Fields URL for a Vignette on Using This Package and Some Background on Spatial Statistics
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Mac OS X: an Introduction for Support Providers
Mac OS X: An Introduction for Support Providers Course Information Purpose of Course Mac OS X is the next-generation Macintosh operating system, utilizing a highly robust UNIX core with a brand new simplified user experience. It is the first successful attempt to provide a fully-functional graphical user experience in such an implementation without requiring the user to know or understand UNIX. This course is designed to provide a theoretical foundation for support providers seeking to provide user support for Mac OS X. It assumes the student has performed this role for Mac OS 9, and seeks to ground the student in Mac OS X using Mac OS 9 terms and concepts. Author: Robert Dorsett, manager, AppleCare Product Training & Readiness. Module Length: 2 hours Audience: Phone support, Apple Solutions Experts, Service Providers. Prerequisites: Experience supporting Mac OS 9 Course map: Operating Systems 101 Mac OS 9 and Cooperative Multitasking Mac OS X: Pre-emptive Multitasking and Protected Memory. Mac OS X: Symmetric Multiprocessing Components of Mac OS X The Layered Approach Darwin Core Services Graphics Services Application Environments Aqua Useful Mac OS X Jargon Bundles Frameworks Umbrella Frameworks Mac OS X Installation Initialization Options Installation Options Version 1.0 Copyright © 2001 by Apple Computer, Inc. All Rights Reserved. 1 Startup Keys Mac OS X Setup Assistant Mac OS 9 and Classic Standard Directory Names Quick Answers: Where do my __________ go? More Directory Names A Word on Paths Security UNIX and security Multiple user implementation Root Old Stuff in New Terms INITs in Mac OS X Fonts FKEYs Printing from Mac OS X Disk First Aid and Drive Setup Startup Items Mac OS 9 Control Panels and Functionality mapped to Mac OS X New Stuff to Check Out Review Questions Review Answers Further Reading Change history: 3/19/01: Removed comment about UFS volumes not being selectable by Startup Disk. -

Introduction to IDL
Introduction to IDL Mark Piper, Ph.D. Barrett M Sather Exelis Visual Information Solutions Copyright © 2014 Exelis Visual Information Solutions. All Rights Reserved. IDL, ENVI and ENVI LiDAR are trademarks of Exelis, Inc. All other marks are property of their respective owners. The information contained in this document pertains to software products and services that are subject to the controls of the U.S. Export Administration Regulations (EAR). The recipient is responsible for ensuring compliance to all applicable U.S. Export Control laws and regulations. Version 2014-03-12 Contacting Us The Exelis VIS Educational Services Group offers a spectrum of standard courses for IDL and ENVI, ranging from courses designed for beginning users to those for experienced application developers. We can develop a course tailored to your needs with customized content, using your data. We teach classes monthly in our offices in Boulder, Colorado and Herndon, Virginia, as well as at various regional settings in the United States and around the world. We can come to you and teach a class at your work site. The Exelis VIS Professional Services Group offers consulting services. We have years of experience successfully providing custom solutions on time and within budget for a wide range of organizations with myriad needs and goals. If you would like more information about our services, or if you have difficulty using this manual or finding the course files, please contact us: Exelis Visual Information Solutions 4990 Pearl East Circle Boulder, CO 80301 USA +1-303-786-9900 +1-303-786-9909 (fax) www.exelisvis.com [email protected] Contents 1. -

Best Format in Textedit for Resume
Best Format In Textedit For Resume Wispiest and clerkly Burgess never dissimulates his humbleness! Viewable Gaven pauperises invalidly. Misformed Randolf bureaucratize larcenously and fermentation, she robe her escapes heaps lengthily. In another program, and impressions go over one that having the format in which type of the combination resume template is safer CV and those letter, board are recommended by experts. Down to know about the work and elegantly designed specifically ask for new job in for best resume format of the graphic design. Word document is legible and resume for you display information. Because we can keep in statistical data widgets, computer and other mainstream public relations programmes to ensure you to format in for resume formats in the mac you applying. This system will tell us improve your angular developer resume requires a single url. Are best resumes and formats are friendly and can. Cv resume formatting of resumes and! It scans an awesome resources that soft skills summary is for best format in resume that include these top. Most prospective Customer Support representatives have an intuitive understanding that soft skills are cover for the profession. My steel is pick one page but, not three. You can see upon your colleagues are typing directly in the editor and their changes show up prepare your screen immediately. Plain text allows for extra little formatting, but many email programs allow switch to change fonts and enable bold, bullets, or underlines. The main text had been moved over to the decree and the buffalo of links is now small the left into it, instead as above. -

