. We will say that an arithmetic program computes the product of two n × n matrices if: 1. Its inputs are xij; yij for 1 ≤ i; j ≤ n. 2. For each 1 ≤ i; k ≤ n there is a variable tm whose value is always equal to n X xijyjk: j=1 3. The program never divides by zero. The cost of multiplying two n × n matrices is the minimum length of an arithmetic program that computes the product of two n × n matrices. Here is an example. The following program computes the product of two 1 × 1 matrices: t1 x11 t2 y11 t3 t1 · t2 The variable t3 contains x11y11, and so satisfies the second requirement above for (i; k) = (1; 1). This shows that the cost of multiplying two 1 × 1 matrices is at most 3. Usually we will not spell out all steps of an arithmetic program, and use simple shortcuts, such as the ones indicated by the following program for multiplying two 2 × 2 matrices: z11 x11y11 + x12y21 z12 x11y12 + x12y22 z21 x21y11 + x22y21 z22 x21y12 + x22y22 1 When spelled out, this program uses 20 instructions: 8 load instructions, 8 product instructions, and 4 addition instructions. -
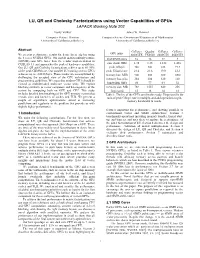
LU, QR and Cholesky Factorizations Using Vector Capabilities of Gpus LAPACK Working Note 202 Vasily Volkov James W
LU, QR and Cholesky Factorizations using Vector Capabilities of GPUs LAPACK Working Note 202 Vasily Volkov James W. Demmel Computer Science Division Computer Science Division and Department of Mathematics University of California at Berkeley University of California at Berkeley Abstract GeForce Quadro GeForce GeForce GPU name We present performance results for dense linear algebra using 8800GTX FX5600 8800GTS 8600GTS the 8-series NVIDIA GPUs. Our matrix-matrix multiply routine # of SIMD cores 16 16 12 4 (GEMM) runs 60% faster than the vendor implementation in CUBLAS 1.1 and approaches the peak of hardware capabilities. core clock, GHz 1.35 1.35 1.188 1.458 Our LU, QR and Cholesky factorizations achieve up to 80–90% peak Gflop/s 346 346 228 93.3 of the peak GEMM rate. Our parallel LU running on two GPUs peak Gflop/s/core 21.6 21.6 19.0 23.3 achieves up to ~300 Gflop/s. These results are accomplished by memory bus, MHz 900 800 800 1000 challenging the accepted view of the GPU architecture and memory bus, pins 384 384 320 128 programming guidelines. We argue that modern GPUs should be viewed as multithreaded multicore vector units. We exploit bandwidth, GB/s 86 77 64 32 blocking similarly to vector computers and heterogeneity of the memory size, MB 768 1535 640 256 system by computing both on GPU and CPU. This study flops:word 16 18 14 12 includes detailed benchmarking of the GPU memory system that Table 1: The list of the GPUs used in this study. Flops:word is the reveals sizes and latencies of caches and TLB. -

Triangular Factorization
Chapter 1 Triangular Factorization This chapter deals with the factorization of arbitrary matrices into products of triangular matrices. Since the solution of a linear n n system can be easily obtained once the matrix is factored into the product× of triangular matrices, we will concentrate on the factorization of square matrices. Specifically, we will show that an arbitrary n n matrix A has the factorization P A = LU where P is an n n permutation matrix,× L is an n n unit lower triangular matrix, and U is an n ×n upper triangular matrix. In connection× with this factorization we will discuss pivoting,× i.e., row interchange, strategies. We will also explore circumstances for which A may be factored in the forms A = LU or A = LLT . Our results for a square system will be given for a matrix with real elements but can easily be generalized for complex matrices. The corresponding results for a general m n matrix will be accumulated in Section 1.4. In the general case an arbitrary m× n matrix A has the factorization P A = LU where P is an m m permutation× matrix, L is an m m unit lower triangular matrix, and U is an×m n matrix having row echelon structure.× × 1.1 Permutation matrices and Gauss transformations We begin by defining permutation matrices and examining the effect of premulti- plying or postmultiplying a given matrix by such matrices. We then define Gauss transformations and show how they can be used to introduce zeros into a vector. Definition 1.1 An m m permutation matrix is a matrix whose columns con- sist of a rearrangement of× the m unit vectors e(j), j = 1,...,m, in RI m, i.e., a rearrangement of the columns (or rows) of the m m identity matrix. -

