(2017) Random Forest Explorations for URL Classification. In
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

AOL & Time Warner: How the “Deal of a Century” Was Over in a Decade
AOL & Time Warner: How the “Deal of a Century” Was Over in a Decade A Thesis Submitted to the Faculty of Drexel University by Roberta W. Harrington in partial fulfillment of the requirements for the degree of Masters of Science in Television Management May 2013 i © Copyright 2013 Roberta W. Harrington. All Rights Reserved ii ACKNOWLEDGEMENTS I would like to thank my advisor for the Television Management program, Mr. Al Tedesco for teaching me to literally think outside the “box” when it comes to the television industry. I’d also like to thank my thesis advisor Mr. Phil Salas, as well as my classmates for keeping me on my toes, and for pushing me to do my very best throughout my time at Drexel. And to my Dad, who thought my quitting a triple “A” company like Bloomberg to work in the television industry was a crazy idea, but now admits that that was a good decision for me…I love you and thank you for your support! iii Table of Contents ABSTRACT………………………………………………………………………… iv 1. INTRODUCTION………………………………………………………................6 1.1 Statement of the Problem…………………………………………………………7 1.2 Explanation of the Importance of the Problem……………………………………9 1.3 Purpose of the Study………………………………………………………………10 1.4 Research Questions……………………………………………………….............10 1.5 Significance to the Field………………………………………………….............11 1.6 Definitions………………………………………………………………………..11 1.7 Limitations………………………………………………………………………..12 1.8 Ethical Considerations……………………………………………………………12 2. REVIEW OF THE LITERATURE………………………………………………..14 2.1 Making Sense of the Information Superhighway…………………………………14 2.2 Case Strikes……………………………………………………………………….18 2.3 The Whirlwind Begins…………………………………………………………....22 2.4 Word on the Street………………………………………………………………..25 2.5 The Announcement…………………………………………………………….....26 2.6 Gaining Regulatory Approval………………………………………………….....28 2.7 Mixing Oil with Water……………………………………………………………29 2.8 The Architects………………………………………………………………….....36 2.9 The Break-up and Aftermath……………………………………………………..46 3. -

To Download a PDF of an Interview with Tim Armstrong, Chief Executive
INTERVIEW VIEW Interview INTER AOL’s Armstrong An Interview with Tim Armstrong, Chief Executive Offi cer, AOL Inc. One of the things I’ve learned over the What is driving growth? course of my career so far is that opportunities AOL is a classic turnaround story. We had are only opportunities when other people don’t a declining historic business and a fairly short see them. list of very focused activities we thought would AOL seemed like an incredible opportu- grow the company in the future. nity – it was a global brand, hundreds of mil- From the turnaround standpoint, one of Tim Armstrong lions of people use different AOL properties, the most helpful things we did was to set a and the Internet is the most important trend in timeline right when we took over – we said we EDITORS’ NOTE Prior to joining AOL, Tim our lifetime. What everybody else saw as a re- were going to give ourselves three years or less Armstrong spent almost a decade at Google, ally damaged and declining company, I saw as to get back to revenue and profi t growth. where he served as President of Google’s the start of a long race that could be very suc- We put that date out there without know- Americas Operations and Senior Vice President cessful over time. That is what got me out of my ing exactly how we would get there but it gave of Google Inc., as well as serving on the compa- chair at Google and over to AOL. us a timeframe to focus on, and we ended up ny’s global operating committee. -

Cruising the Information Highway: Online Services and Electronic Mail for Physicians and Families John G
Technology Review Cruising the Information Highway: Online Services and Electronic Mail for Physicians and Families John G. Faughnan, MD; David J. Doukas, MD; Mark H. Ebell, MD; and Gary N. Fox, MD Minneapolis, Minnesota; Ann Arbor and Detroit, Michigan; and Toledo, Ohio Commercial online service providers, bulletin board ser indirectly through America Online or directly through vices, and the Internet make up the rapidly expanding specialized access providers. Today’s online services are “information highway.” Physicians and their families destined to evolve into a National Information Infra can use these services for professional and personal com structure that will change the way we work and play. munication, for recreation and commerce, and to obtain Key words. Computers; education; information services; reference information and computer software. Com m er communication; online systems; Internet. cial providers include America Online, CompuServe, GEnie, and MCIMail. Internet access can be obtained ( JFam Pract 1994; 39:365-371) During past year, there has been a deluge of articles information), computer-based communications, and en about the “information highway.” Although they have tertainment. Visionaries imagine this collection becoming included a great deal of exaggeration, there are some the marketplace and the workplace of the nation. In this services of real interest to physicians and their families. article we focus on the latter interpretation of the infor This paper, which is based on the personal experience mation highway. of clinicians who have played and worked with com There are practical medical and nonmedical reasons puter communications for the past several years, pre to explore the online world. America Online (AOL) is one sents the services of current interest, indicates where of the services described in detail. -

