Macromolecular Visualization: VMD
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Real-Time Pymol Visualization for Rosetta and Pyrosetta
Real-Time PyMOL Visualization for Rosetta and PyRosetta Evan H. Baugh1, Sergey Lyskov1, Brian D. Weitzner1, Jeffrey J. Gray1,2* 1 Department of Chemical and Biomolecular Engineering, The Johns Hopkins University, Baltimore, Maryland, United States of America, 2 Program in Molecular Biophysics, The Johns Hopkins University, Baltimore, Maryland, United States of America Abstract Computational structure prediction and design of proteins and protein-protein complexes have long been inaccessible to those not directly involved in the field. A key missing component has been the ability to visualize the progress of calculations to better understand them. Rosetta is one simulation suite that would benefit from a robust real-time visualization solution. Several tools exist for the sole purpose of visualizing biomolecules; one of the most popular tools, PyMOL (Schro¨dinger), is a powerful, highly extensible, user friendly, and attractive package. Integrating Rosetta and PyMOL directly has many technical and logistical obstacles inhibiting usage. To circumvent these issues, we developed a novel solution based on transmitting biomolecular structure and energy information via UDP sockets. Rosetta and PyMOL run as separate processes, thereby avoiding many technical obstacles while visualizing information on-demand in real-time. When Rosetta detects changes in the structure of a protein, new coordinates are sent over a UDP network socket to a PyMOL instance running a UDP socket listener. PyMOL then interprets and displays the molecule. This implementation also allows remote execution of Rosetta. When combined with PyRosetta, this visualization solution provides an interactive environment for protein structure prediction and design. Citation: Baugh EH, Lyskov S, Weitzner BD, Gray JJ (2011) Real-Time PyMOL Visualization for Rosetta and PyRosetta. -

A Nano-Visualization Software for Education and Research
A Nano-Visualization Software for Education and Research Lillian C. Oetting Department of Computer Science, Stanford University, Stanford, CA 94305 USA West High School, Iowa City, IA 52246 USA Tehseen Z. Raza Department of Physics and Astronomy, University of Iowa, Iowa City, IA 52242 USA Hassan Raza Department of Electrical and Computer Engineering, University of Iowa, Iowa City, IA 52242 USA Centre for Fundamental Research, Islamabad, Pakistan Abstract: We report the development of a user-friendly nano-visualization software program which can acquaint high-school students with nanotechnology. The visual introduction to atoms and molecules, which are the building blocks of this technology, is an effective way to introduce the key concepts in this area. The software’s graphical user interface enables multidimensional atomic visualization by using ball and stick schematics. Additionally, the software provides the option of wavefunction visualization for arbitrary nanomaterials and nanostructures by using extended Hückel theory. The software is instructive, application oriented and may be useful not only in high school education but also for the undergraduate research and teaching. 1 I. Introduction: The ability to accurately depict atomic, molecular and electronic structures has been a key factor in the advancement of nanotechnology. In this context, it is imperative to provide teaching and research platforms to motivate students towards this novel technology [1-3], while keeping the societal implications in perspective [4]. Nano-visualization appeals well due to its simplistic, yet elegant approach towards the visual representation of detailed concepts about quantum mechanics, quantum chemistry and linear algebra. Additionally, the conflux of quantum mechanics, numerical computation, graphical design, and computer programming gives exposure to the multi-disciplinary aspect of this technology [5-8]. -

