Deep Learning of Graph Transformations
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
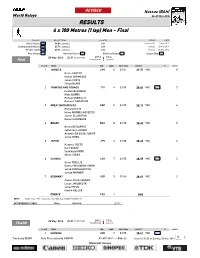
RESULTS 4 X 100 Metres (1 Lap) Men - Final
REVISED Nassau (BAH) World Relays 24-25 May 2014 RESULTS 4 x 100 Metres (1 lap) Men - Final RECORDS RESULT TEAM COUNTRY VENUE DATE World Record WR 36.84 Jamaica JAM London (OP) 11 Aug 2012 Championship Record CR 37.71 Jamaica JAM Nassau 25 May 2014 World Leading WL 37.71 Jamaica JAM Nassau 25 May 2014 Area Record AR National Record NR National Record PB Season Best SB 25 May 2014 20:39 START TIME 29° C 73 % Final TEMPERATURE HUMIDITY PLACE TEAM BIB LANEREACTION RESULT Fn POINTS 1 JAMAICA JAM 6 0.157 37.77 *WC 8 Nesta CARTER Nickel ASHMEADE Julian FORTE Yohan BLAKE 2 TRINIDAD AND TOBAGO TTO 4 0.189 38.04 *WC SB 7 Keston BLEDMAN Marc BURNS Rondel SORRILLO Richard THOMPSON 3 GREAT BRITAIN & N.I. GBR 5 0.139 38.19 *WC 6 Richard KILTY Harry AIKINES-ARYEETEY James ELLINGTON Dwain CHAMBERS 4 BRAZIL BRA 8 0.150 38.40 *WC 5 Bruno DE BARROS Jefferson LUCINDO Aldemir DA SILVA JUNIOR Jorge VIDES 5 JAPAN JPN 2 0.180 38.40 *WC 4 Kazuma OSETO Kei TAKASE Yoshihide KIRYU Shota IIZUKA 6 CANADA CAN 7 0.155 38.55 *WC SB 3 Gavin SMELLIE Dontae RICHARDS-KWOK Jared CONNAUGHTON Justyn WARNER 7 GERMANY GER 3 0.154 38.69 *WC 2 Aleixo-Platini MENGA Lucas JAKUBCZYK Julian REUS Martin KELLER FRANCE FRA 1 DNS NOTE IAAF Rule *WC - Qualified for WORLD CHAMPIONSHIPS INTERMEDIATE TIMES 300m JAMAICA 28.70 25 May 2014 20:28 START TIME 29° C 73 % Final B TEMPERATURE HUMIDITY PLACE TEAM BIB LANEREACTION RESULT Fn POINTS 1 UKRAINE UKR 7 0.155 38.53 *WC NR 1 2 Timing by SEIKO Data Processing by CANON AT-4X1-M-f----.RS6..v2 Issued at 21:32 on Sunday, 25 May 2014 Official IAAF -

A Novel Application of Pagerank and User Preference Algorithms for Assessing the Relative Performance of Track Athletes in Competition
RESEARCH ARTICLE A novel application of PageRank and user preference algorithms for assessing the relative performance of track athletes in competition Clive B. Beggs1*, Simon J. Shepherd2, Stacey Emmonds1, Ben Jones1 1 Institute for Sport, Physical Activity and Leisure, Carnegie Faculty, Leeds Beckett University, Leeds, West a1111111111 Yorkshire, United Kingdom, 2 Medical Biophysics Laboratory, University of Bradford, Bradford, United a1111111111 Kingdom a1111111111 a1111111111 * [email protected] a1111111111 Abstract Ranking enables coaches, sporting authorities, and pundits to determine the relative perfor- OPEN ACCESS mance of individual athletes and teams in comparison to their peers. While ranking is rela- Citation: Beggs CB, Shepherd SJ, Emmonds S, tively straightforward in sports that employ traditional leagues, it is more difficult in sports Jones B (2017) A novel application of PageRank where competition is fragmented (e.g. athletics, boxing, etc.), with not all competitors com- and user preference algorithms for assessing the peting against each other. In such situations, complex points systems are often employed to relative performance of track athletes in competition. PLoS ONE 12(6): e0178458. https:// rank athletes. However, these systems have the inherent weakness that they frequently rely doi.org/10.1371/journal.pone.0178458 on subjective assessments in order to gauge the calibre of the competitors involved. Here Editor: Wei-Xing Zhou, East China University of we show how two Internet derived algorithms, the PageRank (PR) and user preference Science and Technology, CHINA (UP) algorithms, when utilised with a simple `who beat who' matrix, can be used to accu- Received: December 9, 2016 rately rank track athletes, avoiding the need for subjective assessment. -

