Tools for Cloud Infrastructure: Build & Release
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Paas Solutions Evaluation
PaaS solutions evaluation August 2014 Author: Sofia Danko Supervisors: Giacomo Tenaglia Artur Wiecek CERN openlab Summer Student Report 2014 CERN openlab Summer Student Report 2014 Project Specification OpenShift Origin is an open source software developed mainly by Red Hat to provide a multi- language PaaS. It is meant to allow developers to build and deploy their applications in a uniform way, reducing the configuration and management effort required on the administration side. The aim of the project is to investigate how to deploy OpenShift Origin at CERN, and to which extent it could be integrated with CERN "Middleware on Demand" service. The student will be exposed to modern cloud computing concepts such as PaaS, and will work closely with the IT middleware experts in order to evaluate how to address service needs with a focus on deployment in production. Some of the tools that are going to be heavily used are Puppet and Openstack to integrate with the IT infrastructure. CERN openlab Summer Student Report 2014 Abstract The report is a brief summary of Platform as a Service (PaaS) solutions evaluation including investigation the current situation at CERN and Services on Demand provision, homemade solutions, external market analysis and some information about PaaS deployment process. This first part of the report is devoted to the current status of the process of deployment OpenShift Origin at existing infrastructure at CERN, as well as specification of the common issues and restrictions that were found during this process using different machines for test. Furthermore, the following open source software solutions have been proposed for the investigation of possible PaaS provision at CERN: OpenShift Online; Cloud Foundry; Deis; Paasmaster; Cloudify; Stackato; WSO2 Stratos. -

Openshift Vs Pivotal Cloud Foundry Comparison Red Hat Container Stack - Pivotal Cloud Foundry Stack
OPENSHIFT VS PIVOTAL CLOUD FOUNDRY COMPARISON RED HAT CONTAINER STACK - PIVOTAL CLOUD FOUNDRY STACK 3 AT A GLANCE PIVOTAL CF OPENSHIFT • ●Garden and Diego • ●Docker and Kubernetes • ●.NET and Spring • ●.NET, Spring and JBoss Middleware • ●Only Cloud-native apps (including full Java EE) • ●Container security on Ubuntu • ●Cloud-native and stateful apps • ●Deployment automation • ●Enterprise-grade security on • ●Open Core Red Hat Enterprise Linux • ●Pivotal Labs consulting method • ●Complete Ops Management • ●100% Open Source 5X PRICE • ●Red Hat Innovation Labs consulting method BRIEF COMPARISON PIVOTAL CF OPENSHIFT GARDEN & DIEGO DOCKER & KUBERNETES • ●Garden uses OCI runC backend • ●Portable across all docker platforms • ●Not portable across Cloud Foundry distros • ●IP per container • ●Containers share host IP • ●Integrated image registry • ●No image registry • ●Image build from source and binary • ●Private registries are not supported • ●Adoption in many solutions • ●No image build • ●Adoption only in Cloud Foundry 11 NO NATIVE DOCKER IN CLOUD FOUNDRY Converters Are Terrible Cloud Foundry is based on the Garden container runtime, not Docker, and then has RunC and Windows backends. RunC is not Docker, just the lowest runtime layer Docker Developer Experience Does Not Exist in PCF PCF “cf push” Dev Experience does not exist for Docker. In Openshift v3 we built S2I to provide that same experience on top of native Docker images/containers Diego Is Not Kubernetes Kubernetes has become the defacto standard for orchestrating docker containers. -

