Achieving K-Anonymity Privacy Protection Using Generalization and Suppression
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
SF424 Discretionary V2.1 Instructions
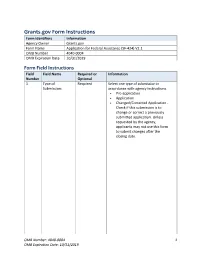
Grants.gov Form Instructions Form Identifiers Information Agency Owner Grants.gov Form Name Application for Federal Assistance (SF-424) V2.1 OMB Number 4040-0004 OMB Expiration Date 10/31/2019 Form Field Instructions Field Field Name Required or Information Number Optional 1. Type of Required Select one type of submission in Submission: accordance with agency instructions. Pre-application Application Changed/Corrected Application - Check if this submission is to change or correct a previously submitted application. Unless requested by the agency, applicants may not use this form to submit changes after the closing date. OMB Number: 4040-0004 1 OMB Expiration Date: 10/31/2019 Field Field Name Required or Information Number Optional 2. Type of Application Required Select one type of application in accordance with agency instructions. New - An application that is being submitted to an agency for the first time. Continuation - An extension for an additional funding/budget period for a project with a projected completion date. This can include renewals. Revision - Any change in the federal government's financial obligation or contingent liability from an existing obligation. If a revision, enter the appropriate letter(s). More than one may be selected. A: Increase Award B: Decrease Award C: Increase Duration D: Decrease Duration E: Other (specify) AC: Increase Award, Increase Duration AD: Increase Award, Decrease Duration BC: Decrease Award, Increase Duration BD: Decrease Award, Decrease Duration 3. Date Received: Required Enter date if form is submitted through other means as instructed by the Federal agency. The date received is completed electronically if submitted via Grants.gov. 4. -

Anonymity and Encryption in Digital Communications, February 2015
Submission to the UN Special Rapporteur on freedom of expression – anonymity and encryption in digital communications, February 201 1! Introduction Privacy International submits this information for the Special Rapporteur's report on the use of encryption and anonymity in digital communications. Anonymity and the use of encryption in digital communications engage both the right to freedom of expression and right to privacy very closely: anonymity and encryption protects privacy, and ithout effective protection of the right to privacy, the right of individuals to communicate anonymously and ithout fear of their communications being unla fully detected cannot be guaranteed. As noted by the previous mandate holder, !rank #aRue, $the right to privacy is essential for individuals to express themselves freely. Indeed, throughout history, people%s illingness to engage in debate on controversial sub&ects in the public sphere has al ays been linked to possibilities for doing so anonymously.'( Individuals' right to privacy extends to their digital communications.) As much as they offer ne opportunities to freely communicate, the proliferation of digital communications have signi*cantly increased the capacity of states, companies and other non+state actors to interfere ith individual's privacy and free expression. Such interference ranges from mass surveillance of communications by state intelligence agencies, to systematic collection and storage of private information by internet and telecommunication companies, to cybercrime. Anonymity and encryption are essential tools available to individuals to mitigate or avert interferences ith their rights to privacy and free expression. In this ay, they are means of individuals exercising to the fullest degree their rights hen engaging in digital communications. -

Anonymity in a Time of Surveillance
LESSONS LEARNED TOO WELL: ANONYMITY IN A TIME OF SURVEILLANCE A. Michael Froomkin* It is no longer reasonable to assume that electronic communications can be kept private from governments or private-sector actors. In theory, encryption can protect the content of such communications, and anonymity can protect the communicator’s identity. But online anonymity—one of the two most important tools that protect online communicative freedom—is under practical and legal attack all over the world. Choke-point regulation, online identification requirements, and data-retention regulations combine to make anonymity very difficult as a practical matter and, in many countries, illegal. Moreover, key internet intermediaries further stifle anonymity by requiring users to disclose their real names. This Article traces the global development of technologies and regulations hostile to online anonymity, beginning with the early days of the Internet. Offering normative and pragmatic arguments for why communicative anonymity is important, this Article argues that anonymity is the bedrock of online freedom, and it must be preserved. U.S. anti-anonymity policies not only enable repressive policies abroad but also place at risk the safety of anonymous communications that Americans may someday need. This Article, in addition to providing suggestions on how to save electronic anonymity, calls for proponents of anti- anonymity policies to provide stronger justifications for such policies and to consider alternatives less likely to destroy individual liberties. In -