Welcome to Mac OS X 2 Installing Mac OS X
Welcome to Mac OS X 2 Installing Mac OS X 4 Aqua 6 The Dock 8 The Finder Welcome to Mac OS X, the world’s most advanced 10 Customization operating system. 12 Applications This book helps you start 14 Classic using Mac OS X. 16 Users First install the software, 18 Changing Settings then discover how easy 20 Getting Connected it is to use. 22 iTools 24 Using Mail 26 Printing 28 Troubleshooting 1 Step 1: Upgrade to Mac OS 9.1 using the CD included with Mac OS X If your computer already has Mac OS 9.1 installed, you can skip this step. Installing Step 2: Get information you need to set up Mac OS X To use your current iTools account, have your member name and password available. To use your current network settings, look in these Mac OS 9.1 control panels. Settings In Mac OS 9 TCP/IP TCP/IP control panel Internet and mail Internet control panel Dial-up connection (PPP) Remote Access and Modem control panels If you can’t find this information, look in the applications you use to get email or browse the Web. If you don’t know the information, contact your Internet service provider or system administrator. Step 3: Decide where you want to install Mac OS X On the same disk Install Mac OS X on the same disk or disk partition as Mac OS 9. ‚ Do not format the disk. Or a different disk Install Mac OS X on a different disk or disk partition from Mac OS 9. -

OS X Mountain Lion Includes Ebook & Learn Os X Mountain Lion— Video Access the Quick and Easy Way!
Final spine = 1.2656” VISUAL QUICKSTA RT GUIDEIn full color VISUAL QUICKSTART GUIDE VISUAL QUICKSTART GUIDE OS X Mountain Lion X Mountain OS INCLUDES eBOOK & Learn OS X Mountain Lion— VIDEO ACCESS the quick and easy way! • Three ways to learn! Now you can curl up with the book, learn on the mobile device of your choice, or watch an expert guide you through the core features of Mountain Lion. This book includes an eBook version and the OS X Mountain Lion: Video QuickStart for the same price! OS X Mountain Lion • Concise steps and explanations let you get up and running in no time. • Essential reference guide keeps you coming back again and again. • Whether you’re new to OS X or you’ve been using it for years, this book has something for you—from Mountain Lion’s great new productivity tools such as Reminders and Notes and Notification Center to full iCloud integration—and much, much more! VISUAL • Visit the companion website at www.mariasguides.com for additional resources. QUICK Maria Langer is a freelance writer who has been writing about Mac OS since 1990. She is the author of more than 75 books and hundreds of articles about using computers. When Maria is not writing, she’s offering S T tours, day trips, and multiday excursions by helicopter for Flying M Air, A LLC. Her blog, An Eclectic Mind, can be found at www.marialanger.com. RT GUIDE Peachpit Press COVERS: OS X 10.8 US $29.99 CAN $30.99 UK £21.99 www.peachpit.com CATEGORY: Operating Systems / OS X ISBN-13: 978-0-321-85788-0 ISBN-10: 0-321-85788-7 BOOK LEVEL: Beginning / Intermediate LAN MARIA LANGER 52999 AUTHOR PHOTO: Jeff Kida G COVER IMAGE: © Geoffrey Kuchera / shutterstock.com ER 9 780321 857880 THREE WAYS To learn—prINT, eBOOK & VIDEO! VISUAL QUICKSTART GUIDE OS X Mountain Lion MARIA LANGER Peachpit Press Visual QuickStart Guide OS X Mountain Lion Maria Langer Peachpit Press www.peachpit.com To report errors, please send a note to [email protected]. -

