Crep: a Regular Expression-Matching Textual Corpus Tool
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
2016-17 Immaculate Basketball Player Checklist;
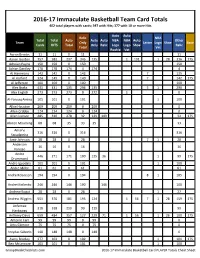
2016-17 Immaculate Basketball Team Card Totals 402 total players with cards; 397 with Hits; 377 with 10 or more Hits Auto Auto Relic NBA Total Total Auto Auto Auto NBA NBA Auto Other Team Only Letter Logo Shoe Base Cards HITS Total Only Relic Logo Logo Shoe Relic Total Vet Rookie Vet Aaron Brooks 11 11 0 11 11 Aaron Gordon 757 582 237 345 135 1 101 1 28 316 175 Adreian Payne 150 150 0 150 150 Adrian Dantley 178 178 174 4 174 4 AJ Hammons 142 142 0 142 7 135 Al Horford 324 149 0 149 7 142 175 Al Jefferson 100 100 0 100 100 Alec Burks 431 431 135 296 135 5 1 290 Alex English 273 273 273 0 272 1 0 Al-Farouq Aminu 101 101 0 101 1 100 Allan Houston 209 209 209 0 209 0 Allen Crabbe 124 124 124 0 124 0 Allen Iverson 485 310 278 32 129 149 32 175 Alonzo Mourning 68 68 35 33 35 33 Amar'e 316 316 0 316 316 Stoudemire Amir Johnson 28 28 0 28 7 1 20 Anderson 16 16 0 16 16 Varejao Andre 446 271 171 100 135 36 1 99 175 Drummond Andre Iguodala 101 101 0 101 1 100 Andre Miller 61 61 0 61 61 Andre Roberson 194 194 0 194 8 1 185 Andrei Kirilenko 246 246 146 100 146 100 Andrew Bogut 28 28 0 28 1 27 Andrew Wiggins 551 376 181 195 124 1 56 7 1 28 159 175 Anfernee 318 318 219 99 219 99 Hardaway Anthony Davis 659 484 357 127 229 71 1 56 1 26 100 175 Antoine Carr 99 99 99 0 99 0 Artis Gilmore 75 75 75 0 75 0 Arvydas Sabonis 148 148 148 0 148 0 Avery Bradley 277 102 0 102 1 101 175 Ben McLemore 101 101 0 101 1 100 GroupBreakChecklists.com 2016-17 Immaculate Basketball Card PLAYER Totals Cheat Sheet Auto Auto Relic NBA Total Total Auto Auto Auto NBA NBA Auto Other -

This Day in Hornets History
THIS DAY IN HORNETS HISTORY January 1, 2005 – Emeka Okafor records his 19th straight double-double, the longest double-double streak by a rookie since 12-time NBA All-Star Elvin Hayes registered 60 straight during the 1968-69 season. January 2, 1998 – Glen Rice scores 42 points, including a franchise-record-tying 28 in the second half, in a 99-88 overtime win over Miami. January 3, 1992 – Larry Johnson becomes the first Hornets player to be named NBA Rookie of the Month, winning the award for the month of December. January 3, 2002 – Baron Davis records his third career triple-double in a 114-102 win over Golden State. January 3, 2005 – For the second time in as many months, Emeka Okafor earns the Eastern Conference Rookie of the Month award for the month of December 2004. January 6, 1997 – After being named NBA Player of the Week earlier in the day, Glen Rice scores 39 points to lead the Hornets to a 109-101 win at Golden State. January 7, 1995 – Alonzo Mourning tallies 33 points and 13 rebounds to lead the Hornets to the 200th win in franchise history, a 106-98 triumph over the Boston Celtics at the Hive. January 7, 1998 – David Wesley steals the ball and hits a jumper with 2.2 seconds left to lift the Hornets to a 91-89 win over Portland. January 7, 2002 – P.J. Brown grabs a career-high 22 rebounds in a 94-80 win over Denver. January 8, 1994 – The Hornets beat the Knicks for the second time in six days, erasing a 20-2 first quarter deficit en route to a 102-99 win. -

