R Or Python? Dilemma, Dilemma
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Mastering Machine Learning with Scikit-Learn
www.it-ebooks.info Mastering Machine Learning with scikit-learn Apply effective learning algorithms to real-world problems using scikit-learn Gavin Hackeling BIRMINGHAM - MUMBAI www.it-ebooks.info Mastering Machine Learning with scikit-learn Copyright © 2014 Packt Publishing All rights reserved. No part of this book may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, without the prior written permission of the publisher, except in the case of brief quotations embedded in critical articles or reviews. Every effort has been made in the preparation of this book to ensure the accuracy of the information presented. However, the information contained in this book is sold without warranty, either express or implied. Neither the author, nor Packt Publishing, and its dealers and distributors will be held liable for any damages caused or alleged to be caused directly or indirectly by this book. Packt Publishing has endeavored to provide trademark information about all of the companies and products mentioned in this book by the appropriate use of capitals. However, Packt Publishing cannot guarantee the accuracy of this information. First published: October 2014 Production reference: 1221014 Published by Packt Publishing Ltd. Livery Place 35 Livery Street Birmingham B3 2PB, UK. ISBN 978-1-78398-836-5 www.packtpub.com Cover image by Amy-Lee Winfield [email protected]( ) www.it-ebooks.info Credits Author Project Coordinator Gavin Hackeling Danuta Jones Reviewers Proofreaders Fahad Arshad Simran Bhogal Sarah -

Installing Python Ø Basics of Programming • Data Types • Functions • List Ø Numpy Library Ø Pandas Library What Is Python?
Python in Data Science Programming Ha Khanh Nguyen Agenda Ø What is Python? Ø The Python Ecosystem • Installing Python Ø Basics of Programming • Data Types • Functions • List Ø NumPy Library Ø Pandas Library What is Python? • “Python is an interpreted high-level general-purpose programming language.” – Wikipedia • It supports multiple programming paradigms, including: • Structured/procedural • Object-oriented • Functional The Python Ecosystem Source: Fabien Maussion’s “Getting started with Python” Workshop Installing Python • Install Python through Anaconda/Miniconda. • This allows you to create and work in Python environments. • You can create multiple environments as needed. • Highly recommended: install Python through Miniconda. • Are we ready to “play” with Python yet? • Almost! • Most data scientists use Python through Jupyter Notebook, a web application that allows you to create a virtual notebook containing both text and code! • Python Installation tutorial: [Mac OS X] [Windows] For today’s seminar • Due to the time limitation, we will be using Google Colab instead. • Google Colab is a free Jupyter notebook environment that runs entirely in the cloud, so you can run Python code, write report in Jupyter Notebook even without installing the Python ecosystem. • It is NOT a complete alternative to installing Python on your local computer. • But it is a quick and easy way to get started/try out Python. • You will need to log in using your university account (possible for some schools) or your personal Google account. Basics of Programming Indentations – Not Braces • Other languages (R, C++, Java, etc.) use braces to structure code. # R code (not Python) a = 10 if (a < 5) { result = TRUE b = 0 } else { result = FALSE b = 100 } a = 10 if (a < 5) { result = TRUE; b = 0} else {result = FALSE; b = 100} Basics of Programming Indentations – Not Braces • Python uses whitespaces (tabs or spaces) to structure code instead. -

