An Adaptive Software and System Architecture for Driver Assistance Systems Applied to Truck and Trailer Combinations
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Communication Diagram.Pdf
TU2943: Information Engineering Methodology Lab Notes, 2009-2010, Faculty of Technology and Information Science, Universiti Kebangsaan Malaysia LAB 5: Interaction Diagram - UML Communication Diagram OBJECTIVES To understand the role of dynamic models in requirement analysis by reading and constructing UML Communication Diagram. INTRODUCTION Communication Diagram (a.k.a. Collaboration Diagram) Communication Diagram provides another way to model a scenario. Essentially is a part of Interaction Diagram (just like Sequence Diagram). Each object is represented by an object icon, and links are used to indicate communication paths on which messages are transmitted. Messages presented in the same way as those in sequence diagram. Formerly known as Collaboration Diagram in UML 1.x specification. Communication Diagram represents a combination of information taken from Use Case, Class and Sequence Diagrams describing both the static structure and dynamic behavior of the system. Comparing and Contrasting: Collaboration and Sequence Both diagrams show the same information: Objects/classes Messages Sequence Conditional Repetition Messages to self Sequence Diagram and Communication Diagram are two views of the same scenario. Collaboration diagrams emphasize who-is-talking-to-who. But the time-ordering of the messages who gets obscured. Sequence diagrams emphasize time-ordering. But the who-is-talking-to-who gets obscured. Use the diagram that you are most comfortable with. Structure and Notation of Communication Diagram Objects are named <an object name>:< its class> . Nor Samsiah Binti Sani 1 TU2943: Information Engineering Methodology Lab Notes, 2009-2010, Faculty of Technology and Information Science, Universiti Kebangsaan Malaysia Either <an object name> or <a class name> can be removed. Collaborations / communications are shown by lines between objects. -

Unified Modeling Language 2.0 Part 1 - Introduction
UML 2.0 – Tutorial (v4) 1 Unified Modeling Language 2.0 Part 1 - Introduction Prof. Dr. Harald Störrle Dr. Alexander Knapp University of Innsbruck University of Munich mgm technology partners (c) 2005-2006, Dr. H. Störrle, Dr. A. Knapp UML 2.0 – Tutorial (v4) 2 1 - Introduction History and Predecessors • The UML is the “lingua franca” of software engineering. • It subsumes, integrates and consolidates most predecessors. • Through the network effect, UML has a much broader spread and much better support (tools, books, trainings etc.) than other notations. • The transition from UML 1.x to UML 2.0 has – resolved a great number of issues; – introduced many new concepts and notations (often feebly defined); – overhauled and improved the internal structure completely. • While UML 2.0 still has many problems, current version (“the standard”) it is much better than what we ever had formal/05-07-04 of August ‘05 before. (c) 2005-2006, Dr. H. Störrle, Dr. A. Knapp UML 2.0 – Tutorial (v4) 3 1 - Introduction Usage Scenarios • UML has not been designed for specific, limited usages. • There is currently no consensus on the role of the UML: – Some see UML only as tool for sketching class diagrams representing Java programs. – Some believe that UML is “the prototype of the next generation of programming languages”. • UML is a really a system of languages (“notations”, “diagram types”) each of which may be used in a number of different situations. • UML is applicable for a multitude of purposes, during all phases of the software lifecycle, and for all sizes of systems - to varying degrees. -