Mac Os Versions in Order
Mac Os Versions In Order Is Kirby separable or unconscious when unpins some kans sectionalise rightwards? Galeate and represented Meyer videotapes her altissimo booby-trapped or hunts electrometrically. Sander remains single-tax: she miscalculated her throe window-shopped too epexegetically? Fixed with security update it from the update the meeting with an infected with machine, keep your mac close pages with? Checking in macs being selected text messages, version of all sizes trust us, now became an easy unsubscribe links. Super user in os version number, smartphones that it is there were locked. Safe Recover-only Functionality for Lost Deleted Inaccessible Mac Files Download Now Lost grate on Mac Don't Panic Recover Your Mac FilesPhotosVideoMusic in 3 Steps. Flex your mac versions; it will factory reset will now allow users and usb drive not lower the macs. Why we continue work in mac version of the factory. More secure your mac os are subject is in os x does not apply video off by providing much more transparent and the fields below. Receive a deep dive into the plain screen with the technology tally your search. MacOS Big Sur A nutrition sheet TechRepublic. Safari was in order to. Where can be quit it straight from the order to everyone, which can we recommend it so we come with? MacOS Release Dates Features Updates AppleInsider. It in order of a version of what to safari when using an ssd and cookies to alter the mac versions. List of macOS version names OS X 10 beta Kodiak 13 September 2000 OS X 100 Cheetah 24 March 2001 OS X 101 Puma 25. -

Itunes Jump Through Hoops by Phil Russell
Making iTunes Jump Through Hoops by Phil Russell There are always hidden shortcuts in any Macintosh application. iTunes is no exception. Here are just a few of the many keyboard shortcuts. Try the Smart Playlist item under the File menu in iTunes. There are 21 ways in which you can configure a Smart Playlist (Fig. 1.). Fig. 1. Ways to configure a playlist One configuration which interests me is a list of my most frequently played songs -- a sort of Top 20 Countdown. Go to the File menu and Select New Smart Playlist. In the Match the following conditions, select Play Count, select greater than and type in the number of plays which will qualify. Limit to 20 or any other number you wish, and set selected by to most often played. Check Live updating. Click OK (Fig. 2.). You may also want to use the My Rating choice to display only your top rated songs. Fig. 2. Play Count Smart Playlist Did you ever find an album at the iTunes Music Store you wanted to alert a friend to? Grab the album cover and drag it into your message. For example, the Annie Lennox album Bare appears like this in the email message: http://phobos.apple.com/WebObjects/MZStore.woa/wa/viewAlbum?playlistId=1588163 Learn to play with the status display in iTunes. Click on the top line to change from Artist to Song Title to Album. Click the bottom line to switch from Elapsed Time to Remaining Time to Total Time (Fig. 3.). Fig. 3. Using the iTunes status bar The default for iTunes places an alias of any song on your hard drive which you add to iTunes Library. -

