Implementing a New Register Allocator for the Server Compiler in the Java Hotspot Virtual Machine
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

CSE 220: Systems Programming
Memory Allocation CSE 220: Systems Programming Ethan Blanton Department of Computer Science and Engineering University at Buffalo Introduction The Heap Void Pointers The Standard Allocator Allocation Errors Summary Allocating Memory We have seen how to use pointers to address: An existing variable An array element from a string or array constant This lecture will discuss requesting memory from the system. © 2021 Ethan Blanton / CSE 220: Systems Programming 2 Introduction The Heap Void Pointers The Standard Allocator Allocation Errors Summary Memory Lifetime All variables we have seen so far have well-defined lifetime: They persist for the entire life of the program They persist for the duration of a single function call Sometimes we need programmer-controlled lifetime. © 2021 Ethan Blanton / CSE 220: Systems Programming 3 Introduction The Heap Void Pointers The Standard Allocator Allocation Errors Summary Examples int global ; /* Lifetime of program */ void foo () { int x; /* Lifetime of foo () */ } Here, global is statically allocated: It is allocated by the compiler It is created when the program starts It disappears when the program exits © 2021 Ethan Blanton / CSE 220: Systems Programming 4 Introduction The Heap Void Pointers The Standard Allocator Allocation Errors Summary Examples int global ; /* Lifetime of program */ void foo () { int x; /* Lifetime of foo () */ } Whereas x is automatically allocated: It is allocated by the compiler It is created when foo() is called ¶ It disappears when foo() returns © 2021 Ethan Blanton / CSE 220: Systems Programming 5 Introduction The Heap Void Pointers The Standard Allocator Allocation Errors Summary The Heap The heap represents memory that is: allocated and released at run time managed explicitly by the programmer only obtainable by address Heap memory is just a range of bytes to C. -

Incrementalized Pointer and Escape Analysis Frédéric Vivien, Martin Rinard
Incrementalized Pointer and Escape Analysis Frédéric Vivien, Martin Rinard To cite this version: Frédéric Vivien, Martin Rinard. Incrementalized Pointer and Escape Analysis. PLDI ’01 Proceedings of the ACM SIGPLAN 2001 conference on Programming language design and implementation, Jun 2001, Snowbird, United States. pp.35–46, 10.1145/381694.378804. hal-00808284 HAL Id: hal-00808284 https://hal.inria.fr/hal-00808284 Submitted on 14 Oct 2018 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Incrementalized Pointer and Escape Analysis∗ Fred´ eric´ Vivien Martin Rinard ICPS/LSIIT Laboratory for Computer Science Universite´ Louis Pasteur Massachusetts Institute of Technology Strasbourg, France Cambridge, MA 02139 [email protected]strasbg.fr [email protected] ABSTRACT to those parts of the program that offer the most attrac- We present a new pointer and escape analysis. Instead of tive return (in terms of optimization opportunities) on the analyzing the whole program, the algorithm incrementally invested resources. Our experimental results indicate that analyzes only those parts of the program that may deliver this approach usually delivers almost all of the benefit of the useful results. An analysis policy monitors the analysis re- whole-program analysis, but at a fraction of the cost. -
Memory Allocation Pushq %Rbp Java Vs
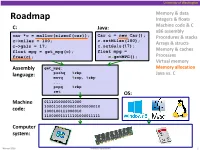
University of Washington Memory & data Roadmap Integers & floats C: Java: Machine code & C x86 assembly car *c = malloc(sizeof(car)); Car c = new Car(); Procedures & stacks c.setMiles(100); c->miles = 100; Arrays & structs c->gals = 17; c.setGals(17); float mpg = get_mpg(c); float mpg = Memory & caches free(c); c.getMPG(); Processes Virtual memory Assembly get_mpg: Memory allocation pushq %rbp Java vs. C language: movq %rsp, %rbp ... popq %rbp ret OS: Machine 0111010000011000 100011010000010000000010 code: 1000100111000010 110000011111101000011111 Computer system: Winter 2016 Memory Allocation 1 University of Washington Memory Allocation Topics Dynamic memory allocation . Size/number/lifetime of data structures may only be known at run time . Need to allocate space on the heap . Need to de-allocate (free) unused memory so it can be re-allocated Explicit Allocation Implementation . Implicit free lists . Explicit free lists – subject of next programming assignment . Segregated free lists Implicit Deallocation: Garbage collection Common memory-related bugs in C programs Winter 2016 Memory Allocation 2 University of Washington Dynamic Memory Allocation Programmers use dynamic memory allocators (such as malloc) to acquire virtual memory at run time . For data structures whose size (or lifetime) is known only at runtime Dynamic memory allocators manage an area of a process’ virtual memory known as the heap User stack Top of heap (brk ptr) Heap (via malloc) Uninitialized data (.bss) Initialized data (.data) Program text (.text) 0 Winter 2016 Memory Allocation 3 University of Washington Dynamic Memory Allocation Allocator organizes the heap as a collection of variable-sized blocks, which are either allocated or free . Allocator requests pages in heap region; virtual memory hardware and OS kernel allocate these pages to the process . -