2013 World Championships Statistics – Men's 200M by K Ken Nakamura
2013 World Championships Statistics – Men’s 200m by K Ken Nakamura The records to look for in Moskva: 1) Nobody won 100m/200m double at the Worlds more than once. Can Bolt do it for the second time? 2) Can Bolt win 200m for the third time to surpass Michael Johnson and Calvin Smith? 3) No country other than US ever won multiple medals in this event. Can Jamaica do it? 4) No European won medal at both 100m and 200m? Can Lemaitre change that? All time Performance List at the World Championships Performance Performer Time Wind Name Nat Pos Venue Year 1 1 19.19 -0.3 Usain Bolt JAM 1 Berlin 2009 2 19.40 0.8 Usain Bolt 1 Daegu 2011 3 2 19.70 0.8 Walter Dix USA 2 Daegu 2011 4 3 19.76 -0.8 Tyson Gay USA 1 Osaka 2007 5 4 19.79 0.5 Michael Johnson USA 1 Göteborg 1995 6 5 19.80 0.8 Christophe Lemaitre FRA 3 Daegu 2011 7 6 19.81 -0.3 Alonso Edward PAN 2 Berlin 2009 8 7 19.84 1.7 Francis Obikwelu NGR 1sf2 Sevilla 1999 9 8 19.85 0.3 Frankie Fredericks NAM 1 Stuttgart 1993 9 9 19.85 -0.3 Wallace Spearmon USA 3 Berlin 2009 11 10 19.89 -0.3 Shawn Crawford USA 4 Berlin 2009 12 11 19.90 1.2 Maurice Greene USA 1 Sevilla 1999 13 19.91 -0.8 Usain Bolt 2 Osaka 2007 14 12 19.94 0.3 John Regis GBR 2 Stuttgart 1993 15 13 19.95 0.8 Jaysuma Saidy Ndure NOR 4 Daegu 2011 16 14 19.98 1.7 Marcin Urbas POL 2sf2 Sevilla 1999 16 15 19.98 -0.3 Steve Mullings JAM 5 Berlin 2009 17 16 19.99 0.3 Carl Lewis USA 3 Stuttgart 1993 19 17 20.00 1.2 Claudinei da Silva BRA 2 Sevilla 1999 19 20.00 -0.4 Tyson Gay 1sf2 Osaka 2007 21 20.01 -3.4 Michael Johnson 1 Tokyo 1991 21 20.01 0.3 -

Table of Contents
A Column By Len Johnson TABLE OF CONTENTS TOM KELLY................................................................................................5 A RELAY BIG SHOW ..................................................................................8 IS THIS THE COMMONWEALTH GAMES FINEST MOMENT? .................11 HALF A GLASS TO FILL ..........................................................................14 TOMMY A MAN FOR ALL SEASONS ........................................................17 NO LIGHTNING BOLT, JUST A WARM SURPRISE ................................. 20 A BEAUTIFUL SET OF NUMBERS ...........................................................23 CLASSIC DISTANCE CONTESTS FOR GLASGOW ...................................26 RISELEY FINALLY GETS HIS RECORD ...................................................29 TRIALS AND VERDICTS ..........................................................................32 KIRANI JAMES FIRST FOR GRENADA ....................................................35 DEEK STILL WEARS AN INDELIBLE STAMP ..........................................38 MICHAEL, ELOISE DO IT THEIR WAY .................................................... 40 20 SECONDS OF BOLT BEATS 20 MINUTES SUNSHINE ........................43 ROWE EQUAL TO DOUBELL, NOT DOUBELL’S EQUAL ..........................46 MOROCCO BOUND ..................................................................................49 ASBEL KIPROP ........................................................................................52 JENNY SIMPSON .....................................................................................55 -

