A Computational Approach for Identifying the Impact Of
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Detection of Interacting Transcription Factors in Human Tissues Using
Myšičková and Vingron BMC Genomics 2012, 13(Suppl 1):S2 http://www.biomedcentral.com/1471-2164/13/S1/S2 PROCEEDINGS Open Access Detection of interacting transcription factors in human tissues using predicted DNA binding affinity Alena Myšičková*, Martin Vingron From The Tenth Asia Pacific Bioinformatics Conference (APBC 2012) Melbourne, Australia. 17-19 January 2012 Abstract Background: Tissue-specific gene expression is generally regulated by combinatorial interactions among transcription factors (TFs) which bind to the DNA. Despite this known fact, previous discoveries of the mechanism that controls gene expression usually consider only a single TF. Results: We provide a prediction of interacting TFs in 22 human tissues based on their DNA-binding affinity in promoter regions. We analyze all possible pairs of 130 vertebrate TFs from the JASPAR database. First, all human promoter regions are scanned for single TF-DNA binding affinities with TRAP and for each TF a ranked list of all promoters ordered by the binding affinity is created. We then study the similarity of the ranked lists and detect candidates for TF-TF interaction by applying a partial independence test for multiway contingency tables. Our candidates are validated by both known protein-protein interactions (PPIs) and known gene regulation mechanisms in the selected tissue. We find that the known PPIs are significantly enriched in the groups of our predicted TF-TF interactions (2 and 7 times more common than expected by chance). In addition, the predicted interacting TFs for studied tissues (liver, muscle, hematopoietic stem cell) are supported in literature to be active regulators or to be expressed in the corresponding tissue. -

Mutations and Altered Expression of SERPINF1 in Patients with Familial Otosclerosis Joanna L
Human Molecular Genetics, 2016, Vol. 25, No. 12 2393–2403 doi: 10.1093/hmg/ddw106 Advance Access Publication Date: 7 April 2016 Original Article ORIGINAL ARTICLE Mutations and altered expression of SERPINF1 in patients with familial otosclerosis Joanna L. Ziff1, Michael Crompton1, Harry R.F. Powell2, Jeremy A. Lavy2, Christopher P. Aldren3, Karen P. Steel4,†, Shakeel R. Saeed1,2 and Sally J. Dawson1,* 1UCL Ear Institute, University College London, London WC1X 8EE, UK, 2Royal National Throat Nose and Ear Hospital, London WC1X 8EE, UK, 3Department of ENT Surgery, The Princess Margaret Hospital, Windsor SL4 3SJ, UK and 4Wellcome Trust Sanger Institute, Hinxton CB10 1SA, UK *To whom correspondence should be addressed. Tel: þ44 2076798935; Email: [email protected] Abstract Otosclerosis is a relatively common heterogenous condition, characterized by abnormal bone remodelling in the otic capsule leading to fixation of the stapedial footplate and an associated conductive hearing loss. Although familial linkage and candidate gene association studies have been performed in recent years, little progress has been made in identifying disease- causing genes. Here, we used whole-exome sequencing in four families exhibiting dominantly inherited otosclerosis to identify 23 candidate variants (reduced to 9 after segregation analysis) for further investigation in a secondary cohort of 84 familial cases. Multiple mutations were found in the SERPINF1 (Serpin Peptidase Inhibitor, Clade F) gene which encodes PEDF (pigment epithelium-derived factor), a potent inhibitor of angiogenesis and known regulator of bone density. Six rare heterozygous SERPINF1 variants were found in seven patients in our familial otosclerosis cohort; three are missense mutations predicted to be deleterious to protein function. -

Modes of Interaction of KMT2 Histone H3 Lysine 4 Methyltransferase/COMPASS Complexes with Chromatin
cells Review Modes of Interaction of KMT2 Histone H3 Lysine 4 Methyltransferase/COMPASS Complexes with Chromatin Agnieszka Bochy ´nska,Juliane Lüscher-Firzlaff and Bernhard Lüscher * ID Institute of Biochemistry and Molecular Biology, Medical School, RWTH Aachen University, Pauwelsstrasse 30, 52057 Aachen, Germany; [email protected] (A.B.); jluescher-fi[email protected] (J.L.-F.) * Correspondence: [email protected]; Tel.: +49-241-8088850; Fax: +49-241-8082427 Received: 18 January 2018; Accepted: 27 February 2018; Published: 2 March 2018 Abstract: Regulation of gene expression is achieved by sequence-specific transcriptional regulators, which convey the information that is contained in the sequence of DNA into RNA polymerase activity. This is achieved by the recruitment of transcriptional co-factors. One of the consequences of co-factor recruitment is the control of specific properties of nucleosomes, the basic units of chromatin, and their protein components, the core histones. The main principles are to regulate the position and the characteristics of nucleosomes. The latter includes modulating the composition of core histones and their variants that are integrated into nucleosomes, and the post-translational modification of these histones referred to as histone marks. One of these marks is the methylation of lysine 4 of the core histone H3 (H3K4). While mono-methylation of H3K4 (H3K4me1) is located preferentially at active enhancers, tri-methylation (H3K4me3) is a mark found at open and potentially active promoters. Thus, H3K4 methylation is typically associated with gene transcription. The class 2 lysine methyltransferases (KMTs) are the main enzymes that methylate H3K4. KMT2 enzymes function in complexes that contain a necessary core complex composed of WDR5, RBBP5, ASH2L, and DPY30, the so-called WRAD complex. -

