Rapid Screening of Keyboard Layouts
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Manual LEIBINGER JET2 Neo
Manual LEIBINGER JET2 neo Release R1.00e Group 1 Table of contents Page 1 1.1 Table of contents 1.1 Table of contents ..........................................................................................................1 1.2 Group directory.............................................................................................................9 1.3 Publisher.....................................................................................................................10 1.4 Introduction.................................................................................................................12 1.5 Document information.................................................................................................13 1.6 Guarantee...................................................................................................................13 2. Safety ..............................................................................................................................14 2.1 Dangers......................................................................................................................14 2.2 Safety instructions and recommendations...................................................................14 2.3 Intended use...............................................................................................................16 2.4 Safety sticker ..............................................................................................................17 2.5 Operating staff ............................................................................................................18 -

The Origin of the Peculiarities of the Vietnamese Alphabet André-Georges Haudricourt
The origin of the peculiarities of the Vietnamese alphabet André-Georges Haudricourt To cite this version: André-Georges Haudricourt. The origin of the peculiarities of the Vietnamese alphabet. Mon-Khmer Studies, 2010, 39, pp.89-104. halshs-00918824v2 HAL Id: halshs-00918824 https://halshs.archives-ouvertes.fr/halshs-00918824v2 Submitted on 17 Dec 2013 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Published in Mon-Khmer Studies 39. 89–104 (2010). The origin of the peculiarities of the Vietnamese alphabet by André-Georges Haudricourt Translated by Alexis Michaud, LACITO-CNRS, France Originally published as: L’origine des particularités de l’alphabet vietnamien, Dân Việt Nam 3:61-68, 1949. Translator’s foreword André-Georges Haudricourt’s contribution to Southeast Asian studies is internationally acknowledged, witness the Haudricourt Festschrift (Suriya, Thomas and Suwilai 1985). However, many of Haudricourt’s works are not yet available to the English-reading public. A volume of the most important papers by André-Georges Haudricourt, translated by an international team of specialists, is currently in preparation. Its aim is to share with the English- speaking academic community Haudricourt’s seminal publications, many of which address issues in Southeast Asian languages, linguistics and social anthropology. -

Daniel O'connell
Daniel O’Connell 708 Hoover St., Norman OK 73072 (405) 820-6218 – [email protected] EDUCATION ACCELERATED DUAL DEGREE PROGRAM: Completing Petroleum Engineering undergraduate Degree and an MBA concurrently Michael F. Price College of Business, University of Oklahoma Norman, OK Master of Business Administration; GPA: 4.0/4.0 May 2018 Training the Street; Two-Day Financial Modeling Seminar Mewbourne College of Earth and Energy, University of Oklahoma Norman, OK Bachelor of Science in Petroleum Engineering; GPA: 3.4/4.0 May 2018 EXPERIENCE May 2017- Gulfport Energy Oklahoma City, OK August 2017 Reservoir Engineering, (Internship) Forecasted oil, gas, and water production and revenues for all PDP wells within ARIES Quantified the effect of compression and spacing on already producing wells Created a water type-curve lookup table within ARIES, based on correlations found in Spotfire, to be used in water production forecasting for new wells drilled in the Utica January 2017- OU Center for Creation of Economic Wealth (CCEW) Norman, OK May 2017 Oklahoma Funding Accelerator Consulting Associate (Internship) Semester-long internship working closely with local Oklahoma City startup, SendARide, on business model generation, business plan creation, financial projections, and loan proposal preparation Researched and suggested top priority candidates for adoption of the SendARide app Explored healthcare regulations for possible limitations and opportunities for success May 2016- LINN Energy Agua Dulce, TX August 2016 Production Engineering, -