Men's 200M Final 23.08.2020
Men's 200m Final 23.08.2020 Start list 200m Time: 17:10 Records Lane Athlete Nat NR PB SB 1 Richard KILTY GBR 19.94 20.34 WR 19.19 Usain BOLT JAM Olympiastadion, Berlin 20.08.09 2 Mario BURKE BAR 19.97 20.08 20.78 AR 19.72 Pietro MENNEA ITA Ciudad de México 12.09.79 3 Felix SVENSSON SWE 20.30 20.73 20.80 NR 20.30 Johan WISSMAN SWE Stuttgart 23.09.07 WJR 19.93 Usain BOLT JAM Hamilton 11.04.04 4 Jan VELEBA CZE 20.46 20.64 20.64 MR 19.77 Michael JOHNSON USA 08.07.96 5 Silvan WICKI SUI 19.98 20.45 20.45 DLR 19.26 Yohan BLAKE JAM Boudewijnstadion, Bruxelles 16.09.11 6 Adam GEMILI GBR 19.94 19.97 20.56 SB 19.76 Noah LYLES USA Stade Louis II, Monaco 14.08.20 7 Bruno HORTELANO-ROIG ESP 20.04 20.04 8 Elijah HALL USA 19.32 20.11 20.69 2020 World Outdoor list 19.76 +0.7 Noah LYLES USA Stade Louis II, Monaco (MON) 14.08.20 19.80 +1.0 Kenneth BEDNAREK USA Montverde, FL (USA) 10.08.20 Medal Winners Stockholm previous 19.96 +1.0 Steven GARDINER BAH Clermont, FL (USA) 25.07.20 20.22 +0.8 Divine ODUDURU NGR Clermont, FL (USA) 25.07.20 2019 - IAAF World Ch. in Athletics Winners 20.23 +0.1 Clarence MUNYAI RSA Pretoria (RSA) 13.03.20 1. Noah LYLES (USA) 19.83 19 Aaron BROWN (CAN) 20.06 20.24 +0.8 André DE GRASSE CAN Clermont, FL (USA) 25.07.20 2. -
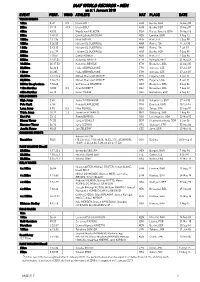
IAAF WORLD RECORDS - MEN As at 1 January 2018 EVENT PERF
IAAF WORLD RECORDS - MEN as at 1 January 2018 EVENT PERF. WIND ATHLETE NAT PLACE DATE TRACK EVENTS 100m 9.58 0.9 Usain BOLT JAM Berlin, GER 16 Aug 09 200m 19.19 -0.3 Usain BOLT JAM Berlin, GER 20 Aug 09 400m 43.03 Wayde van NIEKERK RSA Rio de Janeiro, BRA 14 Aug 16 800m 1:40.91 David Lekuta RUDISHA KEN London, GBR 9 Aug 12 1000m 2:11.96 Noah NGENY KEN Rieti, ITA 5 Sep 99 1500m 3:26.00 Hicham EL GUERROUJ MAR Roma, ITA 14 Jul 98 1 Mile 3:43.13 Hicham EL GUERROUJ MAR Roma, ITA 7 Jul 99 2000m 4:44.79 Hicham EL GUERROUJ MAR Berlin, GER 7 Sep 99 3000m 7:20.67 Daniel KOMEN KEN Rieti, ITA 1 Sep 96 5000m 12:37.35 Kenenisa BEKELE ETH Hengelo, NED 31 May 04 10,000m 26:17.53 Kenenisa BEKELE ETH Bruxelles, BEL 26 Aug 05 20,000m 56:26.0 Haile GEBRSELASSIE ETH Ostrava, CZE 27 Jun 07 1 Hour 21,285 Haile GEBRSELASSIE ETH Ostrava, CZE 27 Jun 07 25,000m 1:12:25.4 Moses Cheruiyot MOSOP KEN Eugene, USA 3 Jun 11 30,000m 1:26:47.4 Moses Cheruiyot MOSOP KEN Eugene, USA 3 Jun 11 3000m Steeplechase 7:53.63 Saif Saaeed SHAHEEN QAT Bruxelles, BEL 3 Sep 04 110m Hurdles 12.80 0.3 Aries MERRITT USA Bruxelles, BEL 7 Sep 12 400m Hurdles 46.78 Kevin YOUNG USA Barcelona, ESP 6 Aug 92 FIELD EVENTS High Jump 2.45 Javier SOTOMAYOR CUB Salamanca, ESP 27 Jul 93 Pole Vault 6.16i Renaud LAVILLENIE FRA Donetsk, UKR 15 Feb 14 Long Jump 8.95 0.3 Mike POWELL USA Tokyo, JPN 30 Aug 91 Triple Jump 18.29 1.3 Jonathan EDWARDS GBR Göteborg, SWE 7 Aug 95 Shot Put 23.12 Randy BARNES USA Los Angeles, USA 20 May 90 Discus Throw 74.08 Jürgen SCHULT GDR Neubrandenburg, GDR 6 Jun 86 Hammer Throw -

