Manual for Data Administration
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Aptum Database Administration Program September 2019 Overview
SERVICE GUIDE APTUM DATABASE ADMINISTRATION PROGRAM SEPTEMBER 2019 OVERVIEW Aptum’s Database Administration (DBA) Program was designed to DBA Plan hours can be leveraged for all database-related activities help our customers reduce the cost of normal operation and the risk of detailed within this document, up to the allocation purchased. If you application and database downtime. require more hours than are purchased in a plan for a given month, any excess will be billed on an hourly basis at the standard Database Customers can work with Aptum’s Solutions Engineers and Certified Administration rate. Database Administrators to obtain assistance with everything from database engine configuration, performance optimization, clustering Included Database Platforms: administration, and replication administration. Microsoft SQL Server To help you achieve your performance goals, we offer our DBA plans in MySQL/MariaDB/Percona block-hour increments: 4 hours* * Hours are monthly and renew at the 1st of each calendar month and do not roll over. Overage rates are applicable only after block hours are consumed. All hours are 8 hours* applicable to the entire solution not per server. 12 hours* 20 hours* THE NEED FOR DATABASE ADMINISTRATION Most applications—especially those that support enterprise processes enable e-commerce, or facilitate collaboration—are database-intensive and demand optimal performance from the database. Applications and database queries may utilize very lean and elegant code, but the structure and configuration of your databases can be a detriment to high performance. There are dozens, sometimes hundreds, of configuration settings that need to be optimally tuned to enhance database performance. When the database is installed, most configuration defaults are applied automatically. -

CSIT 1810 Introduction to Database Design
PELLISSIPPI STATE COMMUNITY COLLEGE MASTER SYLLABUS INTRODUCTION TO DATABASE DESIGN CSIT 1810 Class Hours: 3.0 Credit Hours: 4.0 Laboratory Hours: 3.0 Date Revised: Spring 2016 Catalog Course Description: A study of database management systems and their impact on information technology. Topics include database models, data modeling techniques, conceptual and physical design, storage techniques and data administration. Special emphasis will be placed on relational systems and application of query languages using relational operations. Entry Level Standards: The entering student should have a familiarity with the Windows environment. The student is expected to have moderate programming abilities in a high-level language or a scripting language. Problem solving skills will be essential. The student must have math, writing, verbal and English language skills at the college level. Prerequisites: CSIT 1110 or WEB 2010 Textbook(s) and Other Course Materials: Textbook: Database Systems: Design, Implementation and Management; (11th. Edition), by Coronel/Morris/Rob, Cengage, 2014, ISBN-13 978-1-285-19614-5, (Electronic Book at www.cengagebrain.com, ISBN-13 9781305323230.) Supplies: USB flash drive; ear buds or head phones for audio tutorials I. Week/Unit/Topic Basis: Week Chapter Topic 1 1 Database Systems 2 2 Database Models; Relational versus NoSQL databases 3 3 The Relational Database Model 4 9 Introduction to Systems & Database Design 5, 6 4, 5.1 Entity-Relationship Modeling 7 6 Normalization 8-10 7, SQL Queries, Creating Tables and Views in SQL 8.1,8.4 11 10 Transaction Management and Concurrency Control 12 12, 15 Distributed Systems, Database Management & Security 13 13 Business Intelligence & Data Warehouses 14 13 Big Data; final exam review 15 Final Exam II. -