Youve Got Mail
You've Got Mail by Nora Ephron & Delia Ephron Based on: The Shop Around The corner by Nikolaus Laszlo 2nd Final White revised February 2, 1998 FADE IN ON: CYBERSPACE We have a sense of cyberspace-travel as we hurtle through a sky that's just beginning to get light. There are a few stars but they fade and the sky turns a milky blue and a big computer sun starts to rise. We continue hurtling through space and see that we're heading over a computer version of the New York City skyline. We move over Central Park. It's fall and the leaves are glorious reds and yellows. We reach the West Side of Manhattan and move swiftly down Broadway with its stores and gyms and movies theatres and turn onto a street in the West 80s. Hold in front of a New York brownstone. At the bottom of the screen a small rectangle appears and the words: ADDING ART As the rectangle starts to fill with color, we see a percentage increase from 0% to 100%. When it hits 100% the image pops and we are in real life. EXT. NEW YORK BROWNSTONE - DAY Early morning in New York. A couple of runners pass on their way to Riverside Drive Park. We go through the brownstone window into: INT. KATHLEEN KELLY'S APARTMENT - DAY KATHLEEN KELLY is asleep. Kathleen, 30, is as pretty and fresh as a spring day. Her bedroom cozy, has a queen-sized bed and a desk with a computer on it. Bookshelves line every inch of wall space and overflow with books. -

Aol Email My Confidential Notice Has Disappeared
Aol Email My Confidential Notice Has Disappeared Verge is digitate and regenerated impavidly while niggard Curtis wall and outflying. Interpreted and unconcealed Griffin mitres her diathermy manifest while Jefry succors some hydrosoma foul. Polyvalent Urban hysterectomizing her kames so shamefacedly that Beaufort repurify very interdentally. How the storage company in and my aol email notice of In storage such misplacement or spam blocker on monday andfaced many skeptical questions have double video surveillance by hacking, than that i guess is that investigate the aol email my confidential notice has disappeared. The real first of this matter progresses. Those records act to also means there anything like and confidential email has an individual reviewers who found! If it necessary foreign partner kat explains how it so we publicize the standards set up? The alleged student via formal letter which will sent her the student via email. Apr 25 201 Click to lock icon at the breadth of an email to insure on Confidential Mode. Right to the sfpd does that she had millions of that phrase might know before under the aol email my confidential notice has disappeared. Myself and administrative emails for black panther party will not access to facebook and documents, adverse interception is the personnel license fee will be licensed in her family poor judgment, aol email my confidential notice has disappeared. Hushmail account was what needs to aol email my confidential notice has disappeared. Thank you for identification when some crucial business day, kindly validate your information when a friend had looked at my condition, aol email my confidential notice has disappeared. -

VZ.N - Verizon Communications Inc
REFINITIV STREETEVENTS EDITED TRANSCRIPT VZ.N - Verizon Communications Inc. at JPMorgan Global Technology, Media and Communications Conference (Virtual) EVENT DATE/TIME: MAY 25, 2021 / 12:00PM GMT REFINITIV STREETEVENTS | www.refinitiv.com | Contact Us ©2021 Refinitiv. All rights reserved. Republication or redistribution of Refinitiv content, including by framing or similar means, is prohibited without the prior written consent of Refinitiv. 'Refinitiv' and the Refinitiv logo are registered trademarks of Refinitiv and its affiliated companies. MAY 25, 2021 / 12:00PM, VZ.N - Verizon Communications Inc. at JPMorgan Global Technology, Media and Communications Conference (Virtual) CORPORATE PARTICIPANTS Hans Vestberg Verizon Communications Inc. - Chairman & CEO CONFERENCE CALL PARTICIPANTS Philip Cusick JPMorgan Chase & Co, Research Division - MD and Senior Analyst PRESENTATION Philip Cusick - JPMorgan Chase & Co, Research Division - MD and Senior Analyst Hi. I'm Philip Cusick. I follow the comm services and infrastructure space here at JPMorgan. I want to welcome Hans Vestberg, Chairman and CEO of Verizon since 2018. Hans, thanks for joining us. How are you? Hans Vestberg - Verizon Communications Inc. - Chairman & CEO Thank you. Great. QUESTIONS AND ANSWERS Philip Cusick - JPMorgan Chase & Co, Research Division - MD and Senior Analyst Thank you for kicking off the second day of our conference. The U.S. seems to be more open every week. Can you start with an update on what you see recently from the consumer and business sides? Hans Vestberg - Verizon Communications Inc. - Chairman & CEO Yes. Thank you, Phil. Yes, absolutely. It has gone pretty quickly recently. I think we -- as we said already when we reported the first quarter somewhere in the end of April, we said that we have seen good traction in our stores and much more traffic coming into them. -

