Doc 9303 Machine Readable Travel Documents Eighth Edition, 2021
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Branding Guidelines
2020 v. 1 BRANDING GUIDELINES A visual identity guide for New Orleans Baptist Theological Seminary and Leavell College New Orleans Baptist Theological Seminary and Leavell College 01 2020 v. 1 CONTENTS COLORS 3 Primary Color 3 Secondary Colors 4 Grays LOGOS 5 Graduate Logo 7 Undergraduate Logo 9 Combining both Logos TYPOGRAPHY 10 Roboto Font Family 11 Utopia Font Family 12 Combining both Fonts 13 Branding Statements LAYOUT GUIDELINES Text and Images Margins and Bleeds White Space EXAMPLE PAGES New Orleans Baptist Theological Seminary and Leavell College 02 2020 v. 1 The primary purple and secondary colors should be utilized COLORS for all seminary and college designs. Generally, gray or white should be used for text. Limited use of primary and secondary colors is acceptable for headlines. The primary purple is Primary and intentionally contrasted and complemented by the secondary Secondary Colors colors. A balanced design is structured by the weight, proximity, and alignment of shapes, text, and photos. Photos should be bright and saturated. NOTE: If a printer is not accurate or the material does not hold ink effectively, the purple can easily skew to either a reddish or blueish hue. Primary Purple Secondary Gold Secondary Light Blue Cyan = 80 Cyan = 21 Cyan = 67 Magenta = 88 Magenta = 22 Magenta = 0 CMYK Yellow = 36 Yellow = 100 Yellow = 18 Black = 29 Black = 0 Black = 0 Red = 68 Red = 209 Red = 48 RGB Green = 48 Green = 180 Green = 192 Blue = 90 Blue = 43 Blue = 210 #44305a #d1b42b #30c0d2 HEX 2627 C 110 C 2627 U 110 U PANTONE New Orleans Baptist Theological Seminary and Leavell College 03 2020 v. -

Teemtalk® 5.0 for Windows CE & Xpe User's Guide
TeemTalk® 5.0 for Windows CE & XPe User's Guide USA Neoware, Inc. 3200 Horizon Drive King of Prussia, PA 19406 Tel: +1-610-277-8300 Fax: +1-610-771-4200 Email: [email protected] UK Neoware UK Ltd The Stables, Cosgrove Milton Keynes MK19 7JJ Tel: +44 (0) 1908 267111 Fax: +44 (0) 1908 267112 Email: [email protected] TeemTalk Software Support Telephone: +1-610-277-8300 Web: http://www.neoware.com/support/ Software Version 5.0.1 October 2004 Neoware UK Ltd, The Stables, Cosgrove, Milton Keynes, MK19 7JJ Tel: +44 (0) 1908 267111 Fax: +44 (0) 1908 267112 TeemTalk © 1988-2004 Neoware UK Ltd, All Rights Reserved. This product includes software developed by the OpenSSL Project for use in the OpenSSL Toolkit. (http://www.openssl.org/) This product includes cryptographic software written by Eric Young ([email protected]) The material in this manual is for information purposes only and is subject to change without notice. Neoware UK Ltd accepts no responsibility for any errors contained herein. Trademarks TeemTalk is a registered trademark of Neoware UK Ltd. ADDS Viewpoint A2 is a trademark of Applied Digital Data Systems Inc. AIX is a registered trademark of International Business Machines Corporation. D100, D200 and D410 are trademarks of Data General. Dataspeed is a registered trademark of AT&T. DEC, VT52, VT100, VT131, VT220, VT300, VT320 and VT340 are registered trademarks of Digital Equipment Corporation. Hazeltine is a trademark of Esprit Systems, Inc. HP700/92, HP700/94, HP700/96, HP2392A and HP2622A are trademarks of Hewlett Packard Company. IBM is a registered trademark of International Business Machines Corporation. -

Font HOWTO Font HOWTO
Font HOWTO Font HOWTO Table of Contents Font HOWTO......................................................................................................................................................1 Donovan Rebbechi, elflord@panix.com..................................................................................................1 1.Introduction...........................................................................................................................................1 2.Fonts 101 −− A Quick Introduction to Fonts........................................................................................1 3.Fonts 102 −− Typography.....................................................................................................................1 4.Making Fonts Available To X..............................................................................................................1 5.Making Fonts