Feature-Level Rating System Using Customer Reviews and Review Votes Koteswar Rao Jerripothula, Member, IEEE, Ankit Rai, Kanu Garg, and Yashvardhan Singh Rautela
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Technology That Brings Together All Things Mobile
NFC – The Technology That Brings Together All Things Mobile Philippe Benitez Wednesday, June 4th, 2014 NFC enables fast, secure, mobile contactless services… Card Emulation Mode Reader Mode P2P Mode … for both payment and non-payment services Hospitality – Hotel room keys Mass Transit – passes and limited use tickets Education – Student badge Airlines – Frequent flyer card and boarding passes Enterprise & Government– Employee badge Automotive – car sharing / car rental / fleet management Residential - Access Payment – secure mobile payments Events – Access to stadiums and large venues Loyalty and rewards – enhanced consumer experience 3 h h 1996 2001 2003 2005 2007 2014 2014 2007 2005 2003 2001 1996 previous experiences experiences previous We are benefiting from from benefiting are We Barriers to adoption are disappearing ! NFC Handsets have become mainstream ! Terminalization is being driven by ecosystem upgrades ! TSM Provisioning infrastructure has been deployed Barriers to adoption are disappearing ! NFC Handsets have become mainstream ! Terminalization is being driven by ecosystem upgrades ! TSM Provisioning infrastructure has been deployed 256 handset models now in market worldwide Gionee Elife E7 LG G Pro 2 Nokia Lumia 1020 Samsung Galaxy Note Sony Xperia P Acer E320 Liquid Express Google Nexus 10 LG G2 Nokia Lumia 1520 Samsung Galaxy Note 3 Sony Xperia S Acer Liquid Glow Google Nexus 5 LG Mach Nokia Lumia 2520 Samsung Galaxy Note II Sony Xperia Sola Adlink IMX-2000 Google Nexus 7 (2013) LG Optimus 3D Max Nokia Lumia 610 NFC Samsung -

2014 BT Compatibility List 20141030
Item Brand Name Model 1 Acer Acer beTouch E210 2 Acer acer E400 3 Acer acer P400 4 Acer DX650 5 Acer E200 6 Acer Liquid E 7 Acer Liquid Mini (E310) 8 Acer M900 9 Acer S110 10 Acer Smart handheld 11 Acer Smart handheld 12 Acer Smart handheld E100 13 Acer Smart handheld E101 14 Adec & Partner AG AG vegas 15 Alcatel Alcatel OneTouch Fierce 2 16 Alcatel MISS SIXTY MSX10 17 Alcatel OT-800/ OT-800A 18 Alcatel OT-802/ OT-802A 19 Alcatel OT-806/ OT-806A/ OT-806D/ OT-807/ OT-807A/ OT-807D 20 Alcatel OT-808/ OT-808A 21 Alcatel OT-880/ OT-880A 22 Alcatel OT-980/ OT-980A 23 Altek Altek A14 24 Amazon Amazon Fire Phone 25 Amgoo Telecom Co LTD AM83 26 Apple Apple iPhone 4S 27 Apple Apple iPhone 5 28 Apple Apple iPhone 6 29 Apple Apple iPhone 6 Plus 30 Apple iPhone 2G 31 Apple iPhone 3G 32 Apple iPhone 3Gs 33 Apple iPhone 4 34 Apple iPhone 5C 35 Apple iPHone 5S 36 Aramasmobile.com ZX021 37 Ascom Sweden AB 3749 38 Asustek 1000846 39 Asustek A10 40 Asustek G60 41 Asustek Galaxy3_L and Galaxy3_S 42 Asustek Garmin-ASUS M10E 43 Asustek P320 44 Asustek P565c 45 BlackBerry BlackBerry Passport 46 BlackBerry BlackBerry Q10 47 Broadcom Corporation BTL-A 48 Casio Hitachi C721 49 Cellnet 7 Inc. DG-805 Cellon Communications 50 C2052, Technology(Shenzhen) Co., Ltd. Cellon Communications 51 C2053, Technology(Shenzhen) Co., Ltd. Cellon Communications 52 C3031 Technology(Shenzhen) Co., Ltd. Cellon Communications 53 C5030, Technology(Shenzhen) Co., Ltd. -

