Jakarta Commons Cookbook by Timothy M. O'brien Publisher
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Open Source Used in Cisco Unity Connection 11.5 SU 1
Open Source Used In Cisco Unity Connection 11.5 SU 1 Cisco Systems, Inc. www.cisco.com Cisco has more than 200 offices worldwide. Addresses, phone numbers, and fax numbers are listed on the Cisco website at www.cisco.com/go/offices. Text Part Number: 78EE117C99-132949842 Open Source Used In Cisco Unity Connection 11.5 SU 1 1 This document contains licenses and notices for open source software used in this product. With respect to the free/open source software listed in this document, if you have any questions or wish to receive a copy of any source code to which you may be entitled under the applicable free/open source license(s) (such as the GNU Lesser/General Public License), please contact us at [email protected]. In your requests please include the following reference number 78EE117C99-132949842 Contents 1.1 ace 5.3.5 1.1.1 Available under license 1.2 Apache Commons Beanutils 1.6 1.2.1 Notifications 1.2.2 Available under license 1.3 Apache Derby 10.8.1.2 1.3.1 Available under license 1.4 Apache Mina 2.0.0-RC1 1.4.1 Available under license 1.5 Apache Standards Taglibs 1.1.2 1.5.1 Available under license 1.6 Apache STRUTS 1.2.4. 1.6.1 Available under license 1.7 Apache Struts 1.2.9 1.7.1 Available under license 1.8 Apache Xerces 2.6.2. 1.8.1 Notifications 1.8.2 Available under license 1.9 axis2 1.3 1.9.1 Available under license 1.10 axis2/cddl 1.3 1.10.1 Available under license 1.11 axis2/cpl 1.3 1.11.1 Available under license 1.12 BeanUtils(duplicate) 1.6.1 1.12.1 Notifications Open Source Used In Cisco Unity Connection -
Unravel Data Systems Version 4.5
UNRAVEL DATA SYSTEMS VERSION 4.5 Component name Component version name License names jQuery 1.8.2 MIT License Apache Tomcat 5.5.23 Apache License 2.0 Tachyon Project POM 0.8.2 Apache License 2.0 Apache Directory LDAP API Model 1.0.0-M20 Apache License 2.0 apache/incubator-heron 0.16.5.1 Apache License 2.0 Maven Plugin API 3.0.4 Apache License 2.0 ApacheDS Authentication Interceptor 2.0.0-M15 Apache License 2.0 Apache Directory LDAP API Extras ACI 1.0.0-M20 Apache License 2.0 Apache HttpComponents Core 4.3.3 Apache License 2.0 Spark Project Tags 2.0.0-preview Apache License 2.0 Curator Testing 3.3.0 Apache License 2.0 Apache HttpComponents Core 4.4.5 Apache License 2.0 Apache Commons Daemon 1.0.15 Apache License 2.0 classworlds 2.4 Apache License 2.0 abego TreeLayout Core 1.0.1 BSD 3-clause "New" or "Revised" License jackson-core 2.8.6 Apache License 2.0 Lucene Join 6.6.1 Apache License 2.0 Apache Commons CLI 1.3-cloudera-pre-r1439998 Apache License 2.0 hive-apache 0.5 Apache License 2.0 scala-parser-combinators 1.0.4 BSD 3-clause "New" or "Revised" License com.springsource.javax.xml.bind 2.1.7 Common Development and Distribution License 1.0 SnakeYAML 1.15 Apache License 2.0 JUnit 4.12 Common Public License 1.0 ApacheDS Protocol Kerberos 2.0.0-M12 Apache License 2.0 Apache Groovy 2.4.6 Apache License 2.0 JGraphT - Core 1.2.0 (GNU Lesser General Public License v2.1 or later AND Eclipse Public License 1.0) chill-java 0.5.0 Apache License 2.0 Apache Commons Logging 1.2 Apache License 2.0 OpenCensus 0.12.3 Apache License 2.0 ApacheDS Protocol -

Open Source Software Licenses, Notices, and Information
