Hadoop Mapreduce V2 Cookbook
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Installation Guide
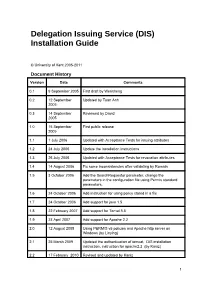
Delegation Issuing Service (DIS) Installation Guide © University of Kent 2005-2011 Document History Version Date Comments 0.1 9 September 2005 First draft by Wensheng 0.2 12 September Updated by Tuan Anh 2005 0.3 14 September Reviewed by David 2005 1.0 15 September First public release 2005 1.1 1 July 2006 Updated with Acceptance Tests for issuing attributes 1.2 24 July 2006 Update the installation instructions 1.3 26 July 2006 Updated with Acceptance Tests for revocation attributes 1.4 14 August 2006 Fix some inconsistencies after validating by Romain 1.5 3 October 2006 Add the SearchRequestor parameter, change the parameters in the configuration file using Permis standard parameters. 1.6 24 October 2006 Add instruction for using policy stored in a file 1.7 24 October 2006 Add support for java 1.5 1.8 22 February 2007 Add support for Tomat 5.5 1.9 23 April 2007 Add support for Apache 2.2 2.0 12 August 2008 Using PERMIS v5 policies and Apache http server on Windows (by Linying) 2.1 25 March 2009 Updated the authentication of tomcat, DIS installation instruction, instruction for apache2.2 (by Kaniz) 2.2 17 February 2010 Revised and updated by Kaniz 1 2.3 16 April 2010 Updated by Mark 2.5 26 October 2010 Install guide rewritten and separated into its own document 2.5.2 2 November 2010 Java installation explained more fully. Tomcat native library installation corrected. Default DIS configuration file inserted. 2.5.4 5 November 2010 Addressed feedback from Kaniz 2.5.5 26 May 2011 Added alternative <FilesMatch> for PHP files. -

Tutorial on Web Services
Tutorial on Web Services HY559 Infrastructure Technologies for Large- Scale Service-Oriented Systems Jason Polakis [email protected] Required Software •Eclipse IDE for Java developers EE http://www.eclipse.org/downloads/ •Netbeans IDE http://netbeans.org/downloads/ •Apache Tomcat http://tomcat.apache.org/ •Apache AXIS2 http://axis.apache.org/axis2/java/core/download.cgi •Apache JUDDI http://juddi.apache.org/releases.html Getting Software • Either directly from given links, or: • In Ubuntu (as root) • To search for software – apt -cache search <program name> – Returns list of <packages> with short description • To install software – apt-get install <package> – Installs software, as well as dependencies Web Services “Any piece of software that makes itself available over the Internet and uses a standardized XML messaging system” •Extremely available •Language and platform independent •Distributed application components •Discoverable via a simple find mechanism •Components of Web Services – SOAP (Simple Object Access Protocol) – WSDL (Web Services Description Language) – UDDI (Universal Description, Discovery and Integration) Web Service Architecture •Web Service Protocol Stack –Service transport (transport messages between applications) •HTTP, SMTP, FTP –XML messaging (encode messages in common XML format ) • XML-RPC, WS-Addressing, and SOAP –Service description (describe public interface of service) –Service discovery (centralize services into common registry) •Programming models: –REST-based web services –SOAP-based web services SOAP-based Services •Use SOAP –protocol for exchanging structured information •Use WSDL –xml-based language for describing Web services •WSDL file –created based on the JAVA code in the service –exposed on the net •To use service, must create a client –based on WSDL info •Messages exchanged in SOAP •Java API for XML Web Services (JAX-WS) model also used for SOAP services. -

Neon Core Infrastructure Services
NeOn-project.org NeOn: Lifecycle Support for Networked Ontologies Integrated Project (IST-2005-027595) Priority: IST-2004-2.4.7 – “Semantic-based knowledge and content systems” D6.4.2 NeOn core infrastructure services Deliverable Co-ordinator: Walter Waterfeld Deliverable Co-ordinating Institution: Software AG (SAG) Other Authors: Diana Maynard, University of Sheffield (USFD), Ian Roberts, University of Sheffield (USFD), Michael Gesmann, Software AG (SAG) Document Identifier: NEON/2010/D6.4.2/v1.0 Date due: October 31st, 2009 Class Deliverable: NEON EU-IST-2005-027595 Submission date: January 31st , 2010 Project start date: March 1, 2006 Version: v1.0 Project duration: 4 years State: Final Distribution: Public 2006–2010 © Copyright lies with the respective authors and their institutions. Page 2 of 25 NeOn Integrated Project EU-IST-027595 NeOn Consortium This document is a part of the NeOn research project funded by the IST Programme of the Commission of the European Communities by the grant number IST-2005-027595. The following partners are involved in the project: Open University (OU) – Coordinator Universität Karlsruhe – TH (UKARL) Knowledge Media Institute – KMi Institut für Angewandte Informatik und Formale Berrill Building, Walton Hall Beschreibungsverfahren – AIFB Milton Keynes, MK7 6AA Englerstrasse 11 United Kingdom D-76128 Karlsruhe, Germany Contact person: Enrico Motta Contact person: Andreas Harth E-mail address: [email protected] E-mail address: [email protected] Universidad Politécnica de Madrid (UPM) Software AG (SAG) Campus de Montegancedo Uhlandstrasse 12 28660 Boadilla del Monte 64297 Darmstadt Spain Germany Contact person: Asunción Gómez Pérez Contact person: Walter Waterfeld E-mail address: [email protected] E-mail address: [email protected] Intelligent Software Components S.A. -