No. 16-3588 in the UNITED STATES COURT of APPEALS for THE
Case: 16-3588 Document: 003112605572 Page: 1 Date Filed: 04/26/2017 No. 16-3588 IN THE UNITED STATES COURT OF APPEALS FOR THE THIRD CIRCUIT ______________________ UNITED STATES OF AMERICA, Appellee v. GABRIEL WERDENE, Appellant ______________________ On Appeal from the United States District Court for the Eastern District of Pennsylvania ______________________ BRIEF OF AMICUS CURIAE PRIVACY INTERNATIONAL IN SUPPORT OF APPELLANT AND IN SUPPORT OF REVERSAL OF THE DECISION BELOW ______________________ Of counsel: Caroline Wilson Palow* Lisa A. Mathewson Scarlet Kim* The Law Offices of PRIVACY INTERNATIONAL Lisa A. Mathewson, LLC 62 Britton Street 123 South Broad Street, Suite 810 London EC1M 5UY Philadelphia, PA 19109 Phone: +44 (0) 20 3422 4321 Phone: (215) 399-9592 [email protected] [email protected] Counsel for Amicus Curiae, *Counsel not admitted to Third Circuit Bar Privacy International Case: 16-3588 Document: 003112605572 Page: 2 Date Filed: 04/26/2017 CORPORATE DISCLOSURE STATEMENT Pursuant to Federal Rule of Appellate Procedure 26.1 and Local Appellate Rule 26.1.1, amicus curiae Privacy International certifies that it does not have a parent corporation and that no publicly held corporation owns 10% or more of its stock. i Case: 16-3588 Document: 003112605572 Page: 3 Date Filed: 04/26/2017 TABLE OF CONTENTS TABLE OF AUTHORITIES ................................................................................... iii STATEMENT OF INTEREST ................................................................................. -

Aiding Surveillance an Exploration of How Development and Humanitarian Aid Initiatives Are Enabling Surveillance in Developing Countries
Privacy International Aiding Surveillance An exploration of how development and humanitarian aid initiatives are enabling surveillance in developing countries Gus Hosein and Carly Nyst 01 October 2013 www.privacyinternational.org Aiding Surveillance — Privacy International Contents Executive Summary 04 Section 1 Introduction 05 Section 2 Methodology 15 Section 3 Management Information Systems 17 and electronic transfers Section 4 Digital identity registration and biometrics 28 Section 5 Mobile phones and data 42 Section 6 Border surveillance and security 50 Section 7 Development at the expense of human rights? 56 The case for caution Endnotes 59 03/80 Aiding Surveillance — Privacy International Executive Summary Information technology transfer is increasingly a crucial element of development and humanitarian aid initiatives. Social protection programmes are incorporating digitised Management Information Systems and electronic transfers, registration and electoral systems are deploying biometric technologies, the proliferation of mobile phones is facilitating access to increased amounts of data, and technologies are being transferred to support security and rule of law efforts. Many of these programmes and technologies involve the surveillance of individuals, groups, and entire populations. The collection and use of personal information in these development and aid initiatives is without precedent, and subject to few legal safeguards. In this report we show that as development and humanitarian donors and agencies rush to adopt new technologies that facilitate surveillance, they may be creating and supporting systems that pose serious threats to individuals’ human rights, particularly their right to privacy. 04/80 Section 1 Aiding Surveillance — Privacy International Introduction 1.0 It is hard to imagine a current public policy arena that does not incorporate new technologies in some way, whether in the planning, development, deployment, or evaluation phases. -

