Using Whole-Exome Sequencing and Protein Interaction Networks To
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Regulates Cellular Telomerase Activity by Methylation of TERT Promoter
www.impactjournals.com/oncotarget/ Oncotarget, 2017, Vol. 8, (No. 5), pp: 7977-7988 Research Paper Tianshengyuan-1 (TSY-1) regulates cellular Telomerase activity by methylation of TERT promoter Weibo Yu1, Xiaotian Qin2, Yusheng Jin1, Yawei Li2, Chintda Santiskulvong3, Victor Vu1, Gang Zeng4,5, Zuofeng Zhang6, Michelle Chow1, Jianyu Rao1,5 1Department of Pathology and Laboratory Medicine, David Geffen School of Medicine, University of California at Los Angeles, Los Angeles, CA, USA 2Beijing Boyuantaihe Biological Technology Co., Ltd., Beijing, China 3Genomics Core, Cedars-Sinai Medical Center, Los Angeles, CA, USA 4Department of Urology, David Geffen School of Medicine, University of California at Los Angeles, Los Angeles, CA, USA 5Jonsson Comprehensive Cancer Center, University of California at Los Angeles, Los Angeles, CA, USA 6Department of Epidemiology, School of Public Health, University of California at Los Angeles, Los Angeles, CA, USA Correspondence to: Jianyu Rao, email: [email protected] Keywords: TSY-1, hematopoietic cells, Telomerase, TERT, methylation Received: September 08, 2016 Accepted: November 24, 2016 Published: December 15, 2016 ABSTRACT Telomere and Telomerase have recently been explored as anti-aging and anti- cancer drug targets with only limited success. Previously we showed that the Chinese herbal medicine Tianshengyuan-1 (TSY-1), an agent used to treat bone marrow deficiency, has a profound effect on stimulating Telomerase activity in hematopoietic cells. Here, the mechanism of TSY-1 on cellular Telomerase activity was further investigated using HL60, a promyelocytic leukemia cell line, normal peripheral blood mononuclear cells, and CD34+ hematopoietic stem cells derived from umbilical cord blood. TSY-1 increases Telomerase activity in normal peripheral blood mononuclear cells and CD34+ hematopoietic stem cells with innately low Telomerase activity but decreases Telomerase activity in HL60 cells with high intrinsic Telomerase activity, both in a dose-response manner. -

CDKN2A and CDKN2B Methylation in Coronary Heart Disease Cases and Controls
EXPERIMENTAL AND THERAPEUTIC MEDICINE 14: 6093-6098, 2016 CDKN2A and CDKN2B methylation in coronary heart disease cases and controls JINYAN ZHONG1,2*, XIAOYING CHEN3*, HUADAN YE3, NAN WU1,3, XIAOMIN CHEN1 and SHIWEI DUAN3 1Cardiology Center, Ningbo First Hospital, Ningbo University; 2Department of Cardiology, Ningbo Second Hospital, Ningbo, Zhejiang 315010; 3Medical Genetics Center, School of Medicine, Ningbo University, Ningbo, Zhejiang 315211, P.R. China Received May 27, 2016; Accepted March 24, 2017 DOI: 10.3892/etm.2017.5310 Abstract. The aim of the present study was to investigate frequencies were significantly associated with age, and there the association between cyclin-dependent kinase inhibitor was a gender dimorphism in CDKN2B methylation. 2A (CDKN2A) and cyclin-dependent kinase inhibitor 2B (CDKN2B) methylation, and coronary heart disease (CHD), Introduction and to explore the interaction between methylation status and CHD clinical characteristics in Han Chinese patients. A total Coronary heart disease (CHD) is a complex chronic disease of 189 CHD (96 males, 93 females) and 190 well-matched that is caused by an imbalance between blood supply and non-CHD controls (96 males, 94 females) were recruited for demand in myocardium. Various environmental and genetic the study. Methylation-specific polymerase chain reaction factors are known to contribute to onset and development of technology was used to examine gene promoter methylation CHD (1). As of 2010, CHD was the leading cause of mortality status. Comparisons of methylation frequencies between CHD globally, resulting in over 7 million cases of mortality (2). and non-CHD patients were carried out using the Chi-square Therefore, association studies for CHD biomarkers have been test. -