Apache AXIS2 Release Notes
AXIS2 for OpenVMS I64 July 2017 1. Introduction Apache AXIS2 for OpenVMS is the core engine for web services. It is a complete redesign and rewrite of the previously used Apache AXIS SOAP stack. This release of AXIS2 for OpenVMS is based on the latest 1.7.3 release from the Apache Software Foundation, and includes various new features and bug fixes. The release also provides a prebuilt Java servlet, which can be deployed within an application server such as Tomcat. Users are strongly encouraged to upgrade to 1.7-3 to take advantage of these improvements. This OpenVMS port of AXIS2 includes all Apache AXIS2 functionality provided by the Open Source 1.7.3 release. 2. Acknowledgements VMS Software Inc. would like to acknowledge the work of the Apache AXIS2 development team for their ongoing efforts in developing and supporting this software. 3. What’s new in this release AXIS2 Version 1.7-3 for OpenVMS is based on Apache AXIS2 1.7.3, and includes the following changes: Apache Axis2 1.7.3 is a security release that contains a fix for CVE-2010-3981. That security vulnerability affects the admin console that is part of the Axis2 Web application. The admin console now has a CSRF prevention mechanism and all known XSS vulnerabilities as well as two non-security bugs in the admin console (AXIS2-4764 and AXIS2-5716) have been fixed. Users of the AXIS2 WAR distribution are encouraged to upgrade to 1.7.3 to take advantage of these improvements. This release also fixes a regression in the HTTP client code that is triggered by the presence of certain types of cookies in HTTP responses (see AXIS2-5772). -

Web Services Enabled Openoffice.Org
Axis2UNO: Web Services Enabled Openoffice.org B.A.N.M. Bambarasinghe, H.M.S. Huruggamuwa, R.G. Ragel and S. Radhakrishnan Department of Computer Engineering, Faculty of Engineering, University of Peradeniya CP 20400 Sri Lanka. [email protected], [email protected], [email protected], [email protected] Abstract— Openoffice.org is a popular, free and open source So opening of doors and windows for web services in office product. This product is used by millions of people and Openoffice.org is going to expose a completely new world of developed, maintained and extended by thousands of developers information easily available and accessible in the office worldwide. Playing a dominant role in the web, web services environment. However implementing a whole set of technology is serving millions of people every day. Axis2 is one of functionalities needed in accessing web services is really a the most popular, free and open source web service engines. The framework presented in this paper, Axis2UNO, a combination of waste as there are already implemented open source web such two technologies is capable of making a new era in office service engines that could be utilized on this endeavour. The environment. Two other attempts to enhance web services role of a web service engine is to accept requests and related functionality in office products are Excel Web Services and UNO parameters to web services, executing the web service and Web Service Proxy. Excel Web Services is combined with Microsoft finally forwarding the outcome to the requesting program. In SharePoint technology and exposes information sharing in a addition to this, web service engines will also provide some different perspective within the proprietary Microsoft office services on security, data formatting, etc. -

