Cling: a Memory Allocator to Mitigate Dangling Pointers
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Memory Management and Garbage Collection
Overview Memory Management Stack: Data on stack (local variables on activation records) have lifetime that coincides with the life of a procedure call. Memory for stack data is allocated on entry to procedures ::: ::: and de-allocated on return. Heap: Data on heap have lifetimes that may differ from the life of a procedure call. Memory for heap data is allocated on demand (e.g. malloc, new, etc.) ::: ::: and released Manually: e.g. using free Automatically: e.g. using a garbage collector Compilers Memory Management CSE 304/504 1 / 16 Overview Memory Allocation Heap memory is divided into free and used. Free memory is kept in a data structure, usually a free list. When a new chunk of memory is needed, a chunk from the free list is returned (after marking it as used). When a chunk of memory is freed, it is added to the free list (after marking it as free) Compilers Memory Management CSE 304/504 2 / 16 Overview Fragmentation Free space is said to be fragmented when free chunks are not contiguous. Fragmentation is reduced by: Maintaining different-sized free lists (e.g. free 8-byte cells, free 16-byte cells etc.) and allocating out of the appropriate list. If a small chunk is not available (e.g. no free 8-byte cells), grab a larger chunk (say, a 32-byte chunk), subdivide it (into 4 smaller chunks) and allocate. When a small chunk is freed, check if it can be merged with adjacent areas to make a larger chunk. Compilers Memory Management CSE 304/504 3 / 16 Overview Manual Memory Management Programmer has full control over memory ::: with the responsibility to manage it well Premature free's lead to dangling references Overly conservative free's lead to memory leaks With manual free's it is virtually impossible to ensure that a program is correct and secure. -

An In-Depth Study with All Rust Cves
Memory-Safety Challenge Considered Solved? An In-Depth Study with All Rust CVEs HUI XU, School of Computer Science, Fudan University ZHUANGBIN CHEN, Dept. of CSE, The Chinese University of Hong Kong MINGSHEN SUN, Baidu Security YANGFAN ZHOU, School of Computer Science, Fudan University MICHAEL R. LYU, Dept. of CSE, The Chinese University of Hong Kong Rust is an emerging programing language that aims at preventing memory-safety bugs without sacrificing much efficiency. The claimed property is very attractive to developers, and many projects start usingthe language. However, can Rust achieve the memory-safety promise? This paper studies the question by surveying 186 real-world bug reports collected from several origins which contain all existing Rust CVEs (common vulnerability and exposures) of memory-safety issues by 2020-12-31. We manually analyze each bug and extract their culprit patterns. Our analysis result shows that Rust can keep its promise that all memory-safety bugs require unsafe code, and many memory-safety bugs in our dataset are mild soundness issues that only leave a possibility to write memory-safety bugs without unsafe code. Furthermore, we summarize three typical categories of memory-safety bugs, including automatic memory reclaim, unsound function, and unsound generic or trait. While automatic memory claim bugs are related to the side effect of Rust newly-adopted ownership-based resource management scheme, unsound function reveals the essential challenge of Rust development for avoiding unsound code, and unsound generic or trait intensifies the risk of introducing unsoundness. Based on these findings, we propose two promising directions towards improving the security of Rust development, including several best practices of using specific APIs and methods to detect particular bugs involving unsafe code. -

