Identification of Hub Genes Correlated with the Pathogenesis and Prognosis in Pancreatic Adenocarcinoma on Bioinformatics Methods
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Imm Catalog.Pdf
$ Gene Symbol A B 3 C 4 D 9 E 10 F 11 G 12 H 13 I 14 J. K 17 L 18 M 19 N 20 O. P 22 R 26 S 27 T 30 U 32 V. W. X. Y. Z 33 A ® ® Gene Symbol Gene ID Antibody Monoclonal Antibody Polyclonal MaxPab Full-length Protein Partial-length Protein Antibody Pair KIt siRNA/Chimera Gene Symbol Gene ID Antibody Monoclonal Antibody Polyclonal MaxPab Full-length Protein Partial-length Protein Antibody Pair KIt siRNA/Chimera A1CF 29974 ● ● ADAMTS13 11093 ● ● ● ● ● A2M 2 ● ● ● ● ● ● ADAMTS20 80070 ● AACS 65985 ● ● ● ADAMTS5 11096 ● ● ● AANAT 15 ● ● ADAMTS8 11095 ● ● ● ● AATF 26574 ● ● ● ● ● ADAMTSL2 9719 ● AATK 9625 ● ● ● ● ADAMTSL4 54507 ● ● ABCA1 19 ● ● ● ● ● ADAR 103 ● ● ABCA5 23461 ● ● ADARB1 104 ● ● ● ● ABCA7 10347 ● ADARB2 105 ● ABCB9 23457 ● ● ● ● ● ADAT1 23536 ● ● ABCC4 10257 ● ● ● ● ADAT2 134637 ● ● ABCC5 10057 ● ● ● ● ● ADAT3 113179 ● ● ● ABCC8 6833 ● ● ● ● ADCY10 55811 ● ● ABCD2 225 ● ADD1 118 ● ● ● ● ● ● ABCD4 5826 ● ● ● ADD3 120 ● ● ● ABCG1 9619 ● ● ● ● ● ADH5 128 ● ● ● ● ● ● ABL1 25 ● ● ADIPOQ 9370 ● ● ● ● ● ABL2 27 ● ● ● ● ● ADK 132 ● ● ● ● ● ABO 28 ● ● ADM 133 ● ● ● ABP1 26 ● ● ● ● ● ADNP 23394 ● ● ● ● ABR 29 ● ● ● ● ● ADORA1 134 ● ● ACAA2 10449 ● ● ● ● ADORA2A 135 ● ● ● ● ● ● ● ACAN 176 ● ● ● ● ● ● ADORA2B 136 ● ● ACE 1636 ● ● ● ● ADRA1A 148 ● ● ● ● ACE2 59272 ● ● ADRA1B 147 ● ● ACER2 340485 ● ADRA2A 150 ● ● ACHE 43 ● ● ● ● ● ● ADRB1 153 ● ● ACIN1 22985 ● ● ● ADRB2 154 ● ● ● ● ● ACOX1 51 ● ● ● ● ● ADRB3 155 ● ● ● ● ACP5 54 ● ● ● ● ● ● ● ADRBK1 156 ● ● ● ● ACSF2 80221 ● ● ADRM1 11047 ● ● ● ● ACSF3 197322 ● ● AEBP1 165 ● ● ● ● ACSL4 2182 ● -

Human and Mouse CD Marker Handbook Human and Mouse CD Marker Key Markers - Human Key Markers - Mouse
Welcome to More Choice CD Marker Handbook For more information, please visit: Human bdbiosciences.com/eu/go/humancdmarkers Mouse bdbiosciences.com/eu/go/mousecdmarkers Human and Mouse CD Marker Handbook Human and Mouse CD Marker Key Markers - Human Key Markers - Mouse CD3 CD3 CD (cluster of differentiation) molecules are cell surface markers T Cell CD4 CD4 useful for the identification and characterization of leukocytes. The CD CD8 CD8 nomenclature was developed and is maintained through the HLDA (Human Leukocyte Differentiation Antigens) workshop started in 1982. CD45R/B220 CD19 CD19 The goal is to provide standardization of monoclonal antibodies to B Cell CD20 CD22 (B cell activation marker) human antigens across laboratories. To characterize or “workshop” the antibodies, multiple laboratories carry out blind analyses of antibodies. These results independently validate antibody specificity. CD11c CD11c Dendritic Cell CD123 CD123 While the CD nomenclature has been developed for use with human antigens, it is applied to corresponding mouse antigens as well as antigens from other species. However, the mouse and other species NK Cell CD56 CD335 (NKp46) antibodies are not tested by HLDA. Human CD markers were reviewed by the HLDA. New CD markers Stem Cell/ CD34 CD34 were established at the HLDA9 meeting held in Barcelona in 2010. For Precursor hematopoetic stem cell only hematopoetic stem cell only additional information and CD markers please visit www.hcdm.org. Macrophage/ CD14 CD11b/ Mac-1 Monocyte CD33 Ly-71 (F4/80) CD66b Granulocyte CD66b Gr-1/Ly6G Ly6C CD41 CD41 CD61 (Integrin b3) CD61 Platelet CD9 CD62 CD62P (activated platelets) CD235a CD235a Erythrocyte Ter-119 CD146 MECA-32 CD106 CD146 Endothelial Cell CD31 CD62E (activated endothelial cells) Epithelial Cell CD236 CD326 (EPCAM1) For Research Use Only. -