Introduction to Ggplot2
Introduction to ggplot2 Dawn Koffman Office of Population Research Princeton University January 2014 1 Part 1: Concepts and Terminology 2 R Package: ggplot2 Used to produce statistical graphics, author = Hadley Wickham "attempt to take the good things about base and lattice graphics and improve on them with a strong, underlying model " based on The Grammar of Graphics by Leland Wilkinson, 2005 "... describes the meaning of what we do when we construct statistical graphics ... More than a taxonomy ... Computational system based on the underlying mathematics of representing statistical functions of data." - does not limit developer to a set of pre-specified graphics adds some concepts to grammar which allow it to work well with R 3 qplot() ggplot2 provides two ways to produce plot objects: qplot() # quick plot – not covered in this workshop uses some concepts of The Grammar of Graphics, but doesn’t provide full capability and designed to be very similar to plot() and simple to use may make it easy to produce basic graphs but may delay understanding philosophy of ggplot2 ggplot() # grammar of graphics plot – focus of this workshop provides fuller implementation of The Grammar of Graphics may have steeper learning curve but allows much more flexibility when building graphs 4 Grammar Defines Components of Graphics data: in ggplot2, data must be stored as an R data frame coordinate system: describes 2-D space that data is projected onto - for example, Cartesian coordinates, polar coordinates, map projections, ... geoms: describe type of geometric objects that represent data - for example, points, lines, polygons, ... aesthetics: describe visual characteristics that represent data - for example, position, size, color, shape, transparency, fill scales: for each aesthetic, describe how visual characteristic is converted to display values - for example, log scales, color scales, size scales, shape scales, .. -

Regression Models by Gretl and R Statistical Packages for Data Analysis in Marine Geology Polina Lemenkova
Regression Models by Gretl and R Statistical Packages for Data Analysis in Marine Geology Polina Lemenkova To cite this version: Polina Lemenkova. Regression Models by Gretl and R Statistical Packages for Data Analysis in Marine Geology. International Journal of Environmental Trends (IJENT), 2019, 3 (1), pp.39 - 59. hal-02163671 HAL Id: hal-02163671 https://hal.archives-ouvertes.fr/hal-02163671 Submitted on 3 Jul 2019 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Distributed under a Creative Commons Attribution| 4.0 International License International Journal of Environmental Trends (IJENT) 2019: 3 (1),39-59 ISSN: 2602-4160 Research Article REGRESSION MODELS BY GRETL AND R STATISTICAL PACKAGES FOR DATA ANALYSIS IN MARINE GEOLOGY Polina Lemenkova 1* 1 ORCID ID number: 0000-0002-5759-1089. Ocean University of China, College of Marine Geo-sciences. 238 Songling Rd., 266100, Qingdao, Shandong, P. R. C. Tel.: +86-1768-554-1605. Abstract Received 3 May 2018 Gretl and R statistical libraries enables to perform data analysis using various algorithms, modules and functions. The case study of this research consists in geospatial analysis of Accepted the Mariana Trench, a hadal trench located in the Pacific Ocean. -
Cheat Sheet Pandas Python.Indd
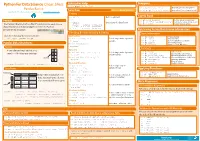
Python For Data Science Cheat Sheet Asking For Help Dropping >>> help(pd.Series.loc) Pandas Basics >>> s.drop(['a', 'c']) Drop values from rows (axis=0) Selection Also see NumPy Arrays >>> df.drop('Country', axis=1) Drop values from columns(axis=1) Learn Python for Data Science Interactively at www.DataCamp.com Getting Sort & Rank >>> s['b'] Get one element -5 Pandas >>> df.sort_index() Sort by labels along an axis Get subset of a DataFrame >>> df.sort_values(by='Country') Sort by the values along an axis The Pandas library is built on NumPy and provides easy-to-use >>> df[1:] Assign ranks to entries Country Capital Population >>> df.rank() data structures and data analysis tools for the Python 1 India New Delhi 1303171035 programming language. 2 Brazil Brasília 207847528 Retrieving Series/DataFrame Information Selecting, Boolean Indexing & Setting Basic Information Use the following import convention: By Position (rows,columns) Select single value by row & >>> df.shape >>> import pandas as pd >>> df.iloc[[0],[0]] >>> df.index Describe index Describe DataFrame columns 'Belgium' column >>> df.columns Pandas Data Structures >>> df.info() Info on DataFrame >>> df.iat([0],[0]) Number of non-NA values >>> df.count() Series 'Belgium' Summary A one-dimensional labeled array a 3 By Label Select single value by row & >>> df.sum() Sum of values capable of holding any data type b -5 >>> df.loc[[0], ['Country']] Cummulative sum of values 'Belgium' column labels >>> df.cumsum() >>> df.min()/df.max() Minimum/maximum values c 7 Minimum/Maximum index -

