Measurement, Analysis and Performance Improvement of the Apache Web Server ¢¡
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Brief Review of Speech Synthesis
Computer Science Computer Networks Piotr Leszczyński Book No. s4207 Remote voice Web browser for people with sight impairment Zdalna głosowa przeglądarka WWW dla osób niewidomych Engineering Thesis Written under the advice of Ph.D. Eng. Przemysław Skurowski Bytom September 2009 Contents 1 Introduction............................................................................... 7 2 A brief review of speech synthesis ................................................ 9 2.1 Human speech synthesis ......................................................... 9 2.2 Text-To-Speech systems overview .......................................... 10 2.2.2 Concatenation Speech Systems ...................................... 11 2.2.3 Articulator Speech Systems ............................................ 11 2.2.4 History ........................................................................ 12 3 Application modeling and implementation .................................... 14 3.1 Application concept ............................................................... 14 3.2 Functional requirements ........................................................ 15 3.3 Non-Functional requirements ................................................. 16 3.4 Feasibility analysis ................................................................ 16 3.5 Technical limitations ............................................................. 17 3.5.1 Accessibility ................................................................. 17 3.5.2 Speech synthesis ......................................................... -

O'reilly® Jason Hunter
rr Help for Server-Side Java Developer, '" Jason Hunter O'REILLY® with William Crawford Page 1 of 94 J ava" Servlet Programming Page 2 of 94 THE JAVA"" SERIES Learning Java m Java'" Performance Tuning Java'" Threads Java'" Internationalization Java'· Network Programming JavaServer Pages" Database Programming with JDBC'Mand Java'" Java m Message Service Java'" Distributed Computing Developing Java Beans'M Java" Security Java" Cryptography Also from O'Reilly Java" Swing Java" Servlet Programming Java'M in a Nutshell Java" I/O J ava" Enterprise in a Nutshell J ava™ 2D Graphics Java'" Foundation Classes in a Nutshell Enterprise Javafleans" Java" Examples in a Nutshell Creating Effective JavaHelp'M JiniTM in a Nutshell Java'" and XML The Enterprise Java" CD Bookshelf Page 3 of 94 -, Javan, Servlet Programming Second Edition Jason Hunter with William Crawford O'REILLY® Beijing. Cambridge. Farnham» Koln » Paris > Sebastopol. Taipei. Tokyo Page 4 of 94 Java Servlet Programming, Second Edition byJason Hunter with William Crawford Copyright © 2001,1998 O'Reilly & Associates, Inc. All rights reserved. Printed in the United States of America. Published by O'Reilly & Associates, Inc., 101 Morris Street, Sebastopol, CA 95472. Editors: Robert Eckstein and Paula Ferguson Production Editor: Colleen Gorman Cover Designer: Hanna Dyer Printing History: October 1998: First Edition. April 2001: Second Edition. Nutshell Handbook, the Nutshell Handbook logo, and the O'Reilly logo are registered trademarks and The Java™ Series is a trademark of O'Reilly & Associates, Inc. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and O'Reilly & Associates, Inc. -