Epigenetic Silencing of CDKN1A and CDKN2B by SNHG1 Promotes The
Li et al. Cell Death and Disease (2020) 11:823 https://doi.org/10.1038/s41419-020-03031-6 Cell Death & Disease ARTICLE Open Access Epigenetic silencing of CDKN1A and CDKN2B by SNHG1 promotes the cell cycle, migration and epithelial-mesenchymal transition progression of hepatocellular carcinoma Bei Li1,AngLi2, Zhen You 1,JingchangXu1 and Sha Zhu3 Abstract Enhanced SNHG1 (small nucleolar RNA host gene 1) expression has been found to play a critical role in the initiation and progression of hepatocellular carcinoma (HCC) with its detailed mechanism largely unknown. In this study, we show that SNHG1 promotes the HCC progression through epigenetically silencing CDKN1A and CDKN2B in the nucleus, and competing with CDK4 mRNA for binding miR-140-5p in the cytoplasm. Using bioinformatics analyses, we found hepatocarcinogenesis is particularly associated with dysregulated expression of SNHG1 and activation of the cell cycle pathway. SNHG1 was upregulated in HCC tissues and cells, and its knockdown significantly inhibited HCC cell cycle, growth, metastasis, and epithelial–mesenchymal transition (EMT) both in vitro and in vivo. Chromatin immunoprecipitation and RNA immunoprecipitation assays demonstrate that SNHG1 inhibit the transcription of CDKN1A and CDKN2B through enhancing EZH2 mediated-H3K27me3 in the promoter of CDKN1A and CDKN2B, thus resulting in the de-repression of the cell cycle. Dual-luciferase assay and RNA pulldown revealed that SNHG1 promotes 1234567890():,; 1234567890():,; 1234567890():,; 1234567890():,; the expression of CDK4 by competitively binding to miR-140-5p. In conclusion, we propose that SNHG1 formed a regulatory network to confer an oncogenic function in HCC and SNHG1 may serve as a potential target for HCC diagnosis and treatment. -

Genetic and Genomic Analysis of Hyperlipidemia, Obesity and Diabetes Using (C57BL/6J × TALLYHO/Jngj) F2 Mice
University of Tennessee, Knoxville TRACE: Tennessee Research and Creative Exchange Nutrition Publications and Other Works Nutrition 12-19-2010 Genetic and genomic analysis of hyperlipidemia, obesity and diabetes using (C57BL/6J × TALLYHO/JngJ) F2 mice Taryn P. Stewart Marshall University Hyoung Y. Kim University of Tennessee - Knoxville, [email protected] Arnold M. Saxton University of Tennessee - Knoxville, [email protected] Jung H. Kim Marshall University Follow this and additional works at: https://trace.tennessee.edu/utk_nutrpubs Part of the Animal Sciences Commons, and the Nutrition Commons Recommended Citation BMC Genomics 2010, 11:713 doi:10.1186/1471-2164-11-713 This Article is brought to you for free and open access by the Nutrition at TRACE: Tennessee Research and Creative Exchange. It has been accepted for inclusion in Nutrition Publications and Other Works by an authorized administrator of TRACE: Tennessee Research and Creative Exchange. For more information, please contact [email protected]. Stewart et al. BMC Genomics 2010, 11:713 http://www.biomedcentral.com/1471-2164/11/713 RESEARCH ARTICLE Open Access Genetic and genomic analysis of hyperlipidemia, obesity and diabetes using (C57BL/6J × TALLYHO/JngJ) F2 mice Taryn P Stewart1, Hyoung Yon Kim2, Arnold M Saxton3, Jung Han Kim1* Abstract Background: Type 2 diabetes (T2D) is the most common form of diabetes in humans and is closely associated with dyslipidemia and obesity that magnifies the mortality and morbidity related to T2D. The genetic contribution to human T2D and related metabolic disorders is evident, and mostly follows polygenic inheritance. The TALLYHO/ JngJ (TH) mice are a polygenic model for T2D characterized by obesity, hyperinsulinemia, impaired glucose uptake and tolerance, hyperlipidemia, and hyperglycemia. -