Project Snowflake: Non-Blocking Safe Manual Memory Management in .NET
Project Snowflake: Non-blocking Safe Manual Memory Management in .NET Matthew Parkinson Dimitrios Vytiniotis Kapil Vaswani Manuel Costa Pantazis Deligiannis Microsoft Research Dylan McDermott Aaron Blankstein Jonathan Balkind University of Cambridge Princeton University July 26, 2017 Abstract Garbage collection greatly improves programmer productivity and ensures memory safety. Manual memory management on the other hand often delivers better performance but is typically unsafe and can lead to system crashes or security vulnerabilities. We propose integrating safe manual memory management with garbage collection in the .NET runtime to get the best of both worlds. In our design, programmers can choose between allocating objects in the garbage collected heap or the manual heap. All existing applications run unmodified, and without any performance degradation, using the garbage collected heap. Our programming model for manual memory management is flexible: although objects in the manual heap can have a single owning pointer, we allow deallocation at any program point and concurrent sharing of these objects amongst all the threads in the program. Experimental results from our .NET CoreCLR implementation on real-world applications show substantial performance gains especially in multithreaded scenarios: up to 3x savings in peak working sets and 2x improvements in runtime. 1 Introduction The importance of garbage collection (GC) in modern software cannot be overstated. GC greatly improves programmer productivity because it frees programmers from the burden of thinking about object lifetimes and freeing memory. Even more importantly, GC prevents temporal memory safety errors, i.e., uses of memory after it has been freed, which often lead to security breaches. Modern generational collectors, such as the .NET GC, deliver great throughput through a combination of fast thread-local bump allocation and cheap collection of young objects [63, 18, 61]. -

Ensuring the Spatial and Temporal Memory Safety of C at Runtime
MemSafe: Ensuring the Spatial and Temporal Memory Safety of C at Runtime Matthew S. Simpson, Rajeev K. Barua Department of Electrical & Computer Engineering University of Maryland, College Park College Park, MD 20742-3256, USA fsimpsom, [email protected] Abstract—Memory access violations are a leading source of dereferencing pointers obtained from invalid pointer arith- unreliability in C programs. As evidence of this problem, a vari- metic; and dereferencing uninitialized, NULL or “manufac- ety of methods exist that retrofit C with software checks to detect tured” pointers.1 A temporal error is a violation caused by memory errors at runtime. However, these methods generally suffer from one or more drawbacks including the inability to using a pointer whose referent has been deallocated (e.g. with detect all errors, the use of incompatible metadata, the need for free) and is no longer a valid object. The most well-known manual code modifications, and high runtime overheads. temporal violations include dereferencing “dangling” point- In this paper, we present a compiler analysis and transforma- ers to dynamically allocated memory and freeing a pointer tion for ensuring the memory safety of C called MemSafe. Mem- more than once. Dereferencing pointers to automatically allo- Safe makes several novel contributions that improve upon previ- ous work and lower the cost of safety. These include (1) a method cated memory (stack variables) is also a concern if the address for modeling temporal errors as spatial errors, (2) a compati- of the referent “escapes” and is made available outside the ble metadata representation combining features of object- and function in which it was defined. -

Memory Safety Without Garbage Collection for Embedded Applications
Memory Safety Without Garbage Collection for Embedded Applications DINAKAR DHURJATI, SUMANT KOWSHIK, VIKRAM ADVE, and CHRIS LATTNER University of Illinois at Urbana-Champaign Traditional approaches to enforcing memory safety of programs rely heavily on run-time checks of memory accesses and on garbage collection, both of which are unattractive for embedded ap- plications. The goal of our work is to develop advanced compiler techniques for enforcing memory safety with minimal run-time overheads. In this paper, we describe a set of compiler techniques that, together with minor semantic restrictions on C programs and no new syntax, ensure memory safety and provide most of the error-detection capabilities of type-safe languages, without using garbage collection, and with no run-time software checks, (on systems with standard hardware support for memory management). The language permits arbitrary pointer-based data structures, explicit deallocation of dynamically allocated memory, and restricted array operations. One of the key results of this paper is a compiler technique that ensures that dereferencing dangling pointers to freed memory does not violate memory safety, without annotations, run-time checks, or garbage collection, and works for arbitrary type-safe C programs. Furthermore, we present a new inter- procedural analysis for static array bounds checking under certain assumptions. For a diverse set of embedded C programs, we show that we are able to ensure memory safety of pointer and dy- namic memory usage in all these programs with no run-time software checks (on systems with standard hardware memory protection), requiring only minor restructuring to conform to simple type restrictions. Static array bounds checking fails for roughly half the programs we study due to complex array references, and these are the only cases where explicit run-time software checks would be needed under our language and system assumptions. -