Unleashing the Power of Allocator-Aware Software
P2126R0 2020-03-02 Pablo Halpern (on behalf of Bloomberg): [email protected] John Lakos: [email protected] Unleashing the Power of Allocator-Aware Software Infrastructure NOTE: This white paper (i.e., this is not a proposal) is intended to motivate continued investment in developing and maturing better memory allocators in the C++ Standard as well as to counter misinformation about allocators, their costs and benefits, and whether they should have a continuing role in the C++ library and language. Abstract Local (arena) memory allocators have been demonstrated to be effective at improving runtime performance both empirically in repeated controlled experiments and anecdotally in a variety of real-world applications. The initial development and subsequent maintenance effort of implementing bespoke data structures using custom memory allocation, however, are typically substantial and often untenable, especially in the limited timeframes that urgent business needs impose. To address such recurring performance needs effectively across the enterprise, Bloomberg has adopted a consistent, ubiquitous allocator-aware software infrastructure (AASI) based on the PMR-style1 plug-in memory allocator protocol pioneered at Bloomberg and adopted into the C++17 Standard Library. In this paper, we highlight the essential mechanics and subtle nuances of programing on top of Bloomberg’s AASI platform. In addition to delineating how to obtain performance gains safely at minimal development cost, we explore many of the inherent collateral benefits — such as object placement, metrics gathering, testing, debugging, and so on — that an AASI naturally affords. After reading this paper and surveying the available concrete allocators (provided in Appendix A), a competent C++ developer should be adequately equipped to extract substantial performance and other collateral benefits immediately using our AASI. -

P1083r2 | Move Resource Adaptor from Library TS to the C++ WP
P1083r2 | Move resource_adaptor from Library TS to the C++ WP Pablo Halpern [email protected] 2018-11-13 | Target audience: LWG 1 Abstract When the polymorphic allocator infrastructure was moved from the Library Fundamentals TS to the C++17 working draft, pmr::resource_adaptor was left behind. The decision not to move pmr::resource_adaptor was deliberately conservative, but the absence of resource_adaptor in the standard is a hole that must be plugged for a smooth transition to the ubiquitous use of polymorphic_allocator, as proposed in P0339 and P0987. This paper proposes that pmr::resource_adaptor be moved from the LFTS and added to the C++20 working draft. 2 History 2.1 Changes from R1 to R2 (in San Diego) • Paper was forwarded from LEWG to LWG on Tuesday, 2018-10-06 • Copied the formal wording from the LFTS directly into this paper • Minor wording changes as per initial LWG review • Rebased to the October 2018 draft of the C++ WP 2.2 Changes from R0 to R1 (pre-San Diego) • Added a note for LWG to consider clarifying the alignment requirements for resource_adaptor<A>::do_allocate(). • Changed rebind type from char to byte. • Rebased to July 2018 draft of the C++ WP. 3 Motivation It is expected that more and more classes, especially those that would not otherwise be templates, will use pmr::polymorphic_allocator<byte> to allocate memory. In order to pass an allocator to one of these classes, the allocator must either already be a polymorphic allocator, or must be adapted from a non-polymorphic allocator. The process of adaptation is facilitated by pmr::resource_adaptor, which is a simple class template, has been in the LFTS for a long time, and has been fully implemented. -

Generalized Escape Analysis and Lightweight Continuations
Generalized Escape Analysis and Lightweight Continuations Abstract Might and Shivers have published two distinct analyses for rea- ∆CFA and ΓCFA are two analysis techniques for higher-order soning about programs written in higher-order languages that pro- functional languages (Might and Shivers 2006b,a). The former uses vide first-class continuations, ∆CFA and ΓCFA (Might and Shivers an enrichment of Harrison’s procedure strings (Harrison 1989) to 2006a,b). ∆CFA is an abstract interpretation based on a variation reason about control-, environment- and data-flow in a program of procedure strings as developed by Sharir and Pnueli (Sharir and represented in CPS form; the latter tracks the degree of approxi- Pnueli 1981), and, most proximately, Harrison (Harrison 1989). mation inflicted by a flow analysis on environment structure, per- Might and Shivers have applied ∆CFA to problems that require mitting the analysis to exploit extra precision implicit in the flow reasoning about the environment structure relating two code points lattice, which improves not only the precision of the analysis, but in a program. ΓCFA is a general tool for “sharpening” the precision often its run-time as well. of an abstract interpretation by tracking the amount of abstraction In this paper, we integrate these two mechanisms, showing how the analysis has introduced for the specific abstract interpretation ΓCFA’s abstract counting and collection yields extra precision in being performed. This permits the analysis to opportunistically ex- ∆CFA’s frame-string model, exploiting the group-theoretic struc- ploit cases where the abstraction has introduced no true approxi- ture of frame strings. mation. -