Available To Ghostscript...............................................................................................1 6.True Type to Type1 Conversion...........................................................................................................2 7.WYSIWYG Publishing and Fonts........................................................................................................2 8.TeX / LaTeX.........................................................................................................................................2 9.Getting Fonts For Linux.......................................................................................................................2 -

Surviving the TEX Font Encoding Mess Understanding The
Surviving the TEX font encoding mess Understanding the world of TEX fonts and mastering the basics of fontinst Ulrik Vieth Taco Hoekwater · EuroT X ’99 Heidelberg E · FAMOUS QUOTE: English is useful because it is a mess. Since English is a mess, it maps well onto the problem space, which is also a mess, which we call reality. Similary, Perl was designed to be a mess, though in the nicests of all possible ways. | LARRY WALL COROLLARY: TEX fonts are mess, as they are a product of reality. Similary, fontinst is a mess, not necessarily by design, but because it has to cope with the mess we call reality. Contents I Overview of TEX font technology II Installation TEX fonts with fontinst III Overview of math fonts EuroT X ’99 Heidelberg 24. September 1999 3 E · · I Overview of TEX font technology What is a font? What is a virtual font? • Font file formats and conversion utilities • Font attributes and classifications • Font selection schemes • Font naming schemes • Font encodings • What’s in a standard font? What’s in an expert font? • Font installation considerations • Why the need for reencoding? • Which raw font encoding to use? • What’s needed to set up fonts for use with T X? • E EuroT X ’99 Heidelberg 24. September 1999 4 E · · What is a font? in technical terms: • – fonts have many different representations depending on the point of view – TEX typesetter: fonts metrics (TFM) and nothing else – DVI driver: virtual fonts (VF), bitmaps fonts(PK), outline fonts (PFA/PFB or TTF) – PostScript: Type 1 (outlines), Type 3 (anything), Type 42 fonts (embedded TTF) in general terms: • – fonts are collections of glyphs (characters, symbols) of a particular design – fonts are organized into families, series and individual shapes – glyphs may be accessed either by character code or by symbolic names – encoding of glyphs may be fixed or controllable by encoding vectors font information consists of: • – metric information (glyph metrics and global parameters) – some representation of glyph shapes (bitmaps or outlines) EuroT X ’99 Heidelberg 24. -
Using Fonts Installed in Local Texlive - Tex - Latex Stack Exchange
27-04-2015 Using fonts installed in local texlive - TeX - LaTeX Stack Exchange sign up log in tour help TeX LaTeX Stack Exchange is a question and answer site for users of TeX, LaTeX, ConTeXt, and related Take the 2minute tour × typesetting systems. It's 100% free, no registration required. Using fonts installed in local texlive I have installed texlive at ~/texlive . I have installed collectionfontsrecommended using tlmgr . Now, ~/texlive/2014/texmfdist/fonts/ has several folders: afm , cmap , enc , ... , vf . Here is the output of tlmgr info helvetic package: helvetic category: Package shortdesc: URW "Base 35" font pack for LaTeX. longdesc: A set of fonts for use as "dropin" replacements for Adobe's basic set, comprising: Century Schoolbook (substituting for Adobe's New Century Schoolbook); Dingbats (substituting for Adobe's Zapf Dingbats); Nimbus Mono L (substituting for Abobe's Courier); Nimbus Roman No9 L (substituting for Adobe's Times); Nimbus Sans L (substituting for Adobe's Helvetica); Standard Symbols L (substituting for Adobe's Symbol); URW Bookman; URW Chancery L Medium Italic (substituting for Adobe's Zapf Chancery); URW Gothic L Book (substituting for Adobe's Avant Garde); and URW Palladio L (substituting for Adobe's Palatino). installed: Yes revision: 31835 sizes: run: 2377k relocatable: No catdate: 20120606 22:57:48 +0200 catlicense: gpl collection: collectionfontsrecommended But when I try to compile: \documentclass{article} \usepackage{helvetic} \begin{document} Hello World! \end{document} It gives an error: ! LaTeX Error: File `helvetic.sty' not found. Type X to quit or <RETURN> to proceed, or enter new name. -

