The Women's Health Initiative, Cohort Studies, and the Population
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
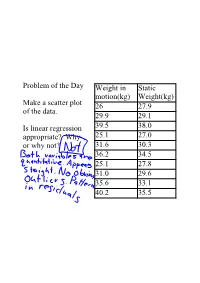
Problem of the Day Make a Scatter Plot of the Data. Is Linear Regression
Problem of the Day Weight in Static motion(kg) Weight(kg) Make a scatter plot 26 27.9 of the data. 29.9 29.1 Is linear regression 39.5 38.0 appropriate? Why 25.1 27.0 or why not? 31.6 30.3 36.2 34.5 25.1 27.8 31.0 29.6 35.6 33.1 40.2 35.5 Salary(in Problem of the Day Player Year millions) Nolan Ryan 1980 1.0 Is it appropriate to use George Foster 1982 2.0 linear regression Kirby Puckett 1990 3.0 to predict salary Jose Canseco 1991 4.7 from year? Roger Clemens 1996 5.3 Why or why not? Ken Griffey, Jr 1997 8.5 Albert Belle 1997 11.0 Pedro Martinez 1998 12.5 Mike Piazza 1999 12.5 Mo Vaughn 1999 13.3 Kevin Brown 1999 15.0 Carlos Delgado 2001 17.0 Alex Rodriguez 2001 22.0 Manny Ramirez 2004 22.5 Alex Rodriguez 2005 26.0 Chapter 10 ReExpressing Data: Get It Straight! Linear Regressioneasiest of methods, how can we make our data linear in appearance Can we reexpress data? Change functions or add a function? Can we think about data differently? What is the meaning of the yunits? Why do we need to reexpress? Methods to deal with data that we have learned 1. 2. Goal 1 making data symmetric Goal 2 make spreads more alike(centers are not necessarily alike), less spread out Goal 3(most used) make data appear more linear Goal 4(similar to Goal 3) make the data in a scatter plot more spread out Ladder of Powers(pg 227) Straightening is good, but limited multimodal data cannot be "straightened" multiple models is really the only way to deal with this data Things to Remember we want linear regression because it is easiest (curves are possible, but beyond the scope of our class) don't choose a model based on r or R2 don't go too far from the Ladder of Powers negative values or multimodal data are difficult to reexpress Salary(in Player Year Find an appropriate millions) Nolan Ryan 1980 1.0 linear model for the George Foster 1982 2.0 data. -

DONNA LEINWAND: (Sounds Gavel.) Good Afternoon and Welcome to the National Press Club. My Name Is Donna Leinwand. I'm a Repor
NATIONAL PRESS CLUB LUNCHEON WITH JEFF IDELSON SUBJECT: JEFF IDELSON, PRESIDENT OF THE NATIONAL BASEBALL HALL OF FAME, IS SCHEDULED TO SPEAK AT A NATIONAL PRESS CLUB LUNCHEON MAY 11. HALL OF FAME THIRD BASEMAN BROOKS ROBINSON WILL BE A SPECIAL GUEST. MODERATOR: DONNA LEINWAND, PRESIDENT, NATIONAL PRESS CLUB LOCATION: NATIONAL PRESS CLUB BALLROOM, WASHINGTON, D.C. TIME: 1:00 P.M. EDT DATE: MONDAY, MAY 11, 2009 (C) COPYRIGHT 2009, NATIONAL PRESS CLUB, 529 14TH STREET, WASHINGTON, DC - 20045, USA. ALL RIGHTS RESERVED. ANY REPRODUCTION, REDISTRIBUTION OR RETRANSMISSION IS EXPRESSLY PROHIBITED. UNAUTHORIZED REPRODUCTION, REDISTRIBUTION OR RETRANSMISSION CONSTITUTES A MISAPPROPRIATION UNDER APPLICABLE UNFAIR COMPETITION LAW, AND THE NATIONAL PRESS CLUB. RESERVES THE RIGHT TO PURSUE ALL REMEDIES AVAILABLE TO IT IN RESPECT TO SUCH MISAPPROPRIATION. FOR INFORMATION ON BECOMING A MEMBER OF THE NATIONAL PRESS CLUB, PLEASE CALL 202-662-7505. DONNA LEINWAND: (Sounds gavel.) Good afternoon and welcome to the National Press Club. My name is Donna Leinwand. I’m a reporter at USA Today and I’m president of the National Press Club. We’re the world’s leading professional organization for journalists and are committed to a future of journalism by providing informative programming, journalism education and fostering a free press worldwide. For more information about the National Press Club, please visit our website at www.press.org. On behalf of our 3,500 members worldwide, I’d like to welcome our speaker and our guests in the audience today. I’d also like to welcome those of you who are watching us on C-Span. We’re looking forward to today’s speech, and afterwards, I’ll ask as many questions from the audience as time permits. -