Tools for Cell Therapy and Immunoregulation
RnDSy-lu-2945 Tools for Cell Therapy and Immunoregulation Target Cell TIM-4 SLAM/CD150 BTNL8 PD-L2/B7-DC B7-H1/PD-L1 (Human) Unknown PD-1 B7-1/CD80 TIM-1 SLAM/CD150 Receptor TIM Family SLAM Family Butyrophilins B7/CD28 Families T Cell Multiple Co-Signaling Molecules Co-stimulatory Co-inhibitory Ig Superfamily Regulate T Cell Activation Target Cell T Cell Target Cell T Cell B7-1/CD80 B7-H1/PD-L1 T cell activation requires two signals: 1) recognition of the antigenic peptide/ B7-1/CD80 B7-2/CD86 CTLA-4 major histocompatibility complex (MHC) by the T cell receptor (TCR) and 2) CD28 antigen-independent co-stimulation induced by interactions between B7-2/CD86 B7-H1/PD-L1 B7-1/CD80 co-signaling molecules expressed on target cells, such as antigen-presenting PD-L2/B7-DC PD-1 ICOS cells (APCs), and their T cell-expressed receptors. Engagement of the TCR in B7-H2/ICOS L 2Ig B7-H3 (Mouse) the absence of this second co-stimulatory signal typically results in T cell B7-H1/PD-L1 B7/CD28 Families 4Ig B7-H3 (Human) anergy or apoptosis. In addition, T cell activation can be negatively regulated Unknown Receptors by co-inhibitory molecules present on APCs. Therefore, integration of the 2Ig B7-H3 Unknown B7-H4 (Mouse) Receptors signals transduced by co-stimulatory and co-inhibitory molecules following TCR B7-H5 4Ig B7-H3 engagement directs the outcome and magnitude of a T cell response Unknown Ligand (Human) B7-H5 including the enhancement or suppression of T cell proliferation, B7-H7 Unknown Receptor differentiation, and/or cytokine secretion. -

Expression Tissue
The Journal of Immunology Killer Cell Ig-Like Receptor and Leukocyte Ig-Like Receptor Transgenic Mice Exhibit Tissue- and Cell-Specific Transgene Expression1 Danny Belkin,* Michaela Torkar,* Chiwen Chang,* Roland Barten,* Mauro Tolaini,† Anja Haude,* Rachel Allen,* Michael J. Wilson,* Dimitris Kioussis,† and John Trowsdale2* To generate an experimental model for exploring the function, expression pattern, and developmental regulation of human Ig-like activating and inhibitory receptors, we have generated transgenic mice using two human genomic clones: 52N12 (a 150-Kb clone encompassing the leukocyte Ig-like receptor (LILR)B1 (ILT2), LILRB4 (ILT3), and LILRA1 (LIR6) genes) and 1060P11 (a 160-Kb clone that contains ten killer cell Ig-like receptor (KIR) genes). Both the KIR and LILR families are encoded within the leukocyte receptor complex, and are involved in immune modulation. We have also produced a novel mAb to LILRA1 to facilitate expression studies. The LILR transgenes were expressed in a similar, but not identical, pattern to that observed in humans: LILRB1 was expressed in B cells, most NK cells, and a small number of T cells; LILRB4 was expressed in a B cell subset; and LILRA1 was found on a ring of cells surrounding B cell areas on spleen sections, consistent with other data showing monocyte/macrophage expression. KIR transgenic mice showed KIR2DL2 expression on a subset of NK cells and T cells, similar to the pattern seen in humans, and expression of KIR2DL4, KIR3DS1, and KIR2DL5 by splenic NK cells. These observations indicate that linked regulatory elements within the genomic clones are sufficient to allow appropriate expression of KIRs in mice, and illustrate that the presence of the natural ligands for these receptors, in the form of human MHC class I proteins, is not necessary for the expression of the KIRs observed in these mice. -