Press Release Chasing Time
Press release April 2014 Press preview 4 June 2014 Chasing time From 5 June 2014 to 18 January 20152015, The Olympic Museum in Lausanne is hosting a new exhibition entitled Chasing Time ,,, which takes the visitor on a journey through time, as it is experienced in sport, socially, technologically and artistically. It is no coincidence that the Olympic motto starts with “Faster”. Time is one of the essential elements for designating winners and losers and for establishing records. Time, in a sporting context, is measured and quantified, but it also incites enthusiasm and passion. The passage of time is inexorable, but this exhibition aims to show Man’s ingeniousness and the artistic creativity that can lead to the observation and study of time, be it in painting, sculpture, music or cinema. Through inventive scenography by Lorenzo GreppiGreppi, the visitor discovers a route organised around nine themed sectors, which clearly illustrate the changes and evolution of the perception of time throughout history. This scenography observes the evolution of the understanding of time, starting at the natural and cyclical notion of the Ancient Games, passing through the first stages of linear time and clock time, and ending at the production of highly specialised systems for measuring and recording time, thanks to the manufacture of high-precision instruments today. The information is punctuated with sociological and philosophical points of view. Quotes from athletes are presented alongside others from writers, while sporting activity, as it relates to Time, dialogues with the arts. The works on display include chronophotographic images by Marey; Pianola , a work by Mel Brimfield created in 2012 as a tribute to Roger Bannister’s record; and a metaphorical work by Michelangelo Pistoletto entitled The Etruscan on the past, present and future. -

Men's 100M Diamond Discipline - Heat 1 20.07.2019
Men's 100m Diamond Discipline - Heat 1 20.07.2019 Start list 100m Time: 14:35 Records Lane Athlete Nat NR PB SB 1 Julian FORTE JAM 9.58 9.91 10.17 WR 9.58 Usain BOLT JAM Berlin 16.08.09 2 Adam GEMILI GBR 9.87 9.97 10.11 AR 9.86 Francis OBIKWELU POR Athina 22.08.04 3 Yuki KOIKE JPN 9.97 10.04 10.04 =AR 9.86 Jimmy VICAUT FRA Paris 04.07.15 =AR 9.86 Jimmy VICAUT FRA Montreuil-sous-Bois 07.06.16 4 Arthur CISSÉ CIV 9.94 9.94 10.01 NR 9.87 Linford CHRISTIE GBR Stuttgart 15.08.93 5 Yohan BLAKE JAM 9.58 9.69 9.96 WJR 9.97 Trayvon BROMELL USA Eugene, OR 13.06.14 6 Akani SIMBINE RSA 9.89 9.89 9.95 MR 9.78 Tyson GAY USA 13.08.10 7 Andrew ROBERTSON GBR 9.87 10.10 10.17 DLR 9.69 Yohan BLAKE JAM Lausanne 23.08.12 8 Oliver BROMBY GBR 9.87 10.22 10.22 SB 9.81 Christian COLEMAN USA Palo Alto, CA 30.06.19 9 Ojie EDOBURUN GBR 9.87 10.04 10.17 2019 World Outdoor list 9.81 -0.1 Christian COLEMAN USA Palo Alto, CA 30.06.19 Medal Winners Road To The Final 9.86 +0.9 Noah LYLES USA Shanghai 18.05.19 1 Christian COLEMAN (USA) 23 9.86 +0.8 Divine ODUDURU NGR Austin, TX 07.06.19 2018 - Berlin European Ch. -

Key Caribbean Cases on Doping: Lessons Learned