Python Tools in Computational Chemistry (And Biology)
Python Tools in Computational Chemistry (and Biology) Andrew Dalke Dalke Scientific, AB Göteborg, Sweden EuroSciPy, 26-27 July, 2008 “Why does ‘import numpy’ take 0.4 seconds? Does it need to import 228 libraries?” - My first Numpy-discussion post (paraphrased) Your use case isn't so typical and so suffers on the import time end of the balance. - Response from Robert Kern (Others did complain. Import time down to 0.28s.) 52,000 structures PDB doubles every 2½ years HEADER PHOTORECEPTOR 23-MAY-90 1BRD 1BRD 2 COMPND BACTERIORHODOPSIN 1BRD 3 SOURCE (HALOBACTERIUM $HALOBIUM) 1BRD 4 EXPDTA ELECTRON DIFFRACTION 1BRD 5 AUTHOR R.HENDERSON,J.M.BALDWIN,T.A.CESKA,F.ZEMLIN,E.BECKMANN, 1BRD 6 AUTHOR 2 K.H.DOWNING 1BRD 7 REVDAT 3 15-JAN-93 1BRDB 1 SEQRES 1BRDB 1 REVDAT 2 15-JUL-91 1BRDA 1 REMARK 1BRDA 1 .. ATOM 54 N PRO 8 20.397 -15.569 -13.739 1.00 20.00 1BRD 136 ATOM 55 CA PRO 8 21.592 -15.444 -12.900 1.00 20.00 1BRD 137 ATOM 56 C PRO 8 21.359 -15.206 -11.424 1.00 20.00 1BRD 138 ATOM 57 O PRO 8 21.904 -15.930 -10.563 1.00 20.00 1BRD 139 ATOM 58 CB PRO 8 22.367 -14.319 -13.591 1.00 20.00 1BRD 140 ATOM 59 CG PRO 8 22.089 -14.564 -15.053 1.00 20.00 1BRD 141 ATOM 60 CD PRO 8 20.647 -15.054 -15.103 1.00 20.00 1BRD 142 ATOM 61 N GLU 9 20.562 -14.211 -11.095 1.00 20.00 1BRD 143 ATOM 62 CA GLU 9 20.192 -13.808 -9.737 1.00 20.00 1BRD 144 ATOM 63 C GLU 9 19.567 -14.935 -8.932 1.00 20.00 1BRD 145 ATOM 64 O GLU 9 19.815 -15.104 -7.724 1.00 20.00 1BRD 146 ATOM 65 CB GLU 9 19.248 -12.591 -9.820 1.00 99.00 1 1BRD 147 ATOM 66 CG GLU 9 19.902 -11.351 -10.387 1.00 99.00 1 1BRD 148 ATOM 67 CD GLU 9 19.243 -10.169 -10.980 1.00 99.00 1 1BRD 149 ATOM 68 OE1 GLU 9 18.323 -10.191 -11.782 1.00 99.00 1 1BRD 150 ATOM 69 OE2 GLU 9 19.760 -9.089 -10.597 1.00 99.00 1 1BRD 151 ATOM 70 N TRP 10 18.764 -15.737 -9.597 1.00 20.00 1BRD 152 ATOM 71 CA TRP 10 18.034 -16.884 -9.090 1.00 20.00 1BRD 153 ATOM 72 C TRP 10 18.843 -17.908 -8.318 1.00 20.00 1BRD 154 ATOM 73 O TRP 10 18.376 -18.310 -7.230 1.00 20.00 1BRD 155 . -

Chemdoodle Web Components: HTML5 Toolkit for Chemical Graphics, Interfaces, and Informatics Melanie C Burger1,2*
Burger. J Cheminform (2015) 7:35 DOI 10.1186/s13321-015-0085-3 REVIEW Open Access ChemDoodle Web Components: HTML5 toolkit for chemical graphics, interfaces, and informatics Melanie C Burger1,2* Abstract ChemDoodle Web Components (abbreviated CWC, iChemLabs, LLC) is a light-weight (~340 KB) JavaScript/HTML5 toolkit for chemical graphics, structure editing, interfaces, and informatics based on the proprietary ChemDoodle desktop software. The library uses <canvas> and WebGL technologies and other HTML5 features to provide solutions for creating chemistry-related applications for the web on desktop and mobile platforms. CWC can serve a broad range of scientific disciplines including crystallography, materials science, organic and inorganic chemistry, biochem- istry and chemical biology. CWC is freely available for in-house use and is open source (GPL v3) for all other uses. Keywords: ChemDoodle Web Components, Chemical graphics, Animations, Cheminformatics, HTML5, Canvas, JavaScript, WebGL, Structure editor, Structure query Introduction Mobile browsers did support HTML5, which opened How we communicate chemical information is increas- the door to web applications built with only HTML, ingly technology driven. Learning management systems, CSS and JavaScript (JS), such as the ChemDoodle Web virtual classrooms and MOOCs are a few examples where Components. chemistry educators need forward compatible tools for digital natives. Companies that implement emerg- Review ing web technologies can find efficiencies and benefit The ChemDoodle Web Components technology stack from competitive advantages. The first chemical graph- and features ics toolkit for the web, MDL Chime, was introduced in The ChemDoodle Web Components library, released in 1996 [1]. Based on the molecular visualization program 2009, is the first chemistry toolkit for structure viewing RasMol, Chime was developed as a plugin for Netscape and editing that is originally built using only web stand- and later for Internet Explorer and Firefox. -

