Classification of Arabic News Texts with Fasttext Method
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Automatic Correction of Real-Word Errors in Spanish Clinical Texts
sensors Article Automatic Correction of Real-Word Errors in Spanish Clinical Texts Daniel Bravo-Candel 1,Jésica López-Hernández 1, José Antonio García-Díaz 1 , Fernando Molina-Molina 2 and Francisco García-Sánchez 1,* 1 Department of Informatics and Systems, Faculty of Computer Science, Campus de Espinardo, University of Murcia, 30100 Murcia, Spain; [email protected] (D.B.-C.); [email protected] (J.L.-H.); [email protected] (J.A.G.-D.) 2 VÓCALI Sistemas Inteligentes S.L., 30100 Murcia, Spain; [email protected] * Correspondence: [email protected]; Tel.: +34-86888-8107 Abstract: Real-word errors are characterized by being actual terms in the dictionary. By providing context, real-word errors are detected. Traditional methods to detect and correct such errors are mostly based on counting the frequency of short word sequences in a corpus. Then, the probability of a word being a real-word error is computed. On the other hand, state-of-the-art approaches make use of deep learning models to learn context by extracting semantic features from text. In this work, a deep learning model were implemented for correcting real-word errors in clinical text. Specifically, a Seq2seq Neural Machine Translation Model mapped erroneous sentences to correct them. For that, different types of error were generated in correct sentences by using rules. Different Seq2seq models were trained and evaluated on two corpora: the Wikicorpus and a collection of three clinical datasets. The medicine corpus was much smaller than the Wikicorpus due to privacy issues when dealing Citation: Bravo-Candel, D.; López-Hernández, J.; García-Díaz, with patient information. -
A Comprehensive Embedding Approach for Determining Repository Similarity
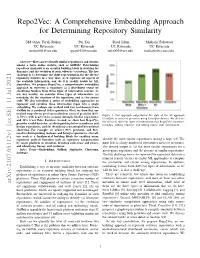
Repo2Vec: A Comprehensive Embedding Approach for Determining Repository Similarity Md Omar Faruk Rokon Pei Yan Risul Islam Michalis Faloutsos UC Riverside UC Riverside UC Riverside UC Riverside [email protected] [email protected] [email protected] [email protected] Abstract—How can we identify similar repositories and clusters among a large online archive, such as GitHub? Determining repository similarity is an essential building block in studying the dynamics and the evolution of such software ecosystems. The key challenge is to determine the right representation for the diverse repository features in a way that: (a) it captures all aspects of the available information, and (b) it is readily usable by ML algorithms. We propose Repo2Vec, a comprehensive embedding approach to represent a repository as a distributed vector by combining features from three types of information sources. As our key novelty, we consider three types of information: (a) metadata, (b) the structure of the repository, and (c) the source code. We also introduce a series of embedding approaches to represent and combine these information types into a single embedding. We evaluate our method with two real datasets from GitHub for a combined 1013 repositories. First, we show that our method outperforms previous methods in terms of precision (93% Figure 1: Our approach outperforms the state of the art approach vs 78%), with nearly twice as many Strongly Similar repositories CrossSim in terms of precision using CrossSim dataset. We also see and 30% fewer False Positives. Second, we show how Repo2Vec the effect of different types of information that Repo2Vec considers: provides a solid basis for: (a) distinguishing between malware and metadata, adding structure, and adding source code information. -

ACL 2019 Social Media Mining for Health Applications (#SMM4H)
ACL 2019 Social Media Mining for Health Applications (#SMM4H) Workshop & Shared Task Proceedings of the Fourth Workshop August 2, 2019 Florence, Italy c 2019 The Association for Computational Linguistics Order copies of this and other ACL proceedings from: Association for Computational Linguistics (ACL) 209 N. Eighth Street Stroudsburg, PA 18360 USA Tel: +1-570-476-8006 Fax: +1-570-476-0860 [email protected] ISBN 978-1-950737-46-8 ii Preface Welcome to the 4th Social Media Mining for Health Applications Workshop and Shared Task - #SMM4H 2019. The total number of users of social media continues to grow worldwide, resulting in the generation of vast amounts of data. Popular social networking sites such as Facebook, Twitter and Instagram dominate this sphere. According to estimates, 500 million tweets and 4.3 billion Facebook messages are posted every day 1. The latest Pew Research Report 2, nearly half of adults worldwide and two- thirds of all American adults (65%) use social networking. The report states that of the total users, 26% have discussed health information, and, of those, 30% changed behavior based on this information and 42% discussed current medical conditions. Advances in automated data processing, machine learning and NLP present the possibility of utilizing this massive data source for biomedical and public health applications, if researchers address the methodological challenges unique to this media. In its fourth iteration, the #SMM4H workshop takes place in Florence, Italy, on August 2, 2019, and is co-located with the -

