Statistical Process Control, Part 2: How and Why SPC Works
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Image Segmentation Based on Histogram Analysis Utilizing the Cloud Model
Computers and Mathematics with Applications 62 (2011) 2824–2833 Contents lists available at SciVerse ScienceDirect Computers and Mathematics with Applications journal homepage: www.elsevier.com/locate/camwa Image segmentation based on histogram analysis utilizing the cloud model Kun Qin a,∗, Kai Xu a, Feilong Liu b, Deyi Li c a School of Remote Sensing Information Engineering, Wuhan University, Wuhan, 430079, China b Bahee International, Pleasant Hill, CA 94523, USA c Beijing Institute of Electronic System Engineering, Beijing, 100039, China article info a b s t r a c t Keywords: Both the cloud model and type-2 fuzzy sets deal with the uncertainty of membership Image segmentation which traditional type-1 fuzzy sets do not consider. Type-2 fuzzy sets consider the Histogram analysis fuzziness of the membership degrees. The cloud model considers fuzziness, randomness, Cloud model Type-2 fuzzy sets and the association between them. Based on the cloud model, the paper proposes an Probability to possibility transformations image segmentation approach which considers the fuzziness and randomness in histogram analysis. For the proposed method, first, the image histogram is generated. Second, the histogram is transformed into discrete concepts expressed by cloud models. Finally, the image is segmented into corresponding regions based on these cloud models. Segmentation experiments by images with bimodal and multimodal histograms are used to compare the proposed method with some related segmentation methods, including Otsu threshold, type-2 fuzzy threshold, fuzzy C-means clustering, and Gaussian mixture models. The comparison experiments validate the proposed method. ' 2011 Elsevier Ltd. All rights reserved. 1. Introduction In order to deal with the uncertainty of image segmentation, fuzzy sets were introduced into the field of image segmentation, and some methods were proposed in the literature. -
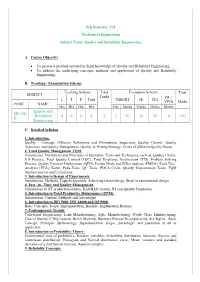
D Quality and Reliability Engineering 4 0 0 4 4 3 70 30 20 0
B.E Semester: VII Mechanical Engineering Subject Name: Quality and Reliability Engineering A. Course Objective To present a problem oriented in depth knowledge of Quality and Reliability Engineering. To address the underlying concepts, methods and application of Quality and Reliability Engineering. B. Teaching / Examination Scheme Teaching Scheme Total Evaluation Scheme Total SUBJECT Credit PR. / L T P Total THEORY IE CIA VIVO Marks CODE NAME Hrs Hrs Hrs Hrs Hrs Marks Marks Marks Marks Quality and ME706- Reliability 4 0 0 4 4 3 70 30 20 0 120 D Engineering C. Detailed Syllabus 1. Introduction: Quality – Concept, Different Definitions and Dimensions, Inspection, Quality Control, Quality Assurance and Quality Management, Quality as Wining Strategy, Views of different Quality Gurus. 2. Total Quality Management TQM: Introduction, Definitions and Principles of Operation, Tools and Techniques, such as, Quality Circles, 5 S Practice, Total Quality Control (TQC), Total Employee Involvement (TEI), Problem Solving Process, Quality Function Deployment (QFD), Failure Mode and Effect analysis (FMEA), Fault Tree Analysis (FTA), Kizen, Poka-Yoke, QC Tools, PDCA Cycle, Quality Improvement Tools, TQM Implementation and Limitations. 3. Introduction to Design of Experiments: Introduction, Methods, Taguchi approach, Achieving robust design, Steps in experimental design 4. Just –in –Time and Quality Management: Introduction to JIT production system, KANBAN system, JIT and Quality Production. 5. Introduction to Total Productive Maintenance (TPM): Introduction, Content, Methods and Advantages 6. Introduction to ISO 9000, ISO 14000 and QS 9000: Basic Concepts, Scope, Implementation, Benefits, Implantation Barriers 7. Contemporary Trends: Concurrent Engineering, Lean Manufacturing, Agile Manufacturing, World Class Manufacturing, Cost of Quality (COQ) system, Bench Marking, Business Process Re-engineering, Six Sigma - Basic Concept, Principle, Methodology, Implementation, Scope, Advantages and Limitation of all as applicable. -

