Newton's Method, the Classical Method for Nding the Zeros of a Function, Is One of the Most Important Algorithms of All Time
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Lecture 9: Newton Method 9.1 Motivation 9.2 History
10-725: Convex Optimization Fall 2013 Lecture 9: Newton Method Lecturer: Barnabas Poczos/Ryan Tibshirani Scribes: Wen-Sheng Chu, Shu-Hao Yu Note: LaTeX template courtesy of UC Berkeley EECS dept. 9.1 Motivation Newton method is originally developed for finding a root of a function. It is also known as Newton- Raphson method. The problem can be formulated as, given a function f : R ! R, finding the point x? such that f(x?) = 0. Figure 9.1 illustrates another motivation of Newton method. Given a function f, we want to approximate it at point x with a quadratic function fb(x). We move our the next step determined by the optimum of fb. Figure 9.1: Motivation for quadratic approximation of a function. 9.2 History Babylonian people first applied the Newton method to find the square root of a positive number S 2 R+. The problem can be posed as solving the equation f(x) = x2 − S = 0. They realized the solution can be achieved by applying the iterative update rule: 2 1 S f(xk) xk − S xn+1 = (xk + ) = xk − 0 = xk − : (9.1) 2 xk f (xk) 2xk This update rule converges to the square root of S, which turns out to be a special case of Newton method. This could be the first application of Newton method. The starting point affects the convergence of the Babylonian's method for finding the square root. Figure 9.2 shows an example of solving the square root for S = 100. x- and y-axes represent the number of iterations and the variable, respectively. -

The Newton Fractal's Leonardo Sequence Study with the Google
INTERNATIONAL ELECTRONIC JOURNAL OF MATHEMATICS EDUCATION e-ISSN: 1306-3030. 2020, Vol. 15, No. 2, em0575 OPEN ACCESS https://doi.org/10.29333/iejme/6440 The Newton Fractal’s Leonardo Sequence Study with the Google Colab Francisco Regis Vieira Alves 1*, Renata Passos Machado Vieira 1 1 Federal Institute of Science and Technology of Ceara - IFCE, BRAZIL * CORRESPONDENCE: [email protected] ABSTRACT The work deals with the study of the roots of the characteristic polynomial derived from the Leonardo sequence, using the Newton fractal to perform a root search. Thus, Google Colab is used as a computational tool to facilitate this process. Initially, we conducted a study of the Leonardo sequence, addressing it fundamental recurrence, characteristic polynomial, and its relationship to the Fibonacci sequence. Following this study, the concept of fractal and Newton’s method is approached, so that it can then use the computational tool as a way of visualizing this technique. Finally, a code is developed in the Phyton programming language to generate Newton’s fractal, ending the research with the discussion and visual analysis of this figure. The study of this subject has been developed in the context of teacher education in Brazil. Keywords: Newton’s fractal, Google Colab, Leonardo sequence, visualization INTRODUCTION Interest in the study of homogeneous, linear and recurrent sequences is becoming more and more widespread in the scientific literature. Therefore, the Fibonacci sequence is the best known and studied in works found in the literature, such as Oliveira and Alves (2019), Alves and Catarino (2019). In these works, we can see an investigation and exploration of the Fibonacci sequence and the complexification of its mathematical model and the generalizations that result from it. -

Lecture 1: What Is Calculus?
Math1A:introductiontofunctionsandcalculus OliverKnill, 2012 Lecture 1: What is Calculus? Calculus formalizes the process of taking differences and taking sums. Differences measure change, sums explore how things accumulate. The process of taking differences has a limit called derivative. The process of taking sums will lead to the integral. These two pro- cesses are related in an intimate way. In this first lecture, we look at these two processes in the simplest possible setup, where functions are evaluated only on integers and where we do not take any limits. About 25’000 years ago, numbers were represented by units like 1, 1, 1, 1, 1, 1,... for example carved in the fibula bone of a baboon1. It took thousands of years until numbers were represented with symbols like today 0, 1, 2, 3, 4,.... Using the modern concept of function, we can say f(0) = 0, f(1) = 1, f(2) = 2, f(3) = 3 and mean that the function f assigns to an input like 1001 an output like f(1001) = 1001. Lets call Df(n) = f(n + 1) − f(n) the difference between two function values. We see that the function f satisfies Df(n) = 1 for all n. We can also formalize the summation process. If g(n) = 1 is the function which is constant 1, then Sg(n) = g(0) + g(1) + ... + g(n − 1) = 1 + 1 + ... + 1 = n. We see that Df = g and Sg = f. Now lets start with f(n) = n and apply summation on that function: Sf(n) = f(0) + f(1) + f(2) + .. -