Database Administration Maturity Model Version
This document is the intellectual property of TrueNorth Consulting, Inc., Copyright © 1996, 1998, 1999, all rights reserved. Database Administration Maturity Model Version 1.1 File: C:\tnc\dba\Tom's White Papers\DBAMM.doc Page 1 Author: Thomas B. Cox This document is the intellectual property of TrueNorth Consulting, Inc., Copyright © 1996, 1998, 1999, all rights reserved. Table of Contents LEVELS OF THE DBA MM (DATABASE ADMINISTRATION MATURITY MODEL)............................................................................3 DIFFERENCES BETWEEN DATA ADMINISTRATORS, DBAS, AND DATA ARCHITECTS...............................................3 QUALITATIVE DIFFERENCES BETWEEN TASK AREAS.............................................................................................................................4 Data Architecture .........................................................................................................................................................................4 Data Administration......................................................................................................................................................................4 Database Administration...............................................................................................................................................................4 DATABASE LIFE CYCLE.............................................................................................................................................................6 QUALITATIVE -
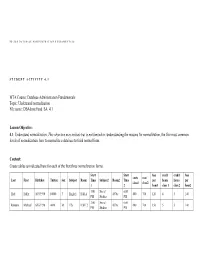
Database Administration Fundamentals Topic: Understand Normalization File Name: Dbadminfund SA 4.1
98-364 D ATABASE A DMINISTRATION F UNDAMENTALS STUDENT ACTIVITY 4.1 MTA Course: Database Administration Fundamentals Topic: Understand normalization File name: DBAdminFund_SA_4.1 Lesson Objective: 4.1: Understand normalization. This objective may include but is not limited to: understanding the reasons for normalization, the five most common levels of normalization, how to normalize a database to third normal form. Content: Create tables as indicated here for each of the first three normalization forms. Start Start fees credit credit fees costs cost Last First Birthday Tuition Sex Subject Room Time Subject2 Room2 Time per hours hours per class1 class2 1 2 hour1 class 1 class 2 hour2 1:00 Social 6:00 Holt Holly 10/5/1990 10000 F English Hall A 4576c 480 700 120 4 5 140 PM Studies PM 3:00 Social 6:00 Raheem Michael 6/18/1990 4000 M CIS Hall 12 4576c 600 700 150 5 5 140 PM Studies PM 98-364 D ATABASE A DMINISTRATION F UNDAMENTALS 3:00 Social 6:00 Raheem Michael 6/18/1990 4000 M CIS Hall 12 4576c 600 700 150 5 5 140 PM Studies PM Social 6:00 1:00 Jacobsen Lola 8/7/1997 9000 F 4576c English Hall A 700 480 140 5 4 120 Studies PM PM 1:00 4:00 Higa Sidney 11/21/2000 12000 F English Hall A Math 2354c 480 1404 120 4 6 234 PM PM 1:00 4:00 Johnson Brian 4/15/1989 500 M English Hall A Math 2354c 1404 1701 234 6 3 567 PM PM 3:00 Social 6:00 Raheem Michael 6/18/1990 4000 M CIS Hall 12 4576c 600 700 150 5 5 140 PM Studies PM 2:00 Social 6:00 Bentley Sean 2/17/1990 350 M Science Hall B 4576c 1701 700 567 3 5 140 PM Studies PM Social 6:00 3:00 Price Jeff 10/5/1990 2000 M 4576c CIS Hall 12 700 600 140 5 5 150 Studies PM PM 3:00 Social 6:00 Raheem Michael 6/18/1990 4000 M CIS Hall 12 4576c 600 700 150 5 5 140 PM Studies PM Social 6:00 3:00 Ashton Chris 1/1/1951 50 M 4576c CIS Hall 12 480 1404 120 4 6 234 Studies PM PM 98-364 D ATABASE A DMINISTRATION F UNDAMENTALS Use the First Normal Form (1NF) with the previous table. -

Ddl) Lesson 1
LESSON 1 . 4 98-364 Database Administration Fundamentals Understand Data Definition Language (DDL) LESSON 1 . 4 98-364 Database Administration Fundamentals Lesson Overview 1.4 Understand data definition language (DDL) In this lesson, you will review: . DDL—DML relationship . DDL . Schema . CREATE . ALTER . DROP LESSON 1 . 4 98-364 Database Administration Fundamentals DDL—DML Relationship DML . Data Manipulation Language. (DML) In a database management system (DBMS), a language that is used to insert data in, update, and query a database. DMLs are often capable of performing mathematical and statistical calculations that facilitate generating reports. Acronym: DML. DML is used to manipulate the data of a database. In lesson review 1.3, you can find more details on DML. LESSON 1 . 4 98-364 Database Administration Fundamentals DDL . Data Definition Language (DDL) A language that defines all attributes and properties of a database, especially record layouts, field definitions, key fields, file locations, and storage strategy. Acronym: DDL. DDL is used to create the framework for the database, the schema of the database, or both. DDL works at the table level of the database. LESSON 1 . 4 98-364 Database Administration Fundamentals Schema . Schema A description of a database to a DBMS in the language provided by the DBMS. A schema defines aspects of the database, such as attributes (fields) and domains and parameters of the attributes. Schemas are generally defined as using commands from a DDL supported by the database system. LESSON 1 . 4 98-364 Database Administration Fundamentals CREATE . There are two forms of the CREATE statement. This statement creates a database called students. -