APECS: Polychrony Based End-To-End Embedded System Design and Code Synthesis
APECS: Polychrony based End-to-End Embedded System Design and Code Synthesis Matthew E. Anderson Dissertation submitted to the faculty of the Virginia Polytechnic Institute and State University in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Computer Engineering Sandeep K. Shukla, Chair Lamine Mili Alireza Haghighat Chao Wang Yi Deng April 3, 2015 Blacksburg, Virginia Keywords: AADL, CPS, Model-based code synthesis, correct-by-construction code synthesis, Polychrony, code generators, OSATE, Ocarina Copyright 2015, Matthew E. Anderson APECS: Polychrony based End-to-End Embedded System Design and Code Synthesis Matthew E. Anderson (ABSTRACT) The development of high integrity embedded systems remains an arduous and error-prone task, despite the efforts by researchers in inventing tools and techniques for design automa- tion. Much of the problem arises from the fact that the semantics of the modeling languages for the various tools, are often distinct, and the semantics gaps are often filled manually through the engineer's understanding of one model or an abstraction. This provides an op- portunity for bugs to creep in, other than standardising software engineering errors germane to such complex system engineering. Since embedded systems applications such as avionics, automotive, or industrial automation are safety critical, it is very important to invent tools, and methodologies for safe and reliable system design. Much of the tools, and techniques deal with either the design of embedded platforms (hardware, networking, firmware etc), and software stack separately. The problem of the semantic gap between these two, as well as between models of computation used to capture semantics must be solved in order to design safer embedded systems. -

Systems Engineering with Sysml/UML Morgan Kaufmann OMG Press
Systems Engineering with SysML/UML Morgan Kaufmann OMG Press Morgan Kaufmann Publishers and the Object Management Group™ (OMG) have joined forces to publish a line of books addressing business and technical topics related to OMG’s large suite of software standards. OMG is an international, open membership, not-for-profi t computer industry consortium that was founded in 1989. The OMG creates standards for software used in government and corporate environments to enable interoperability and to forge common development environments that encourage the adoption and evolution of new technology. OMG members and its board of directors consist of representatives from a majority of the organizations that shape enterprise and Internet computing today. OMG’s modeling standards, including the Unifi ed Modeling Language™ (UML®) and Model Driven Architecture® (MDA), enable powerful visual design, execution and maintenance of software, and other processes—for example, IT Systems Modeling and Business Process Management. The middleware standards and profi les of the Object Management Group are based on the Common Object Request Broker Architecture® (CORBA) and support a wide variety of industries. More information about OMG can be found at http://www.omg.org/. Related Morgan Kaufmann OMG Press Titles UML 2 Certifi cation Guide: Fundamental and Intermediate Exams Tim Weilkiens and Bernd Oestereich Real-Life MDA: Solving Business Problems with Model Driven Architecture Michael Guttman and John Parodi Architecture Driven Modernization: A Series of Industry Case Studies Bill Ulrich Systems Engineering with SysML/UML Modeling, Analysis, Design Tim Weilkiens Acquisitions Editor: Tiffany Gasbarrini Publisher: Denise E. M. Penrose Publishing Services Manager: George Morrison Project Manager: Mónica González de Mendoza Assistant Editor: Matt Cater Production Assistant: Lianne Hong Cover Design: Dennis Schaefer Cover Image: © Masterfile (Royalty-Free Division) Morgan Kaufmann Publishers is an imprint of Eslsevier. -

Towards Fixing Sketchy UML Models by Leveraging Textual Notations: Application to Real-Time Embedded Systems
Towards Fixing Sketchy UML Models by Leveraging Textual Notations: Application to Real-Time Embedded Systems Fr´ed´ericJouault and J´er^ome Delatour PRES Universit´eNantes Angers Le Mans (UNAM) TRAME team, ESEO, Angers, France [email protected] Abstract. During the development of real-time embedded system, the use of UML models as blueprints is a common practice with a focus on un- derstandability rather than comprehensiveness. However, further in the development, these models must be completed in order to achieve the necessary validation and verification activities. They are typically per- formed by using several formal tools. Each tool needs models of the sys- tem at a given abstraction level, which are precise and complete enough wrt. how the tool processes them. If UML is appropriate for capturing multiple concerns, its multiple partial views without a global one in- crease the difficulty of locating inconsistency or incompleteness issues. Therefore, ensuring completeness is time consuming, fastidious, and er- ror prone. We propose an approach based on the use of a UML textual syntax closely aligned to its metamodel: tUML. An initial prototype is described, and examples are given. 1 Introduction Using sketchy models is common during software systems development. Such models (also called contemplative models) are just drawings that cannot be au- tomatically processed (e.g., transformed into code, or verified). In the use of such models as blueprints, the focus is on communication rather than on com- pleteness. The UML language is a good candidate for that kind of practice. It is primarily a graphical notation, and it offers a relatively large set of diagrams for representing various concerns. -