Download Preview
DETROIT TIGERS’ 4 GREATEST HITTERS Table of CONTENTS Contents Warm-Up, with a Side of Dedications ....................................................... 1 The Ty Cobb Birthplace Pilgrimage ......................................................... 9 1 Out of the Blocks—Into the Bleachers .............................................. 19 2 Quadruple Crown—Four’s Company, Five’s a Multitude ..................... 29 [Gates] Brown vs. Hot Dog .......................................................................................... 30 Prince Fielder Fields Macho Nacho ............................................................................. 30 Dangerfield Dangers .................................................................................................... 31 #1 Latino Hitters, Bar None ........................................................................................ 32 3 Hitting Prof Ted Williams, and the MACHO-METER ......................... 39 The MACHO-METER ..................................................................... 40 4 Miguel Cabrera, Knothole Kids, and the World’s Prettiest Girls ........... 47 Ty Cobb and the Presidential Passing Lane ................................................................. 49 The First Hammerin’ Hank—The Bronx’s Hank Greenberg ..................................... 50 Baseball and Heightism ............................................................................................... 53 One Amazing Baseball Record That Will Never Be Broken ...................................... -

The Organizational Life of the College Football Player: an Exploration of Injury
The Organizational Life of the College Football Player: An Exploration of Injury, Football Culture, and Organizational Dialectics A dissertation presented to the faculty of the Scripps College of Communication of Ohio University In partial fulfillment of the requirements for the degree Doctor of Philosophy Kenneth M. Sibal June 2011 © 2011 Kenneth M. Sibal. All Rights Reserved. This dissertation titled The Organizational Life of the College Football Player: An Exploration of Injury, Football Culture, and Organizational Dialectics by KENNETH M. SIBAL has been approved for the School of Communication Studies and the Scripps College of Communication by Claudia L. Hale Professor of Communication Studies Gregory J. Shepherd Dean, Scripps College of Communication ii ABSTRACT SIBAL, KENNETH M., Ph.D., June 2011, Communication Studies The Organizational Life of the College Football Player: An Exploration of Injury, Football Culture, and Organizational Dialectics Director of Dissertation: Claudia L. Hale This dissertation attempts to better understand the lives of college football players. The project begins with the assumption that the ways individuals talk about their experiences have a significant impact on others. An organizational framework is used to appreciate the central importance of communication in coordinating organizational relationships and developing impressions. College football players were gathered from three separate institutions representing different competitive levels of college football. Through interviews, participants were invited to provide stories that reflected their understandings of what it means to play college football. Because the intent of this study was to better understand issues related to the culture of playing football, common themes were derived from those interviews in an attempt to answer four separate research questions. -

MLB Curt Schilling Red Sox Jersey MLB Pete Rose Reds Jersey MLB
MLB Curt Schilling Red Sox jersey MLB Pete Rose Reds jersey MLB Wade Boggs Red Sox jersey MLB Johnny Damon Red Sox jersey MLB Goose Gossage Yankees jersey MLB Dwight Goodin Mets jersey MLB Adam LaRoche Pirates jersey MLB Jose Conseco jersey MLB Jeff Montgomery Royals jersey MLB Ned Yost Royals jersey MLB Don Larson Yankees jersey MLB Bruce Sutter Cardinals jersey MLB Salvador Perez All Star Royals jersey MLB Bubba Starling Royals baseball bat MLB Salvador Perez Royals 8x10 framed photo MLB Rolly Fingers 8x10 framed photo MLB Joe Garagiola Cardinals 8x10 framed photo MLB George Kell framed plaque MLB Salvador Perez bobblehead MLB Bob Horner helmet MLB Salvador Perez Royals sports drink bucket MLB Salvador Perez Royals sports drink bucket MLB Frank White and Willie Wilson framed photo MLB Salvador Perez 2015 Royals World Series poster MLB Bobby Richardson baseball MLB Amos Otis baseball MLB Mel Stottlemyre baseball MLB Rod Gardenhire baseball MLB Steve Garvey baseball MLB Mike Moustakas baseball MLB Heath Bell baseball MLB Danny Duffy baseball MLB Frank White baseball MLB Jack Morris baseball MLB Pete Rose baseball MLB Steve Busby baseball MLB Billy Shantz baseball MLB Carl Erskine baseball MLB Johnny Bench baseball MLB Ned Yost baseball MLB Adam LaRoche baseball MLB Jeff Montgomery baseball MLB Tony Kubek baseball MLB Ralph Terry baseball MLB Cookie Rojas baseball MLB Whitey Ford baseball MLB Andy Pettitte baseball MLB Jorge Posada baseball MLB Garrett Cole baseball MLB Kyle McRae baseball MLB Carlton Fisk baseball MLB Bret Saberhagen baseball -

