Package 'Tesseract'
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Ubuntu Kung Fu
Prepared exclusively for Alison Tyler Download at Boykma.Com What readers are saying about Ubuntu Kung Fu Ubuntu Kung Fu is excellent. The tips are fun and the hope of discov- ering hidden gems makes it a worthwhile task. John Southern Former editor of Linux Magazine I enjoyed Ubuntu Kung Fu and learned some new things. I would rec- ommend this book—nice tips and a lot of fun to be had. Carthik Sharma Creator of the Ubuntu Blog (http://ubuntu.wordpress.com) Wow! There are some great tips here! I have used Ubuntu since April 2005, starting with version 5.04. I found much in this book to inspire me and to teach me, and it answered lingering questions I didn’t know I had. The book is a good resource that I will gladly recommend to both newcomers and veteran users. Matthew Helmke Administrator, Ubuntu Forums Ubuntu Kung Fu is a fantastic compendium of useful, uncommon Ubuntu knowledge. Eric Hewitt Consultant, LiveLogic, LLC Prepared exclusively for Alison Tyler Download at Boykma.Com Ubuntu Kung Fu Tips, Tricks, Hints, and Hacks Keir Thomas The Pragmatic Bookshelf Raleigh, North Carolina Dallas, Texas Prepared exclusively for Alison Tyler Download at Boykma.Com Many of the designations used by manufacturers and sellers to distinguish their prod- ucts are claimed as trademarks. Where those designations appear in this book, and The Pragmatic Programmers, LLC was aware of a trademark claim, the designations have been printed in initial capital letters or in all capitals. The Pragmatic Starter Kit, The Pragmatic Programmer, Pragmatic Programming, Pragmatic Bookshelf and the linking g device are trademarks of The Pragmatic Programmers, LLC. -

Michael Sharpe
294 TUGboat, Volume 38 (2017), No. 3 Interview: Michael Sharpe complex machinery, though I did spend a couple of years working as an assistant to a projectionist in David Walden the local movie theater during my high school years. DW : When you say \misspent on sport", what are you thinking of? MS: Because we moved regularly, I was motivated to focus on making new friends as quickly as possible, and sport was a good way to do it in that environ- ment. I played cricket, Australian Rules football and tennis. It was fortunate for my later career that I was not really good at any of them. DW : Were you already doing electronics things as a hobby and enjoying high school math and science before university? MS: I was not into electronics as a hobby, finding Michael Sharpe has been using TEX since the mid- the analog radio of those days not very interesting. 1980s. In more recent years he has been active in I did do well in sciences and math in high school. If the TEX fonts world. there had been computers available in those days, it may have been a different story. Dave Walden, interviewer: Please tell me a bit DW : What took you away from Australia and to about yourself. Yale for your Ph.D. work? Michael Sharpe, interviewee: I was born in Syd- MS: Just previous to my generation of college grad- ney, Australia in 1941. After 1945, my father joined uates in Australia, most students wanting to pursue the Commonwealth Public Service, which corresponds an advanced degree in sciences and engineering went in the US to the federal civil service, and moved fre- to Great Britain if they could manage it. -

4C24fb34-Ubuntu-Server-Guide.Pdf
Introduction Welcome to the Ubuntu Server Guide! Download the Ubuntu server guide as a PDF. This is the preliminary and in development for the next Ubuntu LTS, Focal Fossa. Contents may have errors and omissions. Changes, Errors, and Bugs If you find any errors or have suggestions for improvements to pages, please use the link at thebottomof each topic titled: “Help improve this document in the forum.” This link will take you to the Server Discourse forum for the specific page you are viewing. There you can share your comments or let us know aboutbugs with each page. Support There are a couple of different ways that Ubuntu Server Edition is supported: commercial support and community support. The main commercial support (and development funding) is available from Canonical, Ltd. They supply reasonably- priced support contracts on a per desktop or per server basis. For more information see the Ubuntu Advantage page. Community support is also provided by dedicated individuals and companies that wish to make Ubuntu the best distribution possible. Support is provided through multiple mailing lists, IRC channels, forums, blogs, wikis, etc. The large amount of information available can be overwhelming, but a good search engine query can usually provide an answer to your questions. See the Ubuntu Support page for more information. Installation This chapter provides a quick overview of installing Ubuntu 20.04 Server Edition. For more detailed instruc- tions, please refer to the Ubuntu Installation Guide. Preparing to Install This section explains various aspects to consider before starting the installation. System Requirements Ubuntu 20.04 Server Edition provides a common, minimalist base for a variety of server applications, such as file/print services, web hosting, email hosting, etc. -