Sports Figures Price Guide
SPORTS FIGURES PRICE GUIDE All values listed are for Mint (white jersey) .......... 16.00- David Ortiz (white jersey). 22.00- Ching-Ming Wang ........ 15 Tracy McGrady (white jrsy) 12.00- Lamar Odom (purple jersey) 16.00 Patrick Ewing .......... $12 (blue jersey) .......... 110.00 figures still in the packaging. The Jim Thome (Phillies jersey) 12.00 (gray jersey). 40.00+ Kevin Youkilis (white jersey) 22 (blue jersey) ........... 22.00- (yellow jersey) ......... 25.00 (Blue Uniform) ......... $25 (blue jersey, snow). 350.00 package must have four perfect (Indians jersey) ........ 25.00 Scott Rolen (white jersey) .. 12.00 (grey jersey) ............ 20 Dirk Nowitzki (blue jersey) 15.00- Shaquille O’Neal (red jersey) 12.00 Spud Webb ............ $12 Stephen Davis (white jersey) 20.00 corners and the blister bubble 2003 SERIES 7 (gray jersey). 18.00 Barry Zito (white jersey) ..... .10 (white jersey) .......... 25.00- (black jersey) .......... 22.00 Larry Bird ............. $15 (70th Anniversary jersey) 75.00 cannot be creased, dented, or Jim Edmonds (Angels jersey) 20.00 2005 SERIES 13 (grey jersey ............... .12 Shaquille O’Neal (yellow jrsy) 15.00 2005 SERIES 9 Julius Erving ........... $15 Jeff Garcia damaged in any way. Troy Glaus (white sleeves) . 10.00 Moises Alou (Giants jersey) 15.00 MCFARLANE MLB 21 (purple jersey) ......... 25.00 Kobe Bryant (yellow jersey) 14.00 Elgin Baylor ............ $15 (white jsy/no stripe shoes) 15.00 (red sleeves) .......... 80.00+ Randy Johnson (Yankees jsy) 17.00 Jorge Posada NY Yankees $15.00 John Stockton (white jersey) 12.00 (purple jersey) ......... 30.00 George Gervin .......... $15 (whte jsy/ed stripe shoes) 22.00 Randy Johnson (white jersey) 10.00 Pedro Martinez (Mets jersey) 12.00 Daisuke Matsuzaka .... -

Sports Business Journal
Portfolio GiViNG BACK adopted hometown of Charlotte. The camp incorporates lessons he learned as a child at camp, and those passed on by Whitfield’s parents. Mix in All-Star-caliber friends, including Michael Jordan, and it’s clear the camp is anything but ordinary. n n n n whitfield, the president and vice chairman of Whitfield’s parents allowed the Hornets, runs him to chase his basketball the achievements dreams, but they also drove unlimited camp home the importance of edu- in charlotte each summer. cation. Both earned master’s degrees and provided an ex- ample that pushed Whitfield to make the honor roll and, eventu- ally, earn three degrees: bachelor’s, MBA and law. Whitfield did well on the court, too. He played college ball at Campbell, where he became all-conference and team MVP. During college summers, he worked as a counselor at the same camp he had attended through high school. During one stint as a counselor, Whitfield worked with a group of campers that included a rising high school senior from Wilmington named Michael Jordan. The two hit it off — Whitfield served as a momentary basketball mentor to Jordan after the camp before His Airness soared into history — and they’ve remained North Carolina, started the camp in friends ever since. the 1950s. (McKinney also played in When Jordan played for Dean Smith Lasting lessons the pros and went on to coach at Wake at North Carolina in the early 1980s, Forest.) A week’s tuition, Whitfield Whitfield would drive from Buies recalls, cost $95, including room and Creek, where he was then a Campbell from camp board. -