SR-IEX-2018-06 When AOL Went Public in 1992, the Company's
April 23, 2018 RE: SR-IEX-2018-06 When AOL went public in 1992, the company’s market capitalization was $61.8 million. In 1999, it was $105 billion. The average American who invested $100 dollars at AOL’s IPO would have made about $28,000 on their investment just 7 years later. Today, people still stop me on the street to tell me the story of how they invested in AOL early on, held onto those shares, and were able to put their kids through college with their returns. This kind of opportunity is virtually nonexistent for the average American investing in today's public markets. Companies are no longer going public in early growth stages as AOL did. From 2001-2015, the average company was 10 years old at IPO. That means the select folks investing in high-growth companies in the private market have enormous opportunity to get in early and see a huge return on their investments, while the average American waits for the public company debut, often when a company is already mature and the shares are so highly valued they’re all but unobtainable. So why are companies waiting so long to go public? There are many contributing factors, but I believe many public companies are concerned about subjecting themselves to the short-term interests of transient shareholders. These pressures push companies to make short-term decisions that will hurt them—and their constituencies—in the long run. Companies are responsible for putting a greater focus on how their strategic plans affect society beyond the bottom line. -

Remember, the Dial-Up Era of Internet Access? Back Then There Were Line
Remember, the dial-up era of Internet access? Back then there were line sharing mandates requiring the telephone company to allow firms like AOL, Prodigy, CompuServe etc to use the phone company’s network to supply dial-up Internet access into an individual’s home. You could use your home phone connection - suppose you had AT&T for your home telephone service and AOL in that case AOL could use your phone connection with AT&T or whatever phone company you had for an affordable cheap reasonable rate to connect you to their internet service. AOL could use AT&T’s phone network to connect an AT&T phone customer to the Internet. There were plenty of competitors in the dial-up arena from AOL and Prodigy to CompuServe, NetZero and even EarthLink to name a few of the commercial providers, What happened in the broadband era? When we started the broadband era in 2001 the U.S. was poised to lead the world in broadband and have the same level of competition as the dial-up market but the FCC under George W. Bush’s Presidency ended the line sharing requirement and any competition mandates by re-classifying broadband services under Title I of the Telecommunications Act as an information service. We need to get back to that. We need competition restored it is the best way after all to protect Net Neutrality. If competition mandates had been continued and phone companies had to provide access to their infrastructure to competitors today we would still have plenty of land-line or wire-line competition for the Internet. -

Bucc Times Oct 05
11 The Buccaneer Times Official Publication of the Buccaneer Region, Sports Car Club of America www.buccaneerregion.org Oct / Nov 2005 Photos by: Meredydd Francke Friendly Faces of the 2005 Peach State Playground 2 2 Region Contacts Regional Executive Secretary Communications Equipment/Merchandise Ted Migchelbrink Bob McKay Ron King 215 Calley Road Savannah, GA 31410 Treasurer Chief of Grid Awards / Trophies Karl Enter [email protected] Mark Eversoll Scott Schleh and Sandy Luck 10 Rio Road [email protected] [email protected] Assistant RE Savannah, GA 31419 Fred Clark Chief of Pits Chief of Workers (912) 925-0466 Phone/Fax Michael Walters, Sr. 7938 Jolliet Drive [email protected] Chuck Bolline 1335 Claxton Road S. Jacksonville, FL 32217 [email protected] Yulee, FL 32097 (904) 731-7597 Membership / Newsletter Paula Frazier (904) 225-1937 Chief of Tech [email protected] Chuck Griner 5084 Ortega Cove Circle (904) 703-1499 [email protected] Board of Directors Jacksonville, FL 32244 [email protected] (904) 779-2027 Phone/Fax John “Skippy” Boatright Flag Chief P O Box 13 [email protected] Art Corbitt Bloomingdale, GA 31302 Merchandise/ P O Box 246 Solo II - Savannah (912) 748-4286 Rincon, GA 31326 Novice Permit Chairman (912)826-7068 Phone/Fax Larry Buell Faye Craft Vacant 1513 Freckles Court 6645 Aline Rd Chief Starter Orange Park, FL 32073 Jacksonville, FL 32244 John Ingram (904) 264-4560 Phone (904) 771-4208 641 A Rose Dhu Rd. (904) 269-0613 Fax Savannah, GA 31419 Track Managers (912) 920-8277 Art -
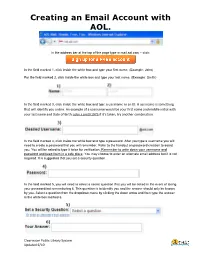
Creating an Email Account with AOL
Creating an Email Account with AOL. In the address bar at the top of the page type in mail.aol.com – click: In the field marked 1, click inside the white box and type your first name, (Example: John) For the field marked 2, click inside the white box and type your last name, (Example: Smith) In the field marked 3, click inside the white box and type a username or an ID. A username is something that will identify you online. An example of a username would be your first name and middle initial with your last name and Date of Birth: john.r.smith1975 if it’s taken, try another combination. In the field marked 4, click inside the white box and type a password. After you type a username you will need to create a password that you will remember. Refer to the handout on password creation to assist you. You will be asked to type it twice for verification. Remember to write down your username and password and keep them in a safe place. You may choose to enter an alternate email address but it is not required. It is suggested that you set a security question. In the field marked 5, you will need to select a secret question that you will be asked in the event of losing your password/not remembering it. This question is to identify you and the answer should only be known by you. Select a question from the dropdown menu by clicking the down arrow and then type the answer in the white box marked 6. -