Quality Assurance: Best Practices in Clinical SAS® Programming
NESUG 2012 Management, Administration and Support Quality Assurance: Best Practices in Clinical SAS® Programming Parag Shiralkar eClinical Solutions, a Division of Eliassen Group Abstract SAS® programmers working on clinical reporting projects are often under constant pressure of meeting tight timelines, producing best quality SAS® code and of meeting needs of customers. As per regulatory guidelines, a typical clinical report or dataset generation using SAS® software is considered as software development. Moreover, since statistical reporting and clinical programming is a part of clinical trial processes, such processes are required to follow strict quality assurance guidelines. While SAS® programmers completely focus on getting best quality deliverable out in a timely manner, quality assurance needs often get lesser priorities or may get unclearly understood by clinical SAS® programming staff. Most of the quality assurance practices are often focused on ‘process adherence’. Statistical programmers using SAS® software and working on clinical reporting tasks need to maintain adequate documentation for the processes they follow. Quality control strategy should be planned prevalently before starting any programming work. Adherence to standard operating procedures, maintenance of necessary audit trails, and necessary and sufficient documentation are key aspects of quality. This paper elaborates on best quality assurance practices which statistical programmers working in pharmaceutical industry are recommended to follow. These quality practices -

Permutation Tests
Permutation tests Ken Rice Thomas Lumley UW Biostatistics Seattle, June 2008 Overview • Permutation tests • A mean • Smallest p-value across multiple models • Cautionary notes Testing In testing a null hypothesis we need a test statistic that will have different values under the null hypothesis and the alternatives we care about (eg a relative risk of diabetes) We then need to compute the sampling distribution of the test statistic when the null hypothesis is true. For some test statistics and some null hypotheses this can be done analytically. The p- value for the is the probability that the test statistic would be at least as extreme as we observed, if the null hypothesis is true. A permutation test gives a simple way to compute the sampling distribution for any test statistic, under the strong null hypothesis that a set of genetic variants has absolutely no effect on the outcome. Permutations To estimate the sampling distribution of the test statistic we need many samples generated under the strong null hypothesis. If the null hypothesis is true, changing the exposure would have no effect on the outcome. By randomly shuffling the exposures we can make up as many data sets as we like. If the null hypothesis is true the shuffled data sets should look like the real data, otherwise they should look different from the real data. The ranking of the real test statistic among the shuffled test statistics gives a p-value Example: null is true Data Shuffling outcomes Shuffling outcomes (ordered) gender outcome gender outcome gender outcome Example: null is false Data Shuffling outcomes Shuffling outcomes (ordered) gender outcome gender outcome gender outcome Means Our first example is a difference in mean outcome in a dominant model for a single SNP ## make up some `true' data carrier<-rep(c(0,1), c(100,200)) null.y<-rnorm(300) alt.y<-rnorm(300, mean=carrier/2) In this case we know from theory the distribution of a difference in means and we could just do a t-test. -

Data Quality Monitoring and Surveillance System Evaluation
TECHNICAL DOCUMENT Data quality monitoring and surveillance system evaluation A handbook of methods and applications www.ecdc.europa.eu ECDC TECHNICAL DOCUMENT Data quality monitoring and surveillance system evaluation A handbook of methods and applications This publication of the European Centre for Disease Prevention and Control (ECDC) was coordinated by Isabelle Devaux (senior expert, Epidemiological Methods, ECDC). Contributing authors John Brazil (Health Protection Surveillance Centre, Ireland; Section 2.4), Bruno Ciancio (ECDC; Chapter 1, Section 2.1), Isabelle Devaux (ECDC; Chapter 1, Sections 3.1 and 3.2), James Freed (Public Health England, United Kingdom; Sections 2.1 and 3.2), Magid Herida (Institut for Public Health Surveillance, France; Section 3.8 ), Jana Kerlik (Public Health Authority of the Slovak Republic; Section 2.1), Scott McNabb (Emory University, United States of America; Sections 2.1 and 3.8), Kassiani Mellou (Hellenic Centre for Disease Control and Prevention, Greece; Sections 2.2, 2.3, 3.3, 3.4 and 3.5), Gerardo Priotto (World Health Organization; Section 3.6), Simone van der Plas (National Institute of Public Health and the Environment, the Netherlands; Chapter 4), Bart van der Zanden (Public Health Agency of Sweden; Chapter 4), Edward Valesco (Robert Koch Institute, Germany; Sections 3.1 and 3.2). Project working group members: Maria Avdicova (Public Health Authority of the Slovak Republic), Sandro Bonfigli (National Institute of Health, Italy), Mike Catchpole (Public Health England, United Kingdom), Agnes -