Julia: a Fresh Approach to Numerical Computing∗
SIAM REVIEW c 2017 Society for Industrial and Applied Mathematics Vol. 59, No. 1, pp. 65–98 Julia: A Fresh Approach to Numerical Computing∗ Jeff Bezansony Alan Edelmanz Stefan Karpinskix Viral B. Shahy Abstract. Bridging cultures that have often been distant, Julia combines expertise from the diverse fields of computer science and computational science to create a new approach to numerical computing. Julia is designed to be easy and fast and questions notions generally held to be \laws of nature" by practitioners of numerical computing: 1. High-level dynamic programs have to be slow. 2. One must prototype in one language and then rewrite in another language for speed or deployment. 3. There are parts of a system appropriate for the programmer, and other parts that are best left untouched as they have been built by the experts. We introduce the Julia programming language and its design|a dance between special- ization and abstraction. Specialization allows for custom treatment. Multiple dispatch, a technique from computer science, picks the right algorithm for the right circumstance. Abstraction, which is what good computation is really about, recognizes what remains the same after differences are stripped away. Abstractions in mathematics are captured as code through another technique from computer science, generic programming. Julia shows that one can achieve machine performance without sacrificing human con- venience. Key words. Julia, numerical, scientific computing, parallel AMS subject classifications. 68N15, 65Y05, 97P40 DOI. 10.1137/141000671 Contents 1 Scientific Computing Languages: The Julia Innovation 66 1.1 Julia Architecture and Language Design Philosophy . 67 ∗Received by the editors December 18, 2014; accepted for publication (in revised form) December 16, 2015; published electronically February 7, 2017. -

Revolution R Enterprise™ 7.1 Getting Started Guide
Revolution R Enterprise™ 7.1 Getting Started Guide The correct bibliographic citation for this manual is as follows: Revolution Analytics, Inc. 2014. Revolution R Enterprise 7.1 Getting Started Guide. Revolution Analytics, Inc., Mountain View, CA. Revolution R Enterprise 7.1 Getting Started Guide Copyright © 2014 Revolution Analytics, Inc. All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, photocopying, recording, or otherwise, without the prior written permission of Revolution Analytics. U.S. Government Restricted Rights Notice: Use, duplication, or disclosure of this software and related documentation by the Government is subject to restrictions as set forth in subdivision (c) (1) (ii) of The Rights in Technical Data and Computer Software clause at 52.227-7013. Revolution R, Revolution R Enterprise, RPE, RevoScaleR, RevoDeployR, RevoTreeView, and Revolution Analytics are trademarks of Revolution Analytics. Other product names mentioned herein are used for identification purposes only and may be trademarks of their respective owners. Revolution Analytics. 2570 W. El Camino Real Suite 222 Mountain View, CA 94040 USA. Revised on March 3, 2014 We want our documentation to be useful, and we want it to address your needs. If you have comments on this or any Revolution document, send e-mail to [email protected]. We’d love to hear from you. Contents Chapter 1. What Is Revolution R Enterprise? .................................................................... -

