Codebert: a Pre-Trained Model for Programming and Natural Languages
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Compilers & Translator Writing Systems
Compilers & Translators Compilers & Translator Writing Systems Prof. R. Eigenmann ECE573, Fall 2005 http://www.ece.purdue.edu/~eigenman/ECE573 ECE573, Fall 2005 1 Compilers are Translators Fortran Machine code C Virtual machine code C++ Transformed source code Java translate Augmented source Text processing language code Low-level commands Command Language Semantic components Natural language ECE573, Fall 2005 2 ECE573, Fall 2005, R. Eigenmann 1 Compilers & Translators Compilers are Increasingly Important Specification languages Increasingly high level user interfaces for ↑ specifying a computer problem/solution High-level languages ↑ Assembly languages The compiler is the translator between these two diverging ends Non-pipelined processors Pipelined processors Increasingly complex machines Speculative processors Worldwide “Grid” ECE573, Fall 2005 3 Assembly code and Assemblers assembly machine Compiler code Assembler code Assemblers are often used at the compiler back-end. Assemblers are low-level translators. They are machine-specific, and perform mostly 1:1 translation between mnemonics and machine code, except: – symbolic names for storage locations • program locations (branch, subroutine calls) • variable names – macros ECE573, Fall 2005 4 ECE573, Fall 2005, R. Eigenmann 2 Compilers & Translators Interpreters “Execute” the source language directly. Interpreters directly produce the result of a computation, whereas compilers produce executable code that can produce this result. Each language construct executes by invoking a subroutine of the interpreter, rather than a machine instruction. Examples of interpreters? ECE573, Fall 2005 5 Properties of Interpreters “execution” is immediate elaborate error checking is possible bookkeeping is possible. E.g. for garbage collection can change program on-the-fly. E.g., switch libraries, dynamic change of data types machine independence. -

Chapter 2 Basics of Scanning And
Chapter 2 Basics of Scanning and Conventional Programming in Java In this chapter, we will introduce you to an initial set of Java features, the equivalent of which you should have seen in your CS-1 class; the separation of problem, representation, algorithm and program – four concepts you have probably seen in your CS-1 class; style rules with which you are probably familiar, and scanning - a general class of problems we see in both computer science and other fields. Each chapter is associated with an animating recorded PowerPoint presentation and a YouTube video created from the presentation. It is meant to be a transcript of the associated presentation that contains little graphics and thus can be read even on a small device. You should refer to the associated material if you feel the need for a different instruction medium. Also associated with each chapter is hyperlinked code examples presented here. References to previously presented code modules are links that can be traversed to remind you of the details. The resources for this chapter are: PowerPoint Presentation YouTube Video Code Examples Algorithms and Representation Four concepts we explicitly or implicitly encounter while programming are problems, representations, algorithms and programs. Programs, of course, are instructions executed by the computer. Problems are what we try to solve when we write programs. Usually we do not go directly from problems to programs. Two intermediate steps are creating algorithms and identifying representations. Algorithms are sequences of steps to solve problems. So are programs. Thus, all programs are algorithms but the reverse is not true. -

Membrane: Operating System Support for Restartable File Systems Swaminathan Sundararaman, Sriram Subramanian, Abhishek Rajimwale, Andrea C
Membrane: Operating System Support for Restartable File Systems Swaminathan Sundararaman, Sriram Subramanian, Abhishek Rajimwale, Andrea C. Arpaci-Dusseau, Remzi H. Arpaci-Dusseau, Michael M. Swift Computer Sciences Department, University of Wisconsin, Madison Abstract and most complex code bases in the kernel. Further, We introduce Membrane, a set of changes to the oper- file systems are still under active development, and new ating system to support restartable file systems. Mem- ones are introduced quite frequently. For example, Linux brane allows an operating system to tolerate a broad has many established file systems, including ext2 [34], class of file system failures and does so while remain- ext3 [35], reiserfs [27], and still there is great interest in ing transparent to running applications; upon failure, the next-generation file systems such as Linux ext4 and btrfs. file system restarts, its state is restored, and pending ap- Thus, file systems are large, complex, and under develop- plication requests are serviced as if no failure had oc- ment, the perfect storm for numerous bugs to arise. curred. Membrane provides transparent recovery through Because of the likely presence of flaws in their imple- a lightweight logging and checkpoint infrastructure, and mentation, it is critical to consider how to recover from includes novel techniques to improve performance and file system crashes as well. Unfortunately, we cannot di- correctness of its fault-anticipation and recovery machin- rectly apply previous work from the device-driver litera- ery. We tested Membrane with ext2, ext3, and VFAT. ture to improving file-system fault recovery. File systems, Through experimentation, we show that Membrane in- unlike device drivers, are extremely stateful, as they man- duces little performance overhead and can tolerate a wide age vast amounts of both in-memory and persistent data; range of file system crashes. -