Etude Des Facteurs De Succès Du Projet Open Source Apache HTTP
Etude des facteurs de succès du projet open source Apache HTTP Dr Ir Robert Viseur * ** * CETIC, Avenue Jean Mermoz, 28, B-6041 Charleroi ** UMONS Faculté Polytechnique, Rue de Houdain, 9, B-7000 Mons [email protected], [email protected] Résumé : Avec Linux, Firefox et OpenOffice.org, le projet Apache HTTP fait partie des success stories populaires dans le domaine open source. Dans cette recherche, nous proposons d’explorer les facteurs de succès qui ont permis au serveur web Apache HTTP de devenir un projet open source mondial et pérenne. Après une étude longitudinale du projet identifiant les facteurs de succès, nous discutons différents apprentissages à l’usage des gestionnaires et développeurs de projets collaboratifs. Mots clés : logiciel libre, open source, serveur web, apache, utilisateur de pointe, world wide web. 1 Study of success factors for the Apache HTTP open source project Dr Ir Robert Viseur * ** * CETIC, Avenue Jean Mermoz, 28, B-6041 Charleroi ** UMONS Faculté Polytechnique, Rue de Houdain, 9, B-7000 Mons [email protected], [email protected] Abstract With Linux, Firefox and OpenOffice.org, Apache HTTP project is one of the popular success stories in the open source sector. In this research, we propose to explore the success factors that enabled Apache HTTP Web server to become a wordlwide and sustainable open source project. After a longitudinal study of the project identifying success factors, we discuss different findings for managers and developers aiming to set up collaborative projects. Keywords free software, open source, web server, apache, lead user, world wide web. 2 Introduction Le serveur web Apache HTTP, avec sa part de marché fréquemment supérieure à 50%, est un des logiciels open source incontournables. -
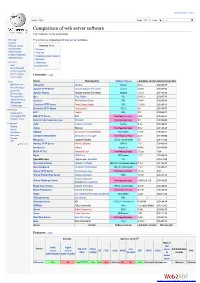
Comparison of Web Server Software from Wikipedia, the Free Encyclopedia
Create account Log in Article Talk Read Edit ViewM ohrisetory Search Comparison of web server software From Wikipedia, the free encyclopedia Main page This article is a comparison of web server software. Contents Featured content Contents [hide] Current events 1 Overview Random article 2 Features Donate to Wikipedia 3 Operating system support Wikimedia Shop 4 See also Interaction 5 References Help 6 External links About Wikipedia Community portal Recent changes Overview [edit] Contact page Tools Server Developed by Software license Last stable version Latest release date What links here AOLserver NaviSoft Mozilla 4.5.2 2012-09-19 Related changes Apache HTTP Server Apache Software Foundation Apache 2.4.10 2014-07-21 Upload file Special pages Apache Tomcat Apache Software Foundation Apache 7.0.53 2014-03-30 Permanent link Boa Paul Phillips GPL 0.94.13 2002-07-30 Page information Caudium The Caudium Group GPL 1.4.18 2012-02-24 Wikidata item Cite this page Cherokee HTTP Server Álvaro López Ortega GPL 1.2.103 2013-04-21 Hiawatha HTTP Server Hugo Leisink GPLv2 9.6 2014-06-01 Print/export Create a book HFS Rejetto GPL 2.2f 2009-02-17 Download as PDF IBM HTTP Server IBM Non-free proprietary 8.5.5 2013-06-14 Printable version Internet Information Services Microsoft Non-free proprietary 8.5 2013-09-09 Languages Jetty Eclipse Foundation Apache 9.1.4 2014-04-01 Čeština Jexus Bing Liu Non-free proprietary 5.5.2 2014-04-27 Galego Nederlands lighttpd Jan Kneschke (Incremental) BSD variant 1.4.35 2014-03-12 Português LiteSpeed Web Server LiteSpeed Technologies Non-free proprietary 4.2.3 2013-05-22 Русский Mongoose Cesanta Software GPLv2 / commercial 5.5 2014-10-28 中文 Edit links Monkey HTTP Server Monkey Software LGPLv2 1.5.1 2014-06-10 NaviServer Various Mozilla 1.1 4.99.6 2014-06-29 NCSA HTTPd Robert McCool Non-free proprietary 1.5.2a 1996 Nginx NGINX, Inc. -

Fastcgi 1 Fastcgi
FastCGI 1 FastCGI FastCGI es un protocolo para interconectar programas interactivos con un servidor web. FastCGI es una variación de la ya conocida Common Gateway Interface (CGI ó Interfaz Común de Entrada). El principal objetivo de FastCGI es reducir la carga asociada con el hecho de interconectar el servidor web y los programas Common Gateway Interface, permitiéndole a un servidor atender más peticiones a la vez. Ventajas • Independencia del lenguaje utilizado. Libertad de elección de la plataforma de desarrollo: C++, PHP, Perl, Java, entre otros. • Se utiliza un proceso separado. Libertad de elección del servidor web. Facilidad para el tratamiento de errores y depuración. • Es posible la ejecución en host separado. Mayor libertad para configuración del sistema, tanto en el diseño de la red como en la elección de los sistemas operativos. Disminución de la carga de trabajo del servidor principal. En resumen, la libertad de diseño de CGI a la velocidad de un módulo del servidor.. Historia CGI es un protocolo para interconectar aplicaciones externas con servidores web. Las aplicaciones CGI corren en un proceso separado que es creado al inicio de cada petición y es finalizado cuando termina su trabajo. Este modelo de "un nuevo proceso por cada petición" hace que los programas CGI sean muy fáciles de implementar, pero limita la eficiencia y la escalabilidad. En altas cargas, la sobrecarga en el sistema operativo por la creación y destrucción de procesos se torna significativa y limita la escalabilidad. Además, el modelo de procesos CGI limita las técnicas de reutilización de recursos (como ser la reutilización de conexiones a base de datos, caché en memoria, etc). -