Fractal Newton Basins
FRACTAL NEWTON BASINS M. L. SAHARI AND I. DJELLIT Received 3 June 2005; Accepted 14 August 2005 The dynamics of complex cubic polynomials have been studied extensively in the recent years. The main interest in this work is to focus on the Julia sets in the dynamical plane, and then is consecrated to the study of several topics in more detail. Newton’s method is considered since it is the main tool for finding solutions to equations, which leads to some fantastic images when it is applied to complex functions and gives rise to a chaotic sequence. Copyright © 2006 M. L. Sahari and I. Djellit. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, dis- tribution, and reproduction in any medium, provided the original work is properly cited. 1. Introduction Isaac Newton discovered what we now call Newton’s method around 1670. Although Newton’s method is an old application of calculus, it was discovered relatively recently that extending it to the complex plane leads to a very interesting fractal pattern. We have focused on complex analysis, that is, studying functions holomorphic on a domain in the complex plane or holomorphic mappings. It is a very exciting field, in which many new phenomena wait to be discovered (and have been discovered). It is very closely linked with fractal geometry, as the basins of attraction for Newton’s method have fractal character in many instances. We are interested in geometric problems, for example, the boundary behavior of conformal mappings. In mathematics, dynamical systems have become popular for another reason: beautiful pictures. -

Top 300 Semifinalists 2016
TOP 300 SEMIFINALISTS 2016 2016 Broadcom MASTERS Semifinalists 2 About Broadcom MASTERS Broadcom MASTERS® (Math, Applied Science, Technology and Engineering for Rising Stars), a program of Society for Science & the Public, is the premier middle school science and engineering fair competition. Society-affiliated science fairs around the country nominate the top 10% of sixth, seventh and eighth grade projects to enter this prestigious competition. After submitting the online application, the top 300 semifinalists are selected. Semifinalists are honored for their work with a prize package that includes an award ribbon, semifinalist certificate of accomplishment, Broadcom MASTERS backpack, a Broadcom MASTERS decal, a one year family digital subscription to Science News magazine, an Inventor's Notebook and copy of “Howtoons” graphic novel courtesy of The Lemelson Foundation, and a one year subscription to Mathematica+, courtesy of Wolfram Research. In recognition of the role that teachers play in the success of their students, each semifinalist's designated teacher also will receive a Broadcom MASTERS tote bag and a one year subscription to Science News magazine, courtesy of KPMG. From the semifinalist group, 30 finalists are selected and will present their research projects and compete in hands-on team STEM challenges to demonstrate their skills in critical thinking, collaboration, communication and creativity at the Broadcom MASTERS finals. Top awards include a grand prize of $25,000, trips to STEM summer camps and more. Broadcom Foundation and Society for Science & the Public thank the following for their support of 2016 Broadcom MASTERS: • Samueli Foundation • Robert Wood Johnson Foundation • Science News for Students • Wolfram Research • Allergan • Affiliated Regional and State Science • Computer History Museum & Engineering Fairs • Deloitte. -

Dynamical Systems with Applications Using Mathematicar
DYNAMICAL SYSTEMS WITH APPLICATIONS USING MATHEMATICA⃝R SECOND EDITION Stephen Lynch Springer International Publishing Contents Preface xi 1ATutorialIntroductiontoMathematica 1 1.1 AQuickTourofMathematica. 2 1.2 TutorialOne:TheBasics(OneHour) . 4 1.3 Tutorial Two: Plots and Differential Equations (One Hour) . 7 1.4 The Manipulate Command and Simple Mathematica Programs . 9 1.5 HintsforProgramming........................ 12 1.6 MathematicaExercises. .. .. .. .. .. .. .. .. .. 13 2Differential Equations 17 2.1 Simple Differential Equations and Applications . 18 2.2 Applications to Chemical Kinetics . 27 2.3 Applications to Electric Circuits . 31 2.4 ExistenceandUniquenessTheorem. 37 2.5 MathematicaCommandsinTextFormat . 40 2.6 Exercises ............................... 41 3PlanarSystems 47 3.1 CanonicalForms ........................... 48 3.2 Eigenvectors Defining Stable and Unstable Manifolds . 53 3.3 Phase Portraits of Linear Systems in the Plane . 56 3.4 Linearization and Hartman’s Theorem . 59 3.5 ConstructingPhasePlaneDiagrams . 61 3.6 MathematicaCommands .. .. .. .. .. .. .. .. .. 69 3.7 Exercises ............................... 70 4InteractingSpecies 75 4.1 CompetingSpecies .......................... 76 4.2 Predator-PreyModels . .. .. .. .. .. .. .. .. .. 79 4.3 Other Characteristics Affecting Interacting Species . 84 4.4 MathematicaCommands .. .. .. .. .. .. .. .. .. 86 4.5 Exercises ............................... 87 v vi CONTENTS 5LimitCycles 91 5.1 HistoricalBackground . .. .. .. .. .. .. .. .. .. 92 5.2 Existence and Uniqueness of -