A Candidate Molecular Signature Associated with Tamoxifen Failure in Primary Breast Cancer
Available online http://breast-cancer-research.com/content/10/5/R88 ResearchVol 10 No 5 article Open Access A candidate molecular signature associated with tamoxifen failure in primary breast cancer Julie A Vendrell1,2,3,4,5,6, Katherine E Robertson7*, Patrice Ravel8*, Susan E Bray5, Agathe Bajard9, Colin A Purdie5, Catherine Nguyen10, Sirwan M Hadad5, Ivan Bieche11, Sylvie Chabaud9, Thomas Bachelot12, Alastair M Thompson5 and Pascale A Cohen1,2,3,4,6 1Université de Lyon, 69008 Lyon, France 2Université de Lyon, Lyon 1, ISPB, Faculté de Pharmacie de Lyon, 69008 Lyon, France 3INSERM, U590, 69008 Lyon, France 4Centre Léon Bérard, FNCLCC, 69373 Lyon, France 5Department of Surgery and Molecular Oncology, Ninewells Hospital and Medical School, University of Dundee, Dundee DD1 9SY, UK 6CNRS UMR 5160, Centre de Pharmacologie et Biotechnologie pour la Santé, Faculté de Pharmacie, 34090 Montpellier, France 7Division of Pathology and Neuroscience, Ninewells Hospital and Medical School, University of Dundee, Dundee DD1 9SY, UK 8Centre de Biochimie Structurale, CNRS, INSERM, Université Montpellier I, 34090 Montpellier, France 9Centre Léon Bérard, FNCLCC, Unité de Biostatistique et d'Evaluation des Thérapeutiques, 69373 Lyon, France 10INSERM ERM206, Laboratoire TAGC, Université d'Aix-Marseille II, 13288 Marseille Cedex 9, France 11INSERM U735, Centre René Huguenin, FNCLCC, 92210 St-Cloud, France 12Centre Léon Bérard, FNCLCC, Département de Médecine, 69373 Lyon, France * Contributed equally Corresponding author: Pascale A Cohen, [email protected] Received: 28 Feb 2008 Revisions requested: 7 Apr 2008 Revisions received: 13 Oct 2008 Accepted: 17 Oct 2008 Published: 17 Oct 2008 Breast Cancer Research 2008, 10:R88 (doi:10.1186/bcr2158) This article is online at: http://breast-cancer-research.com/content/10/5/R88 © 2008 Vendrell et al.; licensee BioMed Central Ltd. -

Mediator of DNA Damage Checkpoint 1 (MDC1) Is a Novel Estrogen Receptor Co-Regulator in Invasive 6 Lobular Carcinoma of the Breast 7 8 Evelyn K
bioRxiv preprint doi: https://doi.org/10.1101/2020.12.16.423142; this version posted December 16, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC 4.0 International license. 1 Running Title: MDC1 co-regulates ER in ILC 2 3 Research article 4 5 Mediator of DNA damage checkpoint 1 (MDC1) is a novel estrogen receptor co-regulator in invasive 6 lobular carcinoma of the breast 7 8 Evelyn K. Bordeaux1+, Joseph L. Sottnik1+, Sanjana Mehrotra1, Sarah E. Ferrara2, Andrew E. Goodspeed2,3, James 9 C. Costello2,3, Matthew J. Sikora1 10 11 +EKB and JLS contributed equally to this project. 12 13 Affiliations 14 1Dept. of Pathology, University of Colorado Anschutz Medical Campus 15 2Biostatistics and Bioinformatics Shared Resource, University of Colorado Comprehensive Cancer Center 16 3Dept. of Pharmacology, University of Colorado Anschutz Medical Campus 17 18 Corresponding author 19 Matthew J. Sikora, PhD.; Mail Stop 8104, Research Complex 1 South, Room 5117, 12801 E. 17th Ave.; Aurora, 20 CO 80045. Tel: (303)724-4301; Fax: (303)724-3712; email: [email protected]. Twitter: 21 @mjsikora 22 23 Authors' contributions 24 MJS conceived of the project. MJS, EKB, and JLS designed and performed experiments. JLS developed models 25 for the project. EKB, JLS, SM, and AEG contributed to data analysis and interpretation. SEF, AEG, and JCC 26 developed and performed informatics analyses. MJS wrote the draft manuscript; all authors read and revised the 27 manuscript and have read and approved of this version of the manuscript. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