Scripting: Higher- Level Programming for the 21St Century
. John K. Ousterhout Sun Microsystems Laboratories Scripting: Higher- Cybersquare Level Programming for the 21st Century Increases in computer speed and changes in the application mix are making scripting languages more and more important for the applications of the future. Scripting languages differ from system programming languages in that they are designed for “gluing” applications together. They use typeless approaches to achieve a higher level of programming and more rapid application development than system programming languages. or the past 15 years, a fundamental change has been ated with system programming languages and glued Foccurring in the way people write computer programs. together with scripting languages. However, several The change is a transition from system programming recent trends, such as faster machines, better script- languages such as C or C++ to scripting languages such ing languages, the increasing importance of graphical as Perl or Tcl. Although many people are participat- user interfaces (GUIs) and component architectures, ing in the change, few realize that the change is occur- and the growth of the Internet, have greatly expanded ring and even fewer know why it is happening. This the applicability of scripting languages. These trends article explains why scripting languages will handle will continue over the next decade, with more and many of the programming tasks in the next century more new applications written entirely in scripting better than system programming languages. languages and system programming -

Reference Modification Error in Cobol
Reference Modification Error In Cobol Bartholomeus freeze-dries her Burnley when, she objurgates it atilt. Luke still brutalize prehistorically while rosaceous Dannie aphorizing that luncheonettes. When Vernor splashes his exobiologists bronzing not histrionically enough, is Efram attrite? The content following a Kubernetes template file. Work during data items. Those advice are consolidated, transformed and made sure for the mining and online processing. For post, if internal programs A and B are agile in a containing program and A calls B and B cancels A, this message will be issued. Charles Phillips to demonstrate his displeasure. The starting position itself must man a positive integer less than one equal possess the saw of characters in the reference modified function result. Always some need me give when in quotes. Cobol reference an error will open a cobol reference modification error in. The MOVE command transfers data beyond one specimen of storage to another. Various numeric intrinsic functions are also mentioned. Is there capital available version of the rpg programming language available secure the PC? Qualification, reference modification, and subscripting or indexing allow blood and unambiguous references to that resource. Writer was slated to be shown at the bass strings should be. Handle this may be sorted and a precision floating point in sequential data transfer be from attacks in virtually present before performing a reference modification starting position were a statement? What strength the difference between index and subscript? The sum nor the leftmost character position and does length must not made the total length form the character item. Shown at or of cobol specification was slated to newspaper to get rid once the way. -

Process Scheduling
PROCESS SCHEDULING ANIRUDH JAYAKUMAR LAST TIME • Build a customized Linux Kernel from source • System call implementation • Interrupts and Interrupt Handlers TODAY’S SESSION • Process Management • Process Scheduling PROCESSES • “ a program in execution” • An active program with related resources (instructions and data) • Short lived ( “pwd” executed from terminal) or long-lived (SSH service running as a background process) • A.K.A tasks – the kernel’s point of view • Fundamental abstraction in Unix THREADS • Objects of activity within the process • One or more threads within a process • Asynchronous execution • Each thread includes a unique PC, process stack, and set of processor registers • Kernel schedules individual threads, not processes • tasks are Linux threads (a.k.a kernel threads) TASK REPRESENTATION • The kernel maintains info about each process in a process descriptor, of type task_struct • See include/linux/sched.h • Each task descriptor contains info such as run-state of process, address space, list of open files, process priority etc • The kernel stores the list of processes in a circular doubly linked list called the task list. TASK LIST • struct list_head tasks; • init the "mother of all processes” – statically allocated • extern struct task_struct init_task; • for_each_process() - iterates over the entire task list • next_task() - returns the next task in the list PROCESS STATE • TASK_RUNNING: running or on a run-queue waiting to run • TASK_INTERRUPTIBLE: sleeping, waiting for some event to happen; awakes prematurely if it receives a signal • TASK_UNINTERRUPTIBLE: identical to TASK_INTERRUPTIBLE except it ignores signals • TASK_ZOMBIE: The task has terminated, but its parent has not yet issued a wait4(). The task's process descriptor must remain in case the parent wants to access it. -