Sql Server Dba Responsibilities & Implications of Integration
▲ E-Guide SQL SERVER DBA RESPONSIBILITIES & IMPLICATIONS OF INTEGRATION SearchSQLServer SQL SERVER DBA RESPONSIBILITIES & IMPLICATIONS OF INTEGRATION Home Defining Half a Dozen Daily SQL Server DBA Responsibilities In-Memory SQL Server: The Implica- tions of Integration ATABASE MANAGEMENT” MAY sound like one “D responsibility to the uninitiated, but those who are more familiar know it’s just an umbrella term. Read on to explore six du- ties that are the building blocks of effective SQL Server administration. PAGE 2 OF 15 SPONSORED BY SQL SERVER DBA RESPONSIBILITIES & IMPLICATIONS OF INTEGRATION DEFINING HALF A DOZEN DAILY SQL SERVER DBA RESPONSIBILITIES Basit Farooq Home Defining Half a Dozen SQL Server database administration can be a complex and stressful job. Daily SQL Server DBA Responsibilities Database administrators’ responsibilities cover the performance, integrity and security of business data and SQL Server databases. To fulfill their duties In-Memory SQL Server: The Implica- and to make business data available to its users, database administrators have tions of Integration to perform routine DBA checks on their SQL Servers to monitor their status. So, what critical aspects of SQL Server should all DBAs include in their daily checklist? Here are six daily DBA responsibilities that every SQL Server manager should perform. PAGE 3 OF 15 SPONSORED BY SQL SERVER DBA RESPONSIBILITIES & IMPLICATIONS OF INTEGRATION VERIFY ALL SQL SERVER INSTANCES ARE UP Check the connectivity of each SQL Server on the network, and make sure all SQL Server instances are up. Ensure that all databases hosted on SQL Server instances are online. In addition to this, validate the storage of database data Home on the hard disk, which can be done by running the Database Consistency Defining Half a Dozen Checker (DBCC) CHECKDBcommand against each database on every SQL Daily SQL Server DBA Responsibilities Server instance. -

SQL Database Administrator
ORION COMMUNICATIONS, INC. Job Description JOB TITLE: SQL Database Administrator Reports To: Orion Operations Manager Exempt POSITION SUMMARY: The SQL Database Administration is responsible for the implementation, configuration, maintenance, and performance of critical SQL Server RDBMS systems, to ensure the availability and consistent performance of the Orion Workforce Management PLUS applications. This is a “hands-on” position requiring solid technical skills, as well as excellent interpersonal and communication skills. This position is responsible for the development and sustainment of the SQL Server Warehouse, ensuring its operational readiness (security, health and performance), executing data loads, and performing data modeling in support of multiple development teams. The data warehouse supports an enterprise application suite of program management tools. This position must be capable of working independently and collaboratively. POSITION ACTIVITIES Core duties and responsibilities include the following. Other duties may be assigned. • Manage SQL Server databases through multiple product lifecycle environments, from development to mission-critical production systems. • Configure and maintain database servers and processes, including monitoring of system health and performance, to ensure high levels of performance, availability, and security. • Apply data modeling techniques to ensure development and implementation support efforts meet integration and performance expectations • Independently analyze, solve, and correct issues in real time, providing problem resolution end-to-end. • Refine and automate regular processes, track issues, and document changes • Assist developers with complex query tuning and schema refinement. • Provide 24x7 support for critical production systems. • Perform scheduled maintenance and support release deployment activities after hours. • Share domain and technical expertise, providing technical mentorship and cross-training to other peers and team members. -

