WEB SERVICE ARCHITECTURE for MOBILE COMPUTING Sangyoon
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Talend Open Studio for Big Data Release Notes
Talend Open Studio for Big Data Release Notes 6.0.0 Talend Open Studio for Big Data Adapted for v6.0.0. Supersedes previous releases. Publication date July 2, 2015 Copyleft This documentation is provided under the terms of the Creative Commons Public License (CCPL). For more information about what you can and cannot do with this documentation in accordance with the CCPL, please read: http://creativecommons.org/licenses/by-nc-sa/2.0/ Notices Talend is a trademark of Talend, Inc. All brands, product names, company names, trademarks and service marks are the properties of their respective owners. License Agreement The software described in this documentation is licensed under the Apache License, Version 2.0 (the "License"); you may not use this software except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0.html. Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. This product includes software developed at AOP Alliance (Java/J2EE AOP standards), ASM, Amazon, AntlR, Apache ActiveMQ, Apache Ant, Apache Avro, Apache Axiom, Apache Axis, Apache Axis 2, Apache Batik, Apache CXF, Apache Cassandra, Apache Chemistry, Apache Common Http Client, Apache Common Http Core, Apache Commons, Apache Commons Bcel, Apache Commons JxPath, Apache -

Webservices - Axis
WebServices - Axis 1. Axis ######### ##### 1.2 #######: [email protected] 1.1. ## • ######### • WSDL2Java ###### • Java2WSDL ###### • ####(WSDD)###### • ##### Axis ## • ######### • Axis ###### • ####### • ########## Axis ############# • #### • ####### 1.2. ######### 1.2.1. WSDL2Java ###### ###: java org.apache.axis.wsdl.WSDL2Java [#####] WSDL-URI #####: -h, --help ################# -v, --verbose ############## -n, --noImports ######## WSDL ########## WSDL ############### ###### -O, --timeout <##> ############# (######45######## -1 ######) -D, --Debug ############ -W, --noWrapped "wrapped" document/literal ######### Page 1 Copyright © 2000-2005 The Apache Software Foundation All rights reserved. WebServices - Axis -s, --server-side Web########################### -S, --skeletonDeploy <##> deploy.wsdd ######(true)#######(false)###### ###### false ###--server-side ####### -N, --NStoPkg <##>=<#> ################### -f, --fileNStoPkg <##> NStoPkg ################ (###### NStoPkg.properties) -p, --package <##> ####################################### ## -o, --output <##> ######################## -d, --deployScope <##> deploy.xml ########### : "Application", "Request", "Session" -t, --testCase Web######## junit ############### -a, --all #####(############)########## -T, --typeMappingVersion 1.1##### 1.2 ############## 1.1 ## (SOAP 1.1 JAX-RPC ## #1.2 # SOAP 1.1 ############)# -F, --factory <##> GeneratorFactory #############(Java #############)# ############### -i, --nsInclude <####> ###################(-x ################## ##################) -

Apache AXIS2 Release Notes
AXIS2 for OpenVMS I64 July 2017 1. Introduction Apache AXIS2 for OpenVMS is the core engine for web services. It is a complete redesign and rewrite of the previously used Apache AXIS SOAP stack. This release of AXIS2 for OpenVMS is based on the latest 1.7.3 release from the Apache Software Foundation, and includes various new features and bug fixes. The release also provides a prebuilt Java servlet, which can be deployed within an application server such as Tomcat. Users are strongly encouraged to upgrade to 1.7-3 to take advantage of these improvements. This OpenVMS port of AXIS2 includes all Apache AXIS2 functionality provided by the Open Source 1.7.3 release. 2. Acknowledgements VMS Software Inc. would like to acknowledge the work of the Apache AXIS2 development team for their ongoing efforts in developing and supporting this software. 3. What’s new in this release AXIS2 Version 1.7-3 for OpenVMS is based on Apache AXIS2 1.7.3, and includes the following changes: Apache Axis2 1.7.3 is a security release that contains a fix for CVE-2010-3981. That security vulnerability affects the admin console that is part of the Axis2 Web application. The admin console now has a CSRF prevention mechanism and all known XSS vulnerabilities as well as two non-security bugs in the admin console (AXIS2-4764 and AXIS2-5716) have been fixed. Users of the AXIS2 WAR distribution are encouraged to upgrade to 1.7.3 to take advantage of these improvements. This release also fixes a regression in the HTTP client code that is triggered by the presence of certain types of cookies in HTTP responses (see AXIS2-5772). -

