5 Duality of Polyhedra
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A General Geometric Construction of Coordinates in a Convex Simplicial Polytope
A general geometric construction of coordinates in a convex simplicial polytope ∗ Tao Ju a, Peter Liepa b Joe Warren c aWashington University, St. Louis, USA bAutodesk, Toronto, Canada cRice University, Houston, USA Abstract Barycentric coordinates are a fundamental concept in computer graphics and ge- ometric modeling. We extend the geometric construction of Floater’s mean value coordinates [8,11] to a general form that is capable of constructing a family of coor- dinates in a convex 2D polygon, 3D triangular polyhedron, or a higher-dimensional simplicial polytope. This family unifies previously known coordinates, including Wachspress coordinates, mean value coordinates and discrete harmonic coordinates, in a simple geometric framework. Using the construction, we are able to create a new set of coordinates in 3D and higher dimensions and study its relation with known coordinates. We show that our general construction is complete, that is, the resulting family includes all possible coordinates in any convex simplicial polytope. Key words: Barycentric coordinates, convex simplicial polytopes 1 Introduction In computer graphics and geometric modelling, we often wish to express a point x as an affine combination of a given point set vΣ = {v1,...,vi,...}, x = bivi, where bi =1. (1) i∈Σ i∈Σ Here bΣ = {b1,...,bi,...} are called the coordinates of x with respect to vΣ (we shall use subscript Σ hereafter to denote a set). In particular, bΣ are called barycentric coordinates if they are non-negative. ∗ [email protected] Preprint submitted to Elsevier Science 3 December 2006 v1 v1 x x v4 v2 v2 v3 v3 (a) (b) Fig. -

1 Lifts of Polytopes
Lecture 5: Lifts of polytopes and non-negative rank CSE 599S: Entropy optimality, Winter 2016 Instructor: James R. Lee Last updated: January 24, 2016 1 Lifts of polytopes 1.1 Polytopes and inequalities Recall that the convex hull of a subset X n is defined by ⊆ conv X λx + 1 λ x0 : x; x0 X; λ 0; 1 : ( ) f ( − ) 2 2 [ ]g A d-dimensional convex polytope P d is the convex hull of a finite set of points in d: ⊆ P conv x1;:::; xk (f g) d for some x1;:::; xk . 2 Every polytope has a dual representation: It is a closed and bounded set defined by a family of linear inequalities P x d : Ax 6 b f 2 g for some matrix A m d. 2 × Let us define a measure of complexity for P: Define γ P to be the smallest number m such that for some C s d ; y s ; A m d ; b m, we have ( ) 2 × 2 2 × 2 P x d : Cx y and Ax 6 b : f 2 g In other words, this is the minimum number of inequalities needed to describe P. If P is full- dimensional, then this is precisely the number of facets of P (a facet is a maximal proper face of P). Thinking of γ P as a measure of complexity makes sense from the point of view of optimization: Interior point( methods) can efficiently optimize linear functions over P (to arbitrary accuracy) in time that is polynomial in γ P . ( ) 1.2 Lifts of polytopes Many simple polytopes require a large number of inequalities to describe. -

The Orientability of Small Covers and Coloring Simple Polytopes
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Osaka City University Repository Nakayama, H. and Nishimura, Y. Osaka J. Math. 42 (2005), 243–256 THE ORIENTABILITY OF SMALL COVERS AND COLORING SIMPLE POLYTOPES HISASHI NAKAYAMA and YASUZO NISHIMURA (Received September 1, 2003) Abstract Small Cover is an -dimensional manifold endowed with a Z2 action whose or- bit space is a simple convex polytope . It is known that a small cover over is characterized by a coloring of which satisfies a certain condition. In this paper we shall investigate the topology of small covers by the coloring theory in com- binatorics. We shall first give an orientability condition for a small cover. In case = 3, an orientable small cover corresponds to a four colored polytope. The four color theorem implies the existence of orientable small cover over every simple con- vex 3-polytope. Moreover we shall show the existence of non-orientable small cover over every simple convex 3-polytope, except the 3-simplex. 0. Introduction “Small Cover” was introduced and studied by Davis and Januszkiewicz in [5]. It is a real version of “Quasitoric manifold,” i.e., an -dimensional manifold endowed with an action of the group Z2 whose orbit space is an -dimensional simple convex poly- tope. A typical example is provided by the natural action of Z2 on the real projec- tive space R whose orbit space is an -simplex. Let be an -dimensional simple convex polytope. Here is simple if the number of codimension-one faces (which are called “facets”) meeting at each vertex is , equivalently, the dual of its boundary complex ( ) is an ( 1)-dimensional simplicial sphere. -