1988-89 Fleer Basketball Checklist
1 988 FLEER BASKETBALL CARD SET CHECKLI ST+A1 1 Antoine Carr 2 Cliff Levingston 3 Doc Rivers 4 Spud Webb 5 Dominique Wilkins 6 Kevin Willis 7 Randy Wittman 8 Danny Ainge 9 Larry Bird 10 Dennis Johnson 11 Kevin McHale 12 Robert Parish 13 Tyrone Bogues 14 Dell Curry 15 Dave Corzine 16 Horace Grant 17 Michael Jordan 18 Charles Oakley 19 John Paxson 20 Scottie Pippen 21 Brad Sellers 22 Brad Daugherty 23 Ron Harper 24 Larry Nance 25 Mark Price 26 John Williams 27 Mark Aguirre 28 Rolando Blackman 29 James Donaldson 30 Derek Harper 31 Sam Perkins 32 Roy Tarpley 33 Michael Adams 34 Alex English 35 Lafayette Lever 36 Blair Rasmussen 37 Dan Schayes 38 Jay Vincent 39 Adrian Dantley 40 Joe Dumars 41 Vinnie Johnson 42 Bill Laimbeer Compliments of BaseballCardBinders.com© 2019 1 43 Dennis Rodman 44 John Salley 45 Isiah Thomas 46 Winston Garland 47 Rod Higgins 48 Chris Mullin 49 Ralph Sampson 50 Joe Barry Carroll 51 Eric Floyd 52 Rodney McCray 53 Akeem Olajuwon 54 Purvis Short 55 Vern Fleming 56 John Long 57 Reggie Miller 58 Chuck Person 59 Steve Stipanovich 60 Wayman Tisdale 61 Benoit Benjamin 62 Michael Cage 63 Mike Woodson 64 Kareem Abdul-Jabbar 65 Michael Cooper 66 A.C. Green 67 Magic Johnson 68 Byron Scott 69 Mychal Thompson 70 James Worthy 71 Dwayne Washington 72 Kevin Williams 73 Randy Breuer 74 Terry Cummings 75 Paul Pressey 76 Jack Sikma 77 John Bagley 78 Roy Hinson 79 Buck Williams 80 Patrick Ewing 81 Sidney Green 82 Mark Jackson 83 Kenny Walker 84 Gerald Wilkins 85 Charles Barkley 86 Maurice Cheeks 87 Mike Gminski 88 Cliff Robinson 89 Armon -

All-Time Roster
ALL-TIME ROSTER All-Time Roster Brad Daugherty was a five-time NBA All-Star and remains the only Cavalier to ever average 20 points and 10 rebounds in a single season (1990-91, 1991-92, 1992-93). Cavaliers All-Time Roster DENG ADEL Height: 6’7” Weight: 200” Born: February 1, 1997 (Louisville ‘18) Signed a Two-Way contract on January 15, 2019. YEAR GP MIN FGM FGA FG% FTM FTA FT% OR DR TR AST PF-D STL BLK PTS PPG 2018-19 19 194 11 36 .306 4 4 1.000 3 16 19 5 13-0 1 4 32 1.7 Three-point field goals: 6-23 (.261) GARY ALEXANDER Height: 6’7” Weight: 240 Born: November 1, 1969 (South Florida ’92) Signed as a free agent, March 23, 1994. YEAR GP MINS FGM FGA FG% FTM FTA FT% OR DR TR AST PF-D STL BS PTS PPG 1993-94 7 43 7 12 .583 3 7 .429 6 6 12 1 7-0 3 0 17 2.4 LANCE ALLRED Height: 6’11” Weight: 250 Born: February 2, 1981 (Weber State ‘05) Signed as a free agent by the Cavaliers on April 4, 2008 and signed 10-day contracts on March 13 and March 25, 2008. YEAR GP MINS FGM FGA FG% FTM FTA FT% OR DR TR AST PF-D STL BS PTS PPG 2007-08 3 10 1 4 .250 1 2 .500 0 1 1 0 1-0 0 0 3 1.0 JOHN AMAECHI Height: 6’10” Weight: 270 Born: November 26, 1970 (Penn State ’95) Signed as a free agent, October 5, 1995. -

2009-10 NCAA Men's Basketball Records (Division I)
Division I Records Individual Records ....................................... 12 Team Records ................................................ 14 All-Time Individual Leaders ..................... 17 Top 10 Individual Scoring Leaders ....... 30 Annual Individual Champions ............... 34 Miscellaneous Player Information ........ 37 All-Time Team Leaders ............................... 37 Annual Team Champions ......................... 46 Statistical Trends ........................................... 52 All-Time Winningest Teams ..................... 53 Vacated and Forfeited Games ................ 56 Winningest Teams By Decade ................ 57 Winningest Teams Over Periods of Time ......................................... 58 Winning Streaks ............................................ 59 Rivalries ............................................................ 60 Associated Press (A.P.) Poll Records ..... 61 Week-by-Week A.P. Polls ........................... 68 Final Season Polls ......................................... 84 12 Individual Records Individual Records Basketball records are confined to the “modern COMBINED POINTS, TwO TEAMMATES era,” which began with the 1937-38 season, the VS. DIVISION I OPPONENT Three-Point Field Goals first without the center jump after each goal Game THRee-PoINT FIELD GOALS scored. Except for the school’s all-time won-lost 92—Kevin Bradshaw (72) and Isaac Brown (20), Alliant Int’l vs. Loyola Marymount, Jan. 5, 1991 Game record or coaches’ records, only statistics achieved 15—Keith Veney, Marshall vs. -