Full-Graph-Limited-Mvn-Deps.Pdf
org.jboss.cl.jboss-cl-2.0.9.GA org.jboss.cl.jboss-cl-parent-2.2.1.GA org.jboss.cl.jboss-classloader-N/A org.jboss.cl.jboss-classloading-vfs-N/A org.jboss.cl.jboss-classloading-N/A org.primefaces.extensions.master-pom-1.0.0 org.sonatype.mercury.mercury-mp3-1.0-alpha-1 org.primefaces.themes.overcast-${primefaces.theme.version} org.primefaces.themes.dark-hive-${primefaces.theme.version}org.primefaces.themes.humanity-${primefaces.theme.version}org.primefaces.themes.le-frog-${primefaces.theme.version} org.primefaces.themes.south-street-${primefaces.theme.version}org.primefaces.themes.sunny-${primefaces.theme.version}org.primefaces.themes.hot-sneaks-${primefaces.theme.version}org.primefaces.themes.cupertino-${primefaces.theme.version} org.primefaces.themes.trontastic-${primefaces.theme.version}org.primefaces.themes.excite-bike-${primefaces.theme.version} org.apache.maven.mercury.mercury-external-N/A org.primefaces.themes.redmond-${primefaces.theme.version}org.primefaces.themes.afterwork-${primefaces.theme.version}org.primefaces.themes.glass-x-${primefaces.theme.version}org.primefaces.themes.home-${primefaces.theme.version} org.primefaces.themes.black-tie-${primefaces.theme.version}org.primefaces.themes.eggplant-${primefaces.theme.version} org.apache.maven.mercury.mercury-repo-remote-m2-N/Aorg.apache.maven.mercury.mercury-md-sat-N/A org.primefaces.themes.ui-lightness-${primefaces.theme.version}org.primefaces.themes.midnight-${primefaces.theme.version}org.primefaces.themes.mint-choc-${primefaces.theme.version}org.primefaces.themes.afternoon-${primefaces.theme.version}org.primefaces.themes.dot-luv-${primefaces.theme.version}org.primefaces.themes.smoothness-${primefaces.theme.version}org.primefaces.themes.swanky-purse-${primefaces.theme.version} -

Ontology Management (ONT) Cell
Informatics for Integrating Biology and the Bedside i2b2 Installation Guide Ontology Management (ONT) Cell Document Version: 1.4.2 I2b2 Software Version: 1.4 Table of Contents About this Guide______________________________________________________________ 3 1. Prerequisites _____________________________________________________________ 4 1.1 Required Software __________________________________________________________ 4 1.1.1 Java JDK_________________________________________________________________________4 1.1.2 JBoss 4.2.2GA ____________________________________________________________________4 1.1.3 Apache Ant 1.6.5 __________________________________________________________________5 1.1.4 Apache Axis2 1.1 __________________________________________________________________5 1.1.5 Oracle Express Edition ______________________________________________________________5 1.1.6 Update Environment Variables________________________________________________________6 1.1.7 Data Installation or Upgrade__________________________________________________________6 2. Install __________________________________________________________________ 7 2.1 Installing the Ontology Management (ONT) Cell _________________________________ 7 2.1.1 Download and Extract Source Code____________________________________________________7 2.1.2 Stop Services _____________________________________________________________________7 2.1.2.1 JBoss _______________________________________________________________________7 2.1.3 Deploy edu.harvard.i2b2.common _____________________________________________________7 -

Servicio Web De Identificación Y Clasificación De Entidades Nombradas
UNIVERSIDAD CARLOS III DE MADRID ESCUELA POLITÉCNICA SUPERIOR PROYECTO FIN DE CARRERA SERVICIO WEB DE IDENTIFICACIÓN Y CLASIFICACIÓN DE ENTIDADES NOMBRADAS INGENIERÍA TÉCNICA EN INFORMÁTICA DE GESTIÓN AUTOR: Ana Belén Megías Sánchez. TUTOR: Paloma Martínez Fernández. 2 INDICE Capítulo 1. Introducción .......................................................................... 11 1.1. Motivación. ............................................................................................................... 11 1.2. Objetivos. ................................................................................................................. 12 1.3. Estructura de la memoria. ....................................................................................... 13 Capítulo 2. Estado de la cuestión ............................................................. 14 2.1 Introducción ............................................................................................................. 14 2.2 Técnicas de extracción de entidades . ..................................................................... 15 2.2.1. Sistemas basados en reglas (Handcrafted). .................................................. 17 2.2.2. Sistemas basados en aprendizaje automático. ............................................. 17 2.2.3. Sistemas Híbridos.......................................................................................... 22 Capítulo 3. Trabajos relacionados ......................................................... 24 3.1. Herramientas comerciales .....................................................................................24 -

(DIS) Installation Guide
Delegation Issuing Service (DIS) Installation Guide © University of Kent 2005-2010 Document History Version Date Comments 0.1 9 September 2005 First draft by Wensheng 0.2 12 September 2005 Updated by Tuan Anh 0.3 14 September 2005 Reviewed by David 1.0 15 September 2005 First public release 1.1 1 July 2006 Updated with Acceptance Tests for issuing attributes 1.2 24 July 2006 Update the installation instructions 1.3 26 July 2006 Updated with Acceptance Tests for revocation attributes 1.4 14 August 2006 Fix some inconsistencies after validating by Romain 1.5 3 October 2006 Add the SearchRequestor parameter, change the parameters in the configuration file using Permis standard parameters. 1.6 24 October 2006 Add instruction for using policy stored in a file 1.7 24 October 2006 Add support for java 1.5 1.8 22 February 2007 Add support for Tomat 5.5 1.9 23 April 2007 Add support for Apache 2.2 2.0 12 August 2008 Using PERMIS v5 policies and Apache http server on Windows (by Linying) 2.1 25 March 2009 Updated the authentication of tomcat, DIS installation instruction, instruction for apache2.2 (by Kaniz) 2.2 17 February 2010 Revised and updated by Kaniz 2.3 16 April 2010 Updated by Mark 2.5 26 October 2010 Install guide rewritten and separated into its own document 2.5.2 2 November 2010 Java installation explained more fully. Tomcat native library installation corrected. Default DIS configuration file inserted. 2.5.4 5 November 2010 Addressed feedback from Kaniz System Requirements For the DIS Web Service A recent Java Runtime Environment (JRE). -