Infrequent Methylation of CDKN2A(Mts1p16) and Rare Mutation of Both CDKN2A and CDKN2B(Mts2ip15) in Primary Astrocytic Tumours
British Joumal of Cancer (1997) 75(1), 2-8 © 1997 Cancer Research Campaign Infrequent methylation of CDKN2A(MTS1p16) and rare mutation of both CDKN2A and CDKN2B(MTS2Ip15) in primary astrocytic tumours EE Schmidt, K Ichimura, KR Messerle, HM Goike and VP Collins Institute for Oncology and Pathology, Division of Tumour Pathology, and Ludwig Institute for Cancer Research, Stockholm Branch, Karolinska Hospital, S-171 76 Stockholm, Sweden Summary In a series of 46 glioblastomas, 16 anaplastic astrocytomas and eight astrocytomas, all tumours retaining one or both alleles of CDKN2A (48 tumours) and CDKN2B (49 tumours) were subjected to sequence analysis (entire coding region and splice acceptor and donor sites). One glioblastoma with hemizygous deletion of CDKN2A showed a missense mutation in exon 2 (codon 83) that would result in the substitution of tyrosine for histidine in the protein. None of the tumours retaining alleles of CDKN2B showed mutations of this gene. Glioblastomas with retention of both alleles of CDKN2A (14 tumours) and CDKN2B (16 tumours) expressed transcripts for these genes. In contrast, 7/13 glioblastomas with hemizygous deletions of CDKN2A and 8/11 glioblastomas with hemizygous deletions of CDKN2B showed no or weak expression. Anaplastic astrocytomas and astrocytomas showed a considerable variation in the expression of both genes, regardless of whether they retained one or two copies of the genes. The methylation status of the 5' CpG island of the CDKN2A gene was studied in all 15 tumours retaining only one allele of CDKN2A as well as in the six tumours showing no significant expression of transcript despite their retaining both CDKN2A alleles. -

A Variant at 9P21.3 Functionally Implicates CDKN2B in Paediatric B-Cell Precursor Acute Lymphoblastic Leukaemia Aetiology
UCSF UC San Francisco Previously Published Works Title A variant at 9p21.3 functionally implicates CDKN2B in paediatric B-cell precursor acute lymphoblastic leukaemia aetiology. Permalink https://escholarship.org/uc/item/3bz9m1pp Journal Nature communications, 7(1) ISSN 2041-1723 Authors Hungate, Eric A Vora, Sapana R Gamazon, Eric R et al. Publication Date 2016-02-12 DOI 10.1038/ncomms10635 Peer reviewed eScholarship.org Powered by the California Digital Library University of California ARTICLE Received 23 Apr 2015 | Accepted 7 Jan 2016 | Published 12 Feb 2016 DOI: 10.1038/ncomms10635 OPEN A variant at 9p21.3 functionally implicates CDKN2B in paediatric B-cell precursor acute lymphoblastic leukaemia aetiology Eric A. Hungate1,*, Sapana R. Vora2,*, Eric R. Gamazon3,4, Takaya Moriyama5, Timothy Best2, Imge Hulur6, Younghee Lee3, Tiffany-Jane Evans7, Eva Ellinghaus8, Martin Stanulla9,Je´remie Rudant10,11, Laurent Orsi10,11, Jacqueline Clavel10,11,12, Elizabeth Milne13, Rodney J. Scott7,14, Ching-Hon Pui15, Nancy J. Cox3, Mignon L. Loh16, Jun J. Yang5, Andrew D. Skol1 & Kenan Onel1 Paediatric B-cell precursor acute lymphoblastic leukaemia (BCP-ALL) is the most common cancer of childhood, yet little is known about BCP-ALL predisposition. In this study, in 2,187 cases of European ancestry and 5,543 controls, we discover and replicate a locus indexed by À 15 rs77728904 at 9p21.3 associated with BCP-ALL susceptibility (Pcombined ¼ 3.32 Â 10 , OR ¼ 1.72) and independent from rs3731217, the previously reported ALL-associated variant in this region. Of correlated SNPs tagged by this locus, only rs662463 is significant in African Americans, suggesting it is a plausible causative variant. -