Quality Control and Reliability Engineering 1152Au128 3 0 0 3
L T P C QUALITY CONTROL AND RELIABILITY ENGINEERING 1152AU128 3 0 0 3 1. Preamble This course provides the essentiality of SQC, sampling and reliability engineering. Study on various types of control charts, six sigma and process capability to help the students understand various quality control techniques. Reliability engineering focuses on the dependability, failure mode analysis, reliability prediction and management of a system 2. Pre-requisite NIL 3. Course Outcomes Upon the successful completion of the course, learners will be able to Level of learning CO Course Outcomes domain (Based on Nos. C01 Explain the basic concepts in Statistical Process Control K2 Apply statistical sampling to determine whether to accept or C02 K2 reject a production lot Predict lifecycle management of a product by applying C03 K2 reliability engineering techniques. C04 Analyze data to determine the cause of a failure K2 Estimate the reliability of a component by applying RDB, C05 K2 FMEA and Fault tree analysis. 4. Correlation with Programme Outcomes Cos PO1 PO2 PO3 PO4 PO5 PO6 PO7 PO8 PO9 PO10 PO11 PO12 PSO1 PSO2 CO1 H H H M L H M L CO2 H H H M L H H M CO3 H H H M L H L H CO4 H H H M L H M M CO5 H H H M L H L H H- High; M-Medium; L-Low 5. Course content UNIT I STATISTICAL QUALITY CONTROL L-9 Methods and Philosophy of Statistical Process Control - Control Charts for Variables and Attributes Cumulative Sum and Exponentially Weighted Moving Average Control Charts - Other SPC Techniques Process - Capability Analysis - Six Sigma Concept. -

Statistical Quality Control Methods in Infection Control and Hospital Epidemiology, Part I: Introduction and Basic Theory Author(S): James C
Statistical Quality Control Methods in Infection Control and Hospital Epidemiology, Part I: Introduction and Basic Theory Author(s): James C. Benneyan Source: Infection Control and Hospital Epidemiology, Vol. 19, No. 3 (Mar., 1998), pp. 194-214 Published by: The University of Chicago Press Stable URL: http://www.jstor.org/stable/30143442 Accessed: 25/06/2010 18:26 Your use of the JSTOR archive indicates your acceptance of JSTOR's Terms and Conditions of Use, available at http://www.jstor.org/page/info/about/policies/terms.jsp. JSTOR's Terms and Conditions of Use provides, in part, that unless you have obtained prior permission, you may not download an entire issue of a journal or multiple copies of articles, and you may use content in the JSTOR archive only for your personal, non-commercial use. Please contact the publisher regarding any further use of this work. Publisher contact information may be obtained at http://www.jstor.org/action/showPublisher?publisherCode=ucpress. Each copy of any part of a JSTOR transmission must contain the same copyright notice that appears on the screen or printed page of such transmission. JSTOR is a not-for-profit service that helps scholars, researchers, and students discover, use, and build upon a wide range of content in a trusted digital archive. We use information technology and tools to increase productivity and facilitate new forms of scholarship. For more information about JSTOR, please contact [email protected]. The University of Chicago Press is collaborating with JSTOR to digitize, preserve and extend access to Infection Control and Hospital Epidemiology. -