Ligature Modeling for Recognition of Characters Written in 3D Space Dae Hwan Kim, Jin Hyung Kim
Ligature Modeling for Recognition of Characters Written in 3D Space Dae Hwan Kim, Jin Hyung Kim To cite this version: Dae Hwan Kim, Jin Hyung Kim. Ligature Modeling for Recognition of Characters Written in 3D Space. Tenth International Workshop on Frontiers in Handwriting Recognition, Université de Rennes 1, Oct 2006, La Baule (France). inria-00105116 HAL Id: inria-00105116 https://hal.inria.fr/inria-00105116 Submitted on 10 Oct 2006 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Ligature Modeling for Recognition of Characters Written in 3D Space Dae Hwan Kim Jin Hyung Kim Artificial Intelligence and Artificial Intelligence and Pattern Recognition Lab. Pattern Recognition Lab. KAIST, Daejeon, KAIST, Daejeon, South Korea South Korea [email protected] [email protected] Abstract defined shape of character while it showed high recognition performance. Moreover when a user writes In this work, we propose a 3D space handwriting multiple stroke character such as ‘4’, the user has to recognition system by combining 2D space handwriting write a new shape which is predefined in a uni-stroke models and 3D space ligature models based on that the and which he/she has never seen. -
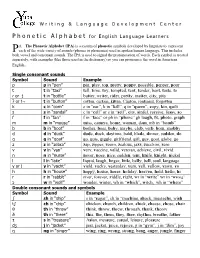
Writing & Language Development Center Phonetic Alphabet for English Language Learners Pin, Play, Top, Pretty, Poppy, Possibl
Writing & Language Development Center Phonetic Alphabet f o r English Language Learners A—The Phonetic Alphabet (IPA) is a system of phonetic symbols developed by linguists to represent P each of the wide variety of sounds (phones or phonemes) used in spoken human language. This includes both vowel and consonant sounds. The IPA is used to signal the pronunciation of words. Each symbol is treated separately, with examples (like those used in the dictionary) so you can pronounce the word in American English. Single consonant sounds Symbol Sound Example p p in “pen” pin, play, top, pretty, poppy, possible, pepper, pour t t in “taxi” tell, time, toy, tempted, tent, tender, bent, taste, to ɾ or ţ t in “bottle” butter, writer, rider, pretty, matter, city, pity ʔ or t¬ t in “button” cotton, curtain, kitten, Clinton, continent, forgotten k c in “corn” c in “car”, k in “kill”, q in “queen”, copy, kin, quilt s s in “sandal” c in “cell” or s in “sell”, city, sinful, receive, fussy, so f f in “fan” f in “face” or ph in “phone” gh laugh, fit, photo, graph m m in “mouse” miss, camera, home, woman, dam, mb in “bomb” b b in “boot” bother, boss, baby, maybe, club, verb, born, snobby d d in “duck” dude, duck, daytime, bald, blade, dinner, sudden, do g g in “goat” go, guts, giggle, girlfriend, gift, guy, goat, globe, go z z in “zebra” zap, zipper, zoom, zealous, jazz, zucchini, zero v v in “van” very, vaccine, valid, veteran, achieve, civil, vivid n n in “nurse” never, nose, nice, sudden, tent, knife, knight, nickel l l in “lake” liquid, laugh, linger, -

Rgreekl2.Ttf © Copyright 2006 Vernon Eugene Kooy Phd This Font Is An
Rgreekl2.ttf © Copyright 2006 Vernon Eugene Kooy PhD This font is an expanded version of earlier versions, hence named Rgreekl2, which stands for Renaissance Greek with Ligatures version 2.0. It is a large font with approximately 960 glyphs and uses Unicode WGL4 numbering to accommodate the number of characters. However, semantically It is not a Unicode font. It is beta encoded similar to other Greek fonts which use beta encoding. This font is freeware and may be used and distributed freely. I retain the copyright however, in order to make improvements, expand it, or otherwise come out with an improved version. It is not an imitation of any particular font such as those of Robert Estienne, Holbein or Aldus Manutius. It is rather a composite font which incorporates many glyphs (sorts) from each of the many early printers. It is hoped that this font gains a modest distribution and not be a mere curiosity. The font is meant to imitate early printed Greek from the age of incunabula to the end of the 18th century. It is not the intention of this font to make Greek any more difficult or obscure than it already is for beginning students. The font is essentially a font for scholars. This font is organized in such a way that it can be used either as a standard Greek font or a font with Ligatures. The basic Latin section contains control codes and keyboard characters for standard Greek with ligatures for and The Latin supplement section contains Unicode control codes, kai\, ou ou=. prepositional prefixes, alternate letter forms and essential diacriticals. -

Contingent Worker Packet – Clinical
HUMAN RESOURCES CONTINGENT WORKER PACKET – CLINICAL PERSONAL INFORMATION AND ACKNOWLEDGEMENTS First Name Middle Name Last Name Address City State Zip Code Email Phone Number Date of Birth Emergency Contact Emergency Contact’s Phone Number Contract Company Name Company Contact Company Contact’s Email Address Company Contact’s Phone Number Position Training Exam Version: Score: Initialed Satisfactory Background Investigation Report Attestation Acknowledgement On behalf of the company listed above, I acknowledge and attest that we own and have in our possession a background investigation report on the individual identified above. Such background investigation is satisfactory in that it: • Does not reveal any criminal conviction that has not been disclosed to OU Medicine, Inc.; • Confirms the individual is not listed as a violent crime or sexual offender; • Confirms the individual is not on the GSA or OIG exclusion lists; • Confirms this individual is not on the U.S. Treasury Department’s Office of Foreign Assets Control list of Specially Designation Nationals; and I further attest that the background investigation report does not include any information about prior or pending investigations, reviews, sanctions or peer review proceedings; or limitations of any licensure, certification or registration. This attestation is provided in lieu of providing a copy of the background investigation report. Revised 09-2020 1 Initialed Application Attestation Acknowledgement On behalf of the company listed above, I acknowledge and attest that we own and have in our possession an application submitted on behalf of the individual identified above, if applicable. The application in our possession includes work and education history. If requested, the application will be provided to OU Medicine, Inc. -