Memory Leak Or Dangling Pointer
Modern C++ for Computer Vision and Image Processing Igor Bogoslavskyi Outline Using pointers Pointers are polymorphic Pointer “this” Using const with pointers Stack and Heap Memory leaks and dangling pointers Memory leak Dangling pointer RAII 2 Using pointers in real world Using pointers for classes Pointers can point to objects of custom classes: 1 std::vector<int> vector_int; 2 std::vector<int >* vec_ptr = &vector_int; 3 MyClass obj; 4 MyClass* obj_ptr = &obj; Call object functions from pointer with -> 1 MyClass obj; 2 obj.MyFunc(); 3 MyClass* obj_ptr = &obj; 4 obj_ptr->MyFunc(); obj->Func() (*obj).Func() ↔ 4 Pointers are polymorphic Pointers are just like references, but have additional useful properties: Can be reassigned Can point to ‘‘nothing’’ (nullptr) Can be stored in a vector or an array Use pointers for polymorphism 1 Derived derived; 2 Base* ptr = &derived; Example: for implementing strategy store a pointer to the strategy interface and initialize it with nullptr and check if it is set before calling its methods 5 1 #include <iostream > 2 #include <vector > 3 using std::cout; 4 struct AbstractShape { 5 virtual void Print() const = 0; 6 }; 7 struct Square : public AbstractShape { 8 void Print() const override { cout << "Square\n";} 9 }; 10 struct Triangle : public AbstractShape { 11 void Print() const override { cout << "Triangle\n";} 12 }; 13 int main() { 14 std::vector<AbstractShape*> shapes; 15 Square square; 16 Triangle triangle; 17 shapes.push_back(&square); 18 shapes.push_back(&triangle); 19 for (const auto* shape : shapes) { shape->Print(); } 20 return 0; 21 } 6 this pointer Every object of a class or a struct holds a pointer to itself This pointer is called this Allows the objects to: Return a reference to themselves: return *this; Create copies of themselves within a function Explicitly show that a member belongs to the current object: this->x(); 7 Using const with pointers Pointers can point to a const variable: 1 // Cannot change value , can reassign pointer. -

CSE 220: Systems Programming
Memory Allocation CSE 220: Systems Programming Ethan Blanton Department of Computer Science and Engineering University at Buffalo Introduction The Heap Void Pointers The Standard Allocator Allocation Errors Summary Allocating Memory We have seen how to use pointers to address: An existing variable An array element from a string or array constant This lecture will discuss requesting memory from the system. © 2021 Ethan Blanton / CSE 220: Systems Programming 2 Introduction The Heap Void Pointers The Standard Allocator Allocation Errors Summary Memory Lifetime All variables we have seen so far have well-defined lifetime: They persist for the entire life of the program They persist for the duration of a single function call Sometimes we need programmer-controlled lifetime. © 2021 Ethan Blanton / CSE 220: Systems Programming 3 Introduction The Heap Void Pointers The Standard Allocator Allocation Errors Summary Examples int global ; /* Lifetime of program */ void foo () { int x; /* Lifetime of foo () */ } Here, global is statically allocated: It is allocated by the compiler It is created when the program starts It disappears when the program exits © 2021 Ethan Blanton / CSE 220: Systems Programming 4 Introduction The Heap Void Pointers The Standard Allocator Allocation Errors Summary Examples int global ; /* Lifetime of program */ void foo () { int x; /* Lifetime of foo () */ } Whereas x is automatically allocated: It is allocated by the compiler It is created when foo() is called ¶ It disappears when foo() returns © 2021 Ethan Blanton / CSE 220: Systems Programming 5 Introduction The Heap Void Pointers The Standard Allocator Allocation Errors Summary The Heap The heap represents memory that is: allocated and released at run time managed explicitly by the programmer only obtainable by address Heap memory is just a range of bytes to C. -