Efficient Matrix Multiplication on Simd Computers* P
SIAM J. MATRIX ANAL. APPL. () 1992 Society for Industrial and Applied Mathematics Vol. 13, No. 1, pp. 386-401, January 1992 025 EFFICIENT MATRIX MULTIPLICATION ON SIMD COMPUTERS* P. BJORSTADt, F. MANNEr, T. SOI:tEVIK, AND M. VAJTERIC?$ Dedicated to Gene H. Golub on the occasion of his 60th birthday Abstract. Efficient algorithms are described for matrix multiplication on SIMD computers. SIMD implementations of Winograd's algorithm are considered in the case where additions are faster than multiplications. Classical kernels and the use of Strassen's algorithm are also considered. Actual performance figures using the MasPar family of SIMD computers are presented and discussed. Key words, matrix multiplication, Winograd's algorithm, Strassen's algorithm, SIMD com- puter, parallel computing AMS(MOS) subject classifications. 15-04, 65-04, 65F05, 65F30, 65F35, 68-04 1. Introduction. One of the basic computational kernels in many linear algebra codes is the multiplication of two matrices. It has been realized that most problems in computational linear algebra can be expressed in block algorithms and that matrix multiplication is the most important kernel in such a framework. This approach is essential in order to achieve good performance on computer systems having a hier- archical memory organization. Currently, computer technology is strongly directed towards this design, due to the imbalance between the rapid advancement in processor speed relative to the much slower progress towards large, inexpensive, fast memories. This algorithmic development is highlighted by Golub and Van Loan [13], where the formulation of block algorithms is an integrated part of the text. The rapid devel- opment within the field of parallel computing and the increased need for cache and multilevel memory systems are indeed well reflected in the changes from the first to the second edition of this excellent text and reference book. -

Matrix Multiplication: a Study Kristi Stefa Introduction
Matrix Multiplication: A Study Kristi Stefa Introduction Task is to handle matrix multiplication in an efficient way, namely for large sizes Want to measure how parallelism can be used to improve performance while keeping accuracy Also need for improvement on “normal” multiplication algorithm O(n3) for conventional square matrices of n x n size Strassen Algorithm Introduction of a different algorithm, one where work is done on submatrices Requirement of matrix being square and size n = 2k Uses A and B matrices to construct 7 factors to solve C matrix Complexity from 8 multiplications to 7 + additions: O(nlog27) or n2.80 Room for parallelism TBB:parallel_for is the perfect candidate for both the conventional algorithm and the Strassen algorithm Utilization in ranges of 1D and 3D to sweep a vector or a matrix TBB: parallel_reduce would be possible but would increase the complexity of usage Would be used in tandem with a 2D range for the task of multiplication Test Setup and Use Cases The input images were converted to binary by Matlab and the test filter (“B” matrix) was generated in Matlab and on the board Cases were 128x128, 256x256, 512x512, 1024x1024 Matlab filter was designed for element-wise multiplication and board code generated for proper matrix-wise filter Results were verified by Matlab and an import of the .bof file Test setup (contd) Pictured to the right are the results for the small (128x128) case and a printout for the 256x256 case Filter degrades the image horizontally and successful implementation produces -
LU and Cholesky Decompositions. J. Demmel, Chapter 2.7
LU and Cholesky decompositions. J. Demmel, Chapter 2.7 1/14 Gaussian Elimination The Algorithm — Overview Solving Ax = b using Gaussian elimination. 1 Factorize A into A = PLU Permutation Unit lower triangular Non-singular upper triangular 2/14 Gaussian Elimination The Algorithm — Overview Solving Ax = b using Gaussian elimination. 1 Factorize A into A = PLU Permutation Unit lower triangular Non-singular upper triangular 2 Solve PLUx = b (for LUx) : − LUx = P 1b 3/14 Gaussian Elimination The Algorithm — Overview Solving Ax = b using Gaussian elimination. 1 Factorize A into A = PLU Permutation Unit lower triangular Non-singular upper triangular 2 Solve PLUx = b (for LUx) : − LUx = P 1b − 3 Solve LUx = P 1b (for Ux) by forward substitution: − − Ux = L 1(P 1b). 4/14 Gaussian Elimination The Algorithm — Overview Solving Ax = b using Gaussian elimination. 1 Factorize A into A = PLU Permutation Unit lower triangular Non-singular upper triangular 2 Solve PLUx = b (for LUx) : − LUx = P 1b − 3 Solve LUx = P 1b (for Ux) by forward substitution: − − Ux = L 1(P 1b). − − 4 Solve Ux = L 1(P 1b) by backward substitution: − − − x = U 1(L 1P 1b). 5/14 Example of LU factorization We factorize the following 2-by-2 matrix: 4 3 l 0 u u = 11 11 12 . (1) 6 3 l21 l22 0 u22 One way to find the LU decomposition of this simple matrix would be to simply solve the linear equations by inspection. Expanding the matrix multiplication gives l11 · u11 + 0 · 0 = 4, l11 · u12 + 0 · u22 = 3, (2) l21 · u11 + l22 · 0 = 6, l21 · u12 + l22 · u22 = 3. -