Math Morphing Proximate and Evolutionary Mechanisms
Curriculum Units by Fellows of the Yale-New Haven Teachers Institute 2009 Volume V: Evolutionary Medicine Math Morphing Proximate and Evolutionary Mechanisms Curriculum Unit 09.05.09 by Kenneth William Spinka Introduction Background Essential Questions Lesson Plans Website Student Resources Glossary Of Terms Bibliography Appendix Introduction An important theoretical development was Nikolaas Tinbergen's distinction made originally in ethology between evolutionary and proximate mechanisms; Randolph M. Nesse and George C. Williams summarize its relevance to medicine: All biological traits need two kinds of explanation: proximate and evolutionary. The proximate explanation for a disease describes what is wrong in the bodily mechanism of individuals affected Curriculum Unit 09.05.09 1 of 27 by it. An evolutionary explanation is completely different. Instead of explaining why people are different, it explains why we are all the same in ways that leave us vulnerable to disease. Why do we all have wisdom teeth, an appendix, and cells that if triggered can rampantly multiply out of control? [1] A fractal is generally "a rough or fragmented geometric shape that can be split into parts, each of which is (at least approximately) a reduced-size copy of the whole," a property called self-similarity. The term was coined by Beno?t Mandelbrot in 1975 and was derived from the Latin fractus meaning "broken" or "fractured." A mathematical fractal is based on an equation that undergoes iteration, a form of feedback based on recursion. http://www.kwsi.com/ynhti2009/image01.html A fractal often has the following features: 1. It has a fine structure at arbitrarily small scales. -

Newton Raphson Method Theory Pdf
Newton raphson method theory pdf Continue Next: Initial Guess: 10.001: Solution of the non-linear previous: Newton-Rafson false method method is one of the most widely used methods of root search. It can be easily generalized to the problem of finding solutions to a system of nonlinear equations called Newton's technique. In addition, it can be shown that the technique is four-valent converged as you approach the root. Unlike bisection and false positioning methods, the Newton-Rafson (N-R) method requires only one initial x0 value, which we will call the original guess for the root. To see how the N-R method works, we can rewrite the f-x function by extending the Taylor series to (x-x0): f(x) - f (x0) - f'(x0) - 1/2 f'(x0) (x-x0)2 - 0 (5), where f'(x) denotes the first derivative f(x) in relation to x, x x, x, x f'(x) is the second derivative, and so on. Now let's assume that the original guess is quite close to the real root. Then (x-x0) small, and only the first few terms in the series are important to get an accurate estimate of the true root, given x0. By truncating the series in the second term (linear in x), we get the N-R iteration formula to get a better estimate of the true root: (6) Thus, the N-R method finds tangent to the function f(x) on x'x0 and extrapolates it to cross the x1 axis. This crossing point is considered to be a new approximation to the root and the procedure is repeated until convergence is obtained as far as possible. -
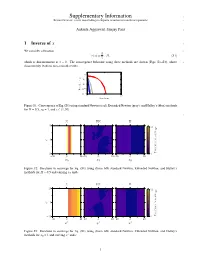
Supplementary Information 1 Beyond Newton: a New Root-finding fixed-Point Iteration for Nonlinear Equations 2
Supplementary Information 1 Beyond Newton: a new root-finding fixed-point iteration for nonlinear equations 2 Ankush Aggarwal, Sanjay Pant 3 1 Inverse of x 4 We consider a function 5 1 r(x) = H; (S1) x − which is discontinuous at x = 0. The convergence behavior using three methods are shown (Figs. S1–S3), where 6 discontinuity leads to non-smooth results. 101 | n x 3 10− − ∗ x | 7 10− 10 11 Error − 15 10− 0 10 Iterations Figure S1: Convergence of Eq. (S1) using standard Newton (red), Extended Newton (gray), and Halley’s (blue) methods for H = 0:5, x = 1, and c (1;50) 0 2 7 N EN H 10 10 c 0 10 1 Iterations to converge − 10 0 10 10 0 10 10 0 10 − − − x0 x0 x0 Figure S2: Iterations to converge for Eq. (S1) using (from left) standard Newton, Extended Newton, and Halley’s methods for H = 0:5 and varying x0 and c N EN H 10 10 c 0 10 1 Iterations to converge − 10 0 10 10 0 10 10 0 10 − − − x∗ x∗ x∗ Figure S3: Iterations to converge for Eq. (S1) using (from left) standard Newton, Extended Newton, and Halley’s methods for x0 = 1 and varying x∗ and c 1 2 Nonlinear compression 8 + We consider a function from nonlinear elasticity, which is only defined in R : 9 ( x2 1 + H if x > 0 r(x) = − x : (S2) Not defined if x 0 ≤ If the current guess xn becomes negative, the iterations are considered to be non-converged. -