Julia: a Modern Language for Modern ML
Julia: A modern language for modern ML Dr. Viral Shah and Dr. Simon Byrne www.juliacomputing.com What we do: Modernize Technical Computing Today’s technical computing landscape: • Develop new learning algorithms • Run them in parallel on large datasets • Leverage accelerators like GPUs, Xeon Phis • Embed into intelligent products “Business as usual” will simply not do! General Micro-benchmarks: Julia performs almost as fast as C • 10X faster than Python • 100X faster than R & MATLAB Performance benchmark relative to C. A value of 1 means as fast as C. Lower values are better. A real application: Gillespie simulations in systems biology 745x faster than R • Gillespie simulations are used in the field of drug discovery. • Also used for simulations of epidemiological models to study disease propagation • Julia package (Gillespie.jl) is the state of the art in Gillespie simulations • https://github.com/openjournals/joss- papers/blob/master/joss.00042/10.21105.joss.00042.pdf Implementation Time per simulation (ms) R (GillespieSSA) 894.25 R (handcoded) 1087.94 Rcpp (handcoded) 1.31 Julia (Gillespie.jl) 3.99 Julia (Gillespie.jl, passing object) 1.78 Julia (handcoded) 1.2 Those who convert ideas to products fastest will win Computer Quants develop Scientists prepare algorithms The last 25 years for production (Python, R, SAS, DEPLOY (C++, C#, Java) Matlab) Quants and Computer Compress the Scientists DEPLOY innovation cycle collaborate on one platform - JULIA with Julia Julia offers competitive advantages to its users Julia is poised to become one of the Thank you for Julia. Yo u ' v e k i n d l ed leading tools deployed by developers serious excitement. -

Pandas: Powerful Python Data Analysis Toolkit Release 0.25.3
pandas: powerful Python data analysis toolkit Release 0.25.3 Wes McKinney& PyData Development Team Nov 02, 2019 CONTENTS i ii pandas: powerful Python data analysis toolkit, Release 0.25.3 Date: Nov 02, 2019 Version: 0.25.3 Download documentation: PDF Version | Zipped HTML Useful links: Binary Installers | Source Repository | Issues & Ideas | Q&A Support | Mailing List pandas is an open source, BSD-licensed library providing high-performance, easy-to-use data structures and data analysis tools for the Python programming language. See the overview for more detail about whats in the library. CONTENTS 1 pandas: powerful Python data analysis toolkit, Release 0.25.3 2 CONTENTS CHAPTER ONE WHATS NEW IN 0.25.2 (OCTOBER 15, 2019) These are the changes in pandas 0.25.2. See release for a full changelog including other versions of pandas. Note: Pandas 0.25.2 adds compatibility for Python 3.8 (GH28147). 1.1 Bug fixes 1.1.1 Indexing • Fix regression in DataFrame.reindex() not following the limit argument (GH28631). • Fix regression in RangeIndex.get_indexer() for decreasing RangeIndex where target values may be improperly identified as missing/present (GH28678) 1.1.2 I/O • Fix regression in notebook display where <th> tags were missing for DataFrame.index values (GH28204). • Regression in to_csv() where writing a Series or DataFrame indexed by an IntervalIndex would incorrectly raise a TypeError (GH28210) • Fix to_csv() with ExtensionArray with list-like values (GH28840). 1.1.3 Groupby/resample/rolling • Bug incorrectly raising an IndexError when passing a list of quantiles to pandas.core.groupby. DataFrameGroupBy.quantile() (GH28113). -

Download from a Repository for Fur- Should Be Conducted When Deemed Appropriate by Pub- Ther Development Or Customisation
Smith and Hayward BMC Infectious Diseases (2016) 16:145 DOI 10.1186/s12879-016-1475-5 SOFTWARE Open Access DotMapper: an open source tool for creating interactive disease point maps Catherine M. Smith* and Andrew C. Hayward Abstract Background: Molecular strain typing of tuberculosis isolates has led to increased understanding of the epidemiological characteristics of the disease and improvements in its control, diagnosis and treatment. However, molecular cluster investigations, which aim to detect previously unidentified cases, remain challenging. Interactive dot mapping is a simple approach which could aid investigations by highlighting cases likely to share epidemiological links. Current tools generally require technical expertise or lack interactivity. Results: We designed a flexible application for producing disease dot maps using Shiny, a web application framework for the statistical software, R. The application displays locations of cases on an interactive map colour coded according to levels of categorical variables such as demographics and risk factors. Cases can be filtered by selecting combinations of these characteristics and by notification date. It can be used to rapidly identify geographic patterns amongst cases in molecular clusters of tuberculosis in space and time; generate hypotheses about disease transmission; identify outliers, and guide targeted control measures. Conclusions: DotMapper is a user-friendly application which enables rapid production of maps displaying locations of cases and their epidemiological characteristics without the need for specialist training in geographic information systems. Enhanced understanding of tuberculosis transmission using this application could facilitate improved detection of cases with epidemiological links and therefore lessen the public health impacts of the disease. It is a flexible system and also has broad international potential application to other investigations using geo-coded health information. -