Generating Combinatorial Complexes of Polyhedral Type
transactions of the american mathematical society Volume 309, Number 1, September 1988 GENERATING COMBINATORIAL COMPLEXES OF POLYHEDRAL TYPE EGON SCHULTE ABSTRACT. The paper describes a method for generating combinatorial com- plexes of polyhedral type. Building blocks B are implanted into the maximal simplices of a simplicial complex C, on which a group operates as a combinato- rial reflection group. Of particular interest is the case where B is a polyhedral block and C the barycentric subdivision of a regular incidence-polytope K together with the action of the automorphism group of K. 1. Introduction. In this paper we discuss a method for generating certain types of combinatorial complexes. We generalize ideas which were recently applied in [23] for the construction of tilings of the Euclidean 3-space E3 by dodecahedra. The 120-cell {5,3,3} in the Euclidean 4-space E4 is a regular convex polytope whose facets and vertex-figures are dodecahedra and 3-simplices, respectively (cf. Coxeter [6], Fejes Toth [12]). When the 120-cell is centrally projected from some vertex onto the 3-simplex T spanned by the neighboured vertices, then a dissection of T into dodecahedra arises (an example of a central projection is shown in Figure 1). This dissection can be used as a building block for a tiling of E3 by dodecahedra. In fact, in the barycentric subdivision of the regular tessellation {4,3,4} of E3 by cubes each 3-simplex can serve as as a fundamental region for the symmetry group W of {4,3,4} (cf. Coxeter [6]). Therefore, mapping T affinely onto any of these 3-simplices and applying all symmetries in W turns the dissection of T into a tiling T of the whole space E3. -

Ma/CS 6B Class 8: Planar and Plane Graphs
1/26/2017 Ma/CS 6b Class 8: Planar and Plane Graphs By Adam Sheffer The Utilities Problem Problem. There are three houses on a plane. Each needs to be connected to the gas, water, and electricity companies. ◦ Is there a way to make all nine connections without any of the lines crossing each other? ◦ Using a third dimension or sending connections through a company or house is not allowed. 1 1/26/2017 Rephrasing as a Graph How can we rephrase the utilities problem as a graph problem? ◦ Can we draw 퐾3,3 without intersecting edges. Closed Curves A simple closed curve (or a Jordan curve) is a curve that does not cross itself and separates the plane into two regions: the “inside” and the “outside”. 2 1/26/2017 Drawing 퐾3,3 with no Crossings We try to draw 퐾3,3 with no crossings ◦ 퐾3,3 contains a cycle of length six, and it must be drawn as a simple closed curve 퐶. ◦ Each of the remaining three edges is either fully on the inside or fully on the outside of 퐶. 퐾3,3 퐶 No 퐾3,3 Drawing Exists We can only add one red-blue edge inside of 퐶 without crossings. Similarly, we can only add one red-blue edge outside of 퐶 without crossings. Since we need to add three edges, it is impossible to draw 퐾3,3 with no crossings. 퐶 3 1/26/2017 Drawing 퐾4 with no Crossings Can we draw 퐾4 with no crossings? ◦ Yes! Drawing 퐾5 with no Crossings Can we draw 퐾5 with no crossings? ◦ 퐾5 contains a cycle of length five, and it must be drawn as a simple closed curve 퐶. -