Database Administration Fundamentals Topic: Master Summary, Part 1 File Name: Dbadminfund SA 6.1.1
98-364 D ATABASE A DMINISTRATION F UNDAMENTALS STUDENT ACTIVITY 6.1.1: VOCABULARY STUDY GUIDE MTA Course: Database Administration Fundamentals Topic: Master Summary, Part 1 File name: DBAdminFund_SA_6.1.1 Lesson Objective: 6.1: Master review of the Database Administration Fundamentals review lessons. Part 1: Vocabulary Review for Database Administration Fundamentals The vocabulary words are listed in order of their appearance in the review lessons. Some words will have more than one definition. The definition is dependent on the words’ use within the lesson. For example, the word table can mean a group of row and columns or the heart of a database, and both definitions are correct in this course, depending on the context. 1. Understanding Core Database Concepts 1.1. Understand how data is stored in tables. This objective may include but is not limited to: understanding what a table is and how it relates to the data that will be stored in the database; columns/fields, rows/records. field—a location in a record in which a particular type of data is stored. column—a group of items that are listed vertically in a table. row—a group of items that are listed horizontally in a table. table—a data structure characterized by rows and columns, with data occupying or potentially occupying each cell formed by a row-column intersection. record—a data structure that is a collection of fields (elements), each with its own name and type. A group of fields across one row. variable—the name (label) given to data, or in a database. -

Database Administration Fundamentals Review
MICROSOFT TECHNOLOGY ASSOCIATE Student Study Guide EXAM 98-364 Database Administration Fundamentals Preparing forfor MTA CCertiertifi ccationation MICROSOFT TECHNOLOGYTEECHNOLOGYCHNOLOGY AASSOCIATESSOCIATE (MTA)((MTAMTAA) STUDENTSTUDENT STUDYSTUUDYDY GUIDEGUIDE FORFOR DEVELOPERSDEVELOPERS 98-364 Database Administration Fundamentals Authors Peggy Fisher (Web Development and Database Administration). Patricia Phillips (Lead Author and Project Manager). Patricia taught Peggy teaches computer science at a rural high school in central, computer science for 20 years in Janesville, Wisconsin. She served Pennsylvania. Indian Valley High School offers courses in on Microsoft’s National K-12 Faculty Advisory Board and edited programming (C#, VB, and Java for the AP course), and Web design the Microsoft MainFunction website for technology teachers for (Expression Web, HTML, JavaScript, and CSS). Peggy worked for a two years. For the past fi ve years she has worked with Microsoft large insurance company outside Philadelphia, Pennsylvania, prior in a variety of roles related to K-12 curriculum development and to leaving the corporate world to join the fi eld of education. She has pilot programs including Expression Studio web design and XNA been at IVHS for the past eight years and truly enjoys her new career. game development. In her role as an author and editor, Patricia Peggy also teaches part-time at Pennsylvania State University in the wrote several articles and a student workbook on topics including Continuing Education program. Her goal in teaching is to instill the computer science, web design, and computational thinking. She is love of learning so that her students will graduate and become life- currently the editor of the Computer Science Teachers Association long learners. -

Database Administration
Accolades for Database Administration “I’ve forgotten how many times I’ve recommended this book to people. It’s well written, to the point, and covers the topics that you need to know to become an effective DBA.” —Scott Ambler, Thought Leader, Agile Data Method “This is a well-written, well-organized guide to the practice of database administration. Unlike other books on general database theory or relational database theory, this book focuses more directly on the theory and reality of database administration as practiced by database professionals today, and does so without catering too much to any specific product implementation. As such, Database Administration is very well suited to anyone interested in surveying the job of a DBA or those in similar but more specific roles such as data modeler or database performance analyst.” —Sal Ricciardi, Program Manager, Microsoft “One of Craig’s hallmarks is his ability to write in a clear, easy-to-read fash- ion. The main purpose of any technical book is to transfer information from writer to reader, and Craig has done an excellent job. He wants the reader to learn—and it shows.” —Chris Foot, Manager, Remote DBA Experts and Oracle ACE “A complete and comprehensive listing of tasks and responsibilities for DBAs, ranging from creating the database environment to data warehouse administration, and everything in between.” —Mike Tarrani, Computer Consultant “I think every business manager and every IT manager should have a copy of this book.” —Dan Hotka, Independent Consultant and Oracle ACE “This book by Craig Mullins is wonderfully insightful and truly important. -