Web Service - Is a Standardized Medium,Protocol Or Language to Propagate Communication Between the Client and Server Applications on the World Wide Web
Web service - is a standardized medium,protocol or language to propagate communication between the client and server applications on the World Wide Web. A web service is a software module that is designed to perform a certain set of tasks. Web services are invoked by the user directly or indirectly to provide services to the program/software which is being used as a part of WWW. User may be unaware about such web services. The web services can be searched for over the network and can also be invoked accordingly. When invoked, the web service would be able to provide the functionality to the client, which invokes that web service. Many people think that the internet and the world wide web (WWW) are the same thing. While they are closely linked, they are very different systems. The internet is a huge network of computers all connected together. The world wide web (‘www’ or ‘web’ for short) is a collection of webpages found on this network of computers. Our web browser uses the internet to access the web. The World Wide Web is a way of exchanging information between computers on the Internet, tying them together into a vast collection of interactive multimedia resources. World Wide Web was created by Timothy Berners Lee in 1989 at CERN in Geneva. World Wide Web came into existence as a proposal by him, to allow researchers to work together effectively and efficiently at CERN. Eventually it became World Wide Web. Web architecture Web is a two – tiered architecture. • A web browser display information contents • Web server that transfers information to the client Web services HTML – Hyper text markup language is a document design language not a programming language. -

PERFORMANCE to Improve the Performance Many Things Must Be Considered
CHAPTER FIVE PERFORMANCE To improve the performance many things must be considered. The web portal must avoid the system downtimes. Different types of the web servers are available in the market. Selection of the web server must be done after considering the server limitations and the needs of the web portal. Most of the time some assumptions are made about the client machine, but to make the robust web portal all the Client side limitations (e.g., communication media limitations or availability of devices like printer, speaker, etc.) must be considered. The most important point about the performance is speed optimization which can be achieved by Task scheduling. Different types of tools are available in the market as per the reQuirements for the Load and Performance Measurement. 5 PERFORMANCE 5.1 Introduction The software products undergo several cycles of alpha and beta tests and receive feedback from the users before they are distributed as a final product. The alpha and beta versions are given to the users and users suggest changes, which are reflected in the final product. If the software is fully customized then different modules are prepared and these models are installed on the user machines and users are asked to use the modules. Dynamic Content Caching (Centralized or Distributed) is used to improve the performance. The End-Users may struggle in the identification and manipulation of variables. The Modelling Web Applications Compare the modelling components using non-object oriented languages, and Compare the modelling components using object-oriented languages. Most commonly used model components are Script, Mark up, Style Sheet, Schema, Data languages, and Object-Oriented languages. -

“Change Request System”
“Change Request System” Tesina Para cumplir la acreditación de las estadías profesionales y contar con los créditos necesarios para obtener el grado de Ingeniero en Informática Autor: Irving Adrián Perea Aguilar Asesor académico: Lic. José Giovanni Ortega Tostado Asesor externo: Lic. Elisa Becerra Ulloa Organismo Receptor: Tata Consultancy Services, Ltd. Mazatlán, Sinaloa a 11 de diciembre de 2015 AGRADECIMIENTOS Con todo el amor del universo y por sobre todas las cosas, a mi madre y a mi padre, que entre la adversa incertidumbre de verme crecer y evolucionar, resintieron caídas incluso más fuertes que las mías, pero con sus espíritus grandes y sus almas soñadoras, estuvieron siempre ahí para darme la mano, ayudarme a levantar y seguir avanzando. Al espacio, al tiempo y a los acontecimientos que me pusieron el día de hoy en el lugar en el que estoy, pues no quisiera estar en ningún otro lado. A todos mis amigos (tanto a los pasajeros como a los de planta), que no hicieron mi vida más fácil, pero fácilmente la hicieron mucho más llevadera; con su elocuencia humorística y su desdén hacia las cosas que los adultos consideran importantes, hicieron de lo que va de mi existencia, la broma más larga y graciosa que alguien pudiera contarte. Quiero hacer, además, una mención especial a una criatura muy particular (cuyo nombre preferiría no recordar para nada) quien me motivó a reflexionar mis días con mucho más detenimiento, y logró que reviviera (de forma bastante dolorosa) mi ilusión en la vida, en el color, en las flores, en el cielo, en la magia y en el amor. -