Proteomic and Functional Characterisation of LILRA3: Role In
Proteomic and Functional Characterisation of LILRA3: Role in Inflammation Terry Hung-Yi Lee A thesis submitted in fulfilment of the requirements for the degree of Doctor of Philosophy Faculty of Medicine The University of New South Wales 2014 PLEASE TYPE THE UNIVERSITY OF NEW SOUTH WALES Thosis/Dissertatlon Sh09t Surname or Fam1ly name L l .... f.- First name / 'f (Z (1. 1 Other name/s H "'" ~ - \'I Abbre111at1on lor degree as given in the University calendar. Pt> .fh •I "!.1 '.j 17 J/ 0 School f t. t,...., ..> I <>f lVI e.~, u1 f <J t.r-UJ Faculty: M e. o1; c.• " e Tlrte Pr,te.;) ""l(. (j. f' il ,: ..... d .;" "' u"'"r &- d·er;..c&.L J .<\ ~ l/<.tf. Al: ~ " ' ~ ..... , ...., ~~~"""'" " "'~" Abstract 350 word s ma•imum: (PLEASE TYPE) Se e (f'JicJE' -------- Declaration relating to disposition of project thos tsldissortation I hereby grant to the Un1vers1ty of New South Wales or rts agents the nght to areh1ve and to make avatlabte my theSIS or dissertation '" whole or 1n part 1n the University libranes in all forms of media. now or here after known. subject to the provisions of the Copyright Act 1968 I retain all property nghts such as patent nghts I also retain the right to use in future works (such as artldes or bOOks) all or pan of this thesis or dlssenat1on I also authonse Un1vers1ty Microfilms to use the 350 word abstract of my thesis In Dissertation Abstracts International (this is appticable to doctoral ~~· ~l.A I Po .~.. <j 'I fJs JV VJignatur~ J1 Witness Date The Un1vers1ty recogn•ses that there may be exceptional circumstances requinng restrictions on copying or conditions on use. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

Supplementary Table 1: Adhesion Genes Data Set
Supplementary Table 1: Adhesion genes data set PROBE Entrez Gene ID Celera Gene ID Gene_Symbol Gene_Name 160832 1 hCG201364.3 A1BG alpha-1-B glycoprotein 223658 1 hCG201364.3 A1BG alpha-1-B glycoprotein 212988 102 hCG40040.3 ADAM10 ADAM metallopeptidase domain 10 133411 4185 hCG28232.2 ADAM11 ADAM metallopeptidase domain 11 110695 8038 hCG40937.4 ADAM12 ADAM metallopeptidase domain 12 (meltrin alpha) 195222 8038 hCG40937.4 ADAM12 ADAM metallopeptidase domain 12 (meltrin alpha) 165344 8751 hCG20021.3 ADAM15 ADAM metallopeptidase domain 15 (metargidin) 189065 6868 null ADAM17 ADAM metallopeptidase domain 17 (tumor necrosis factor, alpha, converting enzyme) 108119 8728 hCG15398.4 ADAM19 ADAM metallopeptidase domain 19 (meltrin beta) 117763 8748 hCG20675.3 ADAM20 ADAM metallopeptidase domain 20 126448 8747 hCG1785634.2 ADAM21 ADAM metallopeptidase domain 21 208981 8747 hCG1785634.2|hCG2042897 ADAM21 ADAM metallopeptidase domain 21 180903 53616 hCG17212.4 ADAM22 ADAM metallopeptidase domain 22 177272 8745 hCG1811623.1 ADAM23 ADAM metallopeptidase domain 23 102384 10863 hCG1818505.1 ADAM28 ADAM metallopeptidase domain 28 119968 11086 hCG1786734.2 ADAM29 ADAM metallopeptidase domain 29 205542 11085 hCG1997196.1 ADAM30 ADAM metallopeptidase domain 30 148417 80332 hCG39255.4 ADAM33 ADAM metallopeptidase domain 33 140492 8756 hCG1789002.2 ADAM7 ADAM metallopeptidase domain 7 122603 101 hCG1816947.1 ADAM8 ADAM metallopeptidase domain 8 183965 8754 hCG1996391 ADAM9 ADAM metallopeptidase domain 9 (meltrin gamma) 129974 27299 hCG15447.3 ADAMDEC1 ADAM-like, -