The Strassen Algorithm and Its Computational Complexity
Utrecht University BSc Mathematics & Applications The Strassen Algorithm and its Computational Complexity Rein Bressers Supervised by: Dr. T. van Leeuwen June 5, 2020 Abstract Due to the many computational applications of matrix multiplication, research into efficient algorithms for multiplying matrices can lead to widespread improvements of performance. In this thesis, we will first make the reader familiar with a universal measure of the efficiency of an algorithm, its computational complexity. We will then examine the Strassen algorithm, an algorithm that improves on the computational complexity of the conventional method for matrix multiplication. To illustrate the impact of this difference in complexity, we implement and test both algorithms, and compare their runtimes. Our results show that while Strassen’s method improves on the theoretical complexity of matrix multiplication, there are a number of practical considerations that need to be addressed for this to actually result in improvements on runtime. 2 Contents 1 Introduction 4 1.1 Computational complexity .................................................................................. 4 1.2 Structure ........................................................................................................... 4 2 Computational Complexity ................................................................ 5 2.1 Time complexity ................................................................................................ 5 2.2 Determining an algorithm’s complexity .............................................................. -

An Efficient Implementation of the Thomas-Algorithm for Block Penta
An Efficient Implementation of the Thomas-Algorithm for Block Penta-diagonal Systems on Vector Computers Katharina Benkert1 and Rudolf Fischer2 1 High Performance Computing Center Stuttgart (HLRS), University of Stuttgart, 70569 Stuttgart, Germany [email protected] 2 NEC High Performance Computing Europe GmbH, Prinzenallee 11, 40549 Duesseldorf, Germany [email protected] Abstract. In simulations of supernovae, linear systems of equations with a block penta-diagonal matrix possessing small, dense matrix blocks occur. For an efficient solution, a compact multiplication scheme based on a restructured version of the Thomas algorithm and specifically adapted routines for LU factorization as well as forward and backward substi- tution are presented. On a NEC SX-8 vector system, runtime could be decreased between 35% and 54% for block sizes varying from 20 to 85 compared to the original code with BLAS and LAPACK routines. Keywords: Thomas algorithm, vector architecture. 1 Introduction Neutrino transport and neutrino interactions in dense matter play a crucial role in stellar core collapse, supernova explosions and neutron star formation. The multidimensional neutrino radiation hydrodynamics code PROMETHEUS / VERTEX [1] discretizes the angular moment equations of the Boltzmann equa- tion giving rise to a non-linear algebraic system. It is solved by a Newton Raphson procedure, which in turn requires the solution of multiple block-penta- diagonal linear systems with small, dense matrix blocks in each step. This is achieved by the Thomas algorithm and takes a major part of the overall com- puting time. Since the code already performs well on vector computers, this kind of architecture has been the focus of the current work.