Xerox® Igen™ 150 Press 3 Party Software License Disclosure
Xerox® iGen™ 150 Press 3rd Party Software License Disclosure October 2013 The following software packages are copyrighted for use in this product according to the license stated. Full terms and conditions of all 3rd party software licenses are available from the About screen under the Help menu on the Press Interface or by accessing the Support & Drivers page located on the http://www.xerox.com website. Adobe Icons and Web Logos, license: Adobe Icons and Web Logos License Apache log4j 1.2.8, Apache log4j 1.2.9, Apache Web Services XML-RPC 1.2.b1, Apache Lucene Java 1.3, Apache Tomcat 4.1.27, license: Apache License 1.1 Apache Axis 1.x 1.4, Apache Jakarta Commons HttpClient 3.0.alpha1, Apache Jakarta Commons Logging 1.0.4, Apache Jakarta Lucene 1.9.1, Apache XML Security Java 1.3.0, saxpath 1.0 FCS, Skin Look And Feel (skinlf) 1.2.8, Spring Framework Utilities 0.7, Apache Web Services Axis 1.2rc3, Apache Xerces Java XML Parser 2.7.1, Apache XML Xalan-Java 2.7.0, Jetty - Java HTTP Servlet Server 4.0.D0, Lucene Snowball, Streaming API for XML (StAX) - JSR-173 20040819, license: Apache License 2.0 Perl 5.8.5, Perl 5.10.0, AppConfig-1.66, Archive-Tar-1.58, Compress::Zlib-2.020, Expect.pm- 1.21, File-NCopy-0.36, File-NFSLock-1.20, Filesys-Df-0.92, Filesys-DiskFree-0.06, HTML- Parser-3.69, HTML-Tagset-3.20, HTML-Template-2.9, IO-Stty-0.02, IO-Tty-1.08, IO-Zlib- 1.09, libxml-perl-0.08, Net-Netmask-1.9015, Net-Telnet-3.03, perl-5.8.3, perlindex-1.605, Pod- Escapes-1.04, Pod-POM-0.25, Pod-Simple-3.13, Proc-ProcessTable-0.45, Socket6-0.23, Stat- -

7.1 Oracle Bpel Process Manager
Institute of Architecture of Application Systems University of Stuttgart Universitätsstraße 38 D–70569 Stuttgart Diplomarbeit Nr. 2728 Fault Handling Across the Web Services Stack Pablo Fuentetaja Abad Course of Study: Computer Science Examiner: Prof. Dr. Frank Leymann Supervisor: Dipl.-Inf. Oliver Kopp Commenced: January ,14 2008 Completed: July, 15 2008 CR-Classification: C.2.0, C.2.1, C.2.2, C.2.4, D.2.11 Acknowledgments To my family and friends. Their support has helped me during the difficult moments. Without them this would have not been possible. To Prof. Dr. F. Leymann. For offer me the opportunity of developing this work in the Institut für Architektur von Anwendungssystemen. To Dipl.-Inf. O. Kopp. For his work, help, and supervision during these months. To Dipl.-Inf. Matthias Wieland. For his last supervision and comments. Abstract The Business Process Execution Language (BPEL) is an XML based language for describing business process behaviour based on Web services. The BPEL notation includes flow control, variables, concurrent execution, input and output, transaction scoping/compensation, and error handling. These processes are executed on a BPEL engine which calls and receives messages from external parties. The BPEL process is suspended or terminated if such communication fails, not providing any detailed information about the cause. The aim of this diploma thesis is the description of the different communication faults that can be found throughout the Web Services Stack, how they are reflected and describe a general concept of fault handling. Two BPEL engines are use on this thesis “Oracle BPEL Process Manager” and “Apache ODE”. -