Gene Ontology Analysis with Cytoscape
Introduction to Systems Biology Exercise 6: Gene Ontology Analysis Overview: Gene Ontology (GO) is a useful resource in bioinformatics and systems biology. GO defines a controlled vocabulary of terms in biological process, molecular function, and cellular location, and relates the terms in a somewhat-organized fashion. This exercise outlines the resources available under Cytoscape to perform analyses for the enrichment of gene annotation (GO terms) in networks or sub-networks. In this exercise you will: • Learn how to navigate the Cytoscape Gene Ontology wizard to apply GO annotations to Cytoscape nodes • Learn how to look for enriched GO categories using the BiNGO plugin. What you will need: • The BiNGO plugin, developed by the Computational Biology Division, Dept. of Plant Systems Biology, Flanders Interuniversitary Institute for Biotechnology (VIB), described in Maere S, et al. Bioinformatics. 2005 Aug 15;21(16):3448-9. Epub 2005 Jun 21. • galFiltered.sif used in the earlier exercises and found under sampleData. Please download any missing files from http://www.cbs.dtu.dk/courses/27041/exercises/Ex3/ Download and install the BiNGO plugin, as follows: 1. Get BiNGO from the course page (see above) or go to the BiNGO page at http://www.psb.ugent.be/cbd/papers/BiNGO/. (This site also provides documentation on BiNGO). 2. Unzip the contents of BiNGO.zip to your Cytoscape plugins directory (make sure the BiNGO.jar file is in the plugins directory and not in a subdirectory). 3. If you are currently running Cytoscape, exit and restart. First, we will load the Gene Ontology data into Cytoscape. 1. Start Cytoscape, under Edit, Preferences, make sure your default species, “defaultSpeciesName”, is set to “Saccharomyces cerevisiae”. -

4-6 Weeks Old Female C57BL/6 Mice Obtained from Jackson Labs Were Used for Cell Isolation
Methods Mice: 4-6 weeks old female C57BL/6 mice obtained from Jackson labs were used for cell isolation. Female Foxp3-IRES-GFP reporter mice (1), backcrossed to B6/C57 background for 10 generations, were used for the isolation of naïve CD4 and naïve CD8 cells for the RNAseq experiments. The mice were housed in pathogen-free animal facility in the La Jolla Institute for Allergy and Immunology and were used according to protocols approved by the Institutional Animal Care and use Committee. Preparation of cells: Subsets of thymocytes were isolated by cell sorting as previously described (2), after cell surface staining using CD4 (GK1.5), CD8 (53-6.7), CD3ε (145- 2C11), CD24 (M1/69) (all from Biolegend). DP cells: CD4+CD8 int/hi; CD4 SP cells: CD4CD3 hi, CD24 int/lo; CD8 SP cells: CD8 int/hi CD4 CD3 hi, CD24 int/lo (Fig S2). Peripheral subsets were isolated after pooling spleen and lymph nodes. T cells were enriched by negative isolation using Dynabeads (Dynabeads untouched mouse T cells, 11413D, Invitrogen). After surface staining for CD4 (GK1.5), CD8 (53-6.7), CD62L (MEL-14), CD25 (PC61) and CD44 (IM7), naïve CD4+CD62L hiCD25-CD44lo and naïve CD8+CD62L hiCD25-CD44lo were obtained by sorting (BD FACS Aria). Additionally, for the RNAseq experiments, CD4 and CD8 naïve cells were isolated by sorting T cells from the Foxp3- IRES-GFP mice: CD4+CD62LhiCD25–CD44lo GFP(FOXP3)– and CD8+CD62LhiCD25– CD44lo GFP(FOXP3)– (antibodies were from Biolegend). In some cases, naïve CD4 cells were cultured in vitro under Th1 or Th2 polarizing conditions (3, 4). -