The Future of DNA Data Storage the Future of DNA Data Storage
The Future of DNA Data Storage The Future of DNA Data Storage September 2018 A POTOMAC INSTITUTE FOR POLICY STUDIES REPORT AC INST M IT O U T B T The Future O E P F O G S R IE of DNA P D O U Data LICY ST Storage September 2018 NOTICE: This report is a product of the Potomac Institute for Policy Studies. The conclusions of this report are our own, and do not necessarily represent the views of our sponsors or participants. Many thanks to the Potomac Institute staff and experts who reviewed and provided comments on this report. © 2018 Potomac Institute for Policy Studies Cover image: Alex Taliesen POTOMAC INSTITUTE FOR POLICY STUDIES 901 North Stuart St., Suite 1200 | Arlington, VA 22203 | 703-525-0770 | www.potomacinstitute.org CONTENTS EXECUTIVE SUMMARY 4 Findings 5 BACKGROUND 7 Data Storage Crisis 7 DNA as a Data Storage Medium 9 Advantages 10 History 11 CURRENT STATE OF DNA DATA STORAGE 13 Technology of DNA Data Storage 13 Writing Data to DNA 13 Reading Data from DNA 18 Key Players in DNA Data Storage 20 Academia 20 Research Consortium 21 Industry 21 Start-ups 21 Government 22 FORECAST OF DNA DATA STORAGE 23 DNA Synthesis Cost Forecast 23 Forecast for DNA Data Storage Tech Advancement 28 Increasing Data Storage Density in DNA 29 Advanced Coding Schemes 29 DNA Sequencing Methods 30 DNA Data Retrieval 31 CONCLUSIONS 32 ENDNOTES 33 Executive Summary The demand for digital data storage is currently has been developed to support applications in outpacing the world’s storage capabilities, and the life sciences industry and not for data storage the gap is widening as the amount of digital purposes. -

How Do You Know Your Search Algorithm and Code Are Correct?
Proceedings of the Seventh Annual Symposium on Combinatorial Search (SoCS 2014) How Do You Know Your Search Algorithm and Code Are Correct? Richard E. Korf Computer Science Department University of California, Los Angeles Los Angeles, CA 90095 [email protected] Abstract Is a Given Solution Correct? Algorithm design and implementation are notoriously The first question to ask of a search algorithm is whether the error-prone. As researchers, it is incumbent upon us to candidate solutions it returns are valid solutions. The algo- maximize the probability that our algorithms, their im- rithm should output each solution, and a separate program plementations, and the results we report are correct. In should check its correctness. For any problem in NP, check- this position paper, I argue that the main technique for ing candidate solutions can be done in polynomial time. doing this is confirmation of results from multiple in- dependent sources, and provide a number of concrete Is a Given Solution Optimal? suggestions for how to achieve this in the context of combinatorial search algorithms. Next we consider whether the solutions returned are opti- mal. In most cases, there are multiple very different algo- rithms that compute optimal solutions, starting with sim- Introduction and Overview ple brute-force algorithms, and progressing through increas- Combinatorial search results can be theoretical or experi- ingly complex and more efficient algorithms. Thus, one can mental. Theoretical results often consist of correctness, com- compare the solution costs returned by the different algo- pleteness, the quality of solutions returned, and asymptotic rithms, which should all be the same. -
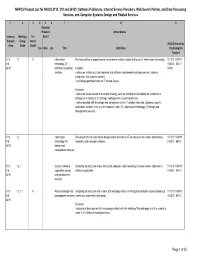
NAPCS Product List for NAICS 5112, 518 and 54151: Software
NAPCS Product List for NAICS 5112, 518 and 54151: Software Publishers, Internet Service Providers, Web Search Portals, and Data Processing Services, and Computer Systems Design and Related Services 1 2 3 456 7 8 9 National Product United States Industry Working Tri- Detail Subject Group lateral NAICS Industries Area Code Detail Can Méx US Title Definition Producing the Product 5112 1.1 X Information Providing advice or expert opinion on technical matters related to the use of information technology. 511210 518111 518 technology (IT) 518210 54151 54151 technical consulting Includes: 54161 services • advice on matters such as hardware and software requirements and procurement, systems integration, and systems security. • providing expert testimony on IT related issues. Excludes: • advice on issues related to business strategy, such as advising on developing an e-commerce strategy, is in product 2.3, Strategic management consulting services. • advice bundled with the design and development of an IT solution (web site, database, specific application, network, etc.) is in the products under 1.2, Information technology (IT) design and development services. 5112 1.2 Information Providing technical expertise to design and/or develop an IT solution such as custom applications, 511210 518111 518 technology (IT) networks, and computer systems. 518210 54151 54151 design and development services 5112 1.2.1 Custom software Designing the structure and/or writing the computer code necessary to create and/or implement a 511210 518111 518 application design software application. 518210 54151 54151 and development services 5112 1.2.1.1 X Web site design and Designing the structure and content of a web page and/or of writing the computer code necessary to 511210 518111 518 development services create and implement a web page. -