Clips for 7-12-10
MEDIA CLIPS – Jan. 23, 2019 Walker short in next-to-last year on HOF ballot Former slugger receives 54.6 percent of vote; Helton gets 16.5 percent in first year of eligibility Thomas Harding | MLB.com | Jan. 22, 2019 DENVER -- Former Rockies star Larry Walker introduced himself under a different title during his conference call with Denver media on Tuesday: "Fifty-four-point-six here." That's the percentage of voters who checked Walker in his ninth year of 10 on the Baseball Writers' Association of America Hall of Fame ballot. It's a dramatic jump from his previous high, 34.1 percent last year -- an increase of 88 votes. However, he's going to need an 87-vote leap to reach the requisite 75 percent next year, his final season of eligibility. Jayson Stark of the Athletic noted during MLB Network's telecast that the only player to receive a jump of at least 80 votes in successive years was former Reds shortstop Barry Larkin, who was inducted in 2012. But when publicly revealed ballots had him approaching the mid-60s in percentage, Walker admitted feeling excitement he hadn't experienced in past years. "I haven't tuned in most years because there's been no chance of it really happening," Walker said. "It was nice to see this year, to watch and to have some excitement involved with it. "I was on Twitter and saw the percentages that were getting put out there for me. It made it more interesting. I'm thankful to be able to go as high as I was there before the final announcement." When discussing the vote, one must consider who else is on the ballot. -

* Text Features
The Boston Red Sox Saturday, April 18, 2020 * The Boston Globe Fenway Park is ready to play ball, even though we are not Stan Grossfeld The grass is perfect and the old ballpark is squeaky clean — it was scrubbed and disinfected for viral pathogens for three days in March. Spending a few hours at Fenway Park is good for the soul. The ballpark is totally silent. The mound and home plate are covered by tarps and the foul lines aren’t drawn yet, but it feels as if there still could be a game played today. The sun’s warmth reflecting off The Wall feels good. The tug of the past is all around but the future is the great unknown. In Fenway, zoom is still a word to describe a Chris Sale fastball, not a video conferencing app. Old friend Terry Francona and the Cleveland Indians would have been here this weekend and there would’ve been big hugs by the batting cage and the rhythmic crack of bat meeting ball. But now gaining access is nearly impossible and includes health questions and safety precautions and a Fenway security escort. Visitors must wear a respiratory mask, gloves, and practice social distancing, larger than the lead Dave Roberts got on Mariano Rivera in the 2004 ALCS. Carissa Unger of Green City Growers in Somerville is planting organic vegetables for Fenway Farms, located on the rooftop of the park. She is one of the few allowed into the ballpark. The harvest this year all will be donated to a local food pantry. -