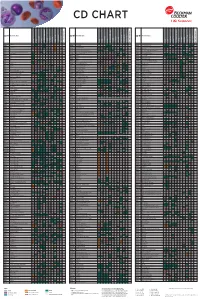
Flow Reagents Single Color Antibodies CD Chart
CD CHART CD N° Alternative Name CD N° Alternative Name CD N° Alternative Name Beckman Coulter Clone Beckman Coulter Clone Beckman Coulter Clone T Cells B Cells Granulocytes NK Cells Macrophages/Monocytes Platelets Erythrocytes Stem Cells Dendritic Cells Endothelial Cells Epithelial Cells T Cells B Cells Granulocytes NK Cells Macrophages/Monocytes Platelets Erythrocytes Stem Cells Dendritic Cells Endothelial Cells Epithelial Cells T Cells B Cells Granulocytes NK Cells Macrophages/Monocytes Platelets Erythrocytes Stem Cells Dendritic Cells Endothelial Cells Epithelial Cells CD1a T6, R4, HTA1 Act p n n p n n S l CD99 MIC2 gene product, E2 p p p CD223 LAG-3 (Lymphocyte activation gene 3) Act n Act p n CD1b R1 Act p n n p n n S CD99R restricted CD99 p p CD224 GGT (γ-glutamyl transferase) p p p p p p CD1c R7, M241 Act S n n p n n S l CD100 SEMA4D (semaphorin 4D) p Low p p p n n CD225 Leu13, interferon induced transmembrane protein 1 (IFITM1). p p p p p CD1d R3 Act S n n Low n n S Intest CD101 V7, P126 Act n p n p n n p CD226 DNAM-1, PTA-1 Act n Act Act Act n p n CD1e R2 n n n n S CD102 ICAM-2 (intercellular adhesion molecule-2) p p n p Folli p CD227 MUC1, mucin 1, episialin, PUM, PEM, EMA, DF3, H23 Act p CD2 T11; Tp50; sheep red blood cell (SRBC) receptor; LFA-2 p S n p n n l CD103 HML-1 (human mucosal lymphocytes antigen 1), integrin aE chain S n n n n n n n l CD228 Melanotransferrin (MT), p97 p p CD3 T3, CD3 complex p n n n n n n n n n l CD104 integrin b4 chain; TSP-1180 n n n n n n n p p CD229 Ly9, T-lymphocyte surface antigen p p n p n -

CD Markers Are Routinely Used for the Immunophenotyping of Cells
ptglab.com 1 CD MARKER ANTIBODIES www.ptglab.com Introduction The cluster of differentiation (abbreviated as CD) is a protocol used for the identification and investigation of cell surface molecules. So-called CD markers are routinely used for the immunophenotyping of cells. Despite this use, they are not limited to roles in the immune system and perform a variety of roles in cell differentiation, adhesion, migration, blood clotting, gamete fertilization, amino acid transport and apoptosis, among many others. As such, Proteintech’s mini catalog featuring its antibodies targeting CD markers is applicable to a wide range of research disciplines. PRODUCT FOCUS PECAM1 Platelet endothelial cell adhesion of blood vessels – making up a large portion molecule-1 (PECAM1), also known as cluster of its intracellular junctions. PECAM-1 is also CD Number of differentiation 31 (CD31), is a member of present on the surface of hematopoietic the immunoglobulin gene superfamily of cell cells and immune cells including platelets, CD31 adhesion molecules. It is highly expressed monocytes, neutrophils, natural killer cells, on the surface of the endothelium – the thin megakaryocytes and some