From a Pipeline to a Government Cloud
From a pipeline to a government cloud Toby Lorne SRE @ GOV.UK Platform-as-a-Service www.toby.codes github.com/tlwr github.com/alphagov From a pipeline to a government cloud How the UK government deploy a Platform-as-a-Service using Concourse, an open-source continuous thing-doer From a pipeline to a government cloud 1. GOV.UK PaaS overview 2. Concourse overview 3. Pipeline walkthrough 4. Patterns and re-use What is GOV.UK PaaS? What is a Platform-as-a Service? What are some challenges with digital services in government? How does GOV.UK PaaS make things better? What is a PaaS? Run, manage, and maintain apps and backing services Without having to buy, manage, and maintain infrastructure or needing specialist expertise Here is my source code Run it for me in the cloud I do not care how Deploy to production safer and faster Reduce waste in the development process Proprietary Open source Heroku Cloud Foundry Pivotal application service DEIS EngineYard Openshift Google App Engine kf AWS Elastic Beanstalk Dokku Tencent BlueKing Rio Why does government need a PaaS? UK-based web hosting for government services Government should focus on building useful services, not managing infrastructure Enable teams to create services faster Reduce the cost of procurement and maintenance An opinionated platform promotes consistency Communication within large bureaucracies can be slow Diverse app workloads are impossible to reason about Highly leveraged team requires trust and autonomy Only able to do this because of open source software and communities APPS -

60 Recipes for Apache Cloudstack
60 Recipes for Apache CloudStack Sébastien Goasguen 60 Recipes for Apache CloudStack by Sébastien Goasguen Copyright © 2014 Sébastien Goasguen. All rights reserved. Printed in the United States of America. Published by O’Reilly Media, Inc., 1005 Gravenstein Highway North, Sebastopol, CA 95472. O’Reilly books may be purchased for educational, business, or sales promotional use. Online editions are also available for most titles (http://safaribooksonline.com). For more information, contact our corporate/ institutional sales department: 800-998-9938 or [email protected]. Editor: Brian Anderson Indexer: Ellen Troutman Zaig Production Editor: Matthew Hacker Cover Designer: Karen Montgomery Copyeditor: Jasmine Kwityn Interior Designer: David Futato Proofreader: Linley Dolby Illustrator: Rebecca Demarest September 2014: First Edition Revision History for the First Edition: 2014-08-22: First release See http://oreilly.com/catalog/errata.csp?isbn=9781491910139 for release details. Nutshell Handbook, the Nutshell Handbook logo, and the O’Reilly logo are registered trademarks of O’Reilly Media, Inc. 60 Recipes for Apache CloudStack, the image of a Virginia Northern flying squirrel, and related trade dress are trademarks of O’Reilly Media, Inc. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and O’Reilly Media, Inc. was aware of a trademark claim, the designations have been printed in caps or initial caps. While every precaution has been taken in the preparation of this book, the publisher and authors assume no responsibility for errors or omissions, or for damages resulting from the use of the information contained herein. -

When I Kube All the Things, What Can Watch Kubernetes?
When I Kube All the Things, What Can Watch Kubernetes? Kira Boyle Pivotal Cloud Foundry @kiracboyle Who am I? Gameplan • What is Kubernetes? • What is Kubernetes Missing? • What is BOSH • Intro to the Cloud Foundry Container Runtime • Why Cloud Foundry Container Runtime? What is Kubernetes? What is Kubernetes? What is Kubernetes? • Deploy • Scale • Operate • Automate What is Kubernetes? Node Container Container Container Container Pod Pod Master Node Container Container Container Container Container Container Pod Pod Pod What is Kubernetes? kube- kube- apiserver scheduler Master controller etcd manager What is Kubernetes? kubectl What is Kubernetes? Kubernetes the hard way: https://github.com/kelseyhightower/kubernetes-the- hard-way https://www.youtube.com/watch?v=kOa_llowQ1c What is Kubernetes? ● Live config editing ● Zero downtime ● Granular config options ● Self contained apps What is Kubernetes Missing? What is Kubernetes Missing? • Deploying multiple clusters easily • Does not build or deploy source code • Ability to self-heal • https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/ Enter a VM Management Solution What is BOSH? VM Management: • Identifiable • Reproducible • Consistent • Agile What is BOSH? STEMCELL RELEASE MANIFEST DEPLOYMENT What is BOSH? STEMCELL https://bosh.io/stemcells What is BOSH? STEMCELLRELEASE Job Package Source Blob Common Releases:https://bosh.io/releases What is BOSH? RELEASE myproduct.sh Common Releases:https://bosh.io/releases What is BOSH? MANIFESTRELEASE RELEASE STEMCELL RELEASE RELEASE -