Memory Tagging and How It Improves C/C++ Memory Safety Kostya Serebryany, Evgenii Stepanov, Aleksey Shlyapnikov, Vlad Tsyrklevich, Dmitry Vyukov Google February 2018
Memory Tagging and how it improves C/C++ memory safety Kostya Serebryany, Evgenii Stepanov, Aleksey Shlyapnikov, Vlad Tsyrklevich, Dmitry Vyukov Google February 2018 Introduction 2 Memory Safety in C/C++ 2 AddressSanitizer 2 Memory Tagging 3 SPARC ADI 4 AArch64 HWASAN 4 Compiler And Run-time Support 5 Overhead 5 RAM 5 CPU 6 Code Size 8 Usage Modes 8 Testing 9 Always-on Bug Detection In Production 9 Sampling In Production 10 Security Hardening 11 Strengths 11 Weaknesses 12 Legacy Code 12 Kernel 12 Uninitialized Memory 13 Possible Improvements 13 Precision Of Buffer Overflow Detection 13 Probability Of Bug Detection 14 Conclusion 14 Introduction Memory safety in C and C++ remains largely unresolved. A technique usually called “memory tagging” may dramatically improve the situation if implemented in hardware with reasonable overhead. This paper describes two existing implementations of memory tagging: one is the full hardware implementation in SPARC; the other is a partially hardware-assisted compiler-based tool for AArch64. We describe the basic idea, evaluate the two implementations, and explain how they improve memory safety. This paper is intended to initiate a wider discussion of memory tagging and to motivate the CPU and OS vendors to add support for it in the near future. Memory Safety in C/C++ C and C++ are well known for their performance and flexibility, but perhaps even more for their extreme memory unsafety. This year we are celebrating the 30th anniversary of the Morris Worm, one of the first known exploitations of a memory safety bug, and the problem is still not solved. -

Memory Management with Explicit Regions by David Edward Gay
Memory Management with Explicit Regions by David Edward Gay Engineering Diploma (Ecole Polytechnique F´ed´erale de Lausanne, Switzerland) 1992 M.S. (University of California, Berkeley) 1997 A dissertation submitted in partial satisfaction of the requirements for the degree of Doctor of Philosophy in Computer Science in the GRADUATE DIVISION of the UNIVERSITY of CALIFORNIA at BERKELEY Committee in charge: Professor Alex Aiken, Chair Professor Susan L. Graham Professor Gregory L. Fenves Fall 2001 The dissertation of David Edward Gay is approved: Chair Date Date Date University of California at Berkeley Fall 2001 Memory Management with Explicit Regions Copyright 2001 by David Edward Gay 1 Abstract Memory Management with Explicit Regions by David Edward Gay Doctor of Philosophy in Computer Science University of California at Berkeley Professor Alex Aiken, Chair Region-based memory management systems structure memory by grouping objects in regions under program control. Memory is reclaimed by deleting regions, freeing all objects stored therein. Our compiler for C with regions, RC, prevents unsafe region deletions by keeping a count of references to each region. RC's regions have advantages over explicit allocation and deallocation (safety) and traditional garbage collection (better control over memory), and its performance is competitive with both|from 6% slower to 55% faster on a collection of realistic benchmarks. Experience with these benchmarks suggests that modifying many existing programs to use regions is not difficult. An important innovation in RC is the use of type annotations that make the structure of a program's regions more explicit. These annotations also help reduce the overhead of reference counting from a maximum of 25% to a maximum of 12.6% on our benchmarks. -
Memory Allocation Pushq %Rbp Java Vs
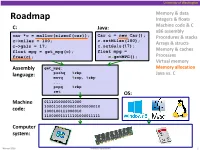
University of Washington Memory & data Roadmap Integers & floats C: Java: Machine code & C x86 assembly car *c = malloc(sizeof(car)); Car c = new Car(); Procedures & stacks c.setMiles(100); c->miles = 100; Arrays & structs c->gals = 17; c.setGals(17); float mpg = get_mpg(c); float mpg = Memory & caches free(c); c.getMPG(); Processes Virtual memory Assembly get_mpg: Memory allocation pushq %rbp Java vs. C language: movq %rsp, %rbp ... popq %rbp ret OS: Machine 0111010000011000 100011010000010000000010 code: 1000100111000010 110000011111101000011111 Computer system: Winter 2016 Memory Allocation 1 University of Washington Memory Allocation Topics Dynamic memory allocation . Size/number/lifetime of data structures may only be known at run time . Need to allocate space on the heap . Need to de-allocate (free) unused memory so it can be re-allocated Explicit Allocation Implementation . Implicit free lists . Explicit free lists – subject of next programming assignment . Segregated free lists Implicit Deallocation: Garbage collection Common memory-related bugs in C programs Winter 2016 Memory Allocation 2 University of Washington Dynamic Memory Allocation Programmers use dynamic memory allocators (such as malloc) to acquire virtual memory at run time . For data structures whose size (or lifetime) is known only at runtime Dynamic memory allocators manage an area of a process’ virtual memory known as the heap User stack Top of heap (brk ptr) Heap (via malloc) Uninitialized data (.bss) Initialized data (.data) Program text (.text) 0 Winter 2016 Memory Allocation 3 University of Washington Dynamic Memory Allocation Allocator organizes the heap as a collection of variable-sized blocks, which are either allocated or free . Allocator requests pages in heap region; virtual memory hardware and OS kernel allocate these pages to the process . -

