Best Practices
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Optimized Database Performance Contents Your Customers Need Lots of Data, Fast
Improve customer experience in B2B SaaS with optimized database performance Contents Your customers need lots of data, fast Your customers need lots of data, fast ......................... 2 Business to business applications such as human resources (HR) portals, collaboration tools and customer relationship management (CRM) Memory and storage: completing the pyramid .......... 3 systems must all provide fast access to data. Companies use these tools Traditional tiers of memory and storage ....................... 3 to increase their productivity, so delays will affect their businesses, and A new memory tier .................................................................. 4 ultimately their loyalty to the software provider. Additional benefits of the 2nd generation Intel® As data volumes grow, business to business software as a service (B2B SaaS) providers need to ensure their databases not only have the Xeon® Scalable processor .....................................................4 capacity for lots of data, but can also access it at speed. Improving caching with Memory Mode .......................... 5 Building services that deliver the data customers need at the moment More responsive storage with App Direct Mode ........ 6 they need it can lead to higher levels of customer satisfaction. That, in turn, could lead to improved loyalty, the opportunity to win new Crawl, walk, run ......................................................................... 8 business, and greater revenue for the B2B SaaS provider. The role of SSDs ...................................................................... -

Grade Database Architecture for Mission-‐Critical, Real
WHITE PAPER Building an Enterprise-Grade Database Architecture for Mission-Critical, Real-Time Applications Table of contents A new generation of applications – Systems of engagement ......................................... 3 New challenges – Always on at the speed of now .......................................................... 3 Shortcomings of conventional technologies ................................................................... 4 Limitations of relational databases .............................................................................. 4 Emergence of NoSQL ................................................................................................... 4 Challenges of adding a caching layer ........................................................................... 5 A better way – In-memory speed without a caching layer ............................................. 7 The industry’s first SSD-optimized NoSQL database architecture ............................... 7 How it works ................................................................................................................... 8 Exploiting cost and durability breakthroughs in flash memory technology ................ 9 Enterprise-grade NoSQL has arrived ............................................................................... 9 Financial services – Position system of record and risk ............................................... 9 More sample use cases ................................................................................................ -

Using Alluxio to Optimize and Improve Performance of Kubernetes-Based Deep Learning in the Cloud
Using Alluxio to Optimize and Improve Performance of Kubernetes-Based Deep Learning in the Cloud Featuring Alibaba Cloud Container Service Team Case Study What’s Inside 1 / New Trends in AI: Kubernetes-based This article presents the collaborative work of Deep Learning in the Cloud Alibaba, Alluxio, and Nanjing University in tackling the problem of Artificial Intelligence and Deep Learning 2 / Container and Data Orchestration model training in the cloud. We adopted a hybrid Based Architecture solution with a data orches-tration layer that connects 3 / Training in the Cloud - The First Take at private data centers to cloud platforms in a Alluxio Distributed Cache containerized environment. Various perfor-mance bottlenecks are analyzed with detailed optimizations of 4 / Performance Optimization of Model each component in the architecture. Our goal was to Training on the Cloud reduce the cost and complexity of data access for Deep 5 / Summary and Future Work Learning training in a hybrid environment, which resulted in over 40% reduction in training time and cost. © Copyright Alluxio, Inc. All rights reserved. Alluxio is a trademark of Alluxio, Inc. WHITEPAPER 1 / New trends in AI: Kubernetes-Based Deep Learning in the Cloud Background The rising popularity of artificial intelligence (AI) and deep learning (DL), where artificial neural networks are trained with increasingly massive amounts of data, continues to drive innovative solutions to improve data processing. Distributed DL model training can take advantage of multiple technologies, such as: • Cloud computing for elastic and scalable infrastructure • Docker for isolation and agile iteration via containers and Kubernetes for orchestrating the deployment of containers • Accelerated computing hardware, such as GPUs The merger of these technologies as a combined solution is emerging as the industry trend for DL training. -