Annual Report 2018
Annual Report 2018 January 2019 In 2018, the Foundation expanded its definition of Cloud Foundry, shifting away from prioritizing the Application Runtime in order to spread awareness of the many projects that comprise Cloud Foundry technologies. This new messaging aligned with the 2018 vision for interoperability, a theme that underpinned all Foundation content. The interoperability of Cloud Foundry was evident across the ecosystem -- in the technologies integrated into the platform itself to the technologies with which Cloud Foundry integrates to form a multi-platform strategy. This year, the Foundation launched a Certified Systems Integrators program, announced new Certified Providers Cloud.gov and SUSE, accepted interoperable projects Eirini and CF Containerization into the Project Management Council and published four research reports -- while planning and hosting two major Summits and six Cloud Foundry Days. Like the platform itself, the Cloud Foundry Foundation has reached a new level of maturity and continues to evolve. Cloud Foundry Foundation Annual Report 2018 2 2018 Highlights TECHNICAL & COMMUNITY • Interoperability: Two new projects were accepted by the Project Management Committees in order to further integrate Kubernetes with Cloud Foundry technologies. CF Containerization, initially developed and donated to the Foundation by SUSE, is designed to package Cloud Foundry BOSH releases into containers and deploy those containers into Kubernetes. Eirini, proposed by IBM and seeing contributions from IBM, SUSE and SAP, is working towards allowing operators and product vendors to use Kubernetes as the underlying container scheduler for the Cloud Foundry Application Runtime. • 2018 Certified Providers: In 2018, Cloud.gov and SUSE joined the list of certified providers of Cloud Foundry, bringing the total to eight -- the other six being Atos, Huawei, IBM, Pivotal, SAP and Swisscom. -

PRÉSENTATION DE BOSH Par Vmware PRÉSENTATION DE BOSH
LIVRE BLANC – AOÛT 2017 PRÉSENTATION DE BOSH par VMware PRÉSENTATION DE BOSH Sommaire Qu’est-ce que BOSH ? ........................................................................................................ 3 Présentation de BOSH...............................................................................................................3 Quels problèmes BOSH permet-il de résoudre ? .........................................................4 Cas d’usage de BOSH ................................................................................................................6 Déploiement de BOSH .......................................................................................................8 Architecture de BOSH ...............................................................................................................8 Informations de référence sur BOSH .................................................................................8 Instructions : Comment déployer Kubo sur vSphere .............................................9 Procédure de déploiement de BOSH (pour Mac OSX) ...........................................9 Procédure de déploiement de Kubo sur BOSH .........................................................10 LIVRE BLANC | 2 PRÉSENTATION DE BOSH Qu’est-ce que BOSH ? Présentation de BOSH BOSH est un outil Open Source qui permet d’assurer le déploiement et de gérer le cycle de vie des systèmes distribués. Principale méthode de déploiement de Cloud Foundry, BOSH bénéficie de la contribution de nombreux membres éminents -
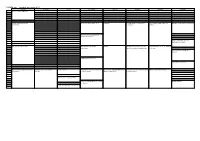
FOSDEM 2013 Schedule
FOSDEM 2013 - Saturday 2013-02-02 (1/9) Janson K.1.105 Ferrer Chavanne Lameere H.1301 H.1302 H.1308 10:30 Welcome to FOSDEM 2013 10:45 11:00 How we made the Jenkins QEMU USB status report 2012 Rockbuild The neat guide to Fedora RPM LinuxonAndroid and SlapOS on Wayland for Application Developers community Packaging Android 11:15 11:30 CRIU: Checkpoint and Restore (mostly) In Userspace 11:45 Ubuntu Online Accounts for application developers 12:00 The Devil is in the Details Vtrill: Rbridges for Virtual PTXdist Building RPM packages from Git Emdedded distro shootout: buildroot Networking repositories with git-buildpackage vs. Debian Better software through user 12:15 research 12:30 Bringing Xen to CentOS-6 Sketching interactions 12:45 13:00 The Open Observatory of Network Porting Fedora to 64-bit ARM Coding Goûter A brief tutorial on Xen's advanced Guacamayo -- Building Multimedia Package management and creation ARM v7 State of the Body ↴ Interference systems security features Appliance with Yocto ↴ in Gentoo Linux ↴ 13:15 Spoiling and Counter-spoiling 13:30 oVirt Live Storage Migration - Under Modern CMake ↴ the Hood ↴ ZONE: towards a better news feed ↴ 13:45 FOSDEM 2013 - Saturday 2013-02-02 (2/9) H.1309 H.2213 H.2214 AW1.120 AW1.121 AW1.125 AW1.126 Guillissen 10:30 10:45 11:00 Metaphor and BDD XMPP 101 Storytelling FLOSS Welcome and Introduction The room open() process Scripting Apache OpenOffice: Welcome to the Perl d… Introductory Nutshell Programs Inheritance versus Roles (Writer, Calc, Impress) 11:15 Signal/Collect: Processing Large -