Web Services & Axis2
Web Services & Axis2 Architecture & Tutorial Ing. Buda Claudio [email protected] 2nd Engineering Faculty University of Bologna June 2007 Axis from SOAP Apache Axis is an implementation of the SOAP ("Simple Object Access Protocol") submission to W3C. Extract from the draft W3C specification: "SOAP is a lightweight protocol for exchanging structured information in a decentralized, distributed environment. It is an XML based protocol that consists of three parts: an envelope that defines a framework for describing what is in a message and how to process it, a set of encoding rules for expressing instances of application-defined datatypes, and a convention for representing remote procedure calls and responses." Axis2 A new architecture for Axis was introduced during the August 2004 Summit in Colombo, Sri Lanka. The new architecture on which Axis2 is based on is more flexible, efficient and configurable in comparison to Axis1.x architecture. Some well established concepts from Axis 1.x, like handlers etc., have been preserved in the new architecture. The Apache Axis2 project is a Java-based implementation of both the client and server sides of the Web services equation. Designed to take advantage of the lessons learned from Apache Axis 1.0, Apache Axis2 provides a complete object model and a modular architecture that makes it easy to add functionality and support for new Web services-related specifications and recommendations. Axis2 abilities Axis2 enables you to easily perform the following tasks: Send SOAP messages Receive and process -

Informatica® Informatica 10.2 Hotfix 1
Informatica® Informatica 10.2 HotFix 1 Notas de la versión Informatica Informatica Notas de la versión 10.2 HotFix 1 Agosto 2018 © Copyright Informatica LLC 1998, 2018 Fecha de publicación: 2018-09-25 Tabla de contenido Resumen....................................................................... vi Capítulo 1: Instalación y actualización........................................ 7 Rutas de actualización de Informatica......................................... 7 Cambios en la compatibilidad.............................................. 8 Cambios en la compatibilidad - Distribuciones de Hadoop para Big Data Management....... 9 Cambios en la compatibilidad - Distribuciones de Intelligent Streaming Hadoop.......... 10 Migración a una base de datos diferente....................................... 10 Actualización a la nueva configuración........................................ 10 Actualización desde la versión 10.1.1 HotFix 2................................... 11 Actualizar desde la versión 9.6.1............................................ 11 Vulnerabilidades solucionadas de bibliotecas de otros fabricantes...................... 12 Instalación y reversión de la revisión......................................... 21 Tareas previas a la instalación.......................................... 21 Aplicación o reversión del HotFix en modo gráfico............................. 22 Aplicación o reversión del HotFix en modo de consola........................... 23 Aplicación o reversión del HotFix en modo silencioso........................... 24 Aplicación -

REST Gateway Demo Documentation Release 1.0
REST Gateway Demo Documentation Release 1.0 Hiranya Jayathilaka September 07, 2015 Contents 1 Introduction 3 1.1 Backend SOAP Service.........................................3 1.2 Synapse ESB Configuration.......................................4 1.3 Sample Client Scripts..........................................4 2 Getting Familiar with Apache Synapse5 2.1 Simple Proxy Services..........................................6 2.2 Messaging Model............................................7 2.3 REST API Support............................................7 2.4 More Documentation and Samples...................................8 2.5 Configuration Language.........................................8 2.6 WSO2 ESB................................................8 3 REST Gateway Tutorial 11 3.1 Prerequisites............................................... 11 3.2 Setting Up the Backend Server...................................... 11 3.3 Setting Up the ESB............................................ 13 3.4 Running the REST Client........................................ 14 3.5 Testing Content Negotiation....................................... 15 3.6 Tracing Messages............................................ 17 4 REST Gateway Implementation 19 4.1 Order API (StarbucksOrderAPI)..................................... 19 4.2 Order List API (StarbucksOrderListAPI)................................ 20 4.3 Error Handling.............................................. 21 5 Indices and tables 23 i ii REST Gateway Demo Documentation, Release 1.0 Contents: Contents 1 REST