KEY CARIBBEAN CASES ON DOPING: LESSONS LEARNED CANOC SPORTS LAW CONFERENCE 2019 ST. VINCENT & THE GRENADINES RE-TESTING – THE LIMITATION PERIOD Article 17 WADC No anti-doping rule violation proceeding may be commenced against an Athlete or other Person unless he or she has been notified of the anti- doping rule violation as provided in Article 7, or notification has been reasonably attempted, within ten years from the date the violation is asserted to have occurred. Nesta Carter v International Olympic Committee CAS 2017/A/49984 Carter won 4$100m gold, along with teammates Usain Bolt, Michael Frater and Asafa Powell, at 2008 Beijing Olympic Games competed Carter was tested then, but the results were negative. In 2016, a reanalysis of the Beijing samples was completed. an adverse analytical finding for the presence of methylhexaneamine (MHA) Carter was notified, but did not accept the Adverse Analytical Finding. The IOC Dispute Committee confirmed that Carter had committed an ADV. He was disqualified from the Men's 4*100 relay event He and teammates had their medalist pins and diplomas withdrawn and they had to be returned Carter appealed to the CAS: RE-TESTING – THE LIMITATION PERIOD Nesta Carter v International Olympic Committee CAS 2017/A/49984 Main issues: was there a delay in the re-analysis of the sample which would require the dismissal of these proceedings as being unfair to the Athlete in view of the specific circumstances of the case? is the establishment of an ADRV based on MHA in violation of the requirement of legal certainty, since MHA was not a listed substance in 2008? RE-TESTING – THE LIMITATION PERIOD Nesta Carter v International Olympic Committee CAS 2017/A/49984 Article 6.5 IOC ADR: "the ownership of the samples is vested in the IOC for the eight years. -

Press Release IAAF/BTC World Relays 2017 Team- JAMAICA
Press Release IAAF/BTC World Relays 2017 Team- JAMAICA Females Males Gayon Evans Kemar Bailey-Cole Simone Facey Yohan Blake Sashalee Forbes Everton Clarke Natasha Morrison Jevaughn Minzie Elaine Thompson Nickel Ashmeade Christania Williams Oshane Bailey Anastacia Le-Roy Rasheed Dwyer Jura Levy Nigel Ellis Dawnalee Loney Chadic Hinds Audra Segree Warren Weir Verone Chambers Javere Bell Christine Day Javon Francis Shericka Jackson Demish Gaye Anneisha McLaughlin-Whilby Steven Gayle Stephenie Ann McPherson Peter Matthews Janieve Russell Rusheen McDonald Natoya Goule Jaheel Hyde Tiffany James Martin Manley Ristananna Tracey Jamari Rose Manager : Marie Tavares Team Doctor: Dr. Paul Auden Asst. Manager: Alan Beckford Team will compete in : Technical Director : Maurice Wilson Masseurs: 4x100m Women & Men Coaches Nathaniel Davis 4x200m Women & Men Paul Francis Shaun Kettle 4x400m Women & Men Jerry Holness Okeile Stewart 4x400m Mixed Relays Michael Clarke Collin Turner Reynaldo Walcott Patrick Dawson Regards, Garth Gayle – Honorary Secretary DIRECTORS: Dr. Warren Blake (President); Ian Forbes (1st Vice President); Lincoln Eatmon (2nd Vice President); Michael Frater, OD (3rd Vice President); Vilma Charlton, OD (4th Vice President); 1111111111111 Garth Gayle (Honorary Secretary); Marie Tavares (Assistant Secretary); Ludlow Watts (Honorary Treasurer); Leroy Cooke (Director of Records) EXECUTIVE COMMITTEE: Maxine Brown; Dr. Carl Bruce: Michael Clarke; Trevor Campbell; George Forbes; Gregory Hamilton; Julette Parkes-Livermore; Ewan Scott Affiliated to the: IAAF; JOA; NACAC; CACAC . -