Intergraph InPursuit® WebRMS 03.06.1909 Open Source Software Licenses, Notices, and Information This information is provided for Intergraph InPursuit® WebRMS, a software program of Intergraph® Corporation D/B/A Hexagon Safety & Infrastructure® (“Hexagon”). Source Code Access Intergraph InPursuit WebRMS may include components licensed pursuant to open source software licenses with an obligation to offer the recipient source code. Please see below the list of such components and the information needed to access the source code repository for each. In the event the source code is inaccessible using the information below, please email [email protected]. Component, version Link to download repository Hibernate ORM https://github.com/hibernate/hibernate-orm/releases/tag/3.6.10.Final 3.6.10.Final javassist 3.12.0.GA https://github.com/jboss-javassist/javassist/releases/tag/rel_3_12_0_ga wsdl4j 1.6.1 https://sourceforge.net/projects/wsdl4j/files/WSDL4J/1.6.1/ aspectj 1.8.4 http://git.eclipse.org/c/aspectj/org.aspectj.git/tag/?h=V1_8_4 displaytag 1.2.9 https://github.com/hexagonSI-RMS/displaytag-hexagon Open Source Software Components Intergraph InPursuit WebRMS may include the open source software components identified below. This document provides the notices and information regarding any such open source software for informational purposes only. Please see the product license agreement for Intergraph InPursuit WebRMS to determine the terms and conditions that apply to the open source software. Hexagon reserves all other rights. Component, version URL Copyright License link ActiveMQ KahaDB, version http://activemq.apache.org/kahadb.html © 2005-2012 Apache Software Foundation License 1 5.5.1 ActiveMQ, version 5.5.1 http://activemq.apache.org/ © 2005-2012 Apache Software Foundation License 1 Activiti, version 5.14.0 https://www.activiti.org/ © 2010-2016 Alfresco Software, Ltd. -
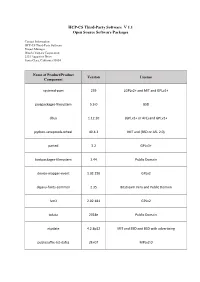
HCP-CS Third-Party Software V1.1
HCP-CS Third-Party Software V 1.1 Open Source Software Packages Contact Information: HCP-CS Third-Party Software Project Manager Hitachi Vantara Corporation 2535 Augustine Drive Santa Clara, California 95054 Name of Product/Product Version License Component systemd-pam 239 LGPLv2+ and MIT and GPLv2+ javapackages-filesystem 5.3.0 BSD dbus 1.12.10 (GPLv2+ or AFL) and GPLv2+ python-setuptools-wheel 40.4.3 MIT and (BSD or ASL 2.0) parted 3.2 GPLv3+ fontpackages-filesystem 1.44 Public Domain device-mapper-event 1.02.150 GPLv2 dejavu-fonts-common 2.35 Bitstream Vera and Public Domain lvm2 2.02.181 GPLv2 tzdata 2018e Public Domain ntpdate 4.2.8p12 MIT and BSD and BSD with advertising publicsuffix-list-dafsa 2E+07 MPLv2.0 Name of Product/Product Version License Component subversion-libs 1.10.2 ASL 2.0 ncurses-base 6.1 MIT javapackages-tools 5.3.0 BSD libX11-common 1.6.6 MIT apache-commons-pool 1.6 ASL 2.0 dnf-data 4.0.4 GPLv2+ and GPLv2 and GPL junit 4.12 EPL-1.0 fedora-release 29 MIT log4j12 1.2.17 ASL 2.0 setup 2.12.1 Public Domain cglib 3.2.4 ASL 2.0 and BSD basesystem 11 Public Domain slf4j 1.7.25 MIT and ASL 2.0 libselinux 2.8 Public Domain tomcat-lib 9.0.10 ASL 2.0 Name of Product/Product Version License Component LGPLv2+ and LGPLv2+ with exceptions and GPLv2+ glibc-all-langpacks 2.28 and GPLv2+ with exceptions and BSD and Inner-Net and ISC and Public Domain and GFDL antlr-tool 2.7.7 ANTLR-PD LGPLv2+ and LGPLv2+ with exceptions and GPLv2+ glibc 2.28 and GPLv2+ with exceptions and BSD and Inner-Net and ISC and Public Domain and GFDL apache-commons-daemon -