Mmnet: Metagenomic Analysis of Microbiome Metabolic Network
mmnet: Metagenomic analysis of microbiome metabolic network Yang Cao, Fei Li, Xiaochen Bo May 15, 2016 Contents 1 Introduction 1 1.1 Installation . .2 2 Analysis Pipeline: from raw Metagenomic Sequence Data to Metabolic Network Analysis 2 2.1 Prepare metagenomic sequence data . .3 2.2 Annotation of Metagenomic Sequence Reads . .3 2.3 Estimating the abundance of enzymatic genes . .5 2.4 Building reference metabolic dataset . .7 2.5 Constructing State Specific Network . .8 2.6 Topological network analysis . .9 2.7 Differential network analysis . 10 2.8 Network Visualization . 10 3 Analysis in Cytoscape 11 1 Introduction This manual is a brief introduction to structure, functions and usage of mmnet pack- age. The mmnet package provides a set of functions to support systems analysis of metagenomic data in R, including annotation of raw metagenomic sequence data, con- struction of metabolic network, and differential network analysis based on state specific metabolic network and enzymatic gene abundance. Meanwhile, the package supports an analysis pipeline for metagenomic systems bi- ology. We can simply start from raw metagenomic sequence data, optionally use MG- RAST to rapidly retrieve metagenomic annotation, fetch pathway data from KEGG using its API to construct metabolic network, and then utilize a metagenomic systems biology computational framework mentioned in [Greenblum et al., 2012] to establish further differential network analysis. The main features of mmnet: • Annotation of metagenomic sequence reads with MG-RAST • Estimating abundances of enzymatic gene based on functional annotation 1 • Constructing State Specific metabolic Network • Topological network analysis • Differential network analysis 1.1 Installation mmnet requires these packages: KEGGREST, igraph, Biobase, XML, RCurl, RJSO- NIO, stringr, ggplot2 and biom. -

Expression Profiling of KLF4
Expression Profiling of KLF4 AJCR0000006 Supplemental Data Figure S1. Snapshot of enriched gene sets identified by GSEA in Klf4-null MEFs. Figure S2. Snapshot of enriched gene sets identified by GSEA in wild type MEFs. 98 Am J Cancer Res 2011;1(1):85-97 Table S1: Functional Annotation Clustering of Genes Up-Regulated in Klf4 -Null MEFs ILLUMINA_ID Gene Symbol Gene Name (Description) P -value Fold-Change Cell Cycle 8.00E-03 ILMN_1217331 Mcm6 MINICHROMOSOME MAINTENANCE DEFICIENT 6 40.36 ILMN_2723931 E2f6 E2F TRANSCRIPTION FACTOR 6 26.8 ILMN_2724570 Mapk12 MITOGEN-ACTIVATED PROTEIN KINASE 12 22.19 ILMN_1218470 Cdk2 CYCLIN-DEPENDENT KINASE 2 9.32 ILMN_1234909 Tipin TIMELESS INTERACTING PROTEIN 5.3 ILMN_1212692 Mapk13 SAPK/ERK/KINASE 4 4.96 ILMN_2666690 Cul7 CULLIN 7 2.23 ILMN_2681776 Mapk6 MITOGEN ACTIVATED PROTEIN KINASE 4 2.11 ILMN_2652909 Ddit3 DNA-DAMAGE INDUCIBLE TRANSCRIPT 3 2.07 ILMN_2742152 Gadd45a GROWTH ARREST AND DNA-DAMAGE-INDUCIBLE 45 ALPHA 1.92 ILMN_1212787 Pttg1 PITUITARY TUMOR-TRANSFORMING 1 1.8 ILMN_1216721 Cdk5 CYCLIN-DEPENDENT KINASE 5 1.78 ILMN_1227009 Gas2l1 GROWTH ARREST-SPECIFIC 2 LIKE 1 1.74 ILMN_2663009 Rassf5 RAS ASSOCIATION (RALGDS/AF-6) DOMAIN FAMILY 5 1.64 ILMN_1220454 Anapc13 ANAPHASE PROMOTING COMPLEX SUBUNIT 13 1.61 ILMN_1216213 Incenp INNER CENTROMERE PROTEIN 1.56 ILMN_1256301 Rcc2 REGULATOR OF CHROMOSOME CONDENSATION 2 1.53 Extracellular Matrix 5.80E-06 ILMN_2735184 Col18a1 PROCOLLAGEN, TYPE XVIII, ALPHA 1 51.5 ILMN_1223997 Crtap CARTILAGE ASSOCIATED PROTEIN 32.74 ILMN_2753809 Mmp3 MATRIX METALLOPEPTIDASE -
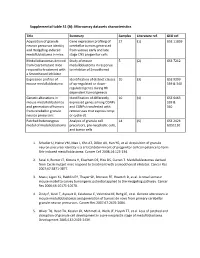
Supplemental Table S1 (A): Microarray Datasets Characteristics
Supplemental table S1 (A): Microarray datasets characteristics Title Summary Samples Literature ref. GEO ref. Acquisition of granule Gene expression profiling of 27 (1) GSE 11859 neuron precursor identity cerebellar tumors generated and Hedgehog‐induced from various early and late medulloblastoma in mice. stage CNS progenitor cells Medulloblastomas derived Study of mouse 5 (2) GSE 7212 from Cxcr6 mutant mice medulloblastoma in response respond to treatment with to inhibitor of Smoothened a Smoothened inhibitor Expression profiles of Identification of distinct classes 10 (3) GSE 9299 mouse medulloblastoma of up‐regulated or down‐ 339 & 340 regulated genes during Hh dependent tumorigenesis Genetic alterations in Identification of differently 10 (4) GSE 6463 mouse medulloblastomas expressed genes among CGNPs 339 & and generation of tumors and CGNPs transfected with 340 from cerebellar granule retroviruses that express nmyc neuron precursors or cyclin‐d1 Patched heterozygous Analysis of granule cell 14 (5) GSE 2426 model of medulloblastoma precursors, pre‐neoplastic cells, GDS1110 and tumor cells 1. Schuller U, Heine VM, Mao J, Kho AT, Dillon AK, Han YG, et al. Acquisition of granule neuron precursor identity is a critical determinant of progenitor cell competence to form Shh‐induced medulloblastoma. Cancer Cell 2008;14:123‐134. 2. Sasai K, Romer JT, Kimura H, Eberhart DE, Rice DS, Curran T. Medulloblastomas derived from Cxcr6 mutant mice respond to treatment with a smoothened inhibitor. Cancer Res 2007;67:3871‐3877. 3. Mao J, Ligon KL, Rakhlin EY, Thayer SP, Bronson RT, Rowitch D, et al. A novel somatic mouse model to survey tumorigenic potential applied to the Hedgehog pathway. Cancer Res 2006;66:10171‐10178. -