Xti 9.5.41.3
Open Source Used In XTI 9.5.41.3 Cisco Systems, Inc. www.cisco.com Cisco has more than 200 offices worldwide. Addresses, phone numbers, and fax numbers are listed on the Cisco website at www.cisco.com/go/offices. Text Part Number: 78EE117C99-163479699 Open Source Used In XTI 9.5.41.3 1 This document contains licenses and notices for open source software used in this product. With respect to the free/open source software listed in this document, if you have any questions or wish to receive a copy of any source code to which you may be entitled under the applicable free/open source license(s) (such as the GNU Lesser/General Public License), please contact us at [email protected]. In your requests please include the following reference number 78EE117C99-163479699 Contents 1.1 activation 1.0.2 1.2 Apache Commons Lib Apache 2.0 1.2.1 Available under license 1.3 Apache Derby 10.10.1.1 1.3.1 Available under license 1.4 Apache HTTP Server 2.2.9 1.4.1 Available under license 1.5 Apache Jakarta Commons Configuration 1.9 1.5.1 Available under license 1.6 Apache Jakarta Commons Lang 3.1 1.6.1 Available under license 1.7 Apache Log4j 1.2.16 1.7.1 Available under license 1.8 apache-log4j 1.2.15 1.8.1 Available under license 1.9 apache-log4j 1.2.15 :DUPLICATE 1.9.1 Available under license 1.10 apache-log4j-extras-1.0.jar 1.0 1.10.1 Available under license 1.11 args4j 2.0.12 1.11.1 Available under license 1.12 axis 1.2.1 1.12.1 Available under license 1.13 axis-jaxrpc 1.2 1.13.1 Available under license 1.14 axis-saaj 1.2.1 Open Source -

Red Hat Codeready Studio 12.19.1 Release Notes
Red Hat CodeReady Studio 12.19.1 Release Notes Highlighted features in 12.19.1 Last Updated: 2021-07-16 Red Hat CodeReady Studio 12.19.1 Release Notes Highlighted features in 12.19.1 Eva-Lotte Gebhardt [email protected] Levi Valeeva [email protected] Yana Hontyk [email protected] Legal Notice Copyright © 2021 Red Hat, Inc. The text of and illustrations in this document are licensed by Red Hat under a Creative Commons Attribution–Share Alike 3.0 Unported license ("CC-BY-SA"). An explanation of CC-BY-SA is available at http://creativecommons.org/licenses/by-sa/3.0/ . In accordance with CC-BY-SA, if you distribute this document or an adaptation of it, you must provide the URL for the original version. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. Red Hat, Red Hat Enterprise Linux, the Shadowman logo, the Red Hat logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries. Linux ® is the registered trademark of Linus Torvalds in the United States and other countries. Java ® is a registered trademark of Oracle and/or its affiliates. XFS ® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries. MySQL ® is a registered trademark of MySQL AB in the United States, the European Union and other countries. Node.js ® is an official trademark of Joyent. -