IAAF World Relays Facts and Figures
IAAF/BTC WORLD RELAYS FACTS & FIGURES IAAF/BTC World Relays .........................................................................................1 Multiple Wins ..........................................................................................................3 IAAF World Championship Medallists and Olympic top three ...............................5 World All-Time Top 10 Lists....................................................................................8 World and Continental Records............................................................................11 The Fastest-Ever 4x400m Relay splits ................................................................15 National Records..................................................................................................17 NASSAU 2017 ★ IAAF WORLD RELAYS 1 IAAF/BTC WORLD RELAYS Venues - 2014: Nassau (24/25 May); 2015 Nassau (2/3 May); 2017 Nassau (22/23 Apr) Year Stadium Countries Athletes Men Women 2014 Thomas A. Robinson Stadium 41 470 276 194 2015 Thomas A. Robinson Stadium 42 584 329 255 MEETING RECORDS (Teams & splits given on later pages) MEN 4 x 100 Metres Relay 37.38 United States Nassau 2 May 15 4 x 200 Metres Relay 1:18.63 Jamaica Nassau 24 May 14 4 x 400 Metres Relay 2:57.25 United States Nassau 25 May 14 4 x 800 Metres Relay 7:04.84 United States Nassau 2 May 15 Distance Medley Relay 9:15.50 United States Nassau 3 May 15 4 x 1500 Metres Relay 14:22.22 Kenya Nassau 25 May 14 WOMEN 4 x 100 Metres Relay 41.88 United States Nassau 24 May 14 4 x 200 Metres Relay -

Senior Males 2015 Top Performances As of October 16
2015 Top Performances as of October 16 Senior Males Rank Mark Wind Athlete NAT DOB Venue Date 100 M 1 9.74 0.9 Justin Gatlin USA 10-Feb-82 Diamond Doha 15-May 2 9.79 -0.5 Usain Bolt 21-Aug-86 WC Beijing 23-Aug 3 9.81 1.3 Asafa Powell 23-Nov-82 Areva Saint-Denis 04-Jul 9 9.91 0.9 Nickel Ashmeade 07-Apr-90 NC Kingston 26-Jun 11 9.92 -0.8 Kemar Bailey-Cole 10-Jan-92 Sainsbury's London 24-Jul 16 9.94 1.4 Andrew Fisher 15-Dec-91 Madrid 11-Jul 23 9.98 1.8 Nesta Carter 11-Oct-85 Jam Inv Kingston 09-May 33 10.03 0.9 Senoj Givans 30-Dec-93 NCAA Eugene OR 10-Jun 44 10.06 1.9 Julian Forte 01-Jul-93 Sainsbury's Birmingham 07-Jun 44 10.06 1.0 Jason Livermore 25-Apr-88 NC Kingston 25-Jun 49 10.07A 1.9 Sheldon Mitchell 19-Jul-90 NACAC San José 07-Aug 65 10.11 0.3 Kemarley Brown 20-Jul-92 Classic Kingston 11-Apr 70 10.12 1.4 Yohan Blake 26-Dec-89 MortonG Dublin 24-Jul 77 10.13 1.5 Taffawee Johnson 10-Mar-88 Last Chance Greensboro NC 17-May 81 10.14 0.8 Tyquendo Tracey 10-Jun-93 NC Kingston 25-Jun 81 10.14 1.0 Michael Frater 06-Oct-82 NC Kingston 25-Jun 200 M 1 19.55 -0.1 Usain Bolt 21-Aug-86 WC Beijing 27-Aug 3 19.80 2.0 Rasheed Dwyer 29-Jan-89 PAG Toronto 23-Jul 17 20.04 1.1 Julian Forte 01-Jul-93 NC Kingston 27-Jun 29 20.18 0.9 Nickel Ashmeade 07-Apr-90 Pre Eugene OR 30-May 38 20.24 -0.1 Warren Weir 31-Oct-89 WC Beijing 25-Aug 60 20.39 1.6 Tyquendo Tracey 10-Jun-93 NC Kingston 27-Jun 88 20.47 2.0 Senoj Givans 30-Dec-93 NCAA Eugene OR 10-Jun 97 20.51 0.3 Jermaine Brown 04-Jul-91 MSR Walnut CA 18-Apr 107 20.54 0.0 Jason Livermore 25-Apr-88 Cayman Inv