Web Server Undefinedundefined Nah Kali Ini Kita Akan Belajar Tentang Teknologi Server
Web Server undefinedundefined Nah kali ini kita akan belajar tentang teknologi server. Dalam posting ini saya akan memberikan sedikit tentang server web dan memahami cara kerjanya. Memahami Server Web Web server adalah perangkat lunak yang menyediakan layanan data yang berfungsi menerima permintaan HTTP atau HTTPS dari klien, yang dikenal sebagai browser web dan mengirimkan kembali hasilnya dalam bentuk halaman web halaman yang biasanya membentuk sebuah dokumen HTML Jenis Server Web: Apache Web Server - The HTTP Web Server 1.Apache Tomcat 2.Microsoft Windows Server 2003 Internet Information Services (IIS) 3.Lighttpd 4.Sun Java Sistem Web Server 5.Xitami Web Server 6.Zeus Web Server Tapi web terkenal dan sering digunakan adalah Apache dan Microsoft Internet Information Services (IIS). Para Cara kerja dari Web Server: Server 1.Web adalah mesin dimana aplikasi atau mendistribusikan perangkat lunak beroperasi dalam suatu halaman web untuk pengguna, tentu saja, sesuai dengan permintaan pengguna. 2. Hubungan antara Web Server dan Browser Internet atau kombinasi dari jaringan komputer yang ada di seluruh dunia. Setelah terhubung secara fisik, Protocol TCP / IP (protokol jaringan) yang memungkinkan semua komputer dapat berkomunikasi dengan orang lain. Pada saat browser meminta data web page ke server maka instruksi permintaan data oleh browser dalam wadah dalam TCP transport protocol dan yang dikirim ke alamat yg dalam hal ini adalah protokol berikutnya adalah Text transfer Hyper Protocol (HTTP ). HTTP adalah protokol yang digunakan di World Wide Web (WWW) antar komputer yang terhubung dalam jaringan di dunia. Untuk mengetahui protokol jelas sangan mudah di mana setiap kali Anda mengetik http:// ... Anda harus menggunakannya, dan membawa Anda ke dunia Internet. -

Optimasi Apache Web Server Menggunakan Varnish Web Cache Dan Reverse Proxy Nginx
OPTIMASI APACHE WEB SERVER MENGGUNAKAN VARNISH WEB CACHE DAN REVERSE PROXY NGINX Skripsi disusun sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer Program Studi Teknik Informatika Oleh Anindya Putri Arunawati 4611416030 JURUSAN ILMU KOMPUTER FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS NEGERI SEMARANG 2020 ii iii iv MOTTO DAN PERSEMBAHAN MOTTO • Jika yang dapat kau lakukan hanyalah merangkak, maka mulailah merangkak (Rumi) • Semakin dia yakin kepada Allah, semakin sedikit dia mengeluh dalam hidupnya (ust. Hanan Attaki) • Jangan pernah lelah untuk berdoa dan percayakan semuanya pada Allah, Allah yang mengatur segalanya (Anindya) PERSEMBAHAN Skripsi ini saya persembahkan kepada: • Kedua Orang Tua saya Bapak Achmad Daserun dan Ibu Watini yang telah mencurahkan keringatnya untuk membiayai pendidikan saya, yang selalu memberikan kasih sayang, doa, dan dukungannnya. • Adik saya, Hilal Hubdin yang telah memberikan dukungan serta doa yang terus dipanjatkan. • Teman-teman saya di jurusan Ilmu Komputer, Fakultas MIPA, serta teman-teman di Universitas Negeri Semarang. • Semua pihak yang tidak dapat disebutkan satu persatu yang telah membantu hingga terselesaikannya penulisan skripsi ini. • Almamater, Universitas Negeri Semarang. v PRAKATA Puji syukur penulis panjatkan kepada Allah Subhanahu wa ta'ala atas berkat rahmat dan hidayah-Nya penulis dapat menyelesaikan skripsi yang berjudul “Optimasi Apache Web Server Menggunakan Varnish Web Cache Dan Reverse Proxy Nginx”. Penulis menyadari bahwa penulisan skripsi ini tidak akan selesai tanpa adanya dukungan serta bantuan dari berbagai pihak. Oleh karena itu, penulis ingin menyampaikan ucapan terima kasih kepada: 1. Prof. Dr. Fathur Rokhman, M.Hum., Rektor Universitas Negeri Semarang. 2. Dr. Sugianto M.Si., Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam Universitas Negeri Semarang. -