Kyocera Hydro ICON User Guide
Available applications and services are subject to change at any time. Table of Contents Get Started 1 Your Phone at a Glance 1 Set Up Your Phone 1 Charge Your Phone Wirelessly 3 Your SIM Card 4 Activation and Service 5 Create Your Account and Pick Your Plan 5 Activate Your Phone 5 Manage Your Account 5 Re-Boost 6 Additional Information 7 Set Up Voicemail 7 Phone Basics 8 Your Phone’s Layout 8 Smart Sonic Receiver 10 Turn Your Phone On and Off 11 Turn Your Screen On and Off 11 Touchscreen Navigation 12 Your Home Screen 16 Home Screen Overview 16 Change the Home Screen Mode 18 Customize the Home Screen 18 Launcher Screens 22 Notifications Panel 23 Quick Settings Panel 23 Status Bar 24 Enter Text 25 Touchscreen Keyboards 25 Swype 26 Google Keyboard 28 Google Voice Typing 30 Tips for Editing Text 31 Phone Calls 33 Make Phone Calls 33 i Call Using the Phone Dialer 33 Call from Recent Calls 34 Call from Contacts 34 Call a Number in a Text Message 34 Call Emergency Numbers 34 Call Numbers with Pauses 35 Call Using the Plus (+) Code 36 Call Using Internet Calling 36 Receive Phone Calls 37 Voicemail 38 Voicemail Setup 38 Voicemail Notification 38 Retrieve Your Voicemail Messages 38 Visual Voicemail 39 Set Up Visual Voicemail 39 Review Visual Voicemail 40 Listen to Multiple Voicemail Messages 41 Compose a Visual Voicemail Message 41 Visual Voicemail Options 41 Configure Visual Voicemail Settings 42 Change Your Main Greeting via the Voicemail Menu 43 Edit the Display Name via the Voicemail Menu 43 Phone Call Options 44 In-call Options 44 Caller -

Release Notice
WOPE 5.2.22 Release Notice Copyright Backelite 2012 1. Introduction We are happy to announce the release of the HTML5-based framework WOPE 5.2. Note that this release is fully compatible with the old BKML syntax making the migration to this new version effortless. Read the release notes below to find out about all enhancements. 2. Delivery description This delivery includes: • This document Release_Notice-5.2.22-en-US.pdf • The complete WOPE Web application wope-5.2.22.war • Resources used to customize UI widgets ResourcesClient-5.2.22.zip • Examples of customizable error pages wope-errors-5.2.22.zip • The english version of the Developer Handbook Developer_Handbook-5.2.22-en-US.pdf • The english version of the Operating Handbook Operating_Handbook-5.2.22-en-US.pdf 3. New features 3.1. New UI components • Introduced responsive menu for best user experience on tablets. Non tablets devices will get a but- ton based sliding menu. • Introduced fixed header and footer elements to provide a more native look and feel. 1 Release Notice • Introduced table sort feature for numbers, strings and currencies. • Improved default CSS layout for easy UI customization. 3.2. Advanced CSS3 features • Enhanced media queries for CSS properties filtering inside the CSS file, based on browser type and version, OS type and version, screen width, etc... • Write prefix-free CSS3 style sheet, WOPE will automatically add vendor prefixes. 3.3. WOPE Box evolution • iPad is now supported in the iOS WOPE Box. 3.4. Performance improvements • Improved compatibility with content delivery networks (CDN). -
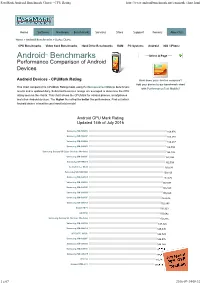