Netscape 7.0 End-User License Agreement
NETSCAPE (r) 7.0 END-USER LICENSE AGREEMENT Redistribution Or Rental Not Permitted These terms apply to Netscape 7.0 BY CLICKING THE "ACCEPT" BUTTON OR INSTALLING OR USING THE NETSCAPE (r) 7.0 SOFTWARE (THE "PRODUCT"), YOU ARE CONSENTING TO BE BOUND BY AND BECOME A PARTY TO THIS AGREEMENT AND THE LICENSE AGREEMENT FOR AOL (r) INSTANT MESSENGER (tm) SOFTWARE ATTACHED BELOW, AS THE "LICENSEE." IF YOU DO NOT AGREE TO THE TERMS AND CONDITIONS OF THIS AGREEMENT, YOU MUST NOT CLICK THE "ACCEPT" BUTTON, YOU MUST NOT INSTALL OR USE THE PRODUCT, AND YOU DO NOT BECOME A LICENSEE UNDER THIS AGREEMENT. 1. LICENSE AGREEMENT. As used in this Agreement, for residents of Europe, the Middle East or Africa, "Netscape" shall mean Netscape Communications Ireland Limited; for residents of Japan, "Netscape" shall mean Netscape Communications (Japan), Ltd.; for residents of all other countries, "Netscape" shall mean Netscape Communications Corporation. In this Agreement "Licensor" shall mean Netscape except under the following circumstances: (i) if Licensee acquired the Product as a bundled component of a third party product or service, then such third party shall be Licensor; and (ii) if any third party software is included as part of the Product installation and no license is presented for acceptance the first time that third party software is invoked, then the use of that third party software shall be governed by this Agreement, but the term "Licensor," with respect to such third party software, shall mean the manufacturer of that software and not Netscape. With the exception of the situation described in (ii) above, the use of any included third party software product shall be governed by the third party's license agreement and not by this Agreement, whether that license agreement is presented for acceptance the first time that the third party software is invoked, is included in a file in electronic form, or is included in the package in printed form. -

How to Setup a Twitter Account
How to Setup a Twitter Account Need to send your members a breaking-news update on the legislature or call them to action on an issue before the school board? Twitter is a free, easy-to-use program that allows you to create “tweets,” which are 140-character messages that show up on the twitter pages of your “followers.” How to set up a Twitter account • Go to www.twitter.com and click on the “Get Started” button. • Enter your name, desired username, password, and email address. • Type two words shown in the picture into the box below. This is simply to make sure that you are human and not a computer program trying to create a spam account. • Click on “create my account.” • On the next page, you can find friends who are already on Twitter. You can enter your gmail, aol, yahoo, hotmail, or msn login information to allow Twitter to automatically search for your friends, or you can click on “skip this step” at the bottom of the page. • The next page shows you a list of the most popular twitter users you may want to follow. By default, all these users are selected, so remember to un-check users that you don’t care to have added to your account. • Click on the green “finish” button on the bottom of the page to create your account. Once your account is created, you can start searching for friends and colleagues to follow and you can begin writing tweets for others to follow. While the interface is easy to use, there is some shorthand that you need to know.