A Könyvtárüggyel Kapcsolatos Nemzetközi Szabványok
A könyvtárüggyel kapcsolatos nemzetközi szabványok 1. Állomány-nyilvántartás ISO 20775:2009 Information and documentation. Schema for holdings information 2. Bibliográfiai feldolgozás és adatcsere, transzliteráció ISO 10754:1996 Information and documentation. Extension of the Cyrillic alphabet coded character set for non-Slavic languages for bibliographic information interchange ISO 11940:1998 Information and documentation. Transliteration of Thai ISO 11940-2:2007 Information and documentation. Transliteration of Thai characters into Latin characters. Part 2: Simplified transcription of Thai language ISO 15919:2001 Information and documentation. Transliteration of Devanagari and related Indic scripts into Latin characters ISO 15924:2004 Information and documentation. Codes for the representation of names of scripts ISO 21127:2014 Information and documentation. A reference ontology for the interchange of cultural heritage information ISO 233:1984 Documentation. Transliteration of Arabic characters into Latin characters ISO 233-2:1993 Information and documentation. Transliteration of Arabic characters into Latin characters. Part 2: Arabic language. Simplified transliteration ISO 233-3:1999 Information and documentation. Transliteration of Arabic characters into Latin characters. Part 3: Persian language. Simplified transliteration ISO 25577:2013 Information and documentation. MarcXchange ISO 259:1984 Documentation. Transliteration of Hebrew characters into Latin characters ISO 259-2:1994 Information and documentation. Transliteration of Hebrew characters into Latin characters. Part 2. Simplified transliteration ISO 3602:1989 Documentation. Romanization of Japanese (kana script) ISO 5963:1985 Documentation. Methods for examining documents, determining their subjects, and selecting indexing terms ISO 639-2:1998 Codes for the representation of names of languages. Part 2. Alpha-3 code ISO 6630:1986 Documentation. Bibliographic control characters ISO 7098:1991 Information and documentation. -

IGP® / VGL Emulation Code V™ Graphics Language Programmer's Reference Manual Line Matrix Series Printers
IGP® / VGL Emulation Code V™ Graphics Language Programmer’s Reference Manual Line Matrix Series Printers Trademark Acknowledgements IBM and IBM PC are registered trademarks of the International Business Machines Corp. HP and PCL are registered trademarks of Hewlett-Packard Company. IGP, LinePrinter Plus, PSA, and Printronix are registered trademarks of Printronix, LLC. QMS is a registered trademark and Code V is a trademark of Quality Micro Systems, Inc. CSA is a registered certification mark of the Canadian Standards Association. TUV is a registered certification mark of TUV Rheinland of North America, Inc. UL is a registered certification mark of Underwriters Laboratories, Inc. This product uses Intellifont Scalable typefaces and Intellifont technology. Intellifont is a registered trademark of Agfa Division, Miles Incorporated (Agfa). CG Triumvirate are trademarks of Agfa Division, Miles Incorporated (Agfa). CG Times, based on Times New Roman under license from The Monotype Corporation Plc is a product of Agfa. Printronix, LLC. makes no representations or warranties of any kind regarding this material, including, but not limited to, implied warranties of merchantability and fitness for a particular purpose. Printronix, LLC. shall not be held responsible for errors contained herein or any omissions from this material or for any damages, whether direct, indirect, incidental or consequential, in connection with the furnishing, distribution, performance or use of this material. The information in this manual is subject to change without notice. This document contains proprietary information protected by copyright. No part of this document may be reproduced, copied, translated or incorporated in any other material in any form or by any means, whether manual, graphic, electronic, mechanical or otherwise, without the prior written consent of Printronix, LLC. -
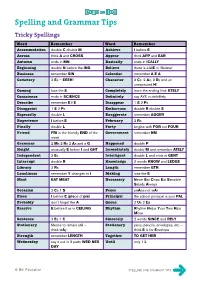
Spelling and Grammar Tips