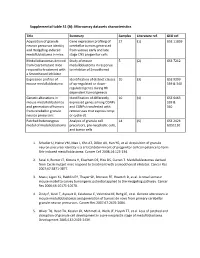
Supplemental Table S1 (A): Microarray Datasets Characteristics
Supplemental table S1 (A): Microarray datasets characteristics Title Summary Samples Literature ref. GEO ref. Acquisition of granule Gene expression profiling of 27 (1) GSE 11859 neuron precursor identity cerebellar tumors generated and Hedgehog‐induced from various early and late medulloblastoma in mice. stage CNS progenitor cells Medulloblastomas derived Study of mouse 5 (2) GSE 7212 from Cxcr6 mutant mice medulloblastoma in response respond to treatment with to inhibitor of Smoothened a Smoothened inhibitor Expression profiles of Identification of distinct classes 10 (3) GSE 9299 mouse medulloblastoma of up‐regulated or down‐ 339 & 340 regulated genes during Hh dependent tumorigenesis Genetic alterations in Identification of differently 10 (4) GSE 6463 mouse medulloblastomas expressed genes among CGNPs 339 & and generation of tumors and CGNPs transfected with 340 from cerebellar granule retroviruses that express nmyc neuron precursors or cyclin‐d1 Patched heterozygous Analysis of granule cell 14 (5) GSE 2426 model of medulloblastoma precursors, pre‐neoplastic cells, GDS1110 and tumor cells 1. Schuller U, Heine VM, Mao J, Kho AT, Dillon AK, Han YG, et al. Acquisition of granule neuron precursor identity is a critical determinant of progenitor cell competence to form Shh‐induced medulloblastoma. Cancer Cell 2008;14:123‐134. 2. Sasai K, Romer JT, Kimura H, Eberhart DE, Rice DS, Curran T. Medulloblastomas derived from Cxcr6 mutant mice respond to treatment with a smoothened inhibitor. Cancer Res 2007;67:3871‐3877. 3. Mao J, Ligon KL, Rakhlin EY, Thayer SP, Bronson RT, Rowitch D, et al. A novel somatic mouse model to survey tumorigenic potential applied to the Hedgehog pathway. Cancer Res 2006;66:10171‐10178. -

Characterization of Dysregulated Lncrna-Mrna Network Based on Cerna Hypothesis to Reveal the Occurrence and Recurrence of Myocar
Zhang et al. Cell Death Discovery (2018) 4:35 DOI 10.1038/s41420-018-0036-7 Cell Death Discovery ARTICLE Open Access Characterization of dysregulated lncRNA- mRNA network based on ceRNA hypothesis to reveal the occurrence and recurrence of myocardial infarction Guangde Zhang1,HaoranSun2, Yawei Zhang2, Hengqiang Zhao2, Wenjing Fan1,JianfeiLi3,YingliLv2, Qiong Song2, Jiayao Li2,MingyuZhang1 and Hongbo Shi2 Abstract Accumulating evidence has demonstrated that long non-coding RNAs (lncRNAs) acting as competing endogenous RNAs (ceRNAs) play important roles in initiation and development of human diseases. However, the mechanism of ceRNA regulated by lncRNA in myocardial infarction (MI) remained unclear. In this study, we performed a multi-step computational method to construct dysregulated lncRNA-mRNA networks for MI occurrence (DLMN_MI_OC) and recurrence (DLMN_MI_Re) based on “ceRNA hypothesis”. We systematically integrated lncRNA and mRNA expression profiles and miRNA-target regulatory interactions. The constructed DLMN_MI_OC and DLMN_MI_Re both exhibited biological network characteristics, and functional analysis demonstrated that the networks were specific for MI. Additionally, we identified some lncRNA-mRNA ceRNA modules involved in MI occurrence and recurrence. Finally, two new panel biomarkers defined