Fedramp Master Acronym and Glossary Document
FedRAMP Master Acronym and Glossary Version 1.6 07/23/2020 i[email protected] fedramp.gov Master Acronyms and Glossary DOCUMENT REVISION HISTORY Date Version Page(s) Description Author 09/10/2015 1.0 All Initial issue FedRAMP PMO 04/06/2016 1.1 All Addressed minor corrections FedRAMP PMO throughout document 08/30/2016 1.2 All Added Glossary and additional FedRAMP PMO acronyms from all FedRAMP templates and documents 04/06/2017 1.2 Cover Updated FedRAMP logo FedRAMP PMO 11/10/2017 1.3 All Addressed minor corrections FedRAMP PMO throughout document 11/20/2017 1.4 All Updated to latest FedRAMP FedRAMP PMO template format 07/01/2019 1.5 All Updated Glossary and Acronyms FedRAMP PMO list to reflect current FedRAMP template and document terminology 07/01/2020 1.6 All Updated to align with terminology FedRAMP PMO found in current FedRAMP templates and documents fedramp.gov page 1 Master Acronyms and Glossary TABLE OF CONTENTS About This Document 1 Who Should Use This Document 1 How To Contact Us 1 Acronyms 1 Glossary 15 fedramp.gov page 2 Master Acronyms and Glossary About This Document This document provides a list of acronyms used in FedRAMP documents and templates, as well as a glossary. There is nothing to fill out in this document. Who Should Use This Document This document is intended to be used by individuals who use FedRAMP documents and templates. How To Contact Us Questions about FedRAMP, or this document, should be directed to [email protected]. For more information about FedRAMP, visit the website at https://www.fedramp.gov. -

Name Standards User Guide
User Guide Contents SEVIS Name Standards 1 SEVIS Name Fields 2 SEVIS Name Standards Tied to Standards for Machine-readable Passport 3 Applying the New Name Standards 3 Preparing for the New Name Standards 4 Appendix 1: Machine-readable Passport Name Standards 5 Understanding the Machine-readable Passport 5 Name Standards in the Visual Inspection Zone (VIZ) 5 Name Standards in the Machine-readable Zone (MRZ) 6 Transliteration of Names 7 Appendix 2: Comparison of Names in Standard Passports 10 Appendix 3: Exceptional Situations 12 Missing Passport MRZ 12 SEVIS Name Order 12 Unclear Name Order 14 Names-Related Resources 15 Bibliography 15 Document Revision History 15 SEVP will implement a set of standards for all nonimmigrant names entered into SEVIS. This user guide describes the new standards and their relationship to names written in passports. SEVIS Name Standards Name standards help SEVIS users: Comply with the standards governing machine-readable passports. Convert foreign names into standardized formats. Get better results when searching for names in government systems. Improve the accuracy of name matching with other government systems. Prevent the unacceptable entry of characters found in some names. SEVIS Name Standards User Guide SEVIS Name Fields SEVIS name fields will be long enough to capture the full name. Use the information entered in the Machine-Readable Zone (MRZ) of a passport as a guide when entering names in SEVIS. Field Names Standards Surname/Primary Name Surname or the primary identifier as shown in the MRZ -

Banner 9 Naming Convention
Banner Page Name Convention Quick Reference Guide About the Banner Page Name Convention The seven-letter naming convention used throughout the Banner Administrative Applications help you to remember page or form names more readily. As shown below, the first three positions use consistent letter codes. The last four positions are an abbreviation of the full page name. For example, all pages in the Banner Student system begin with an S (for Student). All reports, regardless of the Banner system to which they belong, have an R in the third position. In this example, SPAIDEN is a page in the Banner Student system (Position 1 = S for Student system). The page is located in the General Person module (Position 2 = P for Person module). It is an application page (Position 3 = A for Application object type). And in Positions 4-7, IDEN is used as the abbreviation for the full page which is General Person Identification. Position 1 Position 2 Position 3 Position 4 Position 5 Position 6 Position 7 S P A I D E N • Position 1: System Identifier Positions 4-7: Page Name Abbreviation • Position 2: Module Identifier • Position 3: Object Type © 2018 All Rights Reserved | Ellucian Confidential & Proprietary | UNAUTHORIZED DISTRIBUTION PROHIBITED Banner Page Name Convention Quick Reference Guide Position 1: System Identifier. What follows are the Position 1 letter codes and associated descriptions. Position 1 Position 2 Position 3 Position 4 Position 5 Position 6 Position 7 S P A I D E N Position 1 Description Position 1 Description A Banner Advancement P -