types of T-cell. Catalog Number layer of endothelial cells lining the interior 11256-1-AP Type Rabbit Polyclonal Applications ELISA, FC, IF, IHC, IP, WB 16 Publications Immunohistochemical of paraffin-embedded Figure 1: Immunofluorescence staining human hepatocirrhosis using PECAM1, CD31 of PECAM1 (11256-1-AP), Alexa 488 goat antibody (11265-1-AP) at a dilution of 1:50 anti-rabbit (green), and smooth muscle KD/KO Validated (40x objective). alpha-actin (red), courtesy of Nicola Smart. PECAM1: Customer Testimonial Nicola Smart, a cardiovascular researcher “As you can see [the immunostaining] is and a group leader at the University of extremely clean and specific [and] displays Oxford, has said of the PECAM1 antibody strong intercellular junction expression, (11265-1-AP) that it “worked beautifully as expected for a cell adhesion molecule.” on every occasion I’ve tried it.” Proteintech thanks Dr. -

Characteristics of B Cell-Associated Gene Expression in Patients With
MOLECULAR MEDICINE REPORTS 13: 4113-4121, 2016 Characteristics of B cell-associated gene expression in patients with coronary artery disease WENWEN YAN*, HAOMING SONG*, JINFA JIANG, WENJUN XU, ZHU GONG, QIANGLIN DUAN, CHUANGRONG LI, YUAN XIE and LEMIN WANG Department of Internal Medicine, Division of Cardiology, Tongji Hospital, Tongji University School of Medicine, Shanghai 200065, P.R. China Received May 19, 2015; Accepted February 12, 2016 DOI: 10.3892/mmr.2016.5029 Abstract. The current study aimed to identify differentially with the two other groups. Additionally the gene expression expressed B cell-associated genes in peripheral blood mono- levels of B cell regulatory genes were measured. In patients nuclear cells and observe the changes in B cell activation at with AMI, CR1, LILRB2, LILRB3 and VAV1 mRNA expres- different stages of coronary artery disease. Groups of patients sion levels were statistically increased, whereas, CS1 and IL4I1 with acute myocardial infarction (AMI) and stable angina (SA), mRNAs were significantly reduced compared with the SA and as well as healthy volunteers, were recruited into the study control groups. There was no statistically significant difference (n=20 per group). Whole human genome microarray analysis in B cell-associated gene expression levels between patients was performed to examine the expression of B cell-associated with SA and the control group. The present study identified the genes among these three groups. The mRNA expression levels downregulation of genes associated with BCRs, B2 cells and of 60 genes associated with B cell activity and regulation were B cell regulators in patients with AMI, indicating a weakened measured using reverse transcription-quantitative polymerase T cell-B cell interaction and reduced B2 cell activation during chain reaction. -
Technical Note, Appendix: an Analysis of Blood Processing Methods to Prepare Samples for Genechip® Expression Profiling (Pdf, 1