Tambahan Pertemuan 13 E Commerce
Dwi Hartanto, S,.Kom 10/06/2012 Macam ‐ macam Web Server diantanya: 1. Apache HTTP Web Server Apache Web Server ‐ The HTTP Web Server Proyek Apache HTTP Server adalah upaya untuk mengembangkan 1. Apache Tomcat dan memelihara server HTTP open source untuk sistem operasi 2. Microsoft windows Server 2003 Internet Information Services (IIS) modern termasuk UNIX dan Windows NT. Tujuan dari proyek ini 3. Lighttpd adalah untuk menyediakan server yang aman, efisien dan dapat 4. Sun Java System Web Server diperluas yang menyediakan layanan HTTP disinkron dengan HTTP 5. Xitami Web Server standar saat ini. 6. Zeus Web Server Namun web yang terkenal dan yang sering digunakan adalah Apache dan Microsoft Internet Information Service (IIS). E Commerce Pertemuan 13 1 Dwi Hartanto, S,.Kom 10/06/2012 3. Abyss Web Server 2. Virgo Web Server Abyss Web Server memungkinkan Anda untuk meng-host situs web Anda pada Virgo Web Server dari EclipseRT adalah sepenuhnya aplikasi berbasis server komputer sendiri. Abyss Web Server mendukung koneksi keamanan SSL/TLS Java bbbierbasismoddlul yang dirancang untuk menjjlalank an aplikasi Java (HTTPS) sert a b erb agai t ek nol ogi web . Ab yss W eb S erver j uga d apat enterprise dan Spring‐powered aplikasi dengan tingkat fleksibilitas yang menjalankan aplikasi web PHP, Perl, Python, ASP, ASP.NET dan Ruby on Rails canggih yang dapat didukung oleh database seperti MySQL, SQLite, MS SQL tinggi dan kehandalan. Ia menawarkan platform sederhana namun Server, MS Access atau Oracle. komprehensif untuk mengembangkan, menyebarkan dan perusahaan jasa aplikasi Java. 4. Cherokee Web Server Cherokee adalah sebuah inovatif, kaya akan fitur dan mudah untuk mengkonfigurasi Web Server open source. -

Flash: an Efficient and Portable Web Server
THE ADVANCED COMPUTING SYSTEMS ASSOCIATION The following paper was originally published in the Proceedings of the 1999 USENIX Annual Technical Conference Monterey, California, USA, June 6–11, 1999 Flash: An Efficient and Portable Web Server Vivek S. Pai, Peter Druschel, and Willy Zwaenepoel Rice University © 1999 by The USENIX Association All Rights Reserved Rights to individual papers remain with the author or the author's employer. Permission is granted for noncommercial reproduction of the work for educational or research purposes. This copyright notice must be included in the reproduced paper. USENIX acknowledges all trademarks herein. For more information about the USENIX Association: Phone: 1 510 528 8649 FAX: 1 510 548 5738 Email: [email protected] WWW: http://www.usenix.org Flash: An efficient and portable Web server y y Vivek S. Pai z Peter Druschel Willy Zwaenepoel z Department of Electrical and Computer Engineering y Department of Computer Science Rice University Abstract tions that fetch requested content not currently cached This paper presents the design of a new Web server in main memory. architecture called the asymmetric multi-process event- Web servers take different approaches to achieving driven (AMPED) architecture, and evaluates the perfor- this concurrency. Servers using a single-process event- mance of an implementation of this architecture, the driven (SPED) architecture can provide excellent perfor- Flash Web server. The Flash Web server combines the mance for cached workloads, where most requested con- high performance of single-process event-driven servers tent can be kept in main memory. The Zeus server [32] on cached workloads with the performance of multi- and the original Harvest/Squid proxy caches employ the 1 process and multi-threaded servers on disk-bound work- SPED architecture .