PRIMARY RECORD Trinomial ______NRHP Status Code 6Z Other Listings ______Review Code ______Reviewer ______Date ______
State of California – The Resources Agency Primary # ____________________________________ DEPARTMENT OF PARKS AND RECREATION HRI # _______________________________________ PRIMARY RECORD Trinomial _____________________________________ NRHP Status Code 6Z Other Listings ______________________________________________________________ Review Code __________ Reviewer ____________________________ Date ___________ Page 1 of 11 *Resource Name or # (Assigned by recorder) 651 Mathew Street Map Reference Number: P1. Other Identifier: *P2. Location: Not for Publication Unrestricted *a. County Santa Clara County And (P2b and P2c or P2d. Attach a Location Map as necessary.) *b. USGS 7.5’ Quad San Jose West Date 1980 T; R; of Sec Unsectioned; B.M. c. Address 651 Mathew Street City Santa Clara Zip 94050 d. UTM: (give more than one for large and/or linear resources) Zone 10; 593294 mE/ 4135772 mN e. Other Locational Data: (e.g., parcel #, directions to resource, elevation, etc., as appropriate) Parcel #224-40-001. Tract: Laurelwood Farms Subdivision. *P3a. Description: (Describe resource and its major elements. Include design, materials, condition, alterations, size, setting, and boundaries) 651 Mathew Street in Santa Clara is an approximately 4.35-acre light industrial property in a light and heavy industrial setting east of the San Jose International Airport and the Southern Pacific Railroad train tracks. The property contains nine (9) cannery and warehouse buildings formerly operated by a maraschino cherry packing company, the Diana Fruit Preserving Company. The first building was constructed on the property in 1950 and consists of a rectangular shaped, wood-frame and reinforced concrete tilt-up cannery building with a barrel roof and bow-string truss (see photograph 2, 3, 4, 10). A cantilevered roof wraps around the southwest corner and shelters the office extension. -

Local Course Identifier Local Course Title Local Course Descriptor
State Course Code (optional if course Sequence will be mapped Optional Sort Optional Sort Local Course Local Course Local Course Descriptor Credits Total using CO SSCC Field 1 (For Field 2 (For Identifier Title (optional) Course Level (Carnegie Units) Sequence (optional) (optional) Mapping System) District Use) District Use) Maximum 100 100 2000 1 4 1 1 30 20 20 Length Format Alphanumeric Alphanumeric Alphanumeric Alphanumeric Numeric Numeric Numeric Alphanumeric Alphanumeric Alphanumeric Details Default MUST Be Unique! If your district does not Blank G The number of length of the course The Sequence field combined The total number The appropriate state course User Defined User Defined have title for a course, in terms of Carnegie Units. A one with “Sequence Total” of classes offered number which corresponds please repeat the Same year course that meets daily for describes the manner in which in a series of to the local course identifier. Value as the Local approximately 50 minutes to 1 hour school systems may “break classes. Used in Refer to Colorado SSCC Course Identifier = 1 Carnegie Unit Credit. Base all up” increasingly difficult or conjunction with Codes and match as many as calculations on 1 hour for 1 year. more complex course “Sequence” possible with the Therefore, a semester long course information. The sequence corresponding SSCC Code. that meets for approximately 1 hour represents the part of the total. Separate multiple values = .5 Carnegie Unit Credit. with commas. Notes The identifier The Local Course Title The description provided by the local The level associated with The course offered. Valid values are: What is the Carnegie Unit? Typically Sequence will equal Typically Refer to the following link to Recommended Recommended designated by the designated by the local district for the course. -