Passmark Android Benchmark Charts - CPU Rating
PassMark Android Benchmark Charts - CPU Rating http://www.androidbenchmark.net/cpumark_chart.html Home Software Hardware Benchmarks Services Store Support Forums About Us Home » Android Benchmarks » Device Charts CPU Benchmarks Video Card Benchmarks Hard Drive Benchmarks RAM PC Systems Android iOS / iPhone Android TM Benchmarks ----Select A Page ---- Performance Comparison of Android Devices Android Devices - CPUMark Rating How does your device compare? Add your device to our benchmark chart This chart compares the CPUMark Rating made using PerformanceTest Mobile benchmark with PerformanceTest Mobile ! results and is updated daily. Submitted baselines ratings are averaged to determine the CPU rating seen on the charts. This chart shows the CPUMark for various phones, smartphones and other Android devices. The higher the rating the better the performance. Find out which Android device is best for your hand held needs! Android CPU Mark Rating Updated 14th of July 2016 Samsung SM-N920V 166,976 Samsung SM-N920P 166,588 Samsung SM-G890A 166,237 Samsung SM-G928V 164,894 Samsung Galaxy S6 Edge (Various Models) 164,146 Samsung SM-G930F 162,994 Samsung SM-N920T 162,504 Lemobile Le X620 159,530 Samsung SM-N920W8 159,160 Samsung SM-G930T 157,472 Samsung SM-G930V 157,097 Samsung SM-G935P 156,823 Samsung SM-G930A 155,820 Samsung SM-G935F 153,636 Samsung SM-G935T 152,845 Xiaomi MI 5 150,923 LG H850 150,642 Samsung Galaxy S6 (Various Models) 150,316 Samsung SM-G935A 147,826 Samsung SM-G891A 145,095 HTC HTC_M10h 144,729 Samsung SM-G928F 144,576 Samsung -

Electronic 3D Models Catalogue (On July 26, 2019)
Electronic 3D models Catalogue (on July 26, 2019) Acer 001 Acer Iconia Tab A510 002 Acer Liquid Z5 003 Acer Liquid S2 Red 004 Acer Liquid S2 Black 005 Acer Iconia Tab A3 White 006 Acer Iconia Tab A1-810 White 007 Acer Iconia W4 008 Acer Liquid E3 Black 009 Acer Liquid E3 Silver 010 Acer Iconia B1-720 Iron Gray 011 Acer Iconia B1-720 Red 012 Acer Iconia B1-720 White 013 Acer Liquid Z3 Rock Black 014 Acer Liquid Z3 Classic White 015 Acer Iconia One 7 B1-730 Black 016 Acer Iconia One 7 B1-730 Red 017 Acer Iconia One 7 B1-730 Yellow 018 Acer Iconia One 7 B1-730 Green 019 Acer Iconia One 7 B1-730 Pink 020 Acer Iconia One 7 B1-730 Orange 021 Acer Iconia One 7 B1-730 Purple 022 Acer Iconia One 7 B1-730 White 023 Acer Iconia One 7 B1-730 Blue 024 Acer Iconia One 7 B1-730 Cyan 025 Acer Aspire Switch 10 026 Acer Iconia Tab A1-810 Red 027 Acer Iconia Tab A1-810 Black 028 Acer Iconia A1-830 White 029 Acer Liquid Z4 White 030 Acer Liquid Z4 Black 031 Acer Liquid Z200 Essential White 032 Acer Liquid Z200 Titanium Black 033 Acer Liquid Z200 Fragrant Pink 034 Acer Liquid Z200 Sky Blue 035 Acer Liquid Z200 Sunshine Yellow 036 Acer Liquid Jade Black 037 Acer Liquid Jade Green 038 Acer Liquid Jade White 039 Acer Liquid Z500 Sandy Silver 040 Acer Liquid Z500 Aquamarine Green 041 Acer Liquid Z500 Titanium Black 042 Acer Iconia Tab 7 (A1-713) 043 Acer Iconia Tab 7 (A1-713HD) 044 Acer Liquid E700 Burgundy Red 045 Acer Liquid E700 Titan Black 046 Acer Iconia Tab 8 047 Acer Liquid X1 Graphite Black 048 Acer Liquid X1 Wine Red 049 Acer Iconia Tab 8 W 050 Acer -

Udynamo Compatibility List