SUPPLEMENTARY MATERIAL Bone Morphogenetic Protein 4 Promotes
www.intjdevbiol.com doi: 10.1387/ijdb.160040mk SUPPLEMENTARY MATERIAL corresponding to: Bone morphogenetic protein 4 promotes craniofacial neural crest induction from human pluripotent stem cells SUMIYO MIMURA, MIKA SUGA, KAORI OKADA, MASAKI KINEHARA, HIROKI NIKAWA and MIHO K. FURUE* *Address correspondence to: Miho Kusuda Furue. Laboratory of Stem Cell Cultures, National Institutes of Biomedical Innovation, Health and Nutrition, 7-6-8, Saito-Asagi, Ibaraki, Osaka 567-0085, Japan. Tel: 81-72-641-9819. Fax: 81-72-641-9812. E-mail: [email protected] Full text for this paper is available at: http://dx.doi.org/10.1387/ijdb.160040mk TABLE S1 PRIMER LIST FOR QRT-PCR Gene forward reverse AP2α AATTTCTCAACCGACAACATT ATCTGTTTTGTAGCCAGGAGC CDX2 CTGGAGCTGGAGAAGGAGTTTC ATTTTAACCTGCCTCTCAGAGAGC DLX1 AGTTTGCAGTTGCAGGCTTT CCCTGCTTCATCAGCTTCTT FOXD3 CAGCGGTTCGGCGGGAGG TGAGTGAGAGGTTGTGGCGGATG GAPDH CAAAGTTGTCATGGATGACC CCATGGAGAAGGCTGGGG MSX1 GGATCAGACTTCGGAGAGTGAACT GCCTTCCCTTTAACCCTCACA NANOG TGAACCTCAGCTACAAACAG TGGTGGTAGGAAGAGTAAAG OCT4 GACAGGGGGAGGGGAGGAGCTAGG CTTCCCTCCAACCAGTTGCCCCAAA PAX3 TTGCAATGGCCTCTCAC AGGGGAGAGCGCGTAATC PAX6 GTCCATCTTTGCTTGGGAAA TAGCCAGGTTGCGAAGAACT p75 TCATCCCTGTCTATTGCTCCA TGTTCTGCTTGCAGCTGTTC SOX9 AATGGAGCAGCGAAATCAAC CAGAGAGATTTAGCACACTGATC SOX10 GACCAGTACCCGCACCTG CGCTTGTCACTTTCGTTCAG Suppl. Fig. S1. Comparison of the gene expression profiles of the ES cells and the cells induced by NC and NC-B condition. Scatter plots compares the normalized expression of every gene on the array (refer to Table S3). The central line