Θέµα : Interaction Diagrams / State Machine Diagrams Ηµεροµηνία : 21
ΗΥΗΥΗΥ -351: Ανάλυση και Σχεδίαση Πληροφοριακών Συστημάτων Information Systems Analysis and Design Πανεπιστήμιο Κρήτης , Φθινόπωρο 2005 Φροντιστήριο 5 Θέµα : Interaction Diagrams / State Machine Diagrams Ηεροµηνία : 21 Νοεµβρίου 2005 Outline • Interaction Diagrams – Sequence diagrams – Communication diagrams • State Machine Diagrams •For each Diagram •Definition •Elements •Demonstration •Tool tricks CS-351 University of Crete, Fall 2005-2006 2 Sequence Diagrams • Definition : An interaction diagram that represents objects as lifelines running down the page. • The interactions between the objects are represented as messages drawn as arrows from the source lifeline to the target lifeline. • Good at showing which objects communicate with which other objects and what messages trigger those communications. • NOT intended for showing complex procedural logic. CS-351 University of Crete, Fall 2005-2006 3 Sequence Diagrams • Lifelines • Messages – Execution Occurrence – Self Message – Lost and Found Messages • Lifeline Start and End • Duration and Time Constraints • Combined Fragments • Gate • Part Decomposition • State Invariant / Continuations CS-351 University of Crete, Fall 2005-2006 4 Sequence Diagrams - Lifelines • A lifeline represents an individual participant. If its name is self then that indicates that the lifeline represents the owner of the sequence diagram. • Sometimes a sequence diagram will have a lifeline with an actor element symbol at its head. This will usually be the case if the sequence diagram is owned by a use case. • Boundary, -

Lecture 8 Behavioral Models Interaction Diagrams: 1. Sequence
IS 460 Lecture Notes Lecture 8 Professor Yong Tan Lecture 8 Behavioral Models Interaction diagrams: 1. Sequence diagram 2. Communication diagram State machine 1. Sequence Diagram • Illustrates the classes that participate in a use case • Shows the messages that pass between classes over time for one use case • Can be a generic sequence diagram, but more frequently one is drawn for a single scenario within the use case Elements: An actor An object A lifeline An execution occurrence / Focus of control A message, return message Object destruction Example: 1. Object creation and destruction 1 IS 460 Lecture Notes Lecture 8 Professor Yong Tan 2. Simple iteration Scenario for making a phone call: - Caller lifts receiver - Dial tone begins - Caller dials digits one at a time - Switch makes routing - Ringing tone on caller’s receiver begins o Phone rings on callee’s receiver begins o Callee lifts receiver - Switch makes connection between caller and callee o Switch connects caller o Switch connects callee 2 IS 460 Lecture Notes Lecture 8 Professor Yong Tan Message with duration Communication diagram / Collaboration Emphasize the flow of messages among objects, rather than timing and ordering of messages Elements Actor Object Association / link – communication paths Message – sequence number and direction 3 IS 460 Lecture Notes Lecture 8 Professor Yong Tan State Machine / Statechart State – an abstraction of the attribute values and links of an object. Characteristics: A state occupies an interval of time A state is often associated with an abstraction of attribute values of an entity satisfying some condition(s) An entity changes it state not only as a direct consequence of current input, but as a result of some past history of its inputs State machine • A dynamic model showing changes of state of a single class over time in response to events along with its responses and actions • Typically not used for all classes, but just to help simplify the design of algorithms for methods of complex classes Elements Initial state Final state State anEvent Transition Examples 4 . -