by four lncRNAs (RP1-239B22.5, AC135048.13, RP11-4O1.2, RP11-285F7.2) from 1234567890():,; 1234567890():,; DLMN_MI_OC and three lncRNAs (RP11-363E7.4, CTA-29F11.1, RP5-894A10.6) from DLMN_MI_Re with high classification performance were, respectively, identified in distinguishing controls from patients, and patients with recurrent events from those without recurrent events. This study will provide us new insight into ceRNA-mediated regulatory mechanisms involved in MI occurrence and recurrence, and facilitate the discovery of candidate diagnostic and prognosis biomarkers for MI. -

Germline Mutations Causing Familial Lung Cancer
Journal of Human Genetics (2015) 60, 597–603 & 2015 The Japan Society of Human Genetics All rights reserved 1434-5161/15 www.nature.com/jhg ORIGINAL ARTICLE Germline mutations causing familial lung cancer Koichi Tomoshige1,2, Keitaro Matsumoto1, Tomoshi Tsuchiya1, Masahiro Oikawa1, Takuro Miyazaki1, Naoya Yamasaki1, Hiroyuki Mishima2, Akira Kinoshita2, Toru Kubo3, Kiyoyasu Fukushima3, Koh-ichiro Yoshiura2 and Takeshi Nagayasu1 Genetic factors are important in lung cancer, but as most lung cancers are sporadic, little is known about inherited genetic factors. We identified a three-generation family with suspected autosomal dominant inherited lung cancer susceptibility. Sixteen individuals in the family had lung cancer. To identify the gene(s) that cause lung cancer in this pedigree, we extracted DNA from the peripheral blood of three individuals and from the blood of one cancer-free control family member and performed whole-exome sequencing. We identified 41 alterations in 40 genes in all affected family members but not in the unaffected member. These were considered candidate mutations for familial lung cancer. Next, to identify somatic mutations and/or inherited alterations in these 40 genes among sporadic lung cancers, we performed exon target enrichment sequencing using 192 samples from sporadic lung cancer patients. We detected somatic ‘candidate’ mutations in multiple sporadic lung cancer samples; MAST1, CENPE, CACNB2 and LCT were the most promising candidate genes. In addition, the MAST1 gene was located in a putative cancer-linked locus in the pedigree. Our data suggest that several genes act as oncogenic drivers in this family, and that MAST1 is most likely to cause lung cancer. -

Deregulation of the P14arf/MDM2/P53 Pathway Is A
[CANCER RESEARCH 60, 417–424, January 15, 2000] Deregulation of the p14ARF/MDM2/p53 Pathway Is a Prerequisite for Human 1 Astrocytic Gliomas with G1-S Transition Control Gene Abnormalities Koichi Ichimura, Maria Bondesson Bolin,2 Helena M. Goike, Esther E. Schmidt, Ahmad Moshref, and V. Peter Collins3 Department of Pathology, Division of Molecular Histopathology, University of Cambridge, Addenbrooke’s Hospital, Cambridge CB2 2QQ, United Kingdom [K. I., E. E. S., V. P. C], and Ludwig Institute for Cancer Research and Unit of Tumorpathology, Department of Oncology and Pathology, Karolinska Hospital, 171 76 Stockholm, Sweden [K. I., M. B. B., H. M. G., E. E. S., A. M., V. P. C.] ABSTRACT There are several lines of evidence to indicate that deregulation of G1-S transition control alone may be detrimental for cell survival: (a) Deregulation of G -S transition control in cell cycle is one of the 1 transfection of rodent cells with the adenoviral E1A and E1B genes important mechanisms in the development of human tumors including resulted in transformation due to the viral proteins binding to and astrocytic gliomas. We have previously reported that approximately two- inactivating pRB and p53. Transfection with E1A alone induced p53 thirds of glioblastomas (GBs) had abnormalities of G1-S transition control either by mutation/homozygous deletion of RB1 or CDKN2A (p16INK4A), dependent apoptosis (10); (b) when E2F1 was ectopically expressed in or amplification of CDK4 (K. Ichimura et al., Oncogene, 13: 1065–1072, rodent embryo fibroblasts, although the cell indeed entered S phase 1996). However, abnormalities of G1-S transition control genes may in- (11), apoptosis was induced in a p53-dependent manner (12); (c) loss duce p53-dependent apoptosis in cells. -