Alluxio Overview
Alluxio Overview What’s Inside 1 / Introduction 2 / Data Access Challenges 3 / Benefits of Alluxio 4 / How Alluxio Works 5 / Enabling Compute and Storage Separation 6 / Use Cases 7 / Deployment © Copyright Alluxio, Inc. All rights reserved. Alluxio is a trademark of Alluxio, Inc. WHITEPAPER 1 / Introduction Alluxio is an open source software that connects analytics applications to heterogeneous data sources through a distribut- ed caching layer that sits between compute and storage. It runs on commodity hardware, creating a shared data layer abstracting the files or objects in underlying persistent storage systems. Applications connect to Alluxio via a standard interface, accessing data from a single unified source. Application Interface: Alluxio API / Hadoop Compatible / S3 Compatible / REST / FUSE Storage Interface: Any Object / File Storage WHITEPAPER / 2 2 / Data Access Challenges Organizations face a range of challenges while striving to extract value from data. Alluxio provides innovation at the data layer to abstract complexity, unify data, and intelligently manage data. This approach enables a new way to interact with data and connect the applications and people doing the work to the data sources, regardless of format or location. Doing so provides a solution to a range of challenges, for example: · Lack of access to data stored in storage silos across different departments and locations, on-premise and in the cloud · Difficulty in sharing data with multiple applications · Each application and storage system has its own interface and data exists in a wide range of formats · Data is often stored in clouds or remote locations with network latency slowing performance and impacting the freshness of the data · Storage is often tightly coupled with compute making it difficult to scale and manage storage independently / 3 3 / Benefits of Alluxio Alluxio helps overcome the obstacles to extracting value from data by making it simple to give applications access to what- ever data is needed, regardless of format or location. -

Aerospike Multi-Site Clustering: Globally Distributed, Strongly Consistent, Highly Resilient
Aerospike Multi-site Clustering: Globally Distributed, Strongly Consistent, Highly Resilient Transactions at Scale Contents Executive Summary ......................................................................................................... 3 Applications and Use Cases ........................................................................................... 3 Fundamental Concepts.................................................................................................... 5 The Aerospike Approach ................................................................................................. 6 Core Technologies ........................................................................................................... 7 Rack Awareness ..................................................................................................................................... 7 Strong, Immediate Data Consistency ..................................................................................................... 8 Operational Scenarios ..................................................................................................... 9 Healthy Cluster ....................................................................................................................................... 9 Failure Situations .................................................................................................................................. 10 Summary......................................................................................................................... -
Aerospike Vs. Cassandra - a Brief Comparison
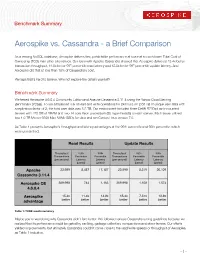
Benchmark Summary Aerospike vs. Cassandra - a Brief Comparison As a leading NoSQL database, Aerospike delivers fast, predictable performance at scale at a much lower Total Cost of Ownership (TCO) than other alternatives. Our tests with Apache Cassandra showed that Aerospike delivered 15.4x better transaction throughput, 14.8x better 99th percentile read latency and 12.8x better 99th percentile update latency. And Aerospike did that at less than 10% of Cassandra’s cost. Perhaps that’s hard to believe. Why not explore the details yourself? Benchmark Summary We tested Aerospike 4.6.0.4 Community Edition and Apache Cassandra 3.11.4 using the Yahoo Cloud Serving Benchmark (YCSB). To run a balanced mix of read and write operations for 24 hours on 2.65 TB of unique user data with a replication factor of 2, the total user data was 5.3 TB. Our environment included three Dell® R730xd rack-mounted servers with 128 GB of DRAM and two 14 core Xeon processors (56 hyperthreads) on each server. Each server utilized two 1.6 TB Micron 9200 Max NVMe SSDs for data and ran Centos Linux version 7.6. As Table 1 presents Aerospike’s throughput and latency advantages at the 99th percentile and 95th percentile, which were unmatched. Read Results Update Results Throughput 95th 99th Throughput 95th 99th Transactions Percentile Percentile Transactions Percentile Percentile (per second) Latency Latency (per second) Latency Latency (µsecs) (µsecs) (µsecs) (µsecs) Apache 23,999 8,487 17,187 23,999 8,319 20,109 Cassandra 3.11.4 Aerospike CE 369,998 744 1,163 369,998 1,108 1,574 4.6.0.4 Aerospike 15.4x 11.4x 14.8x 15.4x 7.51x 12.8x advantage better better better better better better Table 1: YCSB results summary Maybe you’re wondering why Cassandra didn’t fare better. -

Drivescale Architecture for Data Center Scale Composability
DriveScale Architecture for Data Center Scale Composability by Brian Pawlowski, Chris Unkel, Jim Hanko, Jean-François Remy 1 Overview of talk § Defining composable infrastructure § What the administrator sees § DriveScale design and architecture § Future directions § Recapitulation § Questions 2 Defining composable infrastructure 3 DriveScale – Disaggregate then Compose Captive, fixed DAS Composable DAS DAS Disaggregate DAS DAS DAS DAS Purchase Time Right sized Defined Infrastructure Software Defined Infrastructure 4 Composable Infrastructure – blade chassis scale • Single vendor hardware • Low scalability 10,000 Servers 100,000 Drives 5 Composable Infrastructure – data center scale 10,000 Servers 100,000 Drives • Choose optimized dense diskless servers, optimized storage platforms for HDD and SSD • Multivendor – mix and match • Multiprotocol Ethernet (iSCSI, ROCEv2, NVME over TCP) for wide variety of use cases • Composer platform server(s) configuration: dual socket x86, 128GB DRAM, SSD 6 Composable Infrastructure at scale Compose any compute to any drive Ethernet to storage adapters PhysicalLogical View View Hadoop Cassandra Aerospike 7 Think Bare Metal Virtualized Infrastructure for Linux, at scale – but without the VMs. 8 The devil is in the details § Breaking up (disaggregation) is easy (in my pocket) § Composable Infrastructure – at scale – is hard • Create secure durable bindings between servers and drives • Plumb end-to-end Linux storage stack over multiple protocols, multipathing, file systems, RAID configurations, hardware vendors -