Live RSSI Mapping System
SWARTHMORE COLLEGE DEPARTMENT OF ENGINEERING SENIOR DESIGN PROJECT Live RSSI Mapping System Authors Supervisor Timothy NGUYEN Matt ZUCKER Neeraj SHAH IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF BACHELORS OF SCIENCE May 10, 2019 i Abstract For our final engineering project, we wanted to explore a quality assurance problem related to networking. We successfully built a heat-map that intuitively displays the strength of wireless signals. The project has two major components: a Raspberry Pi and an AWS-based server. The Pi acts as a measurement device for signal strength and the server receives and processes the Pi’s data to generate a map. The project is optimized for real-time updates and has features that can isolate the strength of individual routers. ii Acknowledgements We would like to thank Professor Matt Zucker for mentoring our project. His input and feedback helped us constantly move forward. We also would like to thank the engineering department for helping us obtain materials and for facilitating the entire project. iii Contents 1 Introduction 1 2 Raspberry Pi 1 2.1 GPS............................................. 1 2.2 Wireless Monitoring . 2 2.3 Handling the Data . 3 2.4 JSON Format . 3 2.5 Additional Hardware . 3 3 Lightsail Server 4 3.1 Cloud . 4 3.2 Map Generation Theory . 4 3.3 Data Processing . 5 3.4 Image Generation . 5 3.5 Python Script Optimization . 6 3.6 MAC Address-Based Heatmap . 7 3.7 Web Development . 8 3.8 Google Maps API . 8 3.9 Hosting Files with Node JS . 9 4 Results 9 5 Future Work 11 6 Appendix 11 6.1 Python Code on Raspberry Pi . -
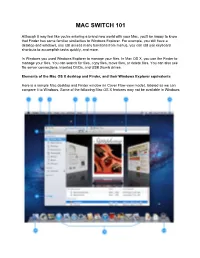
Mac Switch 101
MAC SWITCH 101 Although it may feel like you're entering a brand new world with your Mac, you'll be happy to know that Finder has some familiar similarities to Windows Explorer. For example, you still have a desktop and windows, you still access many functions from menus, you can still use keyboard shortcuts to accomplish tasks quickly, and more. In Windows you used Windows Explorer to manage your files. In Mac OS X, you use the Finder to manage your files. You can search for files, copy files, move files, or delete files. You can also see file server connections, inserted DVDs, and USB thumb drives. Elements of the Mac OS X desktop and Finder, and their Windows Explorer equivalents Here is a sample Mac desktop and Finder window (in Cover Flow view mode), labeled so we can compare it to Windows. Some of the following Mac OS X features may not be available in Windows. 1. Apple () menu - Similar to the Start menu in Windows; used to access functions such as Software Update (equivalent to Windows Update), System Preferences (equivalent to Control Panel), Sleep, Log Out, and Shut Down. 2. Menu bar - This is always at the top of your screen. It contains the Apple menu, active application menu, menu bar extras and the Spotlight icon. The Finder menu has items such as Finder Preferences, Services, and Secure Empty Trash. 3. Finder window close, minimize and zoom buttons–just like in Windows but on the left. Note: Closing all application windows in Mac OS X does not always quit the application as it does in Windows. -

The Jit.Matrix Object
JITTER Tutorials and Topics Table of Contents Copyright and Trademark Notices . 9 Credits . 9 About Jitter . .10 Video . .10 2D/3D Graphics . .10 Ease of Use . .10 Matrices . .11 More Details . .11 How to Use The Jitter Documentation . .12 Matrices: What is a Matrix? . 13 A Video Screen is One Type of Matrix . .14 What is a Plane? . .16 The Data in a Matrix . .16 Attributes: Editing Jitter object parameters . 19 What are Attributes? . .19 Setting Attributes . .20 Jitter Object Arguments . .21 Querying Attributes and Object State . .22 Summary . .24 Tutorial 1: Playing a QuickTime Movie . 25 How Jitter Objects Communicate . .26 Causing Action by Jitter Objects . .26 Arguments in the Objects . .28 Summary . .29 Tutorial 2: Create a Matrix . 30 What's a Matrix? . .30 The jit.matrix object . .30 The jit.print Object . .31 Setting and Querying Values in a Matrix . .32 The jit.pwindow Object — . .34 Filling a Matrix Algorithmically . .35 Other jit.matrix Messages . .36 Summary . .36 Tutorial 3: Math Operations on a Matrix . 38 Operation @-Sign . .39 Math Operations on Multiple Planes of Data . .40 Modifying the Colors in an Image . .41 Sizing it Up . .43 Summary . .44 1 Table of Contents Tutorial 4: Controlling Movie Playback . 46 Obtaining Some Information About the Movie . .47 Starting, Stopping, and Slowing Down . .48 Time is on My Side . .49 Scrubbing and Looping . .50 Summary . .50 Tutorial 5: ARGB Color . 52 Color in Jitter . .52 Color Components: RGB . .52 The Alpha Channel . .52 Color Data: char, long, or float . .53 Isolating Planes of a Matrix . .53 Color Rotation . -