Software Decode SDK for Android Developer Guide (En)
SOFTWARE DECODE SDK FOR ANDROID DEVELOPER GUIDE SOFTWARE DECODE SDK FOR ANDROID DEVELOPER GUIDE 72E-162670-06 Revision A November 2016 ii Software Decode SDK for Android Developer Guide No part of this publication may be reproduced or used in any form, or by any electrical or mechanical means, without permission in writing from Zebra. This includes electronic or mechanical means, such as photocopying, recording, or information storage and retrieval systems. The material in this manual is subject to change without notice. The software is provided strictly on an “as is” basis. All software, including firmware, furnished to the user is on a licensed basis. Zebra grants to the user a non-transferable and non-exclusive license to use each software or firmware program delivered hereunder (licensed program). Except as noted below, such license may not be assigned, sublicensed, or otherwise transferred by the user without prior written consent of Zebra. No right to copy a licensed program in whole or in part is granted, except as permitted under copyright law. The user shall not modify, merge, or incorporate any form or portion of a licensed program with other program material, create a derivative work from a licensed program, or use a licensed program in a network without written permission from Zebra. The user agrees to maintain Zebra’s copyright notice on the licensed programs delivered hereunder, and to include the same on any authorized copies it makes, in whole or in part. The user agrees not to decompile, disassemble, decode, or reverse engineer any licensed program delivered to the user or any portion thereof. -

INDICATORS) • a Tuple Containing All Allowed Vocabulary Terms: ALLOWED VALUES, Which Is Use for Input Validation
python-stix Documentation Release 1.2.0.11 The MITRE Corporation November 16, 2020 Contents 1 Versions 3 2 Contents 5 2.1 Installation................................................5 2.2 Getting Started..............................................6 2.3 Overview.................................................8 2.4 Examples................................................. 13 2.5 APIs or bindings?............................................ 14 3 API Reference 17 3.1 API Reference.............................................. 17 3.2 API Coverage.............................................. 103 4 FAQ 107 5 Contributing 109 6 Indices and tables 111 Python Module Index 113 i ii python-stix Documentation, Release 1.2.0.11 Version: 1.2.0.11 The python-stix library provides an API for developing and consuming Structured Threat Information eXpression (STIX) content. Developers can leverage the API to develop applications that create, consume, translate, or otherwise process STIX content. This page should help new developers get started with using this library. For more information about STIX, please refer to the STIX website. Note: These docs provide standard reference for this Python library. For documentation on idiomatic usage and common patterns, as well as various STIX-related information and utilities, please visit the STIXProject at GitHub. Contents 1 python-stix Documentation, Release 1.2.0.11 2 Contents CHAPTER 1 Versions Each version of python-stix is designed to work with a single version of the STIX Language. The table below shows the latest version the library for each version of STIX. STIX Version python-stix Version 1.2 1.2.0.11 (PyPI)(GitHub) 1.1.1 1.1.1.18 (PyPI)(GitHub) 1.1.0 1.1.0.6 (PyPI)(GitHub) 1.0.1 1.0.1.1 (PyPI)(GitHub) 1.0 1.0.0a7 (PyPI)(GitHub) Users and developers working with multiple versions of STIX content may want to take a look at stix-ramrod, which is a library designed to update STIX and CybOX content. -

Ubuntu Server Guide Basic Installation Preparing to Install
Ubuntu Server Guide Welcome to the Ubuntu Server Guide! This site includes information on using Ubuntu Server for the latest LTS release, Ubuntu 20.04 LTS (Focal Fossa). For an offline version as well as versions for previous releases see below. Improving the Documentation If you find any errors or have suggestions for improvements to pages, please use the link at thebottomof each topic titled: “Help improve this document in the forum.” This link will take you to the Server Discourse forum for the specific page you are viewing. There you can share your comments or let us know aboutbugs with any page. PDFs and Previous Releases Below are links to the previous Ubuntu Server release server guides as well as an offline copy of the current version of this site: Ubuntu 20.04 LTS (Focal Fossa): PDF Ubuntu 18.04 LTS (Bionic Beaver): Web and PDF Ubuntu 16.04 LTS (Xenial Xerus): Web and PDF Support There are a couple of different ways that the Ubuntu Server edition is supported: commercial support and community support. The main commercial support (and development funding) is available from Canonical, Ltd. They supply reasonably- priced support contracts on a per desktop or per-server basis. For more information see the Ubuntu Advantage page. Community support is also provided by dedicated individuals and companies that wish to make Ubuntu the best distribution possible. Support is provided through multiple mailing lists, IRC channels, forums, blogs, wikis, etc. The large amount of information available can be overwhelming, but a good search engine query can usually provide an answer to your questions. -