Frequently Asked Questions in Polyhedral Computation
Frequently Asked Questions in Polyhedral Computation http://www.ifor.math.ethz.ch/~fukuda/polyfaq/polyfaq.html Komei Fukuda Swiss Federal Institute of Technology Lausanne and Zurich, Switzerland [email protected] Version June 18, 2004 Contents 1 What is Polyhedral Computation FAQ? 2 2 Convex Polyhedron 3 2.1 What is convex polytope/polyhedron? . 3 2.2 What are the faces of a convex polytope/polyhedron? . 3 2.3 What is the face lattice of a convex polytope . 4 2.4 What is a dual of a convex polytope? . 4 2.5 What is simplex? . 4 2.6 What is cube/hypercube/cross polytope? . 5 2.7 What is simple/simplicial polytope? . 5 2.8 What is 0-1 polytope? . 5 2.9 What is the best upper bound of the numbers of k-dimensional faces of a d- polytope with n vertices? . 5 2.10 What is convex hull? What is the convex hull problem? . 6 2.11 What is the Minkowski-Weyl theorem for convex polyhedra? . 6 2.12 What is the vertex enumeration problem, and what is the facet enumeration problem? . 7 1 2.13 How can one enumerate all faces of a convex polyhedron? . 7 2.14 What computer models are appropriate for the polyhedral computation? . 8 2.15 How do we measure the complexity of a convex hull algorithm? . 8 2.16 How many facets does the average polytope with n vertices in Rd have? . 9 2.17 How many facets can a 0-1 polytope with n vertices in Rd have? . 10 2.18 How hard is it to verify that an H-polyhedron PH and a V-polyhedron PV are equal? . -

Notes on Convex Sets, Polytopes, Polyhedra, Combinatorial Topology, Voronoi Diagrams and Delaunay Triangulations
Notes on Convex Sets, Polytopes, Polyhedra, Combinatorial Topology, Voronoi Diagrams and Delaunay Triangulations Jean Gallier and Jocelyn Quaintance Department of Computer and Information Science University of Pennsylvania Philadelphia, PA 19104, USA e-mail: [email protected] April 20, 2017 2 3 Notes on Convex Sets, Polytopes, Polyhedra, Combinatorial Topology, Voronoi Diagrams and Delaunay Triangulations Jean Gallier Abstract: Some basic mathematical tools such as convex sets, polytopes and combinatorial topology, are used quite heavily in applied fields such as geometric modeling, meshing, com- puter vision, medical imaging and robotics. This report may be viewed as a tutorial and a set of notes on convex sets, polytopes, polyhedra, combinatorial topology, Voronoi Diagrams and Delaunay Triangulations. It is intended for a broad audience of mathematically inclined readers. One of my (selfish!) motivations in writing these notes was to understand the concept of shelling and how it is used to prove the famous Euler-Poincar´eformula (Poincar´e,1899) and the more recent Upper Bound Theorem (McMullen, 1970) for polytopes. Another of my motivations was to give a \correct" account of Delaunay triangulations and Voronoi diagrams in terms of (direct and inverse) stereographic projections onto a sphere and prove rigorously that the projective map that sends the (projective) sphere to the (projective) paraboloid works correctly, that is, maps the Delaunay triangulation and Voronoi diagram w.r.t. the lifting onto the sphere to the Delaunay diagram and Voronoi diagrams w.r.t. the traditional lifting onto the paraboloid. Here, the problem is that this map is only well defined (total) in projective space and we are forced to define the notion of convex polyhedron in projective space. -