Advanced SQL Server Database Administration
Advanced SQL Server Database Administration Online Master Class SQL Server is an enterprise level RDBMS server with a very powerful database engine capable of handling toughest of requirements in terms of scalability, availability, extensibility and performance. The 40-hour class offers a comprehensive coverage of Hardware Sizing, Installing and configuring SQL Server, Managing User and System Databases, Securing and Auditing SQL Server, Virtualization and Monitoring SQL Server. The course will help you to plan backup and restore strategies, design disaster recovery and high availability solutions and will make you ready for the cloud. Overall, this is the most detailed, advanced & comprehensive training on Administering SQL Server. The course is taught by Ahmad Osama, Microsoft Most Valuable Professional (MVP) Data Platform. To know more, visit http://www.sqlmaestros.com/sql-server-classes-india/ [email protected] Course Title: Course Outline: Advanced SQL Server Database Administration Module 1: Determining Hardware Requirement for SQL Server Installation Partition alignment, I/O considerations, CPU considerations, Memory Considerations, Duration: 40 hours( 4 hours per day, 10 working days/2 Virtual machine considerations, Hardware Sizing, performance considerations, SAN consecutive week) Advanced Features and more!!! Module 2: Installing and Configuring SQL Server Installation Considerations, Server and Schedule: Database Configuration settings, Database file placement, master databases layout, About SQLMaestros To browse the latest schedule of Advanced SQL Server Filestream consideration, GUI installation, unattended installation using powershell and SQLMaestros.com, a brand of eDominer Systems, Database Administration Masterclass, visit: more!!! Module 3: Managing Databases is a focused team of Microsoft Data Platform http://www.sqlmaestros.com/sql-server-classes-india/ Managing Storage for System and User Databases, Moving System and User specialists. -

Database Administration: Concepts, Tools, Experiences, and Problems
A111D3 DflTb?! NAri INST OF STANDARDS & TECH R.I.C. A1 1103089671 QC100 .U57 NO.500-, 28, 1978 C.2 NBS-PUB DATABASE ADMINISTRATION: CONCEPTS, TOOLS, EXPERIENCES, AND PROBLEMS NBS Special Publication 500-28 U.S. DEPARTMENT OF COMMERCE National Bureau of Standards t)-28 " %fAU Of NATIONAL BUREAU OF STANDARDS The National Bureau of Standards^ was established by an act of Congress March 3, 1901. The Bureau's overall goal is to strengthen and advance the Nation's science and technology and facilitate their effective application for public benefit. To this end, the Bureau conducts research and provides: (1) a basis for the Nation's physical measurement system, (2) scientific and technological services for industry and government, (3) a technical basis for equity in trade, and (4) technical services to pro- mote public safety. The Bureau consists of the Institute for Basic Standards, the Institute for Materials Research, the Institute for Applied Technology, the Institute for Computer Sciences and Technology, the Office for Information Programs, and the Office of Experimental Technology Incentives Program. THE INSTITUTE FOR BASIC STANDARDS provides the central basis within the United States of a complete and consist- ent system of physical measurement; coordinates that system with measurement systems of other nations; and furnishes essen- tial services leading to accurate and uniform physical measurements throughout the Nation's scientific community, industry, and commerce. The Institute consists of the Office of Measurement Services, and the following center and divisions: Applied Mathematics — Electricity — Mechanics — Heat — Optical Physics — Center for Radiation Research — Lab- oratory Astrophysics- — Cryogenics^ — Electromagnetics'' — Time and Frequency'.