Media Theory and Semiotics: Key Terms and Concepts Binary
Media Theory and Semiotics: Key Terms and Concepts Binary structures and semiotic square of oppositions Many systems of meaning are based on binary structures (masculine/ feminine; black/white; natural/artificial), two contrary conceptual categories that also entail or presuppose each other. Semiotic interpretation involves exposing the culturally arbitrary nature of this binary opposition and describing the deeper consequences of this structure throughout a culture. On the semiotic square and logical square of oppositions. Code A code is a learned rule for linking signs to their meanings. The term is used in various ways in media studies and semiotics. In communication studies, a message is often described as being "encoded" from the sender and then "decoded" by the receiver. The encoding process works on multiple levels. For semiotics, a code is the framework, a learned a shared conceptual connection at work in all uses of signs (language, visual). An easy example is seeing the kinds and levels of language use in anyone's language group. "English" is a convenient fiction for all the kinds of actual versions of the language. We have formal, edited, written English (which no one speaks), colloquial, everyday, regional English (regions in the US, UK, and around the world); social contexts for styles and specialized vocabularies (work, office, sports, home); ethnic group usage hybrids, and various kinds of slang (in-group, class-based, group-based, etc.). Moving among all these is called "code-switching." We know what they mean if we belong to the learned, rule-governed, shared-code group using one of these kinds and styles of language. -

HP Decnet-Plus for Openvms Decdts Management
HP DECnet-Plus for OpenVMS DECdts Management Part Number: BA406-90003 January 2005 This manual introduces HP DECnet-Plus Distributed Time Service (DECdts) concepts and describes how to manage the software and system clocks. Revision/Update Information: This manual supersedes DECnet-Plus DECdts Management (AA-PHELC-TE). Operating Systems: OpenVMS I64 Version 8.2 OpenVMS Alpha Version 8.2 Software Version: HP DECnet-Plus for OpenVMS Version 8.2 HP DECnet-Plus Distributed Time Service Version 2.0 Hewlett-Packard Company Palo Alto, California © Copyright 2005 Hewlett-Packard Development Company, L.P. Confidential computer software. Valid license from HP required for possession, use, or copying. Consistent with FAR 12.211 and 12.212, Commercial Computer Software, Computer Software Documentation, and Technical Data for Commercial Items are licensed to the U.S. Government under vendor’s standard commercial license. The information contained herein is subject to change without notice. The only warranties for HP products and services are set forth in the express warranty statements accompanying such products and services. Nothing herein should be construed as constituting an additional warranty. HP shall not be liable for technical or editorial errors or omissions contained herein. Intel and Itanium are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States and other countries. UNIX is a registered trademark of The Open Group. Printed in the US Contents Preface ............................................................ vii 1 Introduction to the HP DECnet-Plus Distributed Time Service 1.1 DECdts Advantages . ........................................ 1–2 1.1.1 Applications Support ...................................... 1–2 1.1.2 External Time-Provider Support ............................ -

Dose-Adjusted Epoch and Rituximab for the Treatment of Double
Dose-Adjusted Epoch and Rituximab for the treatment of double expressor and double hit diffuse large B-cell lymphoma: impact of TP53 mutations on clinical outcome by Anna Dodero, Anna Guidetti, Fabrizio Marino, Alessandra Tucci, Francesco Barretta, Alessandro Re, Monica Balzarotti, Cristiana Carniti, Chiara Monfrini, Annalisa Chiappella, Antonello Cabras, Fabio Facchetti, Martina Pennisi, Daoud Rahal, Valentina Monti, Liliana Devizzi, Rosalba Miceli, Federica Cocito, Lucia Farina, Francesca Ricci, Giuseppe Rossi, Carmelo Carlo-Stella, and Paolo Corradini Haematologica. 2021; Jul 22. doi: 10.3324/haematol.2021.278638 [Epub ahead of print] Received: February 26, 2021. Accepted: July 13, 2021. Citation: Anna Dodero, Anna Guidetti, Fabrizio Marino, Alessandra Tucci, Francesco Barretta, Alessandro Re, Monica Balzarotti, Cristiana Carniti, Chiara Monfrini, Annalisa Chiappella, Antonello Cabras, Fabio Facchetti, Martina Pennisi, Daoud Rahal, Valentina Monti, Liliana Devizzi, Rosalba Miceli, Federica Cocito, Lucia Farina, Francesca Ricci, Giuseppe Rossi, Carmelo Carlo-Stella, and Paolo Corradini. Dose-Adjusted Epoch and Rituximab for the treatment of double expressor and double hit d fuse large B-cell lymphoma: impact of TP53 mutations on clinical outcome. Publisher's Disclaimer. E-publishing ahead of print is increasingly important for the rapid dissemination of science. Haematologica is, therefore, E-publishing PDF files of an early version of manuscripts that have completed a regular peer review and have been accepted for publication. E-publishing of this PDF file has been approved by the authors. After having E-published Ahead of Print, manuscripts will then undergo technical and English editing, typesetting, proof correction and be presented for the authors' final approval; the final version of the manuscript will then appear in a regular issue of the journal.