Writing Arabizi: Orthographic Variation in Romanized
WRITING ARABIZI: ORTHOGRAPHIC VARIATION IN ROMANIZED LEBANESE ARABIC ON TWITTER ! ! ! ! Natalie!Sullivan! ! ! ! TC!660H!! Plan!II!Honors!Program! The!University!of!Texas!at!Austin! ! ! ! ! May!4,!2017! ! ! ! ! ! ! ! _______________________________________________________! Barbara!Bullock,!Ph.D.! Department!of!French!&!Italian! Supervising!Professor! ! ! ! ! _______________________________________________________! John!Huehnergard,!Ph.D.! Department!of!Middle!Eastern!Studies! Second!Reader!! ii ABSTRACT Author: Natalie Sullivan Title: Writing Arabizi: Orthographic Variation in Romanized Lebanese Arabic on Twitter Supervising Professors: Dr. Barbara Bullock, Dr. John Huehnergard How does technology influence the script in which a language is written? Over the past few decades, a new form of writing has emerged across the Arab world. Known as Arabizi, it is a type of Romanized Arabic that uses Latin characters instead of Arabic script. It is mainly used by youth in technology-related contexts such as social media and texting, and has made many older Arabic speakers fear that more standard forms of Arabic may be in danger because of its use. Prior work on Arabizi suggests that although it is used frequently on social media, its orthography is not yet standardized (Palfreyman and Khalil, 2003; Abdel-Ghaffar et al., 2011). Therefore, this thesis aimed to examine orthographic variation in Romanized Lebanese Arabic, which has rarely been studied as a Romanized dialect. It was interested in how often Arabizi is used on Twitter in Lebanon and the extent of its orthographic variation. Using Twitter data collected from Beirut, tweets were analyzed to discover the most common orthographic variants in Arabizi for each Arabic letter, as well as the overall rate of Arabizi use. Results show that Arabizi was not used as frequently as hypothesized on Twitter, probably because of its low prestige and increased globalization. -

Analyzing the Implications of the Supreme Court's Holding in Herrera
American Indian Law Review Volume 44 Number 2 2020 Analyzing the Implications of the Supreme Court’s Holding in Herrera v. Wyoming Andrew Rader Follow this and additional works at: https://digitalcommons.law.ou.edu/ailr Part of the Indian and Aboriginal Law Commons Recommended Citation Andrew Rader, Analyzing the Implications of the Supreme Court’s Holding in Herrera v. Wyoming, 44 AM. INDIAN L. REV. 403 (2020), https://digitalcommons.law.ou.edu/ailr/vol44/iss2/7 This Note is brought to you for free and open access by University of Oklahoma College of Law Digital Commons. It has been accepted for inclusion in American Indian Law Review by an authorized editor of University of Oklahoma College of Law Digital Commons. For more information, please contact [email protected]. ANALYZING THE IMPLICATIONS OF THE SUPREME COURT’S HOLDING IN HERRERA v. WYOMING Andrew Rader* Introduction The Crow Tribe has inhabited southern Montana and northern Wyoming for more than three centuries;1 Wyoming officially became a state in 1890, long after the Crow Tribe settled in the area.2 The Tribe’s settlement encompassed what is now known as the Bighorn National Forest, which is partly located in present-day Wyoming.3 Various territories officially declared statehood, and a recurring question became whether tribal treaty rights relating to the lands—now a part of the state—were preempted by the declaration of statehood.4 A common analysis in any treaty-rights case involves looking to congressional intent, as the legislature has the right to abrogate treaty rights in toto.5 Statehood preemption questions have arisen frequently in usufructuary rights cases—ones involving hunting and fishing rights.6 But that is not to say that the Supreme Court’s analysis in usufructuary rights cases cannot be applied to other, more significant treaty rights. -
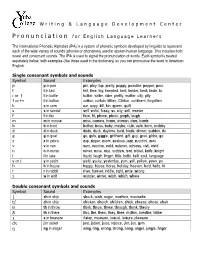
Pronunciation for English Language Learners
Writing & Language Development Center P ronunciation for English Language Learners The International Phonetic Alphabet (IPA) is a system of phonetic symbols developed by linguists to represent each of the wide variety of sounds (phones or phonemes) used in spoken human language. This includes both vowel and consonant sounds. The IPA is used to signal the pronunciation of words. Each symbol is treated separately below, with examples (like those used in the dictionary) so you can pronounce the word in American English. Single consonant symbols and sounds Symbol Sound Examples p p in pen pin, play, top, pretty, poppy, possible, pepper, pour t t in taxi tell, time, toy, tempted, tent, tender, bent, taste, to ɾ or ţ t in bottle butter, writer, rider, pretty, matter, city, pity ʔ or t¬ t in button cotton, curtain, kitten, Clinton, continent, forgotten k c in corn car, copy, kill, kin, queen, quilt s s in sandal sell, sinful, fussy, so, city, cell, receive f f in fan face, fit, phone, photo, graph, laugh m m in mouse miss, camera, home, woman, dam, bomb b b in boot bother, boss, baby, maybe, club, verb, born, snobby d d in duck dude, duck, daytime, bald, blade, dinner, sudden, do g g in goat go, guts, giggle, girlfriend, gift, guy, goat, globe, go z z in zebra zap, zipper, zoom, zealous, jazz, zucchini, zero v v in van very, vaccine, valid, veteran, achieve, civil, vivid n n in nurse never, nose, nice, sudden, tent, nickel, knife, knight l l in lake liquid, laugh, linger, little, belly, bell, soul, language y or j y in yacht yield, yucky, yesterday, -