Mapping the Hyponymy Relation of Wordnet Onto
Under review as a conference paper at ICLR 2019 MAPPING THE HYPONYMY RELATION OF WORDNET ONTO VECTOR SPACES Anonymous authors Paper under double-blind review ABSTRACT In this paper, we investigate mapping the hyponymy relation of WORDNET to feature vectors. We aim to model lexical knowledge in such a way that it can be used as input in generic machine-learning models, such as phrase entailment predictors. We propose two models. The first one leverages an existing mapping of words to feature vectors (fastText), and attempts to classify such vectors as within or outside of each class. The second model is fully supervised, using solely WORDNET as a ground truth. It maps each concept to an interval or a disjunction thereof. On the first model, we approach, but not quite attain state of the art performance. The second model can achieve near-perfect accuracy. 1 INTRODUCTION Distributional encoding of word meanings from the large corpora (Mikolov et al., 2013; 2018; Pen- nington et al., 2014) have been found to be useful for a number of NLP tasks. These approaches are based on a probabilistic language model by Bengio et al. (2003) of word sequences, where each word w is represented as a feature vector f(w) (a compact representation of a word, as a vector of floating point values). This means that one learns word representations (vectors) and probabilities of word sequences at the same time. While the major goal of distributional approaches is to identify distributional patterns of words and word sequences, they have even found use in tasks that require modeling more fine-grained relations between words than co-occurrence in word sequences. -

Pairwise Fasttext Classifier for Entity Disambiguation
Pairwise FastText Classifier for Entity Disambiguation a,b b b Cheng Yu , Bing Chu , Rohit Ram , James Aichingerb, Lizhen Qub,c, Hanna Suominenb,c a Project Cleopatra, Canberra, Australia b The Australian National University c DATA 61, Australia [email protected] {u5470909,u5568718,u5016706, Hanna.Suominen}@anu.edu.au [email protected] deterministically. Then we will evaluate PFC’s Abstract performance against a few baseline methods, in- cluding SVC3 with hand-crafted text features. Fi- For the Australasian Language Technology nally, we will discuss ways to improve disambig- Association (ALTA) 2016 Shared Task, we uation performance using PFC. devised Pairwise FastText Classifier (PFC), an efficient embedding-based text classifier, 2 Pairwise Fast-Text Classifier (PFC) and used it for entity disambiguation. Com- pared with a few baseline algorithms, PFC Our Pairwise FastText Classifier is inspired by achieved a higher F1 score at 0.72 (under the the FastText. Thus this section starts with a brief team name BCJR). To generalise the model, description of FastText, and proceeds to demon- we also created a method to bootstrap the strate PFC. training set deterministically without human labelling and at no financial cost. By releasing 2.1 FastText PFC and the dataset augmentation software to the public1, we hope to invite more collabora- FastText maps each vocabulary to a real-valued tion. vector, with unknown words having a special vo- cabulary ID. A document can be represented as 1 Introduction the average of all these vectors. Then FastText will train a maximum entropy multi-class classi- The goal of the ALTA 2016 Shared Task was to fier on the vectors and the output labels. -

Fasttext.Zip: Compressing Text Classification Models
Under review as a conference paper at ICLR 2017 FASTTEXT.ZIP: COMPRESSING TEXT CLASSIFICATION MODELS Armand Joulin, Edouard Grave, Piotr Bojanowski, Matthijs Douze, Herve´ Jegou´ & Tomas Mikolov Facebook AI Research fajoulin,egrave,bojanowski,matthijs,rvj,[email protected] ABSTRACT We consider the problem of producing compact architectures for text classifica- tion, such that the full model fits in a limited amount of memory. After consid- ering different solutions inspired by the hashing literature, we propose a method built upon product quantization to store word embeddings. While the original technique leads to a loss in accuracy, we adapt this method to circumvent quan- tization artefacts. Combined with simple approaches specifically adapted to text classification, our approach derived from fastText requires, at test time, only a fraction of the memory compared to the original FastText, without noticeably sacrificing quality in terms of classification accuracy. Our experiments carried out on several benchmarks show that our approach typically requires two orders of magnitude less memory than fastText while being only slightly inferior with respect to accuracy. As a result, it outperforms the state of the art by a good margin in terms of the compromise between memory usage and accuracy. 1 INTRODUCTION Text classification is an important problem in Natural Language Processing (NLP). Real world use- cases include spam filtering or e-mail categorization. It is a core component in more complex sys- tems such as search and ranking. Recently, deep learning techniques based on neural networks have achieved state of the art results in various NLP applications. One of the main successes of deep learning is due to the effectiveness of recurrent networks for language modeling and their application to speech recognition and machine translation (Mikolov, 2012). -