Aerospike: Architecture of a Real-Time Operational DBMS
Aerospike: Architecture of a Real-Time Operational DBMS V. Srinivasan Brian Bulkowski Wei-Ling Chu Sunil Sayyaparaju Andrew Gooding Rajkumar Iyer Ashish Shinde Thomas Lopatic Aerospike, Inc. [email protected] ABSTRACT correct advertisement to a user, based on that user’s behavior. You In this paper, we describe the solutions developed to address key can see the basic architecture of the ecosystem illustrated in technical challenges encountered while building a distributed Figure 1. database system that can smoothly handle demanding real-time workloads and provide a high level of fault tolerance. Specifically, we describe schemes for the efficient clustering and data partitioning for the automatic scale out of processing across multiple nodes and for optimizing the usage of CPUs, DRAM, SSDs and networks to efficiently scale up performance on one node. The techniques described here were used to develop Aerospike (formerly Citrusleaf), a high performance distributed database system built to handle the needs of today’s interactive online services. Most real-time decision systems that use Aerospike require very high scale and need to make decisions within a strict SLA by reading from, and writing to, a database containing billions of data items at a rate of millions of operations per second with sub-millisecond latency. For over five years, Aerospike has been continuously used in over a hundred successful production deployments, as many enterprises have discovered that it can Figure 1: RTB technology stack substantially enhance their user experience. In order to participate in the real-time bidding [22] process, every participant in this ecosystem needs to have a high-performance 1. -

Memcached, Redis, and Aerospike Key-Value Stores Empirical
Memcached, Redis, and Aerospike Key-Value Stores Empirical Comparison Anthony Anthony Yaganti Naga Malleswara Rao University of Waterloo University of Waterloo 200 University Ave W 200 University Ave W Waterloo, ON, Canada Waterloo, ON, Canada +1 (226) 808-9489 +1 (226) 505-5900 [email protected] [email protected] ABSTRACT project. Thus, the results are somewhat biased as the tested DB The popularity of NoSQL database and the availability of larger setup might be set to give more advantage of one of the systems. DRAM have generated a great interest in in-memory key-value We will discuss more in Section 8 (Related Work). stores (kv-store) in the recent years. As a consequence, many In this work, we conduct a thorough experimental evaluation by similar kv-store store projects/products has emerged. Besides the comparing three major key-value stores nowadays, namely Redis, benchmarking results provided by the KV-store developers which Memcached, and Aerospike. We first elaborate the databases that are usually tested under their favorable setups and scenario, there we tested in Section 3. Then, the evaluation methodology are very limited comprehensive resources for users to decide comprises experimental setups, i.e., single and cluster mode; which kv-store to choose given a specific workload/use-case. To benchmark setups including the description of YCSB, dataset provide users with an unbiased and up-to-date insight in selecting configurations, types workloads (i.e., read-heavy, balanced, in-memory kv-stores, we conduct a study to empirically compare write-heavy), and concurrent access; and evaluation metrics will Redis, Memcached and Aerospike on equal ground by trying to be discussed in Section 4. -

Accelerate Big Data Processing (Hadoop, Spark, Memcached, & Tensorflow) with HPC Technologies
Accelerate Big Data Processing (Hadoop, Spark, Memcached, & TensorFlow) with HPC Technologies Talk at Intel® HPC Developer Conference 2017 (SC ‘17) by Dhabaleswar K. (DK) Panda Xiaoyi Lu The Ohio State University The Ohio State University E-mail: [email protected] E-mail: [email protected] http://www.cse.ohio-state.edu/~panda http://www.cse.ohio-state.edu/~luxi Big Data Processing and Deep Learning on Modern Clusters • Multiple tiers + Workflow – Front-end data accessing and serving (Online) • Memcached + DB (e.g. MySQL), HBase, etc. – Back-end data analytics and deep learning model training (Offline) • HDFS, MapReduce, Spark, TensorFlow, BigDL, Caffe, etc. Network Based Computing Laboratory Intel® HPC Developer Conference 2017 2 Drivers of Modern HPC Cluster Architectures High Performance Interconnects - Accelerators / Coprocessors InfiniBand high compute density, high Multi-core Processors <1usec latency, 100Gbps Bandwidth> performance/watt SSD, NVMe-SSD, NVRAM >1 TFlop DP on a chip • Multi-core/many-core technologies • Remote Direct Memory Access (RDMA)-enabled networking (InfiniBand and RoCE) • Solid State Drives (SSDs), Non-Volatile Random-Access Memory (NVRAM), NVMe-SSD • Accelerators (NVIDIA GPGPUs and Intel Xeon Phi) Tianhe – 2 Titan Stampede Tianhe – 1A Network Based Computing Laboratory Intel® HPC Developer Conference 2017 3 Interconnects and Protocols in OpenFabrics Stack for HPC (http://openfabrics.org) Application / Middleware Application / Middleware Interface Sockets Verbs Protocol Kernel Space TCP/IP TCP/IP -