Planarity and Duality of Finite and Infinite Graphs
JOURNAL OF COMBINATORIAL THEORY, Series B 29, 244-271 (1980) Planarity and Duality of Finite and Infinite Graphs CARSTEN THOMASSEN Matematisk Institut, Universitets Parken, 8000 Aarhus C, Denmark Communicated by the Editors Received September 17, 1979 We present a short proof of the following theorems simultaneously: Kuratowski’s theorem, Fary’s theorem, and the theorem of Tutte that every 3-connected planar graph has a convex representation. We stress the importance of Kuratowski’s theorem by showing how it implies a result of Tutte on planar representations with prescribed vertices on the same facial cycle as well as the planarity criteria of Whit- ney, MacLane, Tutte, and Fournier (in the case of Whitney’s theorem and MacLane’s theorem this has already been done by Tutte). In connection with Tutte’s planarity criterion in terms of non-separating cycles we give a short proof of the result of Tutte that the induced non-separating cycles in a 3-connected graph generate the cycle space. We consider each of the above-mentioned planarity criteria for infinite graphs. Specifically, we prove that Tutte’s condition in terms of overlap graphs is equivalent to Kuratowski’s condition, we characterize completely the infinite graphs satisfying MacLane’s condition and we prove that the 3- connected locally finite ones have convex representations. We investigate when an infinite graph has a dual graph and we settle this problem completely in the locally finite case. We show by examples that Tutte’s criterion involving non-separating cy- cles has no immediate extension to infinite graphs, but we present some analogues of that criterion for special classes of infinite graphs. -

Convex Hull in Higher Dimensions
Comp 163: Computational Geometry Professor Diane Souvaine Tufts University, Spring 2005 1991 Scribe: Gabor M. Czako, 1990 Scribe: Sesh Venugopal, 2004 Scrib Higher Dimensional Convex Hull Algorithms 1 Convex hulls 1.0.1 Definitions The following definitions will be used throughout. Define • Sd:Ad-Simplex The simplest convex polytope in Rd.Ad-simplex is always the convex hull of some d + 1 affinely independent points. For example, a line segment is a 1 − simplex i.e., the smallest convex subspace which con- tains two points. A triangle is a 2 − simplex and a tetrahedron is a 3 − simplex. • P: A Simplicial Polytope. A polytope where each facet is a d − 1 simplex. By our assumption, a convex hull in 3-D has triangular facets and in 4-D, a convex hull has tetrahedral facets. •P: number of facets of Pi • F : a facet of P • R:aridgeofF • G:afaceofP d+1 • fj(Pi ): The number of j-faces of P .Notethatfj(Sd)=C(j+1). 1.0.2 An Upper Bound on Time Complexity: Cyclic Polytope d 1 2 d Consider the curve Md in R defined as x(t)=(t ,t , ..., t ), t ∈ R.LetH be the hyperplane defined as a0 + a1x1 + a2x2 + ... + adxd = 0. The intersection 2 d of Md and H is the set of points that satisfy a0 + a1t + a2t + ...adt =0. This polynomial has at most d real roots and therefore d real solutions. → H intersects Md in at most d points. This brings us to the following definition: A convex polytope in Rd is a cyclic polytope if it is the convex hull of a 1 set of at least d +1pointsonMd. -