Release Notes Software Release 7.11 LTS Document Updated: February 2020 2
TIBCO Spotfire® Server Release Notes Software Release 7.11 LTS Document Updated: February 2020 2 Important Information SOME TIBCO SOFTWARE EMBEDS OR BUNDLES OTHER TIBCO SOFTWARE. USE OF SUCH EMBEDDED OR BUNDLED TIBCO SOFTWARE IS SOLELY TO ENABLE THE FUNCTIONALITY (OR PROVIDE LIMITED ADD-ON FUNCTIONALITY) OF THE LICENSED TIBCO SOFTWARE. THE EMBEDDED OR BUNDLED SOFTWARE IS NOT LICENSED TO BE USED OR ACCESSED BY ANY OTHER TIBCO SOFTWARE OR FOR ANY OTHER PURPOSE. USE OF TIBCO SOFTWARE AND THIS DOCUMENT IS SUBJECT TO THE TERMS AND CONDITIONS OF A LICENSE AGREEMENT FOUND IN EITHER A SEPARATELY EXECUTED SOFTWARE LICENSE AGREEMENT, OR, IF THERE IS NO SUCH SEPARATE AGREEMENT, THE CLICKWRAP END USER LICENSE AGREEMENT WHICH IS DISPLAYED DURING DOWNLOAD OR INSTALLATION OF THE SOFTWARE (AND WHICH IS DUPLICATED IN THE LICENSE FILE) OR IF THERE IS NO SUCH SOFTWARE LICENSE AGREEMENT OR CLICKWRAP END USER LICENSE AGREEMENT, THE LICENSE(S) LOCATED IN THE “LICENSE” FILE(S) OF THE SOFTWARE. USE OF THIS DOCUMENT IS SUBJECT TO THOSE TERMS AND CONDITIONS, AND YOUR USE HEREOF SHALL CONSTITUTE ACCEPTANCE OF AND AN AGREEMENT TO BE BOUND BY THE SAME. ANY SOFTWARE ITEM IDENTIFIED AS THIRD PARTY LIBRARY IS AVAILABLE UNDER SEPARATE SOFTWARE LICENSE TERMS AND IS NOT PART OF A TIBCO PRODUCT. AS SUCH, THESE SOFTWARE ITEMS ARE NOT COVERED BY THE TERMS OF YOUR AGREEMENT WITH TIBCO, INCLUDING ANY TERMS CONCERNING SUPPORT, MAINTENANCE, WARRANTIES, AND INDEMNITIES. DOWNLOAD AND USE OF THESE ITEMS IS SOLELY AT YOUR OWN DISCRETION AND SUBJECT TO THE LICENSE TERMS APPLICABLE TO THEM. BY PROCEEDING TO DOWNLOAD, INSTALL OR USE ANY OF THESE ITEMS, YOU ACKNOWLEDGE THE FOREGOING DISTINCTIONS BETWEEN THESE ITEMS AND TIBCO PRODUCTS. -

Licensing Information User Manual Mysql Enterprise Monitor 3.4
Licensing Information User Manual MySQL Enterprise Monitor 3.4 Table of Contents Licensing Information .......................................................................................................................... 4 Licenses for Third-Party Components .................................................................................................. 5 Ant-Contrib ............................................................................................................................... 10 ANTLR 2 .................................................................................................................................. 11 ANTLR 3 .................................................................................................................................. 11 Apache Commons BeanUtils v1.6 ............................................................................................. 12 Apache Commons BeanUtils v1.7.0 and Later ........................................................................... 13 Apache Commons Chain .......................................................................................................... 13 Apache Commons Codec ......................................................................................................... 13 Apache Commons Collections .................................................................................................. 14 Apache Commons Daemon ...................................................................................................... 14 Apache -

SDL Tridion Docs Release Notes
SDL Tridion Docs Release Notes SDL Tridion Docs 14 SP1 December 2019 ii SDL Tridion Docs Release Notes 1 Welcome to Tridion Docs Release Notes 1 Welcome to Tridion Docs Release Notes This document contains the complete Release Notes for SDL Tridion Docs 14 SP1. Customer support To contact Technical Support, connect to the Customer Support Web Portal at https://gateway.sdl.com and log a case for your SDL product. You need an account to log a case. If you do not have an account, contact your company's SDL Support Account Administrator. Acknowledgments SDL products include open source or similar third-party software. 7zip Is a file archiver with a high compression ratio. 7-zip is delivered under the GNU LGPL License. 7zip SFX Modified Module The SFX Modified Module is a plugin for creating self-extracting archives. It is compatible with three compression methods (LZMA, Deflate, PPMd) and provides an extended list of options. Reference website http://7zsfx.info/. Akka Akka is a toolkit and runtime for building highly concurrent, distributed, and fault tolerant event- driven applications on the JVM. Amazon Ion Java Amazon Ion Java is a Java streaming parser/serializer for Ion. It is the reference implementation of the Ion data notation for the Java Platform Standard Edition 8 and above. Amazon SQS Java Messaging Library This Amazon SQS Java Messaging Library holds the Java Message Service compatible classes, that are used for communicating with Amazon Simple Queue Service. Animal Sniffer Annotations Animal Sniffer Annotations provides Java 1.5+ annotations which allow marking methods which Animal Sniffer should ignore signature violations of. -
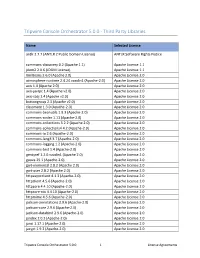
Tripwire Console Orchestrator 5.0.0 - Third Party Libraries
Tripwire Console Orchestrator 5.0.0 - Third Party Libraries Name Selected License antlr 2.7.7 (ANTLR 2 Public Domain License) ANTLR Software Rights Notice commons-discovery 0.2 (Apache 1.1) Apache License 1.1 jdom2 2.0.6 (JDOM License) Apache License 1.1 XmlBeans 2.6.0 (Apache 2.0) Apache License 2.0 atmosphere-runtime 2.4.24.vaadin1 (Apache-2.0) Apache License 2.0 axis 1.4 (Apache 2.0) Apache License 2.0 axis-jaxrpc 1.4 (Apache v2.0) Apache License 2.0 axis-saaj 1.4 (Apache v2.0) Apache License 2.0 buttongroup 2.3 (Apache v2.0) Apache License 2.0 classmate 1.3.0 (Apache-2.0) Apache License 2.0 commons-beanutils 1.9.3 (Apache-2.0) Apache License 2.0 commons-codec 1.11 (Apache-2.0) Apache License 2.0 commons-collections 3.2.2 (Apache 2.0) Apache License 2.0 commons-collections4 4.2 (Apache-2.0) Apache License 2.0 commons-io 2.6 (Apache-2.0) Apache License 2.0 commons-lang3 3.7 (Apache-2.0) Apache License 2.0 commons-logging 1.2 (Apache-2.0) Apache License 2.0 commons-text 1.4 (Apache-2.0) Apache License 2.0 gentyref 1.2.0.vaadin1 (Apache 2.0) Apache License 2.0 guava 25.1 (Apache-2.0) Apache License 2.0 gwt-elemental 2.8.2 (Apache 2.0) Apache License 2.0 gwt-user 2.8.2 (Apache 2.0) Apache License 2.0 httpasyncclient 4.1.3 (Apache-2.0) Apache License 2.0 httpclient 4.5.6 (Apache-2.0) Apache License 2.0 httpcore 4.4.10 (Apache-2.0) Apache License 2.0 httpcore-nio 4.4.10 (Apache-2.0) Apache License 2.0 httpmime 4.5.6 (Apache-2.0) Apache License 2.0 jackson-annotations 2.9.6 (Apache-2.0) Apache License 2.0 jackson-core 2.9.6 (Apache-2.0) Apache -
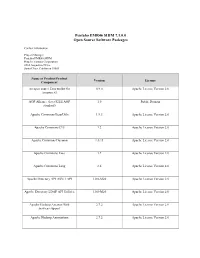
Pentaho EMR46 SHIM 7.1.0.0 Open Source Software Packages
Pentaho EMR46 SHIM 7.1.0.0 Open Source Software Packages Contact Information: Project Manager Pentaho EMR46 SHIM Hitachi Vantara Corporation 2535 Augustine Drive Santa Clara, California 95054 Name of Product/Product Version License Component An open source Java toolkit for 0.9.0 Apache License Version 2.0 Amazon S3 AOP Alliance (Java/J2EE AOP 1.0 Public Domain standard) Apache Commons BeanUtils 1.9.3 Apache License Version 2.0 Apache Commons CLI 1.2 Apache License Version 2.0 Apache Commons Daemon 1.0.13 Apache License Version 2.0 Apache Commons Exec 1.2 Apache License Version 2.0 Apache Commons Lang 2.6 Apache License Version 2.0 Apache Directory API ASN.1 API 1.0.0-M20 Apache License Version 2.0 Apache Directory LDAP API Utilities 1.0.0-M20 Apache License Version 2.0 Apache Hadoop Amazon Web 2.7.2 Apache License Version 2.0 Services support Apache Hadoop Annotations 2.7.2 Apache License Version 2.0 Name of Product/Product Version License Component Apache Hadoop Auth 2.7.2 Apache License Version 2.0 Apache Hadoop Common - 2.7.2 Apache License Version 2.0 org.apache.hadoop:hadoop-common Apache Hadoop HDFS 2.7.2 Apache License Version 2.0 Apache HBase - Client 1.2.0 Apache License Version 2.0 Apache HBase - Common 1.2.0 Apache License Version 2.0 Apache HBase - Hadoop 1.2.0 Apache License Version 2.0 Compatibility Apache HBase - Protocol 1.2.0 Apache License Version 2.0 Apache HBase - Server 1.2.0 Apache License Version 2.0 Apache HBase - Thrift - 1.2.0 Apache License Version 2.0 org.apache.hbase:hbase-thrift Apache HttpComponents Core -
Download Org Apache Commons Beanutils Converters Download Org Apache Commons Beanutils Converters
download org apache commons beanutils converters Download org apache commons beanutils converters. We recommend you use a mirror to download our release builds, but you must verify the integrity of the downloaded files using signatures downloaded from our main distribution directories. Recent releases (48 hours) may not yet be available from all the mirrors. You are currently using https://mirror.checkdomain.de/apache/ . If you encounter a problem with this mirror, please select another mirror. If all mirrors are failing, there are backup mirrors (at the end of the mirrors list) that should be available. It is essential that you verify the integrity of downloaded files, preferably using the PGP signature ( *.asc files); failing that using the SHA256 hash ( *.sha256 checksum files). The KEYS file contains the public PGP keys used by Apache Commons developers to sign releases. Download org apache commons beanutils converters. Completing the CAPTCHA proves you are a human and gives you temporary access to the web property. What can I do to prevent this in the future? If you are on a personal connection, like at home, you can run an anti-virus scan on your device to make sure it is not infected with malware. If you are at an office or shared network, you can ask the network administrator to run a scan across the network looking for misconfigured or infected devices. Another way to prevent getting this page in the future is to use Privacy Pass. You may need to download version 2.0 now from the Chrome Web Store. Cloudflare Ray ID: 67b01c9ffa0e16a1 • Your IP : 188.246.226.140 • Performance & security by Cloudflare. -

Configuring Apache Tomcat
SDL Collaborative Review installation guide Collaborative Review 7.7.0 November 2018 Legal notice Copyright and trademark information relating to this product release. Copyright © 2003–2017 SDL Group. SDL Group means SDL PLC. and its subsidiaries and affiliates. All intellectual property rights contained herein are the sole and exclusive rights of SDL Group. All references to SDL or SDL Group shall mean SDL PLC. and its subsidiaries and affiliates details of which can be obtained upon written request. All rights reserved. Unless explicitly stated otherwise, all intellectual property rights including those in copyright in the content of this website and documentation are owned by or controlled for these purposes by SDL Group. Except as otherwise expressly permitted hereunder or in accordance with copyright legislation, the content of this site, and/or the documentation may not be copied, reproduced, republished, downloaded, posted, broadcast or transmitted in any way without the express written permission of SDL. SDL Tridion Docs is a registered trademark of SDL Group. All other trademarks are the property of their respective owners. The names of other companies and products mentioned herein may be the trade- marks of their respective owners. Unless stated to the contrary, no association with any other company or product is intended or should be inferred. This product may include open source or similar third-party software, details of which can be found by clicking the following link: “Acknowledgments” on page 2. Although SDL Group takes all reasonable measures to provide accurate and comprehensive information about the product, this information is provided as-is and all warranties, conditions or other terms concerning the documentation whether express or implied by statute, common law or otherwise (including those relating to satisfactory quality and fitness for purposes) are excluded to the extent permitted by law. -

Webratio BPM Platform 8.7 Release Notes
BPM Platform 8.7 Release Notes DL RELEASE NOTES WEBRATIO BPM PLATFORM 8.7 Copyright © 2016 WebRatio s.r.l – All rights reserved. This document is protected by copyright and distributed under licenses restricting its use, copying, distribution, and decompilation. No part of this document may be reproduced in any form by any means without prior written authorization of WebRatio and its licensors, if any. WebRatio, the WebRatio logo, are trademarks or registered trademarks of WebRatio in Italy and other countries. DOCUMENTATION IS PROVIDED “AS IS” AND ALL EXPRESS OR IMPLIED CONDITIONS, REPRESENTATIONS, AND WARRANTIES, INCLUDING ANY IMPLIED WARRANTY OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE OR NON-INFRINGEMENT, ARE DISCLAIMED, EXCEPT TO THE EXTENT THAT SUCH DISCLAIMERS ARE HELD TO BE LEGALLY INVALID. THIS MANUAL IS DESIGNED TO SUPPORT AN INSTRUCTOR-LED TRAINING (ILT) COURSE AND IS INTENDED TO BE USED FOR REFERENCE PURPOSES IN CONJUNCTION WITH THE ILT COURSE. THE MANUAL IS NOT A STANDALONE TRAINING TOOL. USE OF THE MANUAL FOR SELF-STUDY WITHOUT CLASS ATTENDANCE IS NOT RECOMMENDED. Ce document est protégé par un copyright et distribuéavecdeslicences qui en restreignent l’utilisation, la copie, la distribution, et la décompilation. Aucunepartie de ce documentnepeutêtrereproduitesousaucune forme, par quelquemoyenque ce soit, sans l’autorisationpréalable et écrite de WebRatiosrl. LA DOCUMENTATION EST FOURNIE “EN L’ETAT” ET TOUTES AUTRES CONDITIONS, DECLARATIONS ET GARANTIES EXPRESSES OU TACITES SONT FORMELLEMENT EXCLUES, DANS LA MESURE AUTORISEE PAR LA LOI APPLICABLE, Y COMPRIS NOTAMMENT TOUTE GARANTIE IMPLICITE RELATIVE A LA QUALITE MARCHANDE, A L’APTITUDE A UNE UTILISATION PARTICULIERE OU A L’ABSENCE DE CONTREFAÇON.