Ultimate++ Forum It Higher Priority Now
Subject: It's suspected to be an issue with Font. Posted by Lance on Fri, 18 Mar 2011 22:50:28 GMT View Forum Message <> Reply to Message The programs I used to compare are UWord from the UPP, and MS Word. The platform is Windows 7. The text I used to test is: The problem with U++ drawed text is that some characters are notably larger than others and some have incorrect horizontal displacement. Please see attached picture for a visual effect. I also encountered issue where chinese characters are displayed correctly displayed on Windows but are blank on Ubuntu. And when I copies the same text that was displayed as blank to, say gedit, the text displayed correctly as in Windows. That part I will attach picture in future. File Attachments 1) font problem.png, downloaded 650 times Subject: Re: It's suspected to be an issue with Font. Posted by mirek on Sun, 10 Apr 2011 12:42:52 GMT View Forum Message <> Reply to Message Lance wrote on Fri, 18 March 2011 18:50The programs I used to compare are UWord from the UPP, and MS Word. The platform is Windows 7. The text I used to test is: The problem with U++ drawed text is that some characters are notably larger than others and some have incorrect horizontal displacement. It works fine on my Windows 7. However, I believe that the problem is caused by font substitution mechanism and perhaps on your system, you have some font that takes precendence for some glyphs, but does not contain other characters. -

Ubuntu Kung Fu.Pdf
Prepared exclusively for J.S. Ash Beta Book Agile publishing for agile developers The book you’re reading is still under development. As part of our Beta book program, we’re releasing this copy well before we normally would. That way you’ll be able to get this content a couple of months before it’s available in finished form, and we’ll get feedback to make the book even better. The idea is that everyone wins! Be warned. The book has not had a full technical edit, so it will con- tain errors. It has not been copyedited, so it will be full of typos and other weirdness. And there’s been no effort spent doing layout, so you’ll find bad page breaks, over-long lines with little black rectan- gles, incorrect hyphenations, and all the other ugly things that you wouldn’t expect to see in a finished book. We can’t be held liable if you use this book to try to create a spiffy application and you somehow end up with a strangely shaped farm implement instead. Despite all this, we think you’ll enjoy it! Throughout this process you’ll be able to download updated PDFs from your account on http://pragprog.com. When the book is finally ready, you’ll get the final version (and subsequent updates) from the same address. In the meantime, we’d appreciate you sending us your feedback on this book at http://books.pragprog.com/titles/ktuk/errata, or by using the links at the bottom of each page. -

Ubuntu Typography – a Guide
Ubuntu Guide Ubuntu Typography – A Guide Ubuntu is the preferred typeface of Special Olympics. It should be used for informational communications produced by Special Olympics. What does the word “Ubuntu” mean? Ubuntu is a Nguni word which has no direct translation into English, but is used to describe a particular African worldview in which people can only find fulfillment through interacting with other people. Thus it represents a spirit of kinship across both race and creed which unites mankind to a common purpose. Archbishop Emeritus Desmond Tutu has said "Ubuntu is very difficult to render into a Western language…It is to say. 'My humanity is caught up, is inextricably bound up, in what is yours'…"1 Why has Ubuntu been chosen? Ubuntu has been chosen for clarity and accessibility both in print and on screen. It is available free of charge in a range of weights and styles. In what languages does Ubuntu appear? Ubuntu currently comes in a range of languages: Latin (Western), Greek & Cyrillic. Note: Arabic and Hebrew versions of Ubuntu are now under development. Please remember! If using Ubuntu typeface within Microsoft office documents (word/powerpoint) please note that these documents should only be shared with third parties or member of the public in PDF format. Otherwise Arial should be used in place of Ubuntu. Arial is available as standard on all PC and Mac computers. How can I access Ubuntu? Ubuntu is available as a free Mac or P.C. download at font.ubuntu.com Here are the steps to follow for a successful download: 1 No Future Without Forgiveness: A Personal Overview of South Africa's Truth and Reconciliation Commission, Desmond Tutu, © 2000. -