Key Data Modeling Techniques
Key Data Modeling Techniques Piyush Gupta Director Customer Enablement Aerospike Aerospike is a "Record Centric", Distributed, NoSQL Database. 2 AEROSPIKE SUMMIT ‘19 | Proprietary & Confidential | All rights reserved. © 2019 Aerospike Inc Relational Data Modeling – Table Centric Schema, 3rdNF 3 AEROSPIKE SUMMIT ‘19 | Proprietary & Confidential | All rights reserved. © 2019 Aerospike Inc NoSQL Modeling: Record Centric Data Model § De-normalization implies duplication of data § Queries required dictate Data Model § No “Joins” across Tables (No View Table generation) § Aggregation (Multiple Data Entry) vs Association (Single Data Entry) § “Consists of” vs “related to” 4 AEROSPIKE SUMMIT ‘19 | Proprietary & Confidential | All rights reserved. © 2019 Aerospike Inc Before jumping into modeling your data ... What do you want to achieve? § Speed at Scale. § Need Consistency & Multi-Record Transactions? § Know your traffic. § Know your data. Model your data: § Even a simple key-value lookup model can be optimized to significantly reduce TCO. § Will you need secondary indexes? § List your Queries upfront. § Design de-normalized data model to address the queries. Data Modeling is tightly coupled with reducing the Total Cost of Operations. 5 AEROSPIKE SUMMIT ‘19 | Proprietary & Confidential | All rights reserved. © 2019 Aerospike Inc Aerospike Architecture Related Decisions [ Proprietary & Confidential || © 2017 Aerospike Inc. All rights reserved. 6 ] Namespaces – Select one or more. [Data Storage Options] § Storage: RAM– fastest, File storage slowest. SSDs: RAM like performance. § ALL FLASH: TCO advantage for petabyte stores/small size records. Latency penalty. 7 AEROSPIKE SUMMIT ‘19 | Proprietary & Confidential | All rights reserved. © 2019 Aerospike Inc Aerospike API Features for Data Modeling API Features to exploit for Data Modeling: § Write policy - GEN_EQUAL for Compare-and-Set (Read-Modify-Write). -

Alluxio: a Virtual Distributed File System by Haoyuan Li A
Alluxio: A Virtual Distributed File System by Haoyuan Li A dissertation submitted in partial satisfaction of the requirements for the degree of Doctor of Philosophy in Computer Science in the Graduate Division of the University of California, Berkeley Committee in charge: Professor Ion Stoica, Co-chair Professor Scott Shenker, Co-chair Professor John Chuang Spring 2018 Alluxio: A Virtual Distributed File System Copyright 2018 by Haoyuan Li 1 Abstract Alluxio: A Virtual Distributed File System by Haoyuan Li Doctor of Philosophy in Computer Science University of California, Berkeley Professor Ion Stoica, Co-chair Professor Scott Shenker, Co-chair The world is entering the data revolution era. Along with the latest advancements of the Inter- net, Artificial Intelligence (AI), mobile devices, autonomous driving, and Internet of Things (IoT), the amount of data we are generating, collecting, storing, managing, and analyzing is growing ex- ponentially. To store and process these data has exposed tremendous challenges and opportunities. Over the past two decades, we have seen significant innovation in the data stack. For exam- ple, in the computation layer, the ecosystem started from the MapReduce framework, and grew to many different general and specialized systems such as Apache Spark for general data processing, Apache Storm, Apache Samza for stream processing, Apache Mahout for machine learning, Ten- sorflow, Caffe for deep learning, Presto, Apache Drill for SQL workloads. There are more than a hundred popular frameworks for various workloads and the number is growing. Similarly, the storage layer of the ecosystem grew from the Apache Hadoop Distributed File System (HDFS) to a variety of choices as well, such as file systems, object stores, blob stores, key-value systems, and NoSQL databases to realize different tradeoffs in cost, speed and semantics.