uDynamo Compatibility List Reader Manuf. Device Name Alt. Model Info Model Info OS OS Version Carrier Date Added Date Tested Type iDynamo 5 Apple iPad Air 2 Lightning N/A iOS N/A N/A Tablet iDynamo 5 Apple iPad Air* Lightning N/A iOS N/A N/A Tablet iDynamo 5 Apple iPad with Retina Display* Lightning N/A iOS N/A N/A Tablet iDynamo 5 Apple iPad mini 3 Lightning N/A iOS N/A N/A Tablet iDynamo 5 Apple iPad mini 2 Lightning N/A iOS N/A N/A Tablet iDynamo 5 Apple iPad mini* Lightning N/A iOS N/A N/A Tablet iDynamo 5 Apple iPhone 5c* Lightning N/A iOS N/A N/A Phone iDynamo 5 Apple iPhone 5s* Lightning N/A iOS N/A N/A Phone iDynamo 5 Apple iPhone 5* Lightning N/A iOS N/A N/A Phone iDynamo 5 Apple iPod touch (5th* generation) Lightning N/A iOS N/A N/A iPod iDynamo 5 Apple iPhone 6* Lightning N/A iOS N/A N/A Phone iDynamo 5 Apple iPhone 6 Plus* Lightning N/A iOS N/A N/A Phone iDynamo Apple iPad (3rd generation) 30 PIN N/A iOS N/A N/A Tablet iDynamo Apple iPad 2 30 PIN N/A iOS N/A N/A Tablet iDynamo Apple iPad 30 PIN N/A iOS N/A N/A Tablet iDynamo Apple iPhone 4s 30 PIN N/A iOS N/A N/A Phone iDynamo Apple iPhone 4 30 PIN N/A iOS N/A N/A Phone iDynamo Apple iPhone 3GS 30 PIN N/A iOS N/A N/A Phone iDynamo Apple iPod touch (3rd and 4th generation) 30 PIN N/A iOS N/A N/A iPod uDynamo Acer liquid MT liquid MT Android 2.3.6 101.18 1/24/14 1/24/14 uDynamo Alcatel Alcatel OneTouch Fierce 7024W Android 4.2.2 101.18 3/6/14 3/6/14 uDynamo ALCATEL Megane ALCATEL ONE TOUCH 5020T Android 4.1.2 101.18 8/10/15 8/10/15 uDynamo ALCATEL ALCATEL ONE TOUCH IDOL X ALCATEL -

Phone Compatibility
Phone Compatibility • Compatible with iPhone models 4S and above using iOS versions 7 or higher. Last Updated: February 14, 2017 • Compatible with phone models using Android versions 4.1 (Jelly Bean) or higher, and that have the following four sensors: Accelerometer, Gyroscope, Magnetometer, GPS/Location Services. • Phone compatibility information is provided by phone manufacturers and third-party sources. While every attempt is made to ensure the accuracy of this information, this list should only be used as a guide. As phones are consistently introduced to market, this list may not be all inclusive and will be updated as new information is received. Please check your phone for the required sensors and operating system. Brand Phone Compatible Non-Compatible Acer Acer Iconia Talk S • Acer Acer Jade Primo • Acer Acer Liquid E3 • Acer Acer Liquid E600 • Acer Acer Liquid E700 • Acer Acer Liquid Jade • Acer Acer Liquid Jade 2 • Acer Acer Liquid Jade Primo • Acer Acer Liquid Jade S • Acer Acer Liquid Jade Z • Acer Acer Liquid M220 • Acer Acer Liquid S1 • Acer Acer Liquid S2 • Acer Acer Liquid X1 • Acer Acer Liquid X2 • Acer Acer Liquid Z200 • Acer Acer Liquid Z220 • Acer Acer Liquid Z3 • Acer Acer Liquid Z4 • Acer Acer Liquid Z410 • Acer Acer Liquid Z5 • Acer Acer Liquid Z500 • Acer Acer Liquid Z520 • Acer Acer Liquid Z6 • Acer Acer Liquid Z6 Plus • Acer Acer Liquid Zest • Acer Acer Liquid Zest Plus • Acer Acer Predator 8 • Alcatel Alcatel Fierce • Alcatel Alcatel Fierce 4 • Alcatel Alcatel Flash Plus 2 • Alcatel Alcatel Go Play • Alcatel Alcatel Idol 4 • Alcatel Alcatel Idol 4s • Alcatel Alcatel One Touch Fire C • Alcatel Alcatel One Touch Fire E • Alcatel Alcatel One Touch Fire S • 1 Phone Compatibility • Compatible with iPhone models 4S and above using iOS versions 7 or higher. -