Extending Openstack Iaas with Cloud Foundry Paas
Intel IT Cloud Extending OpenStack* IaaS with Cloud Foundry* PaaS Speaker: Catherine Spence, IT Principal Engineer, Cloud Computing Acknowledgements: Aaron Huber, Jon Price November 2014 Legal Notices This presentation is for informational purposes only. INTEL MAKES NO WARRANTIES, EXPRESS OR IMPLIED, IN THIS SUMMARY. Intel and the Intel logo are trademarks of Intel Corporation in the U.S. and/or other countries. * Other names and brands may be claimed as the property of others. Copyright © 2014, Intel Corporation. All rights reserved. Copyright © 2014, Intel Corporation. All rights reserved. Agenda • Intel IT Vital Statistics • Cloud Direction, ODCA Cloud Adoption Roadmap • Intel IT Cloud, PaaS Concept, Selection & Usage • Cloud Foundry* Architecture • Provisioning on OpenStack* • Challenges • Capability Roadmap, Future Hybrid Strategy • Summary Copyright © 2014, Intel Corporation. All rights reserved. 2014 Intel IT Vital Statistics >6,300 IT employees 59 global IT sites >98,000 Intel employees1 168 Intel sites in 65 Countries 64 Data Centers (91 Data Centers in 2010) 80% of servers virtualized (42% virtualized in 2010) >147,000+ Devices 100% of laptops encrypted 100% of laptops with SSDs >43,200 handheld devices 57 mobile applications developed Source: Information provided by Intel IT as of Jan 2014 1Total employee count does not include wholly owned subsidiaries that Intel IT does not directly support 4 Copyright © 2014, Intel Corporation. All rights reserved. INTEL IT’S CLOUD JOURNEY Start Today Future • Increased SaaS and • SaaS for large • SaaS Playbook Cloud-Aware Apps scale, standard • IaaS & PaaS, • Common IaaS Control processes emerging hybrid Plane • On-premise hosting • SDN rolled out • Provision physical • Server Virtualization • Database as a Service servers same as virtual • Infrastructure as a • Smart orchestration Service Dynamic, Flexible and Scalable Service Delivery at Reduced Cost Copyright © 2014, Intel Corporation. -

Cloud Computing
Cloud Computing . Overview 1. Genesis of Cloud Computing 2. What is Cloud Computing? Raj Jain 3. Why Use Clouds? Washington University in Saint Louis Saint Louis, MO 63130 4. Cloud Deployment Models [email protected] 5. Cloud Software and Standards These slides and audio/video recordings of this class lecture are at: 6. Software Defined Intelligence http://www.cse.wustl.edu/~jain/cse570-18/ Washington University in St. Louis http://www.cse.wustl.edu/~jain/cse570-18/ ©2018 Raj Jain Washington University in St. Louis http://www.cse.wustl.edu/~jain/cse570-18/ ©2018 Raj Jain 20-1 20-2 Genesis of Cloud Computing Cloud Enabled by Networking August 25, 2006: Amazon announced EC2 Birth of Cloud Computing in reality (Prior theoretical concepts of computing as a utility) Amazon’s CEO was amazed by the number of computers in Clouds their datacenter and their low utilization Large Computing facilities are designed for peak load (Christmas) Low Average Datacenters Needed a way to rent unused capacity, like renting their Demand warehouses and other infrastructure Virtualization Develop an application programming interfaces (APIs) to remotely use computers. Storage/Compute/ So began the computer rental business that we now call cloud Network computing. High Speed Sharing an underutilized resource is good for cloud service customers as well as for the cloud service providers. Networking Ref: Raj Jain and Subharthi Paul, "Network Virtualization and Software Defined Networking for Cloud Computing - A Survey," IEEE Communications Magazine, Nov 2013, pp. 24-31, ISSN: 01636804, DOI: 10.1109/MCOM.2013.6658648, http://www.cse.wustl.edu/~jain/papers/net_virt.htm Washington University in St. -