Spelling and Grammar Tips Tricky Spellings Word Remember Word Remember Accommodation double C double M Achieve I before E Across think A and CROSS Appear think APP and EAR Autumn ends in MN Basically ends in ICALLY Beginning double N before the ING Believe there is a LIE in ‘Believe’ Business remember SIN Calendar remember A E A Cemetery 3 Es – EEEK! Character 2 Cs, 2 As, 2 Rs and an unexpected H! Coming lose the E Completely learn the ending first: ETELY Conscience ends in SCIENCE Definitely say AYE in definItely Describe remember E I E Disappear 1 S 2 Ps Disappoint 1 S 2 Ps Embarrass double R double S Especially double L Exaggerate remember AGGER Experience I before E February 2 Rs Finally double L Forty begins with FOR not FOUR Friend FRI is the friendly END of the Government remember NM week Grammar 2 Ms 2 Rs 2 As and a G Happened double P Height unusually E before I and GHT Immediately double M and remember ATELY Independent 3 Es Intelligent double L and ends in GENT Interrupt double R Knowledge 2 words KNOW and LEDGE Library 2 Rs Length remember GTH Loneliness remember Y changes to I Making lose the E Meat EAT MEAT Necessary Never Eat Chips Eat Sensible Salads Always Occasion 2 Cs 1 S Peace peAce not wAr Piece I before E (piece of pie) Principal the school principal is your PAL Probably don’t forget the A Queue 2 Us 2 Es Receive E before I as in CEILING Rhythm Rhythm Helps Your Two Hips Move Sentence 3 Es 1 C Sincerely 2 words SINCE and RELY Stationary Means to remain still – Stationery pens, pencils, envelopes, etc. -

IS0 9036 : 1987 (E) This Is a Preview - Click Here to Buy the Full Publication
This is a preview - click here to buy the full publication IS0 INTERNATIONAL STANDARD 9036 First edition 1987-04-H INTERNATIONAL ORGANIZATION FOR STANDARDIZATION ORGANISATION INTERNATIONALE DE NORMALISATION MEXflYHAPOflHAFl OPI-AHM3AuMR l-l0 CTAHJJAPTM3A~MM Information processing - Arabic 7-bit coded character set for information interchange Jeu de caractkres arabes cod& A 7 Mments pour Ochange d/information Reference number IS0 9036 : 1987 (E) This is a preview - click here to buy the full publication Foreword IS0 (the International Organization for Standardization) is a worldwide federation of national standards bodies (IS0 member bodies). The work of preparing International Standards is normally carried out through IS0 technical committees. Each member body interested in a subject for which a technical committee has been established has the right to be represented on that committee. International organizations, govern- mental and non-governmental, in liaison with ISO, also take part in the work. Draft International Standards adopted by the technical committees are circulated to the member bodies for approval before their acceptance as International Standards by the IS0 Council. They are approved in accordance with IS0 procedures requiring at least 75 % approval by the member bodies voting. International Standard IS0 9636 was prepared by Technical Committee ISO/TC 97, Information processing systems. Users should note that all International Standards undergo revision from time to time and that any reference made herein to any other International Standard implies its latest edition, unless otherwise stated. 0 International Organization for Standardization, 1987 Printed in Switzerland This is a preview - click here to buy the full publication IS0 9036: 1987 (El Contents Page 1 Scope and field of application ........................................ -
A Framework for Intensive R Developing Cross-Br E Arabic Web Applicati Rowser Data Ions
See discussions, stats, and author profiles for this publication at: https://www.researchgate.net/publication/261111986 A framework for developing cross-browser data intensive Arabic Web applications Conference Paper · October 2012 DOI: 10.1109/ICCTA.2012.6523547 CITATION READS 1 17 3 authors: Mahmoud Youssef Nourhan Hamdi George Washington University Arab Academy for Science, Technology & Maritime Transport 12 PUBLICATIONS 72 CITATIONS 3 PUBLICATIONS 4 CITATIONS SEE PROFILE SEE PROFILE Salma Rayan University of Strathclyde 2 PUBLICATIONS 2 CITATIONS SEE PROFILE Some of the authors of this publication are also working on these related projects: Enhancing location privacy View project All content following this page was uploaded by Salma Rayan on 20 June 2020. The user has requested enhancement of the downloaded file. A Framework for Developing Cross-Browser Data Intensive Arabic Web Applications Mahmoud Youssef, Nourhan Hamdi, and Salma Rayan Business