2012 Game-By-Game by the Numbers…
Here are some interesting facts about 2012 American League Cy Young candidate Felix Hernandez... • 2012 Season – Is 13-6 with an American League leading 2.51 ERA in 28 starts this season…leads the AL in shutouts (5), 2nd in innings pitched (204.0) and complete games (5), 3rd in strikeouts (191) and By the Numbers… opponent avg (.222), T4th in quality starts (19), T8th in wins (13) and 9th with 8.43 K/9.0 IP. • Domination – Over his last 15 starts is 9-1 with a 1.62 ERA (21 ER, 116.1 IP), 5 shutouts, 107 2.51 American League leading ERA strikeouts (8.28 K/9.0 IP) and a .191 opponent batting average (79x413) – only 2 HR allowed…suffered loss in his last start Sept. 1 vs. LAA (7.1,9,5,4,2,7), his first defeat since June 12. 5 Shutouts to lead the AL • Perfect Game – Threw the 23rd Perfect Game in MLB history Aug. 15 vs. Tampa Bay in a 1-0 victory…it was the 7th Perfect Game in MLB history to be decided in a 1-0 contest, and first in the Major League leading 11 starts AL since 1984…struck out 12 batters, 4th-most in a PG. 11 allowing 1 or fewer R in 8.0+ IP • Shutouts – Leads the Majors with 5 shutouts, all coming over his last 13 starts (6/28 vs. BOS, 7/14 vs. TEX, 8/4 at NYY, 8/15 vs. TB, 8/27 at MIN)…is the first pitcher since Randy Johnson in 1998 to 23 23rd Perfect Game in MLB record 5+ shutouts in a 12-start span…has set a Mariners club record for a single season…joins Bert history thrown 8/15 vs. -
Printer-Friendly Version (PDF)
NAME STATISTIC NAME STATISTIC Jim Abbott No-Hitter 9/4/93 Ralph Branca 3x All-Star Bobby Abreu 2005 HR Derby Champion; 2x All-Star George Brett Hall of Fame - 1999 Tommie Agee 1966 AL Rookie of the Year Lou Brock Hall of Fame - 1985 Boston #1 Overall Prospect-Named 2008 Boston Minor Lars Anderson Tom Browning Perfect Game 9/16/88 League Off. P.O.Y. Sparky Anderson Hall of Fame - 2000 Jay Bruce 2007 Minor League Player of the Year Elvis Andrus Texas #1 Overall Prospect -shortstop Tom Brunansky 1985 All-Star; 1987 WS Champion Luis Aparicio Hall of Fame - 1984 Bill Buckner 1980 NL Batting Champion Luke Appling Hall of Fame - 1964 Al Bumbry 1973 AL Rookie of the Year Richie Ashburn Hall of Fame - 1995 Lew Burdette 1957 WS MVP; b. 11/22/26 d. 2/6/07 Earl Averill Hall of Fame - 1975 Ken Caminiti 1996 NL MVP; b. 4/21/63 d. 10/10/04 Jonathan Bachanov Los Angeles AL Pitching prospect Bert Campaneris 6x All-Star; 1st to Player all 9 Positions in a Game Ernie Banks Hall of Fame - 1977 Jose Canseco 1986 AL Rookie of the Year; 1988 AL MVP Boston #4 Overall Prospect-Named 2008 Boston MiLB Daniel Bard Steve Carlton Hall of Fame - 1994 P.O.Y. Philadelphia #1 Overall Prospect-Winning Pitcher '08 Jesse Barfield 1986 All-Star and Home Run Leader Carlos Carrasco Futures Game Len Barker Perfect Game 5/15/81 Joe Carter 5x All-Star; Walk-off HR to win the 1993 WS Marty Barrett 1986 ALCS MVP Gary Carter Hall of Fame - 2003 Tim Battle New York AL Outfield prospect Rico Carty 1970 Batting Champion and All-Star 8x WS Champion; 2 Bronze Stars & 2 Purple Hearts Hank -

The Auction List
Ephrata Lions Club Sports Card Show & Auction – 2:30 p.m., Saturday, October 23, 2021 Ephrata (PA) Recreation Center – Page 1 of 2 Lot Description Lot Description Lot Description Misc. Baseball, Basketball, Hockey 44 Matted New York Yankees 1958 Train Excursion Flyers 88 Auto. Navy Midshipmen Jersey Keenan Reynolds w/ COA-JSA 1 3 Mountain Dew Baseball Stand-ups 45 Babe Ruth and Mickey Mantle Handmade Wooden Plaques w/Career Stats 89 Auto. Steelers Jersey Joey Porter w/ COA-JSA 2 1970s Baltimore Oriole "The Bird" Stuffed Animal & Oriole Logo Mini BB Bat 46 Mickey Mantle Comic Book Graded CGC 9.4 90 Auto. Steelers Jersey Ernie Mills w/ COA-JSA 3 1960s Jim "Catfish" Hunter Signature Endorsed Padded Gun Case Autographed Baseball Items, Photos/Cards 91 Auto. NY Jets Jersey Don Maynard w/ COA-JSA 4 Ted Williams Box of Sears Shotgun Shells and '70s Ted's Root Beer Glass 47 Auto. 8x10 Photos (2) Johnny VanderMeer w/ Auto. Ticket 92 Auto. Warriors Jersey Rick Barry w/ COA-JSA 5 7 1962 Auravision 33 RPM Records w/ Maris, Koufax, Kaline et al. 48 Auto. Photo Willie Mays WS. "The Catch" w/ "Say Hey" Authentication Cert. 93 Auto. Yankees Jersey Bobby Shantz w/ COA-JSA 6 1990 Matchbox MLB Car Set w/ 26 Team Cars in Plastic Display Case 49 Auto. 8x10 Photo Don Newcombe (Deceased)*From Mr Mint/Alan Rosen 94 Auto. Phillies Jersey Rhys Hoskins w/ COA-Hunt Auction 7 1999 M. Jordan UD 19x19 Mobile Hanger w/4 Cards, 4 MJ Silhouettes 50 Auto. 8x10 Photo Al Gionfriddo (Deceased) Pittsburgh & Brooklyn *Mr Mint 95 Auto. -