JMX Bridge for PCF Documentation
JMX Bridge for PCF® Documentation Version 1.9 Published: 29 Jan 2019 © 2019 Pivotal Software, Inc. All Rights Reserved. Table of Contents Table of Contents 2 Pivotal Cloud Foundry JMX Bridge 3 Deploying JMX Bridge 4 Using JMX Bridge 15 Using SSL with a Self-Signed Certificate in JMX Bridge 16 JMX Bridge Resources 20 Troubleshooting and Uninstalling JMX Bridge 21 Application Security Groups 24 Release Notes and Known Issues 25 © Copyright Pivotal Software Inc, 2013-present 2 1.9 Pivotal Cloud Foundry JMX Bridge IMPORTANT: The Pivotal Cloud Foundry (PCF) JMX Bridge tile is deprecated, and no further development will be made against this product. The Pivotal Cloud Foundry (PCF) JMX Bridge collects and exposes system data from Cloud Foundry components via a JMX endpoint. You can use this system data to monitor your installation and assist in troubleshooting. The JMX Bridge tool is composed of the following two VMs: The JMX provider A Nozzle for the Loggregator Firehose . For more information about how a Firehose nozzle works, see Nozzles . Product Snapshot The following table provides version and version-support information about PCF JMX Bridge. Element Details Version v1.9.9 Release date February 9, 2018 Compatible Ops Manager version(s) v1.11.3 or later, v1.12.x, v2.0.x, v2.1.x, v2.2.x Compatible Elastic Runtime version(s) v1.11.x, 1.12.x Compatible Pivotal Application Service version(s) v2.0.x, v2.1.x, v2.2.x IaaS support AWS, Azure, GCP, OpenStack, and vSphere IPsec support? Yes JMX Bridge User Guide Deploying JMX Bridge Using JMX Bridge Using SSL with a Self-Signed Certificate in JMX Bridge Resources Troubleshooting and Uninstalling JMX Bridge Application Security Groups Release Notes and Known Issues View the source for this page in GitHub © Copyright Pivotal Software Inc, 2013-present 3 1.9 Deploying JMX Bridge Page last updated: The JMX Bridge tool is a JMX extension for Elastic Runtime. -

PCF on Google Cloud Platform (GCP)
AMAZON WEB SERVICES VS GOOGE CLOUD PLATFORM FOR PCF PCF on AWS AWS provide support on its cloud platform (IaaS) to implement PCF. AWS also provides service broker utilizing AWS feature for PCF. Following services are supported. Amazon RDS for PostgreSQL Amazon S3 Amazon RDS for MySQL Amazon Aurora Amazon RDS for SQL Server Amazon Dynamo DB Amazon RDS for Oracle Database Amazon RDS for Maria DB Amazon SQS Integration of PCF on AWS Integration Feature-: Option to broker a connection to a service running external to Pivotal Cloud Foundry. Option to create and destroy the service instance on demand as required. Version choice. Operators can let developers choose between multiple versions of the software when creating an instance. Encryption at rest. Stored data is encrypted. Multi-Availability Zone support. Make use of multiple availability zones in cloud deployments to support failover. Quotas. Operators can place limits on service instance counts. HCL Technologies Ltd 1 AMAZON WEB SERVICES VS GOOGE CLOUD PLATFORM FOR PCF PCF on Google Cloud Platform (GCP) GCP also support PCF in its cloud Platform (IaaS). PCF assembles applications and their dependencies using buildpacks and utilizing Cloud Storage. A PCF deployment on GCP also utilizes Google's load balancer, and other software-defined networking features such as subnetworks and firewall rules. PCF allows administrators to register a service broker, which allows application developers to leverage GCP’s data services natively Basic integration is given in below diagram Benefit