Information Systems Department Arab Academy for Science, Technology, and Maritime Transport Alexandria, Egypt [email protected], [email protected], and [email protected] Abstract— the frequent encounter of incorrectly functioning The impact of properly functioning Arabic data-intensive Arabic Websites, especially those of large businesses and Websites can be seen on different fronts. From a societal governments calls for a clear and applied framework to help perspective, it enables the spread of e-commerce and e- practitioners develop properly functioning Websites. The issue of government applications in the Arab world with their Website internationalization has been addressed in a plethora of associated benefits. Moreover, it enhances the trust in the standards, guideline, good practices, and tutorials. -

Inventory of Romanization Tools
Inventory of Romanization Tools Standards Intellectual Management Office Library and Archives Canad Ottawa 2006 Inventory of Romanization Tools page 1 Language Script Romanization system for an English Romanization system for a French Alternate Romanization system catalogue catalogue Amharic Ethiopic ALA-LC 1997 BGN/PCGN 1967 UNGEGN 1967 (I/17). http://www.eki.ee/wgrs/rom1_am.pdf Arabic Arabic ALA-LC 1997 ISO 233:1984.Transliteration of Arabic BGN/PCGN 1956 characters into Latin characters NLC COPIES: BS 4280:1968. Transliteration of Arabic characters NL Stacks - TA368 I58 fol. no. 00233 1984 E DMG 1936 NL Stacks - TA368 I58 fol. no. DIN-31635, 1982 00233 1984 E - Copy 2 I.G.N. System 1973 (also called Variant B of the Amended Beirut System) ISO 233-2:1993. Transliteration of Arabic characters into Latin characters -- Part 2: Lebanon national system 1963 Arabic language -- Simplified transliteration Morocco national system 1932 Royal Jordanian Geographic Centre (RJGC) System Survey of Egypt System (SES) UNGEGN 1972 (II/8). http://www.eki.ee/wgrs/rom1_ar.pdf Update, April 2004: http://www.eki.ee/wgrs/ung22str.pdf Armenian Armenian ALA-LC 1997 ISO 9985:1996. Transliteration of BGN/PCGN 1981 Armenian characters into Latin characters Hübschmann-Meillet. Assamese Bengali ALA-LC 1997 ISO 15919:2001. Transliteration of Hunterian System Devanagari and related Indic scripts into Latin characters UNGEGN 1977 (III/12). http://www.eki.ee/wgrs/rom1_as.pdf 14/08/2006 Inventory of Romanization Tools page 2 Language Script Romanization system for an English Romanization system for a French Alternate Romanization system catalogue catalogue Azerbaijani Arabic, Cyrillic ALA-LC 1997 ISO 233:1984.Transliteration of Arabic characters into Latin characters. -

Le Codage Informatique De L'écriture Arabe : D'asmo 449 À Unicode Et
Le codage informatique de l’écriture arabe : d’ASMO 449 à Unicode et ISO/CEI 10646 Rachid Zghibi Département documentation Université Paris 8 Maison des Sciences de l’Homme Paris Nord 4, rue de la Croix Faron, Plaine Saint-Denis F-93210 Saint-Denis [email protected] RÉSUMÉ. Le traitement de l’écriture arabe par le standard Unicode et la norme ISO/CEI 10646 constitue l’objet de cet article. Nous présentons d’abord les principaux problèmes liés au codage informatique de l’écriture arabe, puis nous montrons comment Unicode résout ces problèmes. ABSTRACT. The present paper deals with the treatment of arabic script by the Unicode and ISO/CEI 10646. First, we shall outline the principal problems related to the encoding of arabic script. Then we shall show how Unicode resolves this problems. MOTS-CLÉS : écriture arabe, Unicode, ISO/CEI 10646, codage. KEYWORDS: arabic script, Unicode, ISO/CEI 10646, encoding. Document numérique. Volume 6 – n° 3-4/2002, pages 155 à 182 Cet article des Editions Lavoisier est disponible en acces libre et gratuit sur dn.revuesonline.com 156 DN – 6/2002. Unicode, écriture du monde ? 1. Écriture arabe 1.1.Origine L’arabe fait partie des langues chamito-sémitique et plus précisément, à l’intérieur de cet ensemble, du groupe des langues sémitiques. Ce groupe se divise en sémitique oriental (avec l’akkadien), sémitique occidental ou du nord (cananéen, phénicien, hébreu, araméen) et sémitique méridional. L’arabe relève de ce dernier groupe avec l’éthiopien et le sud-arabique. À la différence d’autres nations, comme les anciens égyptiens, les babyloniens et les chinois dont les systèmes d’écriture remontent à des milliers d’années, l’écriture arabe n’est apparue qu’au VIe siècle.