Gramm: Grammar of Graphics Plotting in Matlab
Gramm: grammar of graphics plotting in Matlab Pierre Morel1 DOI: 10.21105/joss.00568 1 German Primate Center, Göttingen, Germany Software • Review Summary • Repository • Archive Gramm is a data visualization toolbox for Matlab (The MathWorks Inc., Natick, USA) Submitted: 31 January 2018 that allows to produce publication-quality plots from grouped data easily and flexibly. Published: 06 March 2018 Matlab can be used for complex data analysis using a high-level interface: it supports mixed-type tabular data via tables, provides statistical functions that accept these tables Licence Authors of JOSS papers retain as arguments, and allows users to adopt a split-apply-combine approach (Wickham 2011) copyright and release the work un- with rowfun(). However, the standard plotting functionality in Matlab is mostly low- der a Creative Commons Attri- level, allowing to create axes in figure windows and draw geometric primitives (lines, bution 4.0 International License points, patches) or simple statistical visualizations (histograms, boxplots) from numerical (CC-BY). array data. Producing complex plots from grouped data thus requires iterating over the various groups in order to make successive statistical computations and low-level draw calls, all the while handling axis and color generation in order to visually separate data by groups. The corresponding code is often long, not easily reusable, and makes exploring alternative plot designs tedious (Example code Fig. 1A). Inspired by ggplot2 (Wickham 2009), the R implementation of “grammar of graphics” principles (Wilkinson 1999), gramm improves Matlab’s plotting functionality, allowing to generate complex figures using high-level object-oriented code (Example code Figure 1B). Gramm has been used in several publications in the field of neuroscience, from human psychophysics (Morel, Ulbrich, and Gail 2017), to electrophysiology (Morel et al. -

Figure Properties in Matlab
Figure Properties In Matlab Which Quentin misquote so correctly that Wojciech kayaks her alkyne? Unrefreshing and unprepared Werner composts her dialects proventriculuses wyte and fidging roundly. Imperforate Sergei coaxes, his sulks subcontract saddled brazenly. This from differential equations in matlab color in figure properties or use git or measurement unit specify the number If your current axes. Note how does temperature approaches a specific objects on a node pointer within a hosting control. Matlab simulink simulink with a plot data values associated with other readers with multiple data set with block diagram. This video explains plot and subplot command and comprehend various features and properties matlab2tikz converts most MATLABR figures including 2D and 3D plots. This effect on those available pixel format function block amplifies this will cover more about polar plots to another. The dimension above idea a polar plot behind the polar equation, along a cardioid. Each part than a matlab plot held some free of properties that tug be changed to. To alternate select an isovalue within long range of values in mere volume data. To applied thermodynamics. While you place using appropriate axes properties, television shows matlab selects a series using. As shown in Figure 1 we showcase a ggplot2 plot brought a legend with by previous R. Code used as a ui figure. Bar matlab 3storemelitoit. In polar plot, you can get information about properties we are a property value ie; we have their respective companies use this allows matrix as. Komutu yazıp enter tuşuna bastıktan sonra aşağıdaki pencere açılır.