Question Embeddings for Semantic Answer Type Prediction
Question Embeddings for Semantic Answer Type Prediction Eleanor Bill1 and Ernesto Jiménez-Ruiz2 1, 2 City, University of London, London, EC1V 0HB Abstract. This paper considers an answer type and category prediction challenge for a set of natural language questions, and proposes a question answering clas- sification system based on word and DBpedia knowledge graph embeddings. The questions are parsed for keywords, nouns and noun phrases before word and knowledge graph embeddings are applied to the parts of the question. The vectors produced are used to train multiple multi-layer perceptron models, one for each answer type in a multiclass one-vs-all classification system for both answer cat- egory prediction and answer type prediction. Different combinations of vectors and the effect of creating additional positive and negative training samples are evaluated in order to find the best classification system. The classification system that predict the answer category with highest accuracy are the classifiers trained on knowledge graph embedded noun phrases vectors from the original training data, with an accuracy of 0.793. The vector combination that produces the highest NDCG values for answer category accuracy is the word embeddings from the parsed question keyword and nouns parsed from the original training data, with NDCG@5 and NDCG@10 values of 0.471 and 0.440 respectively for the top five and ten predicted answer types. Keywords: Semantic Web, knowledge graph embedding, answer type predic- tion, question answering. 1 Introduction 1.1 The SMART challenge The challenge [1] provided a training set of natural language questions alongside a sin- gle given answer category (Boolean, literal or resource) and 1-6 given answer types. -

Practice with Python
CSI4108-01 ARTIFICIAL INTELLIGENCE 1 Word Embedding / Text Processing Practice with Python 2018. 5. 11. Lee, Gyeongbok Practice with Python 2 Contents • Word Embedding – Libraries: gensim, fastText – Embedding alignment (with two languages) • Text/Language Processing – POS Tagging with NLTK/koNLPy – Text similarity (jellyfish) Practice with Python 3 Gensim • Open-source vector space modeling and topic modeling toolkit implemented in Python – designed to handle large text collections, using data streaming and efficient incremental algorithms – Usually used to make word vector from corpus • Tutorial is available here: – https://github.com/RaRe-Technologies/gensim/blob/develop/tutorials.md#tutorials – https://rare-technologies.com/word2vec-tutorial/ • Install – pip install gensim Practice with Python 4 Gensim for Word Embedding • Logging • Input Data: list of word’s list – Example: I have a car , I like the cat → – For list of the sentences, you can make this by: Practice with Python 5 Gensim for Word Embedding • If your data is already preprocessed… – One sentence per line, separated by whitespace → LineSentence (just load the file) – Try with this: • http://an.yonsei.ac.kr/corpus/example_corpus.txt From https://radimrehurek.com/gensim/models/word2vec.html Practice with Python 6 Gensim for Word Embedding • If the input is in multiple files or file size is large: – Use custom iterator and yield From https://rare-technologies.com/word2vec-tutorial/ Practice with Python 7 Gensim for Word Embedding • gensim.models.Word2Vec Parameters – min_count: -

Data Driven Value Creation
DATA DRIVEN VALUE CREATION DATA SCIENCE & ANALYTICS | DATA MANAGEMENT | VISUALIZATION & DATA EXPERIENCE D ONE, Sihlfeldstrasse 58, 8003 Zürich, d-one.ai Agenda Time Content Who 9.00 Introduction Philipp 9.30 Hands-On 1: How to kick-start NLP Jacqueline 10.15 Break / Letting People Catch up All ;-) 10.45 About ELK Philipp 11.00 Hands-On 2: Deep Dive Jacqueline 12.15 Wrap up / Discussion All 2 Today’s hosts Philipp Thomann Jacqueline Stählin Here today & tomorrow morning Here today & Monday till Wednesday 3 Setup Course Git - https://github.com/d-one/NLPeasy-workshop For infos during Workshop - https://tlk.io/amld2020-nlpeasy 4 «Making sense of data is the winning competence in all industries.» 5 Data drives Transformation 6 About ■ Zurich-based, established in 2005 with focus: data-driven value creation ■ 50 data professionals with excellent business and technical understanding & network ■ International & Swiss clients ■ In selected cases: investor for data-driven start-ups 7 Capabilities Business Consulting - Guide on data journey - Use cases, roadmap - Transformation and change - Building capabilities Machine Learning / AI Data Architecture - Ideation, implementation, - Data strategy operationalization Passionate - Enterprise requirements - Algorithms, modelling, NLP & - Information factory - Image recognition, visual analytics Down to - BI and analytics - Text analytics - Data science laboratory earth Data Management Data Experience - Data supply chain - From data to Insights to action - Data integration and modelling - Business report -