On the Treewidth of Triangulated 3-Manifolds
On the Treewidth of Triangulated 3-Manifolds Kristóf Huszár Institute of Science and Technology Austria (IST Austria) Am Campus 1, 3400 Klosterneuburg, Austria [email protected] https://orcid.org/0000-0002-5445-5057 Jonathan Spreer1 Institut für Mathematik, Freie Universität Berlin Arnimallee 2, 14195 Berlin, Germany [email protected] https://orcid.org/0000-0001-6865-9483 Uli Wagner Institute of Science and Technology Austria (IST Austria) Am Campus 1, 3400 Klosterneuburg, Austria [email protected] https://orcid.org/0000-0002-1494-0568 Abstract In graph theory, as well as in 3-manifold topology, there exist several width-type parameters to describe how “simple” or “thin” a given graph or 3-manifold is. These parameters, such as pathwidth or treewidth for graphs, or the concept of thin position for 3-manifolds, play an important role when studying algorithmic problems; in particular, there is a variety of problems in computational 3-manifold topology – some of them known to be computationally hard in general – that become solvable in polynomial time as soon as the dual graph of the input triangulation has bounded treewidth. In view of these algorithmic results, it is natural to ask whether every 3-manifold admits a triangulation of bounded treewidth. We show that this is not the case, i.e., that there exists an infinite family of closed 3-manifolds not admitting triangulations of bounded pathwidth or treewidth (the latter implies the former, but we present two separate proofs). We derive these results from work of Agol and of Scharlemann and Thompson, by exhibiting explicit connections between the topology of a 3-manifold M on the one hand and width-type parameters of the dual graphs of triangulations of M on the other hand, answering a question that had been raised repeatedly by researchers in computational 3-manifold topology. -
5 Graph Theory
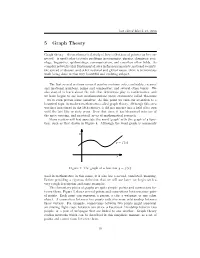
last edited March 21, 2016 5 Graph Theory Graph theory – the mathematical study of how collections of points can be con- nected – is used today to study problems in economics, physics, chemistry, soci- ology, linguistics, epidemiology, communication, and countless other fields. As complex networks play fundamental roles in financial markets, national security, the spread of disease, and other national and global issues, there is tremendous work being done in this very beautiful and evolving subject. The first several sections covered number systems, sets, cardinality, rational and irrational numbers, prime and composites, and several other topics. We also started to learn about the role that definitions play in mathematics, and we have begun to see how mathematicians prove statements called theorems – we’ve even proven some ourselves. At this point we turn our attention to a beautiful topic in modern mathematics called graph theory. Although this area was first introduced in the 18th century, it did not mature into a field of its own until the last fifty or sixty years. Over that time, it has blossomed into one of the most exciting, and practical, areas of mathematical research. Many readers will first associate the word ‘graph’ with the graph of a func- tion, such as that drawn in Figure 4. Although the word graph is commonly Figure 4: The graph of a function y = f(x). used in mathematics in this sense, it is also has a second, unrelated, meaning. Before providing a rigorous definition that we will use later, we begin with a very rough description and some examples. -

SELF-DUAL GRAPHS 1. Self-Duality of Graphs 1.1. Forms of Self
SELF-DUAL GRAPHS BRIGITTE SERVATIUS AND HERMAN SERVATIUS Abstract. We consider the three forms of self-duality that can be exhibited by a planar graph G, map self-duality, graph self-duality and matroid self- duality. We show how these concepts are related with each other and with the connectivity of G. We use the geometry of self-dual polyhedra together with the structure of the cycle matroid to construct all self-dual graphs. 1. Self-Duality of Graphs 1.1. Forms of Self-duality. Given a planar graph G = (V, E), any regular em- bedding of the topological realization of G into the sphere partitions the sphere into regions called the faces of the embedding, and we write the embedded graph, called a map, as M = (V, E, F ). G may have loops and parallel edges. Given a map M, we form the dual map, M ∗ by placing a vertex f ∗ in the center of each face f, and for ∗ each edge e of M bounding two faces f1 and f2, we draw a dual edge e connecting ∗ ∗ the vertices f1 and f2 and crossing e once transversely. Each vertex v of M will then correspond to a face v∗ of M ∗ and we write M ∗ = (F ∗,E∗,V ∗). If the graph G has distinguishable embeddings, then G may have more than one dual graph, see Figure 1. In this example a portion of the map (V, E, F ) is flipped over on a Q ¡@A@ ¡BB Q ¡ sA @ ¡ sB QQ ¨¨ HH H ¨¨PP ¨¨ ¨ H H ¨ H@ HH¨ @ PP ¨ B¨¨ HH HH HH ¨¨ ¨¨ H HH H ¨¨PP ¨ @ Hs ¨s @¨c H c @ Hs ¢¢ HHs @¨c P@Pc¨¨ s s c c c c s s c c c c @ A ¡ @ A ¢ @s@A ¡ s c c @s@A¢ s c c ∗ ∗ ∗ ∗ 0 ∗ 0∗ ∗ ∗ (V, E,s F ) −→ (F ,E ,V ) (V, E,s F ) −→ (F ,E ,V ) Figure 1.