64-194 Projekt Parallelrechnerevaluation Abschlussbericht
64-194 Projekt Parallelrechnerevaluation Abschlussbericht Automatisierte Build-Tests für Spack Sarah Lubitz Malte Fock [email protected] [email protected] Studiengang: LA Berufliche Schulen – Informatik Studiengang LaGym - Informatik Matr.-Nr. 6570465 Matr.-Nr. 6311966 Inhaltsverzeichnis i Inhaltsverzeichnis 1 Einleitung1 1.1 Motivation.....................................1 1.2 Vorbereitungen..................................2 1.2.1 Spack....................................2 1.2.2 Python...................................2 1.2.3 Unix-Shell.................................3 1.2.4 Slurm....................................3 1.2.5 GitHub...................................4 2 Code 7 2.1 Automatisiertes Abrufen und Installieren von Spack-Paketen.......7 2.1.1 Python Skript: install_all_packets.py..................7 2.2 Batch-Jobskripte..................................9 2.2.1 Test mit drei Paketen........................... 10 2.3 Analyseskript................................... 11 2.3.1 Test mit 500 Paketen........................... 12 2.3.2 Code zur Analyse der Error-Logs, forts................. 13 2.4 Hintereinanderausführung der Installationen................. 17 2.4.1 Wrapper Skript.............................. 19 2.5 E-Mail Benachrichtigungen........................... 22 3 Testlauf 23 3.1 Durchführung und Ergebnisse......................... 23 3.2 Auswertung und Schlussfolgerungen..................... 23 3.3 Fazit und Ausblick................................ 24 4 Schulische Relevanz 27 Literaturverzeichnis -
Instructions for PDB Downloading (From Either Website)
Molecular Visualization A BBSI Tutorial http://www.ccbb.pitt.edu/BBSI/index.htm By: Jeffry D. Madura Joshua A. Plumley Thomas J. Dick Table of Contents Instructions for PDB downloading..........................................................2 RasMol Tutorial ...........................................................................................3 VMD Tutorial ...............................................................................................5 CAChe Tutuorial..........................................................................................8 MOE Tutorial ............................................................................................. 10 Chimera Tutorial ....................................................................................... 13 Exercises .................................................................................................... 16 1 Instructions for PDB downloading (from either website) -Go to: - Go to: www.rcsb.org/pdb/ www.pdb.bu.edu/oca-bin/pdblite -Type in name of protein (examples at - Type in name of Protein / bottom of the page). Macromolecule ( examples at bottom of page). - Click on Name icon (first name in purple box). - Click on Retrieve Released Data Matching Your Query icon. -On the left side of the screen, click on Download/Display Structure - Highlight any of the molecule name and click on the View/ Analyze/ -Under Download the Structure File, Save Macro Molecule icon. right click on the X where the PDB(top) meets with none, under - Under the Data Retrieval section, -

USER MANUAL Version 4.5
GROMACS Groningen Machine for Chemical Simulations USER MANUAL Version 4.5 GROMACS USER MANUAL Version 4.5 Written by Emile Apol, Rossen Apostolov, Herman J.C. Berendsen, Aldert van Buuren, Par¨ Bjelkmar, Rudi van Drunen, Anton Feenstra, Gerrit Groenhof, Peter Kasson, Per Larsson, Peiter Meulenhoff, Teemu Murtola, Szilard´ Pall,´ Sander Pronk, Roland Schultz, Michael Shirts, Alfons Sijbers, Peter Tieleman Berk Hess, David van der Spoel, and Erik Lindahl. Additional contributions by Mark Abraham, Christoph Junghans, Carsten Kutzner, Justin A. Lemkul, Erik Marklund, Maarten Wolf. c 1991–2000: Department of Biophysical Chemistry, University of Groningen. Nijenborgh 4, 9747 AG Groningen, The Netherlands. c 2001–2010: The GROMACS development teams at the Royal Institute of Technology and Uppsala University, Sweden. More information can be found on our website: www.gromacs.org. iv Preface & Disclaimer This manual is not complete and has no pretention to be so due to lack of time of the contributors – our first priority is to improve the software. It is worked on continuously, which in some cases might mean the information is not entirely correct. Comments are welcome, please send them by e-mail to [email protected], or to one of the mailing lists (see www.gromacs.org). We try to release an updated version of the manual whenever we release a new version of the soft- ware, so in general it is a good idea to use a manual with the same major and minor release number as your GROMACS installation. Any revision numbers (like 3.1.1) are however independent, to make it possible to implement bug fixes and manual improvements if necessary. -