When Is a Basket Not a Basket? the Basket Either Was Made Before the Clock Expired Or Nswer: When 3 the Protest by After
“Local name, national Perspective” $3.95 © Volume 4 Issue 6 NBA PLAYOFFS SPECIAL April 1998 BASKETBALL FOR THOUGHT by Kris Gardner, e-mail: [email protected] A clock was involved; not a foul or a violation of the rules. When is a Basket not a Basket? The basket either was made before the clock expired or nswer: when 3 The protest by after. The clock provides tan- officials and deter- the losing gible proof. This wasn’t a commissioner mina- team. "The charge or block call. Period. David Stern tion as Board of No gray area here. say so. to Governors Secondly, it’s time the Sunday, April 12, the whethe has not league allows officials to use Knicks apparently defeated r a ball seen fit to replay when dealing with is- the Miami Heat 83 - 82, on a is shot adopt such sues involving the clock. It’s last second rebound by G prior a rule," the sad that the entire viewing Allan Houston. Replays to the Commis- audience could see replays showed Allan scored the bas- expira- sioner showing the basket should be ket with 2 tenths of a second tion of stated, allowed and not the 3 most on the clock. However, offi- time, "although important people—the refer- cials disagreed. They hud- Stern © ees calling the game! Ironi- dled after the shot for 30 "...although the subject has been considered from time to cally, the officials viewed the seconds to determine if they time. Until it does so, such is not the function of the replays in the locker after the were all in agreement. -

Name Nba Club Aau Association College Year
NAME NBA CLUB AAU ASSOCIATION COLLEGE YEAR A.J Guydon Chicago Bulls Central Indiana 2000 Acie Earl Boston Celtics Iowa 1989 Al Harrington Al Jefferson Alaa Abdlnaby Portland New Jersey Duke 1986 Albert King New Jersey Nets Metropolitan Maryland 1977 Allan Ray Allen Iverson Philadelphia '76er Virginia Georgetown 1993 Alonzo Mourning Miami Heat Virginia Georgetown 1988 Amare Stoudemire Phoenix Sun Florida Cypress Creek H.S 2000 Amir Johnson Andre Barrett Andre Brown Andre Miller Andrew Bynum LA Lakers New Jersey Andrew Lang Phoenix Sun Arkansas Arkansas 1984 Anfernee Hardaway Orlando Magic Southeastern University of Memphis 1990 Antawn Jamison Washington Wizards North Carolina North Carolina 1995 Anthony Avent Atlanta Hawks New Jersey Seton Hall 1987 Anthony Parker Orlando Magic Central Bradley Anthony Peeler Toronto Kansas Missouri 1987 Antoine Walker Boston Celtics Central Kentucky 1993 B.J. Armstrong Chicago Bulls Iowa 1985 Baron Davis Charlotte Hornets UCLA 1996 Ben Gordon Chicago Bulls UCONN Billy King Indiana Pacers Potomac Valley Duke 1981 Billy Thompson LA Lakers 1981 Blair Rasmussen Denver Nuggets Inland Empire Oregon 1981 Bob Sura Florida State Bobby Hansen Sacramento Kings Iowa Iowa 1983 Bobby Hurley Sacramento Metropolitan Duke 1987 Bracey Wright Indiana Indiana Brad LoHaus Iowa 1982 Brandon Bass Southern-LA LSU Brendan Haywood Washington Wizards North Carolina North Carolina 1998 NAME NBA CLUB AAU ASSOCIATION COLLEGE YEAR Brevin Knight Brian Cardinal Central Purdue 2000 Brian Cook LA Lakers Illinois Brian Evans Orlando Magic Indiana Indiana Brian Oliver Philadelphia '76er Georgia Georgia Tech Brian Quinnett New York Knicks Inland Empire Washinghton St. Bryant Stith Denver Nuggets Virginia Virginia 1987 Byron Houston Oklahoma Oklahoma State 1986 C.J. -