The Equipment Pricing Below Is Offered in Association with ELIN EG01 and EG03
The equipment pricing below is offered in association with ELIN EG01 and EG03. Voice Devices Device Price LG Cosmos 3 (VN251S) $0.00* LG Exalt II $79.99 LG Extravert 2 (VN280) $79.99 LG Revere 3 (VN170) $0.00* LG Terra $0.99 Samsung Gusto 3 (Dark Blue SMB311ZKA) $0.00 Kyocera DuraXV $0.00* Camera (KYOE4520) / Non Camera (KYOE4520NC) ** Applies to new activation of service or eligible upgrades on plans with a minimum monthly access of $14.99 or greater (after negotiated discount). Promotional Offer expires June 30, 2016. Push to Talk Devices Device Price Samsung Convoy 3 (SCH-u680MAV) $0.00* Kyocera DuraXV+ $0.00* Camera (KYOE4520PTT) / Non Camera (KYOE4520NCPTT) ** Applies to new activation of service or eligible upgrades on plans with a minimum monthly access of $14.99 or greater (after negotiated discount). Promotional Offer expires June 30, 2016. BlackBerry Devices Device Price BlackBerry Z30 $0.00** (while supplies last) (BBSTA100-3) BlackBerry® Classic 4G LTE $0.00* (Camera- BBSQC100-3)/ (Non Camera- BBSQC100-5) BlackBerry Priv 4G LTE $249.99 (BBSTV100-2) **Applies to new activation of service or eligible upgrades on a primary voice of $15.00 or higher with a required data bolt-on feature or a primary voice and data bundle plan with monthly access fee of $39.99 or higher. Data only Blackberry/Smartphone plans are not eligible. Voice and Data Add-A-Line share plans are eligible provided they meet the minimum access requirement. Promotional offer expires June 30, 2016. Smartphone Devices Device Price HTC Desire 612 4G LTE $19.99 (HTC331ZLVW) -
Android Benchmarks - Geekbench Browser 11/05/2015 6:27 Pm Geekbench Browser Geekbench 3 Geekbench 2 Benchmark Charts Search Geekbench 3 Results Sign up Log In
Android Benchmarks - Geekbench Browser 11/05/2015 6:27 pm Geekbench Browser Geekbench 3 Geekbench 2 Benchmark Charts Search Geekbench 3 Results Sign Up Log In COMPARE Android Benchmarks Processor Benchmarks Mac Benchmarks iOS Benchmarks Welcome to Primate Labs' Android benchmark chart. The data on this chart is gathered from user-submitted Geekbench 3 results from the Geekbench Browser. Android Benchmarks Geekbench 3 scores are calibrated against a baseline score of 2500 (which is the score of an Intel Core i5-2520M @ 2.50 GHz). Higher scores are better, with double the score indicating double the performance. SHARE If you're curious how your computer compares, you can download Geekbench 3 and run it on your computer to find out your score. Tweet 0 This chart was last updated 30 minutes ago. 139 Like 891 Single Core Multi-Core Device Score HTC Nexus 9 1890 NVIDIA Tegra K1 Denver 2499 MHz (2 cores) Samsung Galaxy S6 edge 1306 Samsung Exynos 7420 1500 MHz (8 cores) Samsung Galaxy S6 1241 Samsung Exynos 7420 1500 MHz (8 cores) Samsung Galaxy Note 4 1164 Samsung Exynos 5433 1300 MHz (8 cores) NVIDIA SHIELD Tablet 1087 NVIDIA Tegra K1 2218 MHz (4 cores) Motorola DROID Turbo 1052 Qualcomm APQ8084 Snapdragon 805 2649 MHz (4 cores) Samsung Galaxy S5 Plus 1027 Qualcomm APQ8084 Snapdragon 805 2457 MHz (4 cores) Motorola Nexus 6 1016 Qualcomm APQ8084 Snapdragon 805 2649 MHz (4 cores) Samsung Galaxy Note 4 986 Qualcomm APQ8084 Snapdragon 805 2457 MHz (4 cores) Motorola Moto X (2014) 970 Qualcomm MSM8974AC Snapdragon 801 2457 MHz (4 cores) HTC One (M8x) -