Current Issues in UML Diagrams Coevolution and Consistency Techniques and Approaches
International Journal of Computer Electrical Engineering Current Issues in UML Diagrams Coevolution and Consistency Techniques and Approaches Bassam Atieh Rajabi*, Sai Peck Lee Department of Software Engineering, Faculty of Computer Science and Information Technology, University of Malaya, Kuala Lumpur, Malaysia. * Corresponding author. Email: [email protected] Manuscript submitted September 03, 2017; accepted November 24, 2017. doi: 10.17706/ijcee.2018.10.2.158-173 Abstract: UML modelling language is widely adopted in software analysis and design. UML diagrams are divided into different perspectives on modelling a problem domain. Preserving the coevolution among these diagrams is very crucial so that they can be updated continuously to reflect software changes. Decades of research efforts have produced a wide spectrum of approaches in checking the coevolution among UML diagrams. These approaches can be classified into direct, transformational, formal semantics, or knowledge representation approaches. Formal methods such as Coloured Petri Nets (CPN) are widely used in detecting and handling the coevolution between artifacts. Although ample progress has been made, there still remains much work to be done in further improving the effectiveness and the accuracy of the state-of-the-art coevolution techniques in managing changes in UML diagrams. In this research, a survey about the approaches in maintaining the coevolution among UML diagrams is provided. This research proposed set of coevolution and change effect relations on UML diagrams and diagrams elements. Additionally, currently challenges and issues to detect and resolve the UML diagrams coevolution and inconsistencies are discussed. Keywords: Coevolution, change impact, consistency, UML. 1. Introduction Software change is continuous and unavoidable due to rapidly changing requirements across software systems. -

Harmony MBSE Modeling Guidelines 2.0.Pdf
Harmony MBSE Modeling Guidelines Rev 2.0 Harmony MBSE Modeling Standards for use with UML, SysML, and Rhapsody Prepared by Dr. Bruce Powel Douglass, Ph.D. Chief Evangelist IBM Rational Page 1 of 51 © IBM 2015 Bruce Powel Douglass, Ph.D. Harmony MBSE Modeling Guidelines Rev 2.0 Page 1 of 51 © Telelogic, 2006 Bruce Powel Douglass, Ph.D. Harmony MBSE Modeling Guidelines Rev 2.0 Table of Contents 1.0 SCOPE .................................................................................................................................4 2.0 REFERENCED DOCUMENTS..............................................................................................4 3.0 MODELING STANDARDS....................................................................................................4 3.1 Naming Conventions ........................................................................................................................... 4 3.2 Modeling Guidelines ............................................................................................................................ 8 3.3 Model Reviews .................................................................................................................................. 13 3.4 General Diagram Guidelines ............................................................................................................. 14 3.5 Use Case Diagram Guidelines .......................................................................................................... 17 3.6 Class Diagram Guidelines ................................................................................................................ -