How to Print a Crystal Structure Model in 3D Teng-Hao Chen,*A Semin Lee, B Amar H
Electronic Supplementary Material (ESI) for CrystEngComm. This journal is © The Royal Society of Chemistry 2014 How to Print a Crystal Structure Model in 3D Teng-Hao Chen,*a Semin Lee, b Amar H. Flood b and Ognjen Š. Miljanić a a Department of Chemistry, University of Houston, 112 Fleming Building, Houston, Texas 77204-5003, United States b Department of Chemistry, Indiana University, 800 E. Kirkwood Avenue, Bloomington, Indiana 47405, United States Supporting Information Instructions for Printing a 3D Model of an Interlocked Molecule: Cyanostars .................................... S2 Instructions for Printing a "Molecular Spinning Top" in 3D: Triazolophanes ..................................... S3 References ....................................................................................................................................................................... S4 S1 Instructions for Printing a 3D Model of an Interlocked Molecule: Cyanostars Mechanically interlocked molecules such as rotaxanes and catenanes can also be easily printed in 3D. As long as the molecule is correctly designed and modeled, there is no need to assemble and glue the components after printing—they are printed inherently as mechanically interlocked molecules. We present the preparation of a cyanostar- based [3]rotaxane as an example. A pair of sandwiched cyanostars S1 (CS ) derived from the crystal structure was "cleaned up" in the molecular computation software Spartan ʹ10, i.e. disordered atoms were removed. A linear molecule was created and threaded through the cavity of two cyanostars (Figure S1a). Using a space filling view of the molecule, the three components were spaced sufficiently far apart to ensure that they did not make direct contact Figure S1 . ( a) Side and top view of two cyanostars ( CS ) with each other when they are printed. threaded with a linear molecule. ( b) Side and top view of a Bulky stoppers were added to each [3]rotaxane. -

Conformational and Chemical Selection by a Trans-Acting Editing
Correction BIOCHEMISTRY Correction for “Conformational and chemical selection by a trans- acting editing domain,” by Eric M. Danhart, Marina Bakhtina, William A. Cantara, Alexandra B. Kuzmishin, Xiao Ma, Brianne L. Sanford, Marija Kosutic, Yuki Goto, Hiroaki Suga, Kotaro Nakanishi, Ronald Micura, Mark P. Foster, and Karin Musier-Forsyth, which was first published August 2, 2017; 10.1073/pnas.1703925114 (Proc Natl Acad Sci USA 114:E6774–E6783). The authors note that Oscar Vargas-Rodriguez should be added to the author list between Brianne L. Sanford and Marija Kosutic. Oscar Vargas-Rodriguez should be credited with de- signing research, performing research, and analyzing data. The corrected author line, affiliation line, and author contributions appear below. The online version has been corrected. The authors note that the following statement should be added to the Acknowledgments: “We thank Daniel McGowan for assistance with preparing mutant proteins.” Eric M. Danharta,b, Marina Bakhtinaa,b, William A. Cantaraa,b, Alexandra B. Kuzmishina,b,XiaoMaa,b, Brianne L. Sanforda,b, Oscar Vargas-Rodrigueza,b, Marija Kosuticc,d,YukiGotoe, Hiroaki Sugae, Kotaro Nakanishia,b, Ronald Micurac,d, Mark P. Fostera,b, and Karin Musier-Forsytha,b aDepartment of Chemistry and Biochemistry, The Ohio State University, Columbus, OH 43210; bCenter for RNA Biology, The Ohio State University, Columbus, OH 43210; cInstitute of Organic Chemistry, Leopold Franzens University, A-6020 Innsbruck, Austria; dCenter for Molecular Biosciences, Leopold Franzens University, A-6020 Innsbruck, Austria; and eDepartment of Chemistry, Graduate School of Science, The University of Tokyo, Tokyo 113-0033, Japan Author contributions: E.M.D., M.B., W.A.C., B.L.S., O.V.-R., M.P.F., and K.M.-F. -
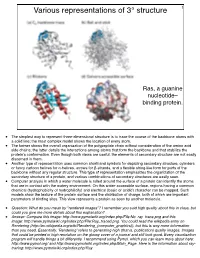
Various Representations of 3° Structure 1
Various representations of 3° structure 1 Ras, a guanine nucleotide– binding protein. • The simplest way to represent three-dimensional structure is to trace the course of the backbone atoms with a solid line; the most complex model shows the location of every atom. • The former shows the overall organization of the polypeptide chain without consideration of the amino acid side chains; the latter details the interactions among atoms that form the backbone and that stabilize the protein’s conformation. Even though both views are useful, the elements of secondary structure are not easily discerned in them. • Another type of representation uses common shorthand symbols for depicting secondary structure, cylinders or fancy cartoon helices for α-helices, arrows for β-strands, and a flexible string-like form for parts of the backbone without any regular structure. This type of representation emphasizes the organization of the secondary structure of a protein, and various combinations of secondary structures are easily seen. • Computer analysis in which a water molecule is rolled around the surface of a protein can identify the atoms that are in contact with the watery environment. On this water-accessible surface, regions having a common chemical (hydrophobicity or hydrophilicity) and electrical (basic or acidic) character can be mapped. Such models show the texture of the protein surface and the distribution of charge, both of which are important parameters of binding sites. This view represents a protein as seen by another molecule. • Question: What do you mean by "rendered images"? I remember you said high quality about this in class, but could you give me more details about this explanation? • Answer: Compare this image: http://www.pymolwiki.org/index.php/File:No_ray_trace.png and this image: http://www.pymolwiki.org/index.php/File:Ray_traced.png. -