Performance Evaluation of Java Web Services: a Developer's Perspective Je-Loon Yang University of North Florida
UNF Digital Commons UNF Graduate Theses and Dissertations Student Scholarship 2007 Performance Evaluation of Java Web Services: A Developer's Perspective Je-Loon Yang University of North Florida Suggested Citation Yang, Je-Loon, "Performance Evaluation of Java Web Services: A Developer's Perspective" (2007). UNF Graduate Theses and Dissertations. 246. https://digitalcommons.unf.edu/etd/246 This Master's Project is brought to you for free and open access by the Student Scholarship at UNF Digital Commons. It has been accepted for inclusion in UNF Graduate Theses and Dissertations by an authorized administrator of UNF Digital Commons. For more information, please contact Digital Projects. © 2007 All Rights Reserved PERFORMANCE EVALUATION OF JAVA WEB SERVICES: A DEVELOPER'S PERSPECTIVE by Je-Loon Yang A project submitted to the School of Computing in partial fulfillment of the requirements for the degree of Master of Science in Computer and Information Sciences UNIVERSITY OF NORTH FLORIDA SCHOOL OF COMPUTING December, 2007 The project "Performance Evaluation of Java Web Services: A Developer's Perspective" submitted by J e-Loon Yang in partial fulfillment of the requirements for the degree of Master of Science in Computer and Information Sciences has been Approved by: Date Signature Deleted /2-&/07 Sanjay Ahuja I Project Director Signature Deleted Charles N. Winton Graduate Director of the School of Computing Signature Deleted ii ACKNOWLEDGEMENT This paper is a tribute to the helpful and thoughtful guidance of my adviser Dr. Sanjay Ahuja. I further express my gratitude to my family for unwavering support and understanding, during the many hours I dedicated to achieving this milestone in my life and career. -

Developing Google Android Mobile Clients for Web Services: a Case Study
Facoltà di Ingegneria Corso di Studi in Ingegneria Informatica tesi di laurea specialistica Developing Google Android Mobile Clients for Web Services: a Case Study Anno Accademico 2007/2008 relatore Ch.mo prof. Stefano Russo correlatore Ing. Marcello Cinque candidato Vito Daniele Cuccaro matr. 885/83 1 “Anyone who has never made a mistake has never tried anything new.” Albert Einstein 2 A chi ha condiviso con me tratti di vita, lunghi o brevi, camminando al mio fianco e sorreggendomi quando inciampavo. To whoever shared with me stretches of life, long or short, walking by me and holding me up while I was stumbling. 3 DEVELOPING GOOGLE ANDROID MOBILE CLIENTS FOR WEB SERVICES: A CASE STUDY ........................................................................................................................... 1 Introduction .......................................................................................................................................................... 6 Chapter 1 - Web Services for a Service Oriented Architecture ............................................................ 8 1.1 Web Services: the latest evolution of distributed computing ................................................ 8 1.2 Key benefits and known challenges of Web Services ......................................................... 13 1.3 The basic operational model of Web Services .................................................................... 15 1.4 The SOA-based Web Services Architecture ...................................................................... -

Open Source and Third Party Documentation
Open Source and Third Party Documentation Verint.com Twitter.com/verint Facebook.com/verint Blog.verint.com Content Introduction.....................2 Licenses..........................3 Page 1 Open Source Attribution Certain components of this Software or software contained in this Product (collectively, "Software") may be covered by so-called "free or open source" software licenses ("Open Source Components"), which includes any software licenses approved as open source licenses by the Open Source Initiative or any similar licenses, including without limitation any license that, as a condition of distribution of the Open Source Components licensed, requires that the distributor make the Open Source Components available in source code format. A license in each Open Source Component is provided to you in accordance with the specific license terms specified in their respective license terms. EXCEPT WITH REGARD TO ANY WARRANTIES OR OTHER RIGHTS AND OBLIGATIONS EXPRESSLY PROVIDED DIRECTLY TO YOU FROM VERINT, ALL OPEN SOURCE COMPONENTS ARE PROVIDED "AS IS" AND ANY EXPRESSED OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. Any third party technology that may be appropriate or necessary for use with the Verint Product is licensed to you only for use with the Verint Product under the terms of the third party license agreement specified in the Documentation, the Software or as provided online at http://verint.com/thirdpartylicense. You may not take any action that would separate the third party technology from the Verint Product. Unless otherwise permitted under the terms of the third party license agreement, you agree to only use the third party technology in conjunction with the Verint Product. -