Escape from Escape Analysis of Golang
Escape from Escape Analysis of Golang Cong Wang Mingrui Zhang Yu Jiang∗ KLISS, BNRist, School of Software, KLISS, BNRist, School of Software, KLISS, BNRist, School of Software, Tsinghua University Tsinghua University Tsinghua University Beijing, China Beijing, China Beijing, China Huafeng Zhang Zhenchang Xing Ming Gu Compiler and Programming College of Engineering and Computer KLISS, BNRist, School of Software, Language Lab, Huawei Technologies Science, ANU Tsinghua University Hangzhou, China Canberra, Australia Beijing, China ABSTRACT KEYWORDS Escape analysis is widely used to determine the scope of variables, escape analysis, memory optimization, code generation, go pro- and is an effective way to optimize memory usage. However, the gramming language escape analysis algorithm can hardly reach 100% accurate, mistakes ACM Reference Format: of which can lead to a waste of heap memory. It is challenging to Cong Wang, Mingrui Zhang, Yu Jiang, Huafeng Zhang, Zhenchang Xing, ensure the correctness of programs for memory optimization. and Ming Gu. 2020. Escape from Escape Analysis of Golang. In Software In this paper, we propose an escape analysis optimization ap- Engineering in Practice (ICSE-SEIP ’20), May 23–29, 2020, Seoul, Republic of proach for Go programming language (Golang), aiming to save Korea. ACM, New York, NY, USA, 10 pages. https://doi.org/10.1145/3377813. heap memory usage of programs. First, we compile the source code 3381368 to capture information of escaped variables. Then, we change the code so that some of these variables can bypass Golang’s escape 1 INTRODUCTION analysis mechanism, thereby saving heap memory usage and reduc- Memory management is very important for software engineering. -

Escape Analysis for Java
Escape Analysis for Java Jong-Deok Choi Manish Gupta Mauricio Serrano Vugranam C. Sreedhar Sam Midkiff IBM T. J. Watson Research Center P. O. Box 218, Yorktown Heights, NY 10598 jdchoi, mgupta, mserrano, vugranam, smidkiff ¡ @us.ibm.com ¢¤£¦¥¨§ © ¦ § § © § This paper presents a simple and efficient data flow algorithm Java continues to gain importance as a language for general- for escape analysis of objects in Java programs to determine purpose computing and for server applications. Performance (i) if an object can be allocated on the stack; (ii) if an object is an important issue in these application environments. In is accessed only by a single thread during its lifetime, so that Java, each object is allocated on the heap and can be deallo- synchronization operations on that object can be removed. We cated only by garbage collection. Each object has a lock asso- introduce a new program abstraction for escape analysis, the ciated with it, which is used to ensure mutual exclusion when connection graph, that is used to establish reachability rela- a synchronized method or statement is invoked on the object. tionships between objects and object references. We show that Both heap allocation and synchronization on locks incur per- the connection graph can be summarized for each method such formance overhead. In this paper, we present escape analy- that the same summary information may be used effectively in sis in the context of Java for determining whether an object (1) different calling contexts. We present an interprocedural al- may escape the method (i.e., is not local to the method) that gorithm that uses the above property to efficiently compute created the object, and (2) may escape the thread that created the connection graph and identify the non-escaping objects for the object (i.e., other threads may access the object). -

Making Collection Operations Optimal with Aggressive JIT Compilation
Making Collection Operations Optimal with Aggressive JIT Compilation Aleksandar Prokopec David Leopoldseder Oracle Labs Johannes Kepler University, Linz Switzerland Austria [email protected] [email protected] Gilles Duboscq Thomas Würthinger Oracle Labs Oracle Labs Switzerland Switzerland [email protected] [email protected] Abstract 1 Introduction Functional collection combinators are a neat and widely ac- Compilers for most high-level languages, such as Scala, trans- cepted data processing abstraction. However, their generic form the source program into an intermediate representa- nature results in high abstraction overheads – Scala collec- tion. This intermediate program representation is executed tions are known to be notoriously slow for typical tasks. We by the runtime system. Typically, the runtime contains a show that proper optimizations in a JIT compiler can widely just-in-time (JIT) compiler, which compiles the intermediate eliminate overheads imposed by these abstractions. Using representation into machine code. Although JIT compilers the open-source Graal JIT compiler, we achieve speedups of focus on optimizations, there are generally no guarantees up to 20× on collection workloads compared to the standard about the program patterns that result in fast machine code HotSpot C2 compiler. Consequently, a sufficiently aggressive – most optimizations emerge organically, as a response to JIT compiler allows the language compiler, such as Scalac, a particular programming paradigm in the high-level lan- to focus on other concerns. guage. Scala’s functional-style collection combinators are a In this paper, we show how optimizations, such as inlin- paradigm that the JVM runtime was unprepared for. ing, polymorphic inlining, and partial escape analysis, are Historically, Scala collections [Odersky and Moors 2009; combined in Graal to produce collections code that is optimal Prokopec et al. -