Installation and Configuration Guide
Installation and Configuration Guide SOGo v5.1.1 Table of Contents 1. About this Guide . 2 2. Introduction . 3 2.1. Architecture and Compatibility . 3 3. System Requirements . 6 3.1. Assumptions . 6 3.2. Minimum Hardware Requirements. 6 3.3. Operating System Requirements . 7 4. Installation . 9 4.1. Software Downloads . 9 4.2. Software Installation . 10 5. Configuration. 11 5.1. GNUstep Environment Overview . 11 5.2. Preferences Hierarchy . 11 5.3. General Preferences . 12 5.4. Authentication using LDAP. 24 5.5. LDAP Attributes Indexing . 31 5.6. LDAP Attributes Mapping . 32 5.7. Authenticating using C.A.S.. 33 5.8. Authenticating using SAML2 . 35 5.9. Database Configuration . 35 5.10. Authentication using SQL . 40 5.11. SMTP Server Configuration . 43 5.12. IMAP Server Configuration. 44 5.13. Web Interface Configuration . 47 5.14. SOGo Configuration Summary. 57 5.15. Multi-domains Configuration . 58 5.16. Apache Configuration . 60 5.17. Starting Services . 61 5.18. Cronjob — EMail reminders. 61 5.19. Cronjob — Vacation messages activation and expiration . 62 6. Managing User Accounts . 63 6.1. Creating the SOGo Administrative Account . 63 6.2. Creating a User Account . 63 7. Microsoft Enterprise ActiveSync . 65 8. Microsoft Enterprise ActiveSync Tuning . 68 9. S/MIME Support in SOGo . 70 10. Using SOGo. 71 10.1. SOGo Web Interface. 71 10.2. Mozilla Thunderbird and Lightning . 71 10.3. Apple Calendar (macOS, iOS, iPadOS). 72 10.4. Apple AddressBook . 72 10.5. Microsoft ActiveSync . 73 11. Upgrading . 74 12. Additional Information . 76 13. Commercial Support and Contact Information . -
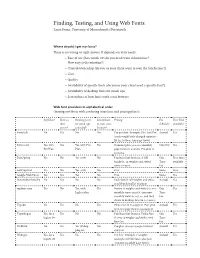
Finding, Testing, and Using Web Fonts Laura Franz, University of Massachusetts Dartmouth 1
Finding, Testing, and Using Web Fonts Laura Franz, University of Massachusetts Dartmouth 1 Finding, Testing, and Using Web Fonts Laura Franz, University of Massachusetts Dartmouth Where should I get my fonts? There is no wrong or right answer. It depends on your needs. • Ease of use (how much CSS do you need/want to know/use? How easy is the interface?) • Control/ownership (do you or your client want to own the font license?) • Cost • Quality • Availability of specific fonts (do you or your client need a specific font?) • Availability of desktop fonts for mock-ups • Screenshots of how fonts work cross browser Web font providers in alphabetical order (leaving out those with confusing interfaces and pricing plans): Self Host? Host on Desktop fonts Screenshots Pricing Fee Free Trial their for mock-ups of fonts cross Schedule available? server? provided? browser? Fontdeck No Yes No No Pay per font. Example: Din Text Pro Annual Yes (each weight/style charged separate- ly) $12.50/year. (1m page views) Fonts.com Yes, with Yes Yes, with Pro Yes Standard plan (500,000 monthly Monthly Yes Pro Plan Plan page views) is $20/mo. Pro plan is $100/mo. FontSpring Yes No Yes (otf) No Purchase font licenses. A full One Free fonts family (3–14 weights and styles) Time available costs $0–$300. Fee FontSquirrel Yes No Yes (otf) No Free None Free Google Web Fonts Yes Yes Yes No Free None Yes Justanotherfoundry No Yes No No Each family (all weights and styles, Annual Yes 2gb/Month traffic) €19/year myfonts.com Yes No Yes, with Yes Futura (6 weights and styles) 10,000 One Yes higher plan monthly views $133.68. -

9780857191274 Sample.Pdf
• • • • Sample • • • • Emoti-coms About the Authors Xavier Quattrocchi-Oubradous is an artist-turned- investment-banker-turned-media-entrepreneur. After many years of cello practice, trying unsuccessfully to emulate his family roots, he graduated in management at Dauphine University, Paris and in political sciences at Sciences Po, Paris. His business career started with financing industrial projects at investment banks Calyon and GE Capital. He then launched a series of businesses in the marketing and communications industry – including QobliQ, a multinational group offering digital, sponsorship, corporate social responsibility (CSR), social media and experiential marketing services. He has published several articles in Admap . Dr Charles Bal was research manager and is now head of brandRapport France, a sponsorship and associative marketing consultancy owned by QobliQ Group. He has developed a new family of sponsorship measurements that take into account the highly emotional nature of sponsorship. As part of a cotutelle agreement between the University of Paris- 1 Panthéon Sorbonne (France) and the University of Adelaide (Australia), in 2010 Charles completed a PhD examining the role played by emotions in the sponsorship persuasion process. He has already presented his results at marketing conferences in Europe and Asia-Pacific, and has published his work in several international reviews ( Journal of Sponsorship , Asia-Pacific Journal of Marketing & Logistics , Admap ). Emoti-coms A mArkEting guidE to communicAting through Emotions From shouting to singing your message by XAviEr QuAttrocchi-oubrAdous & chArlEs bAl Hh HARRIMAN HOUSE LTD 3A Penns Road Petersfield Hampshire GU32 2EW GREAT BRITAIN Tel: +44 (0)1730 233870 Fax: +44 (0)1730 233880 Email: [email protected] Website: www.harriman-house.com First published in Great Britain in 2011 Copyright © Harriman House Ltd The right of Xavier Quattrocchi-Oubradous and Charles Bal to be identified as the Authors has been asserted in accordance with the Copyright, Design and Patents Act 1988.