Toward a Historically Faithful Performance of the Piano Works of Anton´Inqweˇrt´Y
15 Toward a historically faithful performance of the piano works of Anton´ınQweˇrt´y William Gunther Brian Kell Google, Inc. Google, Inc. [email protected] [email protected] SIGBOVIK ’18 Carnegie Mellon University April −2, 2018 Concrete The great Czech composer Anton´ın Dvoˇr´ak (1841–1904) wrote many pieces for the piano, including the famous Humoresque No. 7 in G-flat Ma- jor [2]. Unfortunately, typical performances of these works today sound nothing like what the composer intended because most modern pianos are configured with a different keyboard layout. Through painstaking histor- ical research, we have reconstructed the original Dvoˇr´ak piano keyboard layout. We have applied this discovery by transposing the Humoresque so that it is playable on a modern piano, enabling the first historically faithful performance of this piece in over a century. 1 92 Figure 1: A Dvorak keyboard with the original or “classic” layout [3]. There are several variants of the Dvorak layout, but Dvoˇr´akwas a classical composer, so this is almost certainly the one he used. Furthermore, this layout has 44 white keys (not counting the spacebar, which is clearly used only for rests). That is exactly half of the number of keys on a piano. Thus we may confidently conclude that the left half of Dvoˇr´ak’s piano layout was just these 44 keys, while the right half was the same keys again with the Shift key held down. Figure 2: A modern QWERTY keyboard with the United States layout [4]. This layout has 47 white keys (not counting the spacebar), but obviouslythree of them are useless: nobody really needs the characters ‘~]}\| [1]. -
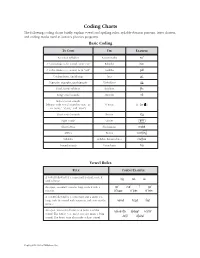
Phonics TRB Coding Chart
Coding Charts The following coding charts briefly explain vowel and spelling rules, syllable-division patterns, letter clusters, and coding marks used in Saxon’s phonics programs. Basic Coding TO CODE USE EXAMPLE Accented syllables Accent marks noÆ C ’s that make a /k/ sound, as in “cat” K-backs |cat C ’s that make a /s/ sound, as in “cell” Cedillas çell Combinations; diphthongs Arcs ar™ Digraphs; trigraphs; quadrigraphs Underlines SH___ Final, stable syllables Brackets [fle Long vowel sounds Macrons nO Schwa vowel sounds (rhymes with vowel sound in “sun,” as Schwas o÷ (or ) in “some,” “about,” and “won”) Short vowel sounds Breves log Sight words Circles ≤are≥ Silent letters Slash marks mak´ Affixes Boxes work ingfl Syllables Syllable division lines cac\tus Voiced sounds Voice lines hiß Vowel Rules RULE CODING EXAMPLE A vowel followed by a consonant is short; code it logcatsit with a breve. An open, accented vowel is long; code it with a nOÆ mEÆ íÆ gOÆ macron. AÆ\|cor™n OÆ\p»n EÆ\v»n A vowel followed by a consonant and a silent e is long; code the vowel with a macron and cross out the nAm´ hOp´ lIk´ silent e. An open, unaccented vowel can make a schwa b«\nanÆ\« E\rAs´Æ hO\telÆ sound. The letters e, o, and u can also make a long sound. The letter i can also make a short sound. JU\lŒÆ di\vId´Æ Copyright by Saxon Publishers, Inc. Spelling Rules† RULE EXAMPLE Floss Rule: When a one-syllable root word has a short vowel sound followed by the sound /f/, /l/, or /s/, it is puff doll pass usually spelled ff, ll, or ss.