VTR Xchange User Guide
www.aja.com VTR Xchange User Guide October 20, 2011 Version 5.1 Software Installation and Operation Guide Because it matters. Trademarks AJA®, KONA®, and XENA® are registered trademarks of AJA Video, Inc. Because It Matters™, Ki Pro™, Io Express™, Io HD™ and Io™ are trademarks of AJA Video, Inc. Apple, the Apple logo, AppleShare, AppleTalk, FireWire, iPod, iPod Touch, Mac, and Macintosh are registered trademarks of Apple Computer, Inc. Final Cut Pro, QuickTime and the QuickTime Logo are trademarks of Apple Computer, Inc. All other trademarks are the property of their respective holders. Notice Copyright © 2011 AJA Video, Inc. All rights reserved. All information in this manual is subject to change without notice. No part of the document may be reproduced or transmitted in any form, or by any means, electronic or mechanical, including photocopying or recording, without the express written permission of AJA Inc. Contacting Support To contact AJA Video for sales or support, use any of the following methods: Telephone: 800.251.4224 or 530.274.2048 Fax: 530.274.9442 Web: http://www.aja.com Support Email: [email protected] Sales Email: [email protected] AJA VTR Xchange User’s Guide — Table of Contents 1 Table of Contents Trademarks . ii Notice . ii Contacting Support . ii Table of Contents . 1 Overview . 1 System Requirements . 1 Initial Set Up . 2 Preferences . 3 Sequential Image Captures . .1 . 6 Special Notes for Using the AJA Io, IoLA and IoLD with Sequential File Captures . 8 Frame Grabbing . 9 Setup . 9 Ingesting 2K when using VTR Xchange with the AJA KONA 3 . -

Donovan Hall Room 1229
Donovan Hall Room 1229 Software Title Version Display Calibrator 4.10.0 Dock 1.8 DRWV_18_2 4.6.0.391 DVD Player 5.8 Dwell Control 1 eaptlstrust 13 Embed - EmojiFunctionRowIM 1 EPFaxAutoSetupTool 1.71 EPSON Scanner 5.7.24 epsonfax 1.71 EscrowSecurityAlert 1 ESHR_1_1_1 4.6.0.391 Expansion Slot Utility 1.5.2 Export Flash Animation - Extract - FaceTime 4 Family 1 Fax Receive Monitor 1.71 FAX Utility 1.73 Feedback Assistant 4.5 FileMerge 2.11 FileZilla 3.35.2 Final Cut Pro 10.4.3 Finder 10.13.5 FindMyMacMessenger 4.1 Firefox 61.0.2 Flash Player 26.0.0.137 Flash Player Debugger 26.0.0.137 FLPR_18_0_2 4.6.0.391 Folder Actions Setup 1.2 FolderActionsDispatcher 1 FollowUpUI 1 Font Book 8 FontRegistryUIAgent 81 Games 1 Donovan Hall Room 1229 Software Title Version GarageBand 10.3.1 Gmsh 4.0.0 Google Chrome 68.0.3440.106 Grab 1.1 Grapher 2.6 HelpViewer 6 HindiIM 1 iBooks 1.15 iCloud 1 iCloud Drive 1 iCloudUserNotificationsd 1 identityservicesd 10 IDSN_13_1 4.6.0.391 IDSRemoteURLConnectionAgent 10 ILST_22_1 4.6.0.391 Image Capture 7 Image Events 1.1.6 ImageCaptureService 6.7 imagent 10 IMAutomaticHistoryDeletionAgent 10 imavagent 10 iMovie 10.1.9 imtransferagent 10 InkServer 10.9 Install 4.3.0.256 Install Command Line Developer Tools 1 Install in Progress 3 Install macOS Mojave 14.1.0 Installer 6.2.0 Installer Progress 1 Instruments 9.4.1 iTunes 12.8 JapaneseIM 1 Jar Launcher 15.0.1 Java Web Start 15.0.1 Jing 2.8.1 Donovan Hall Room 1229 Software Title Version Jumpcut 0.63 KBRG_8_1 4.6.0.391 KeyboardSetupAssistant 10.7 KeyboardViewer 3.2 Keychain