Unleashing the Power of Allocator-Aware Software
P2126R0 2020-03-02 Pablo Halpern (on behalf of Bloomberg): [email protected] John Lakos: [email protected] Unleashing the Power of Allocator-Aware Software Infrastructure NOTE: This white paper (i.e., this is not a proposal) is intended to motivate continued investment in developing and maturing better memory allocators in the C++ Standard as well as to counter misinformation about allocators, their costs and benefits, and whether they should have a continuing role in the C++ library and language. Abstract Local (arena) memory allocators have been demonstrated to be effective at improving runtime performance both empirically in repeated controlled experiments and anecdotally in a variety of real-world applications. The initial development and subsequent maintenance effort of implementing bespoke data structures using custom memory allocation, however, are typically substantial and often untenable, especially in the limited timeframes that urgent business needs impose. To address such recurring performance needs effectively across the enterprise, Bloomberg has adopted a consistent, ubiquitous allocator-aware software infrastructure (AASI) based on the PMR-style1 plug-in memory allocator protocol pioneered at Bloomberg and adopted into the C++17 Standard Library. In this paper, we highlight the essential mechanics and subtle nuances of programing on top of Bloomberg’s AASI platform. In addition to delineating how to obtain performance gains safely at minimal development cost, we explore many of the inherent collateral benefits — such as object placement, metrics gathering, testing, debugging, and so on — that an AASI naturally affords. After reading this paper and surveying the available concrete allocators (provided in Appendix A), a competent C++ developer should be adequately equipped to extract substantial performance and other collateral benefits immediately using our AASI. -

P1083r2 | Move Resource Adaptor from Library TS to the C++ WP
P1083r2 | Move resource_adaptor from Library TS to the C++ WP Pablo Halpern [email protected] 2018-11-13 | Target audience: LWG 1 Abstract When the polymorphic allocator infrastructure was moved from the Library Fundamentals TS to the C++17 working draft, pmr::resource_adaptor was left behind. The decision not to move pmr::resource_adaptor was deliberately conservative, but the absence of resource_adaptor in the standard is a hole that must be plugged for a smooth transition to the ubiquitous use of polymorphic_allocator, as proposed in P0339 and P0987. This paper proposes that pmr::resource_adaptor be moved from the LFTS and added to the C++20 working draft. 2 History 2.1 Changes from R1 to R2 (in San Diego) • Paper was forwarded from LEWG to LWG on Tuesday, 2018-10-06 • Copied the formal wording from the LFTS directly into this paper • Minor wording changes as per initial LWG review • Rebased to the October 2018 draft of the C++ WP 2.2 Changes from R0 to R1 (pre-San Diego) • Added a note for LWG to consider clarifying the alignment requirements for resource_adaptor<A>::do_allocate(). • Changed rebind type from char to byte. • Rebased to July 2018 draft of the C++ WP. 3 Motivation It is expected that more and more classes, especially those that would not otherwise be templates, will use pmr::polymorphic_allocator<byte> to allocate memory. In order to pass an allocator to one of these classes, the allocator must either already be a polymorphic allocator, or must be adapted from a non-polymorphic allocator. The process of adaptation is facilitated by pmr::resource_adaptor, which is a simple class template, has been in the LFTS for a long time, and has been fully implemented.