MA#12Jumpingconclusions Old Coding
Mathematics Assessment Activity #12: Mathematics Assessed: · Ability to support or refute a claim; Jumping to Conclusions · Understanding of mean, median, mode, and range; · Calculation of mean, The ten highest National Basketball League median, mode and salaries are found in the table below. Numbers range; like these lead us to believe that all professional · Problem solving; and basketball players make millions of dollars · Communication every year. While all NBA players make a lot, they do not all earn millions of dollars every year. NBA top 10 salaries for 1999-2000 No. Player Team Salary 1. Shaquille O'Neal L.A. Lakers $17.1 million 2. Kevin Garnett Minnesota Timberwolves $16.6 million 3. Alonzo Mourning Miami Heat $15.1 million 4. Juwan Howard Washington Wizards $15.0 million 5. Patrick Ewing New York Knicks $15.0 million 6. Scottie Pippen Portland Trail Blazers $14.8 million 7. Hakeem Olajuwon Houston Rockets $14.3 million 8. Karl Malone Utah Jazz $14.0 million 9. David Robinson San Antonio Spurs $13.0 million 10. Jayson Williams New Jersey Nets $12.4 million As a matter of fact according to data from USA Today (12/8/00) and compiled on the website “Patricia’s Basketball Stuff” http://www.nationwide.net/~patricia/ the following more accurately reflects the salaries across professional basketball players in the NBA. 1 © 2003 Wyoming Body of Evidence Activities Consortium and the Wyoming Department of Education. Wyoming Distribution Ready August 2003 Salaries of NBA Basketball Players - 2000 Number of Players Salaries 2 $19 to 20 million 0 $18 to 19 million 0 $17 to 18 million 3 $16 to 17 million 1 $15 to 16 million 3 $14 to 15 million 2 $13 to 14 million 4 $12 to 13 million 5 $11 to 12 million 15 $10 to 11 million 9 $9 to 10 million 11 $8 to 9 million 8 $7 to 8 million 8 $6 to 7 million 25 $5 to 6 million 23 $4 to 5 million 41 3 to 4 million 92 $2 to 3 million 82 $1 to 2 million 130 less than $1 million 464 Total According to this source the average salaries for the 464 NBA players in 2000 was $3,241,895. -

Stephen Curry Reading Comprehension Name___Stephen Curry Is a Basketball Player
Stephen Curry Reading Comprehension Name_______________________ Stephen Curry is a basketball player for the Golden State Warriors and was the first person to be named Most Valuable Player by unanimous vote in NBA history. He was born on March 14, 1988, and grew up in Charlotte, North Carolina. Curry is the son of former NBA player Dell Curry, and he learned the basics of basketball from playing with his father. While his father was on road trips playing with his team, Curry’s mother Sonya, a former Division I volleyball athlete, encouraged him to keep playing and honing his skills in the game. Curry went to Davidson College and impressed with his talents in shooting and ball- handling. In 2009, he was drafted to play for the Golden State Warriors. After 2010, he averaged more than 22 points per game, and finished second in balloting for Rookie of the Year. Curry clinched a spot on the USA Men’s Basketball Senior National Team, and won a gold medal at the 2010 World Championships. In 2012, he continued his upward trajectory by setting an NBA record of 272 three-pointers. In 2014, Curry and his fellow teammate Klay Thompson led the warriors to an early 16- game win streak. They were hailed as the Splash Brothers due to their incredible shooting accuracy; their shots always “splashed” into the net. Curry led the Warriors to an NBA championship in 2015—the team’s first championship since 1975. In May 2016, he became the first person to be named MVP by a unanimous vote. -

2013 Retrospective FINAL
A LOOK BACK AT THE McDONALD’S ALL AMERICAN® GAMES SUPERSTARS AND UNFORGETTABLE MEMORIES FROM GAMES PAST You’ve seen them on TV and at the movies, in the NBA, WNBA and college ranks – McDonald’s All American alumni are household names to basketball fans. But before they were winning Olympic gold medals, NBA, WNBA and NCAA championships, many of them received their first major national television exposure as high school students at the McDonald’s All American Games. Since the Games inception, more than 1,000 prep stars have been named McDonald’s All Americans and had the opportunity to show off their skills on a national stage before reaching the college or professional ranks. Most importantly, the Games raise funds for Ronald McDonald House Charities® (RMHC®) and its network of local Chapters. To date, the McDonald’s All American Games have raised more than $10 million for RMHC, helping to bring families together in their time of need. As we look forward to celebrating the 37th Anniversary of the McDonald’s All American Boys Game and the 13th Anniversary of the Girls Game on April 2, 2014 in Chicago, Ill., the following is a brief look back at highlights from the past 36 years of McDonald’s All American Games, including funds raised for RMHC: Chicago, Ill. 2013 For the third year in a row, the 2013 McDonald’s All American Games took place at Chicago’s United Center. The 2013 Games raised nearly $470,000 for Ronald McDonald House Charities and were played in front of a crowd of 15,818.