California Proposition 65
AT&T Wireless Handsets, Tablets, Wearables and other Connected Wireless Products California Proposition 65 If you received a Proposition 65 warning on your receipt, packing slip or email confirmation document, please see the following list of products to determine which product you purchased is subject to the warning. Manufacturer SKU Marketing Name and/or model # ASUS 6588A ASUS PadFone X mini Black ASUS 6593A ASUS PadFone X mini Black ASUS 6594A ASUS PadFone X mini Black ASUS R588A ASUS PadFone X mini Black - certified like new ASUS R593A ASUS PadFone X mini Black - certified like new ASUS R594A ASUS PadFone X mini Black - certified like new ASUS S588A ASUS PadFone X mini Black - warranty replacement ASUS S593A ASUS PadFone X mini Black - warranty replacement ASUS S594A ASUS PadFone X mini Black - warranty replacement ASUS 6768A ASUS ZenFone 2E White ASUS 6769A ASUS ZenFone 2E White ASUS 6770A ASUS ZenFone 2E White ASUS R768A ASUS ZenFone 2E White - certified like new ASUS R769A ASUS ZenFone 2E White - certified like new ASUS R770A ASUS ZenFone 2E White - certified like new ASUS S768A ASUS ZenFone 2E White - warranty replacement ASUS S769A ASUS ZenFone 2E White - warranty replacement ASUS S770A ASUS ZenFone 2E White - warranty replacement ASUS 6722A ASUS MeMO Pad 7 LTE (ME375CL) -BLK ASUS 6723A ASUS MeMO Pad 7 LTE (ME375CL) -BLK ASUS 6725A ASUS MeMO Pad 7 LTE (ME375CL) -BLK May 18, 2016 © 2016 AT&T Intellectual Property. All rights reserved. AT&T and the Globe logo are registered trademarks of AT&T Intellectual Property. AT&T Wireless -

Papago M11 Malaysia Apk
Papago m11 malaysia apk Continue Papago M11 Software Features: - Built 3D Landmarks and 3D Buildings - Crossroads View - Detailed Map Data - Multi Navigation Mode: 2D/3D/Split Screen - Auto Rotate - Road Elevation Display - i-Fly Touch Screen Interface - Simulation inside the Tunnels - with Malaysia, Singapore, Thailand, Brunei and Indonesia latest maps. - Free card updates every month - supported by AES Speed Trap in Malaysia Times I want to make a record regarding the Papago set tutorial! M11 SGMY on your Android phone (built-in GPS). After trying it's better than the M9 version. You don't have to worry because originally this app is a paid app, but what I dedicate is the Papago M11, which was hacked right. So free la. Hehe Features he can see here. Download apps (Papago M11!) ONCE A MONTH MAP UPDATE FREE 100%Full VERSION 22/9/2014 updated!! Click on the link below to download the Papago M11 (Download using computer :) Download (If the link to the download above doesn't work, please try the alternative link below) Download tutorial: 1. Make sure you download above 2 files. 2. Remove both files that you downloaded. Make sure the folder name is as shown below. 3. Copy the MFM-PPG-X8.5-X9 folder. Open the NaviM11SGMY folder and insert it into the Map folder. Make sure it's like the picture below. 4. Connect your Android phone on your laptop and PC with a usb cable. 5. Transfer the NaviM11SGMY folder to internal storage (for The Android version of GingerBread 2.1/2.2/2.3).