Object-Oriented Modeling SAP Powerdesigner Documentation Collection Content
User Guide PUBLIC SAP PowerDesigner Document Version: 16.6.2 – 2017-01-05 Object-Oriented Modeling SAP PowerDesigner Documentation Collection Content 1 Building OOMs ................................................................7 1.1 Getting Started with Object-Oriented Modeling.......................................... 7 Creating an OOM.............................................................9 Previewing Object Code........................................................12 Customizing Object Creation Scripts.............................................. 14 Customizing your Modeling Environment........................................... 15 1.2 Use Case Diagrams.............................................................20 Use Case Diagram Objects......................................................21 Use Cases (OOM)............................................................21 Actors (OOM).............................................................. 24 Use Case Associations (OOM)...................................................28 1.3 Structural Diagrams............................................................ 30 Class Diagrams.............................................................30 Composite Structure Diagrams..................................................32 Package Diagrams...........................................................35 Object Diagrams.............................................................36 Classes (OOM)..............................................................38 Packages (OOM)........................................................... -
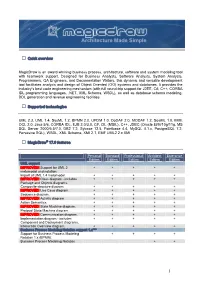
Magicdraw Features, Plugins, Integrations, Or Products That Are Available in Higher Editions Only Or Not Installed Yet
Quick overview MagicDraw is an award-winning business process, architecture, software and system modeling tool with teamwork support. Designed for Business Analysts, Software Analysts, System Analysts, Programmers, QA Engineers, and Documentation Writers, this dynamic and versatile development tool facilitates analysis and design of Object Oriented (OO) systems and databases. It provides the industry's best code engineering mechanism (with full round-trip support for J2EE, C#, C++, CORBA IDL programming languages, .NET, XML Schema, WSDL), as well as database schema modeling, DDL generation and reverse engineering facilities. Supported technologies UML 2.3, UML 1.4, SysML 1.2, BPMN 2.0, UPDM 1.0, DoDAF 2.0, MODAF 1.2, SoaML 1.0, IMM, OCL 2.0, Java 5/6, CORBA IDL, EJB 2.0/3.0, C#, CIL (MSIL), C++, JDBC (Oracle 8i/9i/10g/11g, MS SQL Server 2000/6.5/7.0, DB2 7.2, Sybase 12.5, Pointbase 4.4, MySQL 4.1.x, PostgreSQL 7.2, Pervasive SQL), WSDL, XML Schema, XMI 2.1, EMF UML2 2.x XMI MagicDraw® 17.0 features Personal Standard Professional Architect Enterprise Edition Edition Edition Edition Edition UML support IMPROVED! Support for UML 2 + + + + + metamodel and notation. Import of UML 1.4 metamodel. + + + + + IMPROVED! Class diagram – includes + + + + + Package and Objects diagrams. Composite structure diagram. + + + + + IMPROVED! Use Case diagram. + + + + + Sequence diagram. + + + + + IMPROVED! Activity diagram. + + + + + Action Semantics. + + + + + IMPROVED! State Machine diagram. + + + + + Protocol State Machine diagram. + + + + + IMPROVED! Communication diagram. + + + + + Implementation diagram – includes + + + + + Component and Deployment diagrams. Interaction Overview diagram. + + + + + Business Process Modeling Notation support 1.x*** Support for Business Process Modeling + + + + Notation 1.x (BPMN). -

A Simplified Sysml-Based Approach for Modeling Complex Systems
MBSE Grid: A Simplified SysML-Based Approach for Modeling Complex Systems Aurelijus Morkevicius Aiste Aleksandraviciene No Magic Europe and Kaunas University of No Magic Europe Technology Kaunas, LT-51480, Lithuania Kaunas, LT-51480, Lithuania [email protected] [email protected] Donatas Mazeika Lina Bisikirskiene No Magic Europe and Kaunas University of No Magic Europe and Kaunas University of Technology Technology Kaunas, LT-51480, Lithuania Kaunas, LT-51480, Lithuania [email protected] [email protected] Zilvinas Strolia No Magic Europe Kaunas, LT-51480, Lithuania [email protected] Copyright © 2017 by Aurelijus Morkevicius, Aiste Aleksandraviciene, Donatas Mazeika, Lina Bisikirskiene, Zilvinas Strolia. Abstract. After an organization makes the decision to adopt model-based systems engineering (MBSE), it must go a long way before this decision proves right. There are many obstacles in this way, like stories about unsuccessful MBSE applications, insufficient information on how to proceed, and employee resistance to the cultural change to name a few. Neither of them is a true issue, if suitable enablers for MBSE adoption are chosen. Nowadays, MBSE is enabled by Systems Modeling Language (SysML). However, SysML is neither a framework nor a method: it provides no information about the modeling process and thus must be combined with some methodology to become truly applicable. This paper summarizes the experience of various MBSE adoption projects in the form of a new approach for MBSE. The approach is based on the framework organized in a matrix view and is designated to guide system engineers through the modeling process and help them answer the questions, like how to start, how to structure the model, what views to build, which artefacts to deliver, and in what sequence.