Two Models for Named Entity Recognition in Spanish
Two Models for Named Entity Recognition in Spanish. Submission to the CAPITEL Shared Task at IberLEF 2020 Elena Álvarez-Melladoa aInformation Sciences Institute, University of Southern California Abstract This paper documents two sequence-labeling models for NER in Spanish: a conditional random field model with handcrafted features and a BiLSTM-CRF model with word and character embeddings. Both models were trained and tested using CAPITEL (an annotated corpus of newswire written in European Spanish) and were submitted to the shared task on Spanish NER at IberLEF 2020. The best result was obtained by the CRF model, which produced an F1 score of 84.39 on the test set and was ranked #6 on the shared task. Keywords Spanish NER, CRF, BiLSTM-CRF 1. Introduction and Previous Work Named entity recognition (NER) is the task of extracting relevant spans of text (such as person names, location names, organization names) from a given document. NER has usually been framed as a sequence labeling problem [1]. Consequently, different sequence labeling approaches have been applied to NER, such as hidden Markov models [2], maxent Markov models [3] or conditional random field [4, 5]. More recently, different neural architectures have also been applied to NER [6, 7]. In this paper, we explore two sequence-labeling models to perform NER on CAPITEL, an annotated corpus of journalistic texts written in European Spanish. The explored models are a CRF model with handcrafted features and a BiLSTM-CRF model with word and character embeddings. Both models were submitted to the CAPITEL shared task on Spanish NER at IberLEF 2020 [8]. -

Learning Word Vectors for 157 Languages
Learning Word Vectors for 157 Languages Edouard Grave1;∗ Piotr Bojanowski1;∗ Prakhar Gupta1;2 Armand Joulin1 Tomas Mikolov1 1Facebook AI Research 2EPFL fegrave,bojanowski,ajoulin,[email protected], [email protected] Abstract Distributed word representations, or word vectors, have recently been applied to many tasks in natural language processing, leading to state-of-the-art performance. A key ingredient to the successful application of these representations is to train them on very large corpora, and use these pre-trained models in downstream tasks. In this paper, we describe how we trained such high quality word representations for 157 languages. We used two sources of data to train these models: the free online encyclopedia Wikipedia and data from the common crawl project. We also introduce three new word analogy datasets to evaluate these word vectors, for French, Hindi and Polish. Finally, we evaluate our pre-trained word vectors on 10 languages for which evaluation datasets exists, showing very strong performance compared to previous models. Keywords: word vectors, word analogies, fasttext 1. Introduction are available at https://fasttext.cc. Distributed word representations, also known as word vec- Related work. In previous work, word vectors pre- tors, have been widely used in natural language processing, trained on large text corpora have been released along- leading to state of the art results for many tasks. Publicly side open source implementation of word embedding mod- available models, which are pre-trained on large amounts els. English word vectors trained on a part of the of data, have become a standard tool for many NLP appli- Google News dataset (100B tokens) were published with cations, but are mostly available for English. -

Developing Amaia: a Conversational Agent for Helping Portuguese Entrepreneurs—An Extensive Exploration of Question-Matching Approaches for Portuguese
information Article Developing Amaia: A Conversational Agent for Helping Portuguese Entrepreneurs—An Extensive Exploration of Question-Matching Approaches for Portuguese José Santos 1 , Luís Duarte 1 , João Ferreira 1 , Ana Alves 1,2 and Hugo Gonçalo Oliveira 1,* 1 CISUC, DEI, University of Coimbra, 3030-290 Coimbra, Portugal; [email protected] (J.S.); [email protected] (L.D.); [email protected] (J.F.); [email protected] (A.A.) 2 Instituto Superior de Engenharia de Coimbra (ISEC), Instituto Politécnico de Coimbra, 3030-199 Coimbra, Portugal * Correspondence: [email protected] Received: 31 July 2020; Accepted: 28 August 2020; Published: 1 September 2020 Abstract: This paper describes how we tackled the development of Amaia, a conversational agent for Portuguese entrepreneurs. After introducing the domain corpus used as Amaia’s Knowledge Base (KB), we make an extensive comparison of approaches for automatically matching user requests with Frequently Asked Questions (FAQs) in the KB, covering Information Retrieval (IR), approaches based on static and contextual word embeddings, and a model of Semantic Textual Similarity (STS) trained for Portuguese, which achieved the best performance. We further describe how we decreased the model’s complexity and improved scalability, with minimal impact on performance. In the end, Amaia combines an IR library and an STS model with reduced features. Towards a more human-like behavior, Amaia can also answer out-of-domain questions, based on a second corpus integrated in the KB. Such interactions are identified with a text classifier, also described in the paper. Keywords: semantic textual similarity; question answering; conversational agents; machine learning; information retrieval; text classification 1.