Shinyitemanalysis for Psychometric Training and to Enforce Routine Analysis of Educational Tests
ShinyItemAnalysis for Psychometric Training and to Enforce Routine Analysis of Educational Tests Patrícia Martinková Dept. of Statistical Modelling, Institute of Computer Science, Czech Academy of Sciences College of Education, Charles University in Prague R meetup Warsaw, May 24, 2018 R meetup Warsaw, 2018 1/35 Introduction ShinyItemAnalysis Teaching psychometrics Routine analysis of tests Discussion Announcement 1: Save the date for Psychoco 2019! International Workshop on Psychometric Computing Psychoco 2019 February 21 - 22, 2019 Charles University & Czech Academy of Sciences, Prague www.psychoco.org Since 2008, the international Psychoco workshops aim at bringing together researchers working on modern techniques for the analysis of data from psychology and the social sciences (especially in R). Patrícia Martinková ShinyItemAnalysis for Psychometric Training and Test Validation R meetup Warsaw, 2018 2/35 Introduction ShinyItemAnalysis Teaching psychometrics Routine analysis of tests Discussion Announcement 2: Job offers Job offers at Institute of Computer Science: CAS-ICS Postdoctoral position (deadline: August 30) ICS Doctoral position (deadline: June 30) ICS Fellowship for junior researchers (deadline: June 30) ... further possibilities to participate on grants E-mail at [email protected] if interested in position in the area of Computational psychometrics Interdisciplinary statistics Other related disciplines Patrícia Martinková ShinyItemAnalysis for Psychometric Training and Test Validation R meetup Warsaw, 2018 3/35 Outline 1. Introduction 2. ShinyItemAnalysis 3. Teaching psychometrics 4. Routine analysis of tests 5. Discussion Introduction ShinyItemAnalysis Teaching psychometrics Routine analysis of tests Discussion Motivation To teach psychometric concepts and methods Graduate courses "IRT models", "Selected topics in psychometrics" Workshops for admission test developers Active learning approach w/ hands-on examples To enforce routine analyses of educational tests Admission tests to Czech Universities Physiology concept inventories .. -

Lecture 8 Sample Mean and Variance, Histogram, Empirical Distribution Function Sample Mean and Variance
Lecture 8 Sample Mean and Variance, Histogram, Empirical Distribution Function Sample Mean and Variance Consider a random sample , where is the = , , … sample size (number of elements in ). Then, the sample mean is given by 1 = . Sample Mean and Variance The sample mean is an unbiased estimator of the expected value of a random variable the sample is generated from: . The sample mean is the sample statistic, and is itself a random variable. Sample Mean and Variance In many practical situations, the true variance of a population is not known a priori and must be computed somehow. When dealing with extremely large populations, it is not possible to count every object in the population, so the computation must be performed on a sample of the population. Sample Mean and Variance Sample variance can also be applied to the estimation of the variance of a continuous distribution from a sample of that distribution. Sample Mean and Variance Consider a random sample of size . Then, = , , … we can define the sample variance as 1 = − , where is the sample mean. Sample Mean and Variance However, gives an estimate of the population variance that is biased by a factor of . For this reason, is referred to as the biased sample variance . Correcting for this bias yields the unbiased sample variance : 1 = = − . − 1 − 1 Sample Mean and Variance While is an unbiased estimator for the variance, is still a biased estimator for the standard deviation, though markedly less biased than the uncorrected sample standard deviation . This estimator is commonly used and generally known simply as the "sample standard deviation". -

Methodological Challenges Associated with Meta-Analyses in Health Care and Behavioral Health Research
o title: Methodological Challenges Associated with Meta Analyses in Health Care and Behavioral Health Research o date: May 14, 2012 Methodologicalo author: Challenges Associated with Judith A. Shinogle, PhD, MSc. Meta-AnalysesSenior Research Scientist in Health , Maryland InstituteCare for and Policy Analysis Behavioraland Research Health Research University of Maryland, Baltimore County 1000 Hilltop Circle Baltimore, Maryland 21250 http://www.umbc.edu/mipar/shinogle.php Judith A. Shinogle, PhD, MSc Senior Research Scientist Maryland Institute for Policy Analysis and Research University of Maryland, Baltimore County 1000 Hilltop Circle Baltimore, Maryland 21250 http://www.umbc.edu/mipar/shinogle.php Please see http://www.umbc.edu/mipar/shinogle.php for information about the Judith A. Shinogle Memorial Fund, Baltimore, MD, and the AKC Canine Health Foundation (www.akcchf.org), Raleigh, NC. Inquiries may also be directed to Sara Radcliffe, Executive Vice President for Health, Biotechnology Industry Organization, www.bio.org, 202-962-9200. May 14, 2012 Methodological Challenges Associated with Meta-Analyses in Health Care and Behavioral Health Research Judith A. Shinogle, PhD, MSc I. Executive Summary Meta-analysis is used to inform a wide array of questions ranging from pharmaceutical safety to the relative effectiveness of different medical interventions. Meta-analysis also can be used to generate new hypotheses and reflect on the nature and possible causes of heterogeneity between studies. The wide range of applications has led to an increase in use of meta-analysis. When skillfully conducted, meta-analysis is one way researchers can combine and evaluate different bodies of research to determine the answers to research questions. However, as use of meta-analysis grows, it is imperative that the proper methods are used in order to draw meaningful conclusions from these analyses. -