Lecture 1: What Is Calculus?
Math1A:introductiontofunctionsandcalculus OliverKnill, 2011 Lecture 1: What is Calculus? Calculus is a powerful tool to describe our world. It formalizes the process of taking differences and taking sums. Both are natural operations. Differences measure change, sums measure how things accumulate. We are interested for example in the total amount of precipitation in Boston over a year but we are also interested in how the temperature does change over time. The process of taking differences is in a limit called derivative. The process of taking sums is in the limit called integral. These two processes are related in an intimate way. In this first lecture, we want to look at these two processes in a discrete setup first, where functions are evaluated only on integers. We will call the process of taking differences a derivative and the process of taking sums as integral. Start with the sequence of integers 1, 2, 3, 4, ... We say f(1) = 1, f(2) = 2, f(3) = 3 etc and call f a function. It assigns to a number a number. It assigns for example to the number 100 the result f(100) = 100. Now we add these numbers up. The sum of the first n numbers is called Sf(n) = f(1) + f(2) + f(3) + ... + f(n) . In our case we get 1, 3, 6, 10, 15, ... It defines a new function g which satisfies g(1) = 1, g(2) = 3, g(2) = 6 etc. The new numbers are known as the triangular numbers. From the function g we can get f back by taking difference: Dg(n) = g(n) g(n 1) = f(n) . -

Improved Newton Iterative Algorithm for Fractal Art Graphic Design
Hindawi Complexity Volume 2020, Article ID 6623049, 11 pages https://doi.org/10.1155/2020/6623049 Research Article Improved Newton Iterative Algorithm for Fractal Art Graphic Design Huijuan Chen and Xintao Zheng Academy of Arts, Hebei GEO University, Shijiazhuang 050031, Hebei, China Correspondence should be addressed to Xintao Zheng; [email protected] Received 19 October 2020; Revised 13 November 2020; Accepted 18 November 2020; Published 29 November 2020 Academic Editor: Zhihan Lv Copyright © 2020 Huijuan Chen and Xintao Zheng. +is is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. Fractal art graphics are the product of the fusion of mathematics and art, relying on the computing power of a computer to iteratively calculate mathematical formulas and present the results in a graphical rendering. +e selection of the initial value of the first iteration has a greater impact on the final calculation result. If the initial value of the iteration is not selected properly, the iteration will not converge or will converge to the wrong result, which will affect the accuracy of the fractal art graphic design. Aiming at this problem, this paper proposes an improved optimization method for selecting the initial value of the Gauss-Newton iteration method. +rough the area division method of the system composed of the sensor array, the effective initial value of iterative calculation is selected in the corresponding area for subsequent iterative calculation. Using the special skeleton structure of Newton’s iterative graphics, such as infinitely finely inlaid chain-like, scattered-point-like composition, combined with the use of graphic secondary design methods, we conduct fractal art graphics design research with special texture effects. -

Fractpy's Documentation!
FractPy Release 0.0.4 Amarjit Singh Gaba May 12, 2021 CONTENTS: 1 Tutorial: Generating Newton Fractal for a simple function3 1.1 Introduction to Fractal..........................................3 1.2 Installing FractPy.............................................4 1.3 Using FractPy..............................................4 2 How to 7 2.1 Create a Model..............................................7 2.2 Create a Plot...............................................7 2.3 Create a Zoom Plot............................................8 2.4 To Find the Derivative and the Roots..................................9 3 Explanantion 11 3.1 Newton Fractal.............................................. 11 4 Reference 13 4.1 Bibliography............................................... 13 4.2 Source Code............................................... 13 5 Indices and tables 17 Bibliography 19 Index 21 i ii FractPy, Release 0.0.4 This is a Python library to generate fractals of various kinds. CONTENTS: 1 FractPy, Release 0.0.4 2 CONTENTS: CHAPTER ONE TUTORIAL: GENERATING NEWTON FRACTAL FOR A SIMPLE FUNCTION 1.1 Introduction to Fractal A fractal is never ending pattern. Fractals are a type of mathematical shape that are infinitely complex. They are created by repeating a simple process over and over in an ongoing feedback loop. In essence, a Fractal is a pattern that repeats forever, and every part of the Fractal, regardless of how zoomed in, or zoomed out you are, it looks very similar to the whole image. A shape does not have to be exactly identical to be classified as a Fractal. Instead shapes that display inherent and repeating similarities are the main requirement for being classified as a Fractal. [Falconer1990] Fractals are found all over nature, spanning a huge range of scales. We find the same patterns again and again, from the tiny branching of our blood vessels and neurons to the branching of trees, lightning bolts, snowflakes, river networks and even the clustering of galaxies.