Package Name Software Description Project
A S T 1 Package Name Software Description Project URL 2 Autoconf An extensible package of M4 macros that produce shell scripts to automatically configure software source code packages https://www.gnu.org/software/autoconf/ 3 Automake www.gnu.org/software/automake 4 Libtool www.gnu.org/software/libtool 5 bamtools BamTools: a C++ API for reading/writing BAM files. https://github.com/pezmaster31/bamtools 6 Biopython (Python module) Biopython is a set of freely available tools for biological computation written in Python by an international team of developers www.biopython.org/ 7 blas The BLAS (Basic Linear Algebra Subprograms) are routines that provide standard building blocks for performing basic vector and matrix operations. http://www.netlib.org/blas/ 8 boost Boost provides free peer-reviewed portable C++ source libraries. http://www.boost.org 9 CMake Cross-platform, open-source build system. CMake is a family of tools designed to build, test and package software http://www.cmake.org/ 10 Cython (Python module) The Cython compiler for writing C extensions for the Python language https://www.python.org/ 11 Doxygen http://www.doxygen.org/ FFmpeg is the leading multimedia framework, able to decode, encode, transcode, mux, demux, stream, filter and play pretty much anything that humans and machines have created. It supports the most obscure ancient formats up to the cutting edge. No matter if they were designed by some standards 12 ffmpeg committee, the community or a corporation. https://www.ffmpeg.org FFTW is a C subroutine library for computing the discrete Fourier transform (DFT) in one or more dimensions, of arbitrary input size, and of both real and 13 fftw complex data (as well as of even/odd data, i.e. -

Optimizing the Use of Open-Source Software Applications in Drug
DDT • Volume 11, Number 3/4 • February 2006 REVIEWS TICS INFORMA Optimizing the use of open-source • software applications in drug discovery Reviews Werner J. Geldenhuys1, Kevin E. Gaasch2, Mark Watson2, David D. Allen1 and Cornelis J.Van der Schyf1,3 1Department of Pharmaceutical Sciences, School of Pharmacy,Texas Tech University Health Sciences Center, Amarillo,TX, USA 2West Texas A&M University, Canyon,TX, USA 3Pharmaceutical Chemistry, School of Pharmacy, North-West University, Potchefstroom, South Africa Drug discovery is a time consuming and costly process. Recently, a trend towards the use of in silico computational chemistry and molecular modeling for computer-aided drug design has gained significant momentum. This review investigates the application of free and/or open-source software in the drug discovery process. Among the reviewed software programs are applications programmed in JAVA, Perl and Python, as well as resources including software libraries. These programs might be useful for cheminformatics approaches to drug discovery, including QSAR studies, energy minimization and docking studies in drug design endeavors. Furthermore, this review explores options for integrating available computer modeling open-source software applications in drug discovery programs. To bring a new drug to the market is very costly, with the current of combinatorial approaches and HTS. The addition of computer- price tag approximating US$800 million, according to data reported aided drug design technologies to the R&D approaches of a com- in a recent study [1]. Therefore, it is not surprising that pharma- pany, could lead to a reduction in the cost of drug design and ceutical companies are seeking ways to optimize costs associated development by up to 50% [6,7].