Hyundai Becomes the First Official Sponsor of Triplea Baseball
Hyundai Motor America 10550 Talbert Ave, Fountain Valley, CA 92708 MEDIA WEBSITE: HyundaiNews.com CORPORATE WEBSITE: HyundaiUSA.com FOR IMMEDIATE RELEASE TRIPLEA BASEBALL HITS A HOME RUN WITH HYUNDAI Miles Johnson Senior Manager, Quality, Service and Technology (714) 3661048 [email protected] ID: 28839 Hyundai Becomes the First Official Sponsor of TripleA Baseball DUBLIN, April 18, 2006– TripleA Baseball today announced a first in its storied 120year history by making Hyundai Motor America its official automotive sponsor. The exclusive sponsorship swings into full gear in May. “With an alltime high attendance of 14.1 million fans in 2005, TripleA Baseball is the fifth most attended professional sport in the United States,” said Michelle Cervantez, vice president of marketing for Hyundai Motor America. “TripleA Baseball fans align perfectly with Hyundai owners – they are fun, familyoriented and appreciate a good value. We are thrilled to position the Hyundai brand with baseball played by tomorrow’s big league stars, today.” Hyundai will bring its sponsorship to life via a fully integrated program for each participating teams including: Five “Hyundai Sundays” at each ballpark (125 in all) will feature interactive car displays in which fans can check out new Hyundai Sonatas and Tucsons with a chance to win a brandnew Sonata through the “Hyundai Home Run Challenge.” Hyundai will also conduct rideanddrives on select Sundays so fans can get behind the wheel and experience the satisfaction of driving a Hyundai for themselves. Title sponsorship of the “Hyundai Legends of TripleA Baseball” program, marking the first time its “legends” will be nationally recognized in league history. -

Sports Figures Price Guide
SPORTS FIGURES PRICE GUIDE All values listed are for Mint (white jersey) .......... 16.00- David Ortiz (white jersey). 22.00- Ching-Ming Wang ........ 15 Tracy McGrady (white jrsy) 12.00- Lamar Odom (purple jersey) 16.00 Patrick Ewing .......... $12 (blue jersey) .......... 110.00 figures still in the packaging. The Jim Thome (Phillies jersey) 12.00 (gray jersey). 40.00+ Kevin Youkilis (white jersey) 22 (blue jersey) ........... 22.00- (yellow jersey) ......... 25.00 (Blue Uniform) ......... $25 (blue jersey, snow). 350.00 package must have four perfect (Indians jersey) ........ 25.00 Scott Rolen (white jersey) .. 12.00 (grey jersey) ............ 20 Dirk Nowitzki (blue jersey) 15.00- Shaquille O’Neal (red jersey) 12.00 Spud Webb ............ $12 Stephen Davis (white jersey) 20.00 corners and the blister bubble 2003 SERIES 7 (gray jersey). 18.00 Barry Zito (white jersey) ..... .10 (white jersey) .......... 25.00- (black jersey) .......... 22.00 Larry Bird ............. $15 (70th Anniversary jersey) 75.00 cannot be creased, dented, or Jim Edmonds (Angels jersey) 20.00 2005 SERIES 13 (grey jersey ............... .12 Shaquille O’Neal (yellow jrsy) 15.00 2005 SERIES 9 Julius Erving ........... $15 Jeff Garcia damaged in any way. Troy Glaus (white sleeves) . 10.00 Moises Alou (Giants jersey) 15.00 MCFARLANE MLB 21 (purple jersey) ......... 25.00 Kobe Bryant (yellow jersey) 14.00 Elgin Baylor ............ $15 (white jsy/no stripe shoes) 15.00 (red sleeves) .......... 80.00+ Randy Johnson (Yankees jsy) 17.00 Jorge Posada NY Yankees $15.00 John Stockton (white jersey) 12.00 (purple jersey) ......... 30.00 George Gervin .......... $15 (whte jsy/ed stripe shoes) 22.00 Randy Johnson (white jersey) 10.00 Pedro Martinez (Mets jersey) 12.00 Daisuke Matsuzaka ....