Appendix 1: Signature genes for different blood cell types. Blood Cell Type Source Probe Set Description Symbol Blood Cell Type Source Probe Set Description Symbol Fraction ID Fraction ID Mono- Lympho- GSK 203547_at CD4 antigen (p55) CD4 Whitney et al. 209813_x_at T cell receptor TRG nuclear cytes gamma locus cells Whitney et al. 209995_s_at T-cell leukemia/ TCL1A Whitney et al. 203104_at colony stimulating CSF1R lymphoma 1A factor 1 receptor, Whitney et al. 210164_at granzyme B GZMB formerly McDonough (granzyme 2, feline sarcoma viral cytotoxic T-lymphocyte- (v-fms) oncogene associated serine homolog esterase 1) Whitney et al. 203290_at major histocompatibility HLA-DQA1 Whitney et al. 210321_at similar to granzyme B CTLA1 complex, class II, (granzyme 2, cytotoxic DQ alpha 1 T-lymphocyte-associated Whitney et al. 203413_at NEL-like 2 (chicken) NELL2 serine esterase 1) Whitney et al. 203828_s_at natural killer cell NK4 (H. sapiens) transcript 4 Whitney et al. 212827_at immunoglobulin heavy IGHM Whitney et al. 203932_at major histocompatibility HLA-DMB constant mu complex, class II, Whitney et al. 212998_x_at major histocompatibility HLA-DQB1 DM beta complex, class II, Whitney et al. 204655_at chemokine (C-C motif) CCL5 DQ beta 1 ligand 5 Whitney et al. 212999_x_at major histocompatibility HLA-DQB Whitney et al. 204661_at CDW52 antigen CDW52 complex, class II, (CAMPATH-1 antigen) DQ beta 1 Whitney et al. 205049_s_at CD79A antigen CD79A Whitney et al. 213193_x_at T cell receptor beta locus TRB (immunoglobulin- Whitney et al. 213425_at Homo sapiens cDNA associated alpha) FLJ11441 fis, clone Whitney et al. 205291_at interleukin 2 receptor, IL2RB HEMBA1001323, beta mRNA sequence Whitney et al. -

Supplementary Material DNA Methylation in Inflammatory Pathways Modifies the Association Between BMI and Adult-Onset Non- Atopic
Supplementary Material DNA Methylation in Inflammatory Pathways Modifies the Association between BMI and Adult-Onset Non- Atopic Asthma Ayoung Jeong 1,2, Medea Imboden 1,2, Akram Ghantous 3, Alexei Novoloaca 3, Anne-Elie Carsin 4,5,6, Manolis Kogevinas 4,5,6, Christian Schindler 1,2, Gianfranco Lovison 7, Zdenko Herceg 3, Cyrille Cuenin 3, Roel Vermeulen 8, Deborah Jarvis 9, André F. S. Amaral 9, Florian Kronenberg 10, Paolo Vineis 11,12 and Nicole Probst-Hensch 1,2,* 1 Swiss Tropical and Public Health Institute, 4051 Basel, Switzerland; [email protected] (A.J.); [email protected] (M.I.); [email protected] (C.S.) 2 Department of Public Health, University of Basel, 4001 Basel, Switzerland 3 International Agency for Research on Cancer, 69372 Lyon, France; [email protected] (A.G.); [email protected] (A.N.); [email protected] (Z.H.); [email protected] (C.C.) 4 ISGlobal, Barcelona Institute for Global Health, 08003 Barcelona, Spain; [email protected] (A.-E.C.); [email protected] (M.K.) 5 Universitat Pompeu Fabra (UPF), 08002 Barcelona, Spain 6 CIBER Epidemiología y Salud Pública (CIBERESP), 08005 Barcelona, Spain 7 Department of Economics, Business and Statistics, University of Palermo, 90128 Palermo, Italy; [email protected] 8 Environmental Epidemiology Division, Utrecht University, Institute for Risk Assessment Sciences, 3584CM Utrecht, Netherlands; [email protected] 9 Population Health and Occupational Disease, National Heart and Lung Institute, Imperial College, SW3 6LR London, UK; [email protected] (D.J.); [email protected] (A.F.S.A.) 10 Division of Genetic Epidemiology, Medical University of Innsbruck, 6020 Innsbruck, Austria; [email protected] 11 MRC-PHE Centre for Environment and Health, School of Public Health, Imperial College London, W2 1PG London, UK; [email protected] 12 Italian Institute for Genomic Medicine (IIGM), 10126 Turin, Italy * Correspondence: [email protected]; Tel.: +41-61-284-8378 Int.