Common Identifier Background Paper 1: Frameworks for Creating a Common Identifier for a Statewide Data System Kathy Bracco and Kathy Booth, Wested
Common Identifier Background Paper 1: Frameworks for Creating a Common Identifier for a Statewide Data System Kathy Bracco and Kathy Booth, WestEd Introduction In 2019, California enacted the Cradle-to-Career Data System Act (Act), which called for the establishment of a state longitudinal data system to link existing education, social services, and workforce information.1 The Act also laid out a long-term vision for putting these data to work to improve education, social, and employment outcomes for all Californians, with a focus on identifying opportunity disparities in these areas. The legislation articulated the scope of an 18-month planning process for a linked longitudinal data system. The process will be shaped by a workgroup that consists of the partner entities named in the California Cradle-to-Career Data System Act.2 Suggestions from this workgroup will be used to inform a report to the legislature and shape the state data system designs approved by the Governor’s Office. Because the legislation laid out a number of highly technical topics that must be addressed as part of the legislative report, five subcommittees were created that include representatives from the partner entities and other experts. The Common Identifier Subcommittee will 1 Read the California Cradle-to-Career Data System Act at: https://leginfo.legislature.ca.gov/faces/codes_displayText.xhtml?lawCode=EDC&division=1.&title=1.& part=7.&chapter=8.5.&article= 2 The partner entities include the Association of Independent California Colleges and Universities, Bureau for Private Postsecondary Education, California Community Colleges, California Department of Education, California Department of Social Services, California Department of Technology, California Health and Human Services Agency, California School Information Services, California State University, California Student Aid Commission, Commission on Teacher Credentialing, Employment Development Department, Labor and Workforce Development Agency, State Board of Education, and University of California. -

Privacy International, Human and Digital Rights Organizations, and International Legal Scholars As Amici Curiae in Support of Respondent
No. 17-2 IN THE Supreme Court of the United States IN THE MdATTER OF A WARRANT TO SEARCH A CERTAIN EMAIL ACCOUNT CONTROLLED AND MAINTAINED BY MICROSOFT CORPORATION UNITED STATES OF AMERICA, Petitioner, —v.— MICROSOFT CORPORATION, Respondent. ON WRIT OF CERTIORARI TO THE UNITED STATES COURT OF APPEALS FOR THE SECOND CIRCUIT BRIEF OF PRIVACY INTERNATIONAL, HUMAN AND DIGITAL RIGHTS ORGANIZATIONS, AND INTERNATIONAL LEGAL SCHOLARS AS AMICI CURIAE IN SUPPORT OF RESPONDENT LAUREN GALLO WHITE BRIAN M. WILLEN RYAN T. O’HOLLAREN Counsel of Record WILSON, SONSINI, GOODRICH BASTIAAN G. SUURMOND & ROSATI, P.C. WILSON, SONSINI, GOODRICH One Market Plaza Spear Tower, & ROSATI, P.C. Suite 3300 1301 Avenue of the Americas, San Francisco, California 94105 40th Floor (415) 947-2000 New York, New York 10019 [email protected] (212) 999-5800 [email protected] [email protected] [email protected] Attorneys for Amici Curiae (Counsel continued on inside cover) CAROLINE WILSON PALOW SCARLET KIM PRIVACY INTERNATIONAL 62 Britton Street London, EC1M 5UY United Kingdom [email protected] [email protected] i QUESTION PRESENTED Whether construing the Stored Communications Act (“SCA”) to authorize the seizure of data stored outside the United States would conflict with foreign data-protection laws, including those of Ireland and the European Union, and whether these conflicts should be avoided by applying established canons of construction, including presumptions against extra- territoriality and in favor of international comity, which direct U.S. courts to construe statutes as applying only domestically and consistently with foreign laws, absent clear Congressional intent. ii TABLE OF CONTENTS PAGE QUESTION PRESENTED ..........................