Apache Axis 1.4
Apache Axis 1.4 This product includes axis 1.4 which is distributed in accordance with the following license agreement: Apache License Version 2.0, January 2004 http://www.apache.org/licenses/ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION 1. Definitions. "License" shall mean the terms and conditions for use, reproduction, and distribution as defined by Sections 1 through 9 of this document. "Licensor" shall mean the copyright owner or entity authorized by the copyright owner that is granting the License. "Legal Entity" shall mean the union of the acting entity and all other entities that control, are controlled by, or are under common control with that entity. For the purposes of this definition, "control" means (i) the power, direct or indirect, to cause the direction or management of such entity, whether by contract or otherwise, or (ii) ownership of fifty percent (50%) or more of the outstanding shares, or (iii) beneficial ownership of such entity. "You" (or "Your") shall mean an individual or Legal Entity exercising permissions granted by this License. "Source" form shall mean the preferred form for making modifications, including but not limited to software source code, documentation source, and configuration files. "Object" form shall mean any form resulting from mechanical transformation or translation of a Source form, including but not limited to compiled object code, generated documentation, and conversions to other media types. "Work" shall mean the work of authorship, whether in Source or Object form, made available under the License, as indicated by a copyright notice that is included in or attached to the work (an example is provided in the Appendix below). -
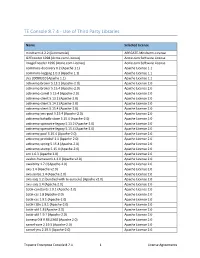
TE Console 8.7.4 - Use of Third Party Libraries
TE Console 8.7.4 - Use of Third Party Libraries Name Selected License mindterm 4.2.2 (Commercial) APPGATE-Mindterm-License GifEncoder 1998 (Acme.com License) Acme.com Software License ImageEncoder 1996 (Acme.com License) Acme.com Software License commons-discovery 0.2 (Apache 1.1) Apache License 1.1 commons-logging 1.0.3 (Apache 1.1) Apache License 1.1 jrcs 20080310 (Apache 1.1) Apache License 1.1 activemq-broker 5.13.2 (Apache-2.0) Apache License 2.0 activemq-broker 5.15.4 (Apache-2.0) Apache License 2.0 activemq-camel 5.15.4 (Apache-2.0) Apache License 2.0 activemq-client 5.13.2 (Apache-2.0) Apache License 2.0 activemq-client 5.14.2 (Apache-2.0) Apache License 2.0 activemq-client 5.15.4 (Apache-2.0) Apache License 2.0 activemq-jms-pool 5.15.4 (Apache-2.0) Apache License 2.0 activemq-kahadb-store 5.15.4 (Apache-2.0) Apache License 2.0 activemq-openwire-legacy 5.13.2 (Apache-2.0) Apache License 2.0 activemq-openwire-legacy 5.15.4 (Apache-2.0) Apache License 2.0 activemq-pool 5.15.4 (Apache-2.0) Apache License 2.0 activemq-protobuf 1.1 (Apache-2.0) Apache License 2.0 activemq-spring 5.15.4 (Apache-2.0) Apache License 2.0 activemq-stomp 5.15.4 (Apache-2.0) Apache License 2.0 ant 1.6.3 (Apache 2.0) Apache License 2.0 avalon-framework 4.2.0 (Apache v2.0) Apache License 2.0 awaitility 1.7.0 (Apache-2.0) Apache License 2.0 axis 1.4 (Apache v2.0) Apache License 2.0 axis-jaxrpc 1.4 (Apache 2.0) Apache License 2.0 axis-saaj 1.2 [bundled with te-console] (Apache v2.0) Apache License 2.0 axis-saaj 1.4 (Apache 2.0) Apache License 2.0 batik-constants