The Slab Allocator: an Object-Caching Kernel Memory Allocator
The Slab Allocator: An Object-Caching Kernel Memory Allocator Jeff Bonwick Sun Microsystems Abstract generally superior in both space and time. Finally, Section 6 describes the allocator’s debugging This paper presents a comprehensive design over- features, which can detect a wide variety of prob- view of the SunOS 5.4 kernel memory allocator. lems throughout the system. This allocator is based on a set of object-caching primitives that reduce the cost of allocating complex objects by retaining their state between uses. These 2. Object Caching same primitives prove equally effective for manag- Object caching is a technique for dealing with ing stateless memory (e.g. data pages and temporary objects that are frequently allocated and freed. The buffers) because they are space-efficient and fast. idea is to preserve the invariant portion of an The allocator’s object caches respond dynamically object’s initial state — its constructed state — to global memory pressure, and employ an object- between uses, so it does not have to be destroyed coloring scheme that improves the system’s overall and recreated every time the object is used. For cache utilization and bus balance. The allocator example, an object containing a mutex only needs also has several statistical and debugging features to have mutex_init() applied once — the first that can detect a wide range of problems throughout time the object is allocated. The object can then be the system. freed and reallocated many times without incurring the expense of mutex_destroy() and 1. Introduction mutex_init() each time. An object’s embedded locks, condition variables, reference counts, lists of The allocation and freeing of objects are among the other objects, and read-only data all generally qual- most common operations in the kernel. -

Fast Efficient Fixed-Size Memory Pool: No Loops and No Overhead
COMPUTATION TOOLS 2012 : The Third International Conference on Computational Logics, Algebras, Programming, Tools, and Benchmarking Fast Efficient Fixed-Size Memory Pool No Loops and No Overhead Ben Kenwright School of Computer Science Newcastle University Newcastle, United Kingdom, [email protected] Abstract--In this paper, we examine a ready-to-use, robust, it can be used in conjunction with an existing system to and computationally fast fixed-size memory pool manager provide a hybrid solution with minimum difficulty. On with no-loops and no-memory overhead that is highly suited the other hand, multiple instances of numerous fixed-sized towards time-critical systems such as games. The algorithm pools can be used to produce a general overall flexible achieves this by exploiting the unused memory slots for general solution to work in place of the current system bookkeeping in combination with a trouble-free indexing memory manager. scheme. We explain how it works in amalgamation with Alternatively, in some time critical systems such as straightforward step-by-step examples. Furthermore, we games; system allocations are reduced to a bare minimum compare just how much faster the memory pool manager is to make the process run as fast as possible. However, for when compared with a system allocator (e.g., malloc) over a a dynamically changing system, it is necessary to allocate range of allocations and sizes. memory for changing resources, e.g., data assets Keywords-memory pools; real-time; memory allocation; (graphical images, sound files, scripts) which are loaded memory manager; memory de-allocation; dynamic memory dynamically at runtime. -

Escape Analysis on Lists∗
Escape Analysis on Lists∗ Young Gil Parkyand Benjamin Goldberg Department of Computer Science Courant Institute of Mathematical Sciences New York Universityz Abstract overhead, and other optimizations that are possible when the lifetimes of objects can be computed stati- Higher order functional programs constantly allocate cally. objects dynamically. These objects are typically cons Our approach is to define a high-level non-standard cells, closures, and records and are generally allocated semantics that, in many ways, is similar to the stan- in the heap and reclaimed later by some garbage col- dard semantics and captures the escape behavior caused lection process. This paper describes a compile time by the constructs in a functional language. The ad- analysis, called escape analysis, for determining the vantage of our analysis lies in its conceptual simplicity lifetime of dynamically created objects in higher or- and portability (i.e. no assumption is made about an der functional programs, and describes optimizations underlying abstract machine). that can be performed, based on the analysis, to im- prove storage allocation and reclamation of such ob- jects. In particular, our analysis can be applied to 1 Introduction programs manipulating lists, in which case optimiza- tions can be performed to allow whole cons cells in Higher order functional programs constantly allocate spines of lists to be either reclaimed at once or reused objects dynamically. These objects are typically cons without incurring any garbage collection overhead. In cells, closures, and records and are generally allocated a previous paper on escape analysis [10], we had left in the heap and reclaimed later by some garbage col- open the problem of performing escape analysis on lection process.