Supplementary Table S4. FGA Co-Expressed Gene List in LUAD
Supplementary Table S4. FGA co-expressed gene list in LUAD tumors Symbol R Locus Description FGG 0.919 4q28 fibrinogen gamma chain FGL1 0.635 8p22 fibrinogen-like 1 SLC7A2 0.536 8p22 solute carrier family 7 (cationic amino acid transporter, y+ system), member 2 DUSP4 0.521 8p12-p11 dual specificity phosphatase 4 HAL 0.51 12q22-q24.1histidine ammonia-lyase PDE4D 0.499 5q12 phosphodiesterase 4D, cAMP-specific FURIN 0.497 15q26.1 furin (paired basic amino acid cleaving enzyme) CPS1 0.49 2q35 carbamoyl-phosphate synthase 1, mitochondrial TESC 0.478 12q24.22 tescalcin INHA 0.465 2q35 inhibin, alpha S100P 0.461 4p16 S100 calcium binding protein P VPS37A 0.447 8p22 vacuolar protein sorting 37 homolog A (S. cerevisiae) SLC16A14 0.447 2q36.3 solute carrier family 16, member 14 PPARGC1A 0.443 4p15.1 peroxisome proliferator-activated receptor gamma, coactivator 1 alpha SIK1 0.435 21q22.3 salt-inducible kinase 1 IRS2 0.434 13q34 insulin receptor substrate 2 RND1 0.433 12q12 Rho family GTPase 1 HGD 0.433 3q13.33 homogentisate 1,2-dioxygenase PTP4A1 0.432 6q12 protein tyrosine phosphatase type IVA, member 1 C8orf4 0.428 8p11.2 chromosome 8 open reading frame 4 DDC 0.427 7p12.2 dopa decarboxylase (aromatic L-amino acid decarboxylase) TACC2 0.427 10q26 transforming, acidic coiled-coil containing protein 2 MUC13 0.422 3q21.2 mucin 13, cell surface associated C5 0.412 9q33-q34 complement component 5 NR4A2 0.412 2q22-q23 nuclear receptor subfamily 4, group A, member 2 EYS 0.411 6q12 eyes shut homolog (Drosophila) GPX2 0.406 14q24.1 glutathione peroxidase -

Supplementary Materials
Supplementary materials Supplementary Table S1: MGNC compound library Ingredien Molecule Caco- Mol ID MW AlogP OB (%) BBB DL FASA- HL t Name Name 2 shengdi MOL012254 campesterol 400.8 7.63 37.58 1.34 0.98 0.7 0.21 20.2 shengdi MOL000519 coniferin 314.4 3.16 31.11 0.42 -0.2 0.3 0.27 74.6 beta- shengdi MOL000359 414.8 8.08 36.91 1.32 0.99 0.8 0.23 20.2 sitosterol pachymic shengdi MOL000289 528.9 6.54 33.63 0.1 -0.6 0.8 0 9.27 acid Poricoic acid shengdi MOL000291 484.7 5.64 30.52 -0.08 -0.9 0.8 0 8.67 B Chrysanthem shengdi MOL004492 585 8.24 38.72 0.51 -1 0.6 0.3 17.5 axanthin 20- shengdi MOL011455 Hexadecano 418.6 1.91 32.7 -0.24 -0.4 0.7 0.29 104 ylingenol huanglian MOL001454 berberine 336.4 3.45 36.86 1.24 0.57 0.8 0.19 6.57 huanglian MOL013352 Obacunone 454.6 2.68 43.29 0.01 -0.4 0.8 0.31 -13 huanglian MOL002894 berberrubine 322.4 3.2 35.74 1.07 0.17 0.7 0.24 6.46 huanglian MOL002897 epiberberine 336.4 3.45 43.09 1.17 0.4 0.8 0.19 6.1 huanglian MOL002903 (R)-Canadine 339.4 3.4 55.37 1.04 0.57 0.8 0.2 6.41 huanglian MOL002904 Berlambine 351.4 2.49 36.68 0.97 0.17 0.8 0.28 7.33 Corchorosid huanglian MOL002907 404.6 1.34 105 -0.91 -1.3 0.8 0.29 6.68 e A_qt Magnogrand huanglian MOL000622 266.4 1.18 63.71 0.02 -0.2 0.2 0.3 3.17 iolide huanglian MOL000762 Palmidin A 510.5 4.52 35.36 -0.38 -1.5 0.7 0.39 33.2 huanglian MOL000785 palmatine 352.4 3.65 64.6 1.33 0.37 0.7 0.13 2.25 huanglian MOL000098 quercetin 302.3 1.5 46.43 0.05 -0.8 0.3 0.38 14.4 huanglian MOL001458 coptisine 320.3 3.25 30.67 1.21 0.32 0.9 0.26 9.33 huanglian MOL002668 Worenine