Unit 23: Control Charts
Unit 23: Control Charts Prerequisites Unit 22, Sampling Distributions, is a prerequisite for this unit. Students need to have an understanding of the sampling distribution of the sample mean. Students should be familiar with normal distributions and the 68-95-99.7% Rule (Unit 7: Normal Curves, and Unit 8: Normal Calculations). They should know how to calculate sample means (Unit 4: Measures of Center). Additional Topic Coverage Additional coverage of this topic can be found in The Basic Practice of Statistics, Chapter 27, Statistical Process Control. Activity Description This activity should be used at the end of the unit and could serve as an assessment of x charts. For this activity students will use the Control Chart tool from the Interactive Tools menu. Students can either work individually or in pairs. Materials Access to the Control Chart tool. Graph paper (optional). For the Control Chart tool, students select a mean and standard deviation for the process (from when the process is in control), and then decide on a sample size. After students have determined and entered correct values for the upper and lower control limits, the Control Chart tool will draw the reference lines on the control chart. (Remind students to enter the values for the upper and lower control limits to four decimals.) At that point, students can use the Control Chart tool to generate sample data, compute the sample mean, and then plot the mean Unit 23: Control Charts | Faculty Guide | Page 1 against the sample number. After each sample mean has been plotted, students must decide either that the process is in control and thus should be allowed to continue or that the process is out of control and should be stopped. -

University Quality Indicators: a Critical Assessment
DIRECTORATE GENERAL FOR INTERNAL POLICIES POLICY DEPARTMENT B: STRUCTURAL AND COHESION POLICIES CULTURE AND EDUCATION UNIVERSITY QUALITY INDICATORS: A CRITICAL ASSESSMENT STUDY This document was requested by the European Parliament's Committee on Culture and Education AUTHORS Bernd Wächter (ACA) Maria Kelo (ENQA) Queenie K.H. Lam (ACA) Philipp Effertz (DAAD) Christoph Jost (DAAD) Stefanie Kottowski (DAAD) RESPONSIBLE ADMINISTRATOR Mr Miklós Györffi Policy Department B: Structural and Cohesion Policies European Parliament B-1047 Brussels E-mail: [email protected] EDITORIAL ASSISTANCE Lyna Pärt LINGUISTIC VERSIONS Original: EN ABOUT THE EDITOR To contact the Policy Department or to subscribe to its monthly newsletter please write to: [email protected] Manuscript completed in April 2015. © European Parliament, 2015. Print ISBN 978-92-823-7864-9 doi: 10.2861/660770 QA-02-15-583-EN-C PDF ISBN 978-92-823-7865-6 doi: 10.2861/426164 QA-02-15-583-EN-N This document is available on the Internet at: http://www.europarl.europa.eu/studies DISCLAIMER The opinions expressed in this document are the sole responsibility of the author and do not necessarily represent the official position of the European Parliament. Reproduction and translation for non-commercial purposes are authorized, provided the source is acknowledged and the publisher is given prior notice and sent a copy. DIRECTORATE GENERAL FOR INTERNAL POLICIES POLICY DEPARTMENT B: STRUCTURAL AND COHESION POLICIES CULTURE AND EDUCATION UNIVERSITY QUALITY INDICATORS: A CRITICAL ASSESSMENT STUDY Abstract The ‘Europe 2020 Strategy’ and other EU initiatives call for more excellence in